

基于方法论实现的Flashcat监控有哪些设计上的理念和方法?
Flashcat 是基于开源夜莺监控(Nightingale)并结合了方法论实现的监控产品。Flashcat的设计初衷是实现一个从数据到平台到场景真正一体化的统一监控,成为服务稳定性保障,特别是故障处理的真帮手。
Flashcat都有哪些特别的设计理念和方法呢?今天和大家分享几个主要的设计考虑,如果你也有共鸣或不同的观点,欢迎交流讨论。
数据
巧妇难为无米之炊。一个新监控系统的落地,有一半的难度可能来源于监控数据的采集和获取。
数据采集在当前都有哪些普遍的问题?
传统的监控采集方案不适应云和容器环境的数据采集;
云上的服务组件如RDS、LBS等有自己的监控采集通道,很多组件的关键指标或宿主的指标外部的采集器难以直接采集。而容器随时产生,随时消亡的特点,也是传统以物理机为中心的采集agent难以适应的。
新的采集方案质量良莠不齐,管理成本高;
适应kubernetes和容器环境的配套监控系统是prometheus,prometheus依赖各种exporter导出采集对象特别是组件类对象的数据,而exporter大家都可以提供,导致采集的数据不同,由于种类繁多管理起来也很麻烦。
Metrics、Logging、Tracing各类数据的采集方案差异大,有没有统一的采集方案?
在opentelemetry的标准下,一个完善的可观测性至少包括Metrics、Logging、Tracing三个维度,针对这三类数据的采集,如果也能由一个agent来负责,那将更为理想。 目前实现了这个采集能力的是商业配套并开源的datadog-agent,但由于历史原因,体积庞大结构复杂,并且有独立的协议,主要服务于datadog自己的平台。
落地一个监控系统要不要把已有的采集方案推倒重来?成本太高
无论是部署采集agent/exporter,还是安装日志采集agent,特别是需要研发在代码中嵌入sdk的方案,整个落地一次非常不易。如果引进一个新的监控系统需要把这些工作重做一遍,可能很多人会望而却步。特别是在还没确认新产品的效果前就去做这个事情,无异于一次冒险。
Flashcat的数据输入方法
针对数据采集的问题,Flashcat开源了一个All-in-one的采集器 Categraf,能够用一个agent,通过简单修改配置的方式,采集各类监控对象的Metrics,用户不再需要满世界去找各种exporter,并担心采集器的质量问题。
同时,Categraf 也能够采集Logging、Tracing的数据,实现了统一采集的方案。
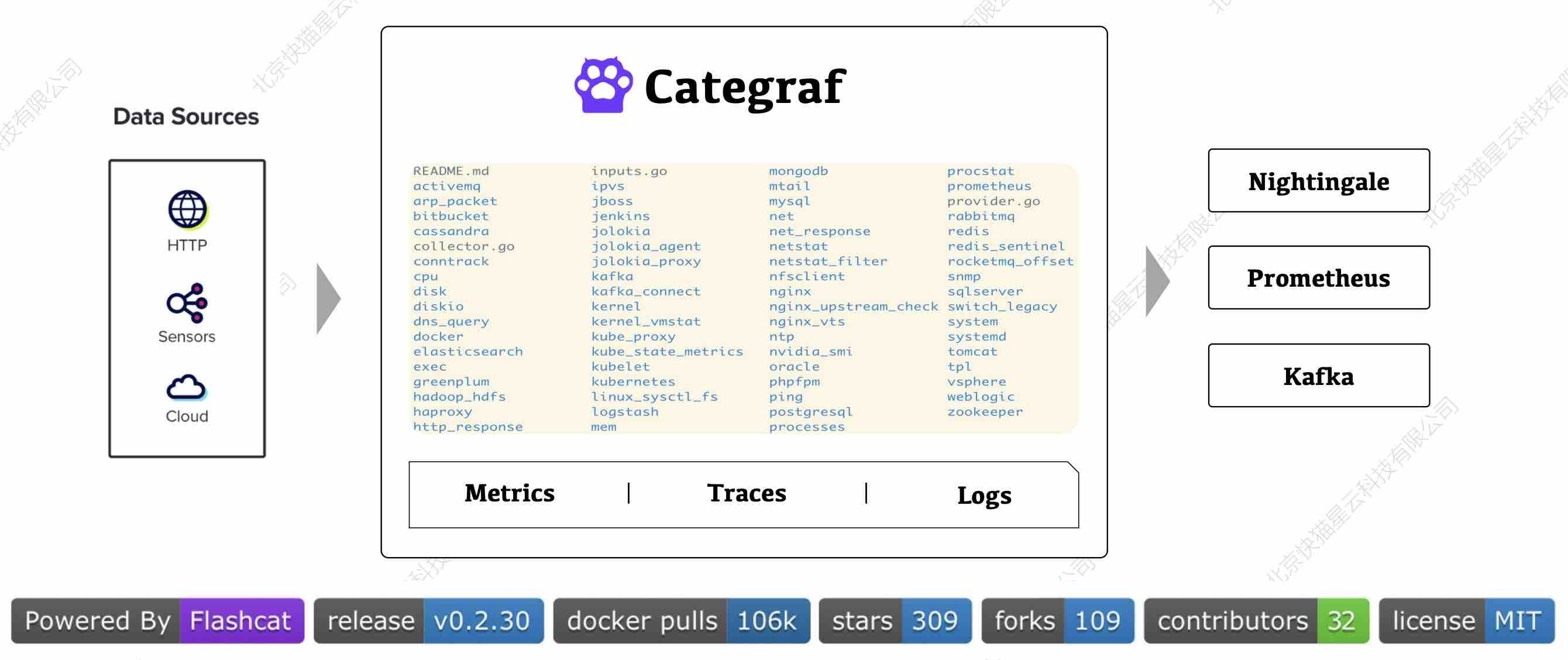
针对云组件的数据采集问题,和重新部署采集方案的成本问题,Flashcat采用了数据源集成的方案,能够集成大部分常用的数据源,以及云监控。
各类产品的数据能够相互集成,实际上是国外toB类产品生态中一个非常明显的特点,能够让整个生态获得良性的发展。

通过实现All-in-one的采集器Categraf,并集成丰富的云数据源和常用数据源来解决数据输入的问题,这就是Flashcat的数据输入方法。
平台
一套趁手的炊具是好厨师的必备。Flashcat建设了一套工程师的监控平台/工具。
Flashcat在监控平台的建设上遵循以下方法:
功能:作为一个监控系统,需要具备监控所需的所有核心功能,包括查询、看图、大盘、告警等;
Flashcat在夜莺的基础上进一步丰富了监控的功能,形成一个功能完备的监控平台,如日志告警、智能告警等。 作为商业产品,Flashcat 会结合产品的设计初衷,考虑各个功能的位置,以及它们之间的相互关系和互联互通。
协议:兼容opentelemetry协议、兼容prometheus生态;
opentelemetry协议和prometheus生态已经是云原生时代监控和可观测领域的事实标准,另起炉灶的做法已难以获得支持者。
架构:高可用、可伸缩架构;
Flashcat基于开源夜莺实现,开源夜莺在架构的高可用和可伸缩上做了设计。而高可用和可伸缩的重点是存储,夜莺采用的VictoriaMetrics时序存储,以及Flashcat自研和引入的组件,均遵循高可用和可伸缩的架构设计原则。
接口:支持API获取数据及OaC(Observability as Code);
Flashcat平台的数据支持通过API输入及获取。同时部分产品的配置既可以在前端完成,也已经可以通过配置化的方式实现批量修改和管理(OaC)。
API操作和类IaC(infrastructure as Code)的理念在国外的工程师中有广泛的市场,我们也相信在可观测性逐渐成为服务基础能力的趋势下,给用户更多的操作选择是必要的。
场景
不是有了丰富的食材和上等的炊具就一定能做好一道菜。
好的产品一定是在某个场景下符合了用户的需求,离开场景谈产品,属于无的放矢。稳定性保障特别是故障处理是Flashcat明确针对的场景。
结合场景实现产品是Flashcat在设计上做了最多考虑的地方,举例几点:
场景拆解
为了做好场景的产品设计,Flashcat对故障处理的场景做了拆解,拆解完后每个点上需要什么变得很明确。

让VIP的功能享受VIP的待遇
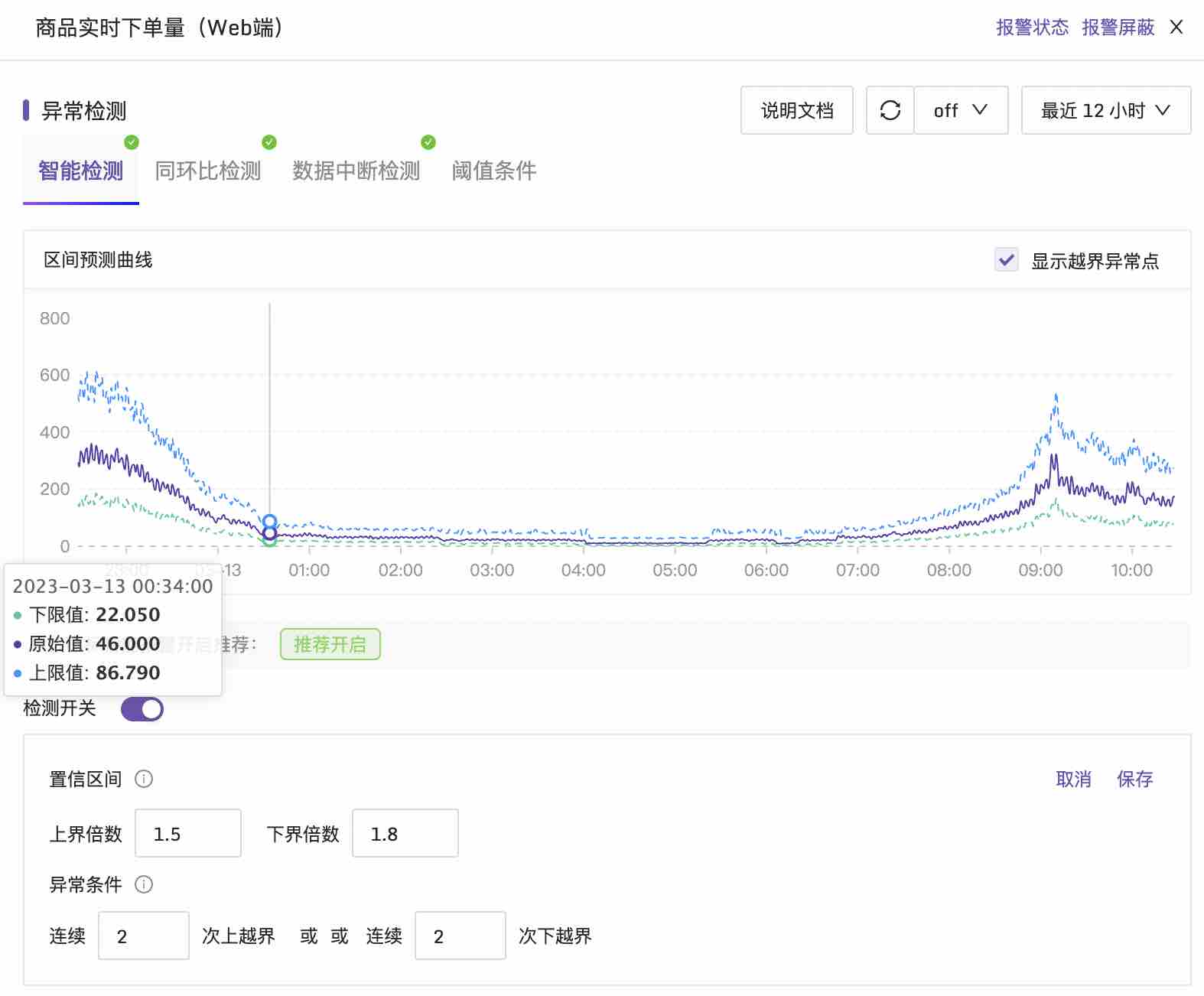
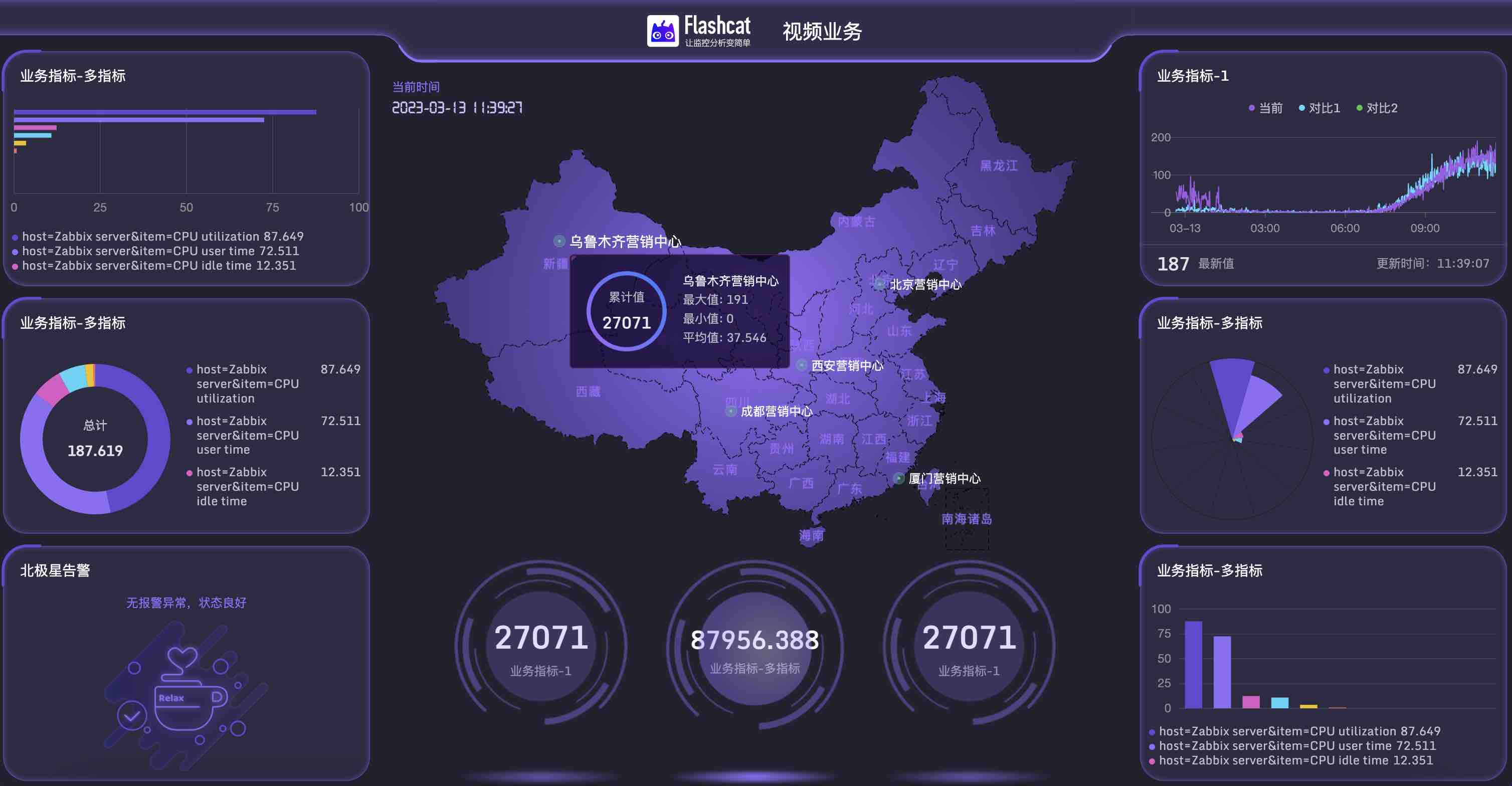
Flashcat里设计了北极星系统,用于量化业务指标的健康状态和用户体验的质量。之所以叫北极星就因为里面的指标就是稳定性工作的指引,是所有指标里的VIP。
作为VIP系统,Flashcat在产品实现上会让各种资源和功能围绕北极星指标来运行,而不是将指标所需的功能散落到各个功能系统里。
如北极星指标有预置的智能检测和智能报警功能,用户基本无需配置,如需调参或设置报警也是原地即可操作,无需切到告警系统里去设置。
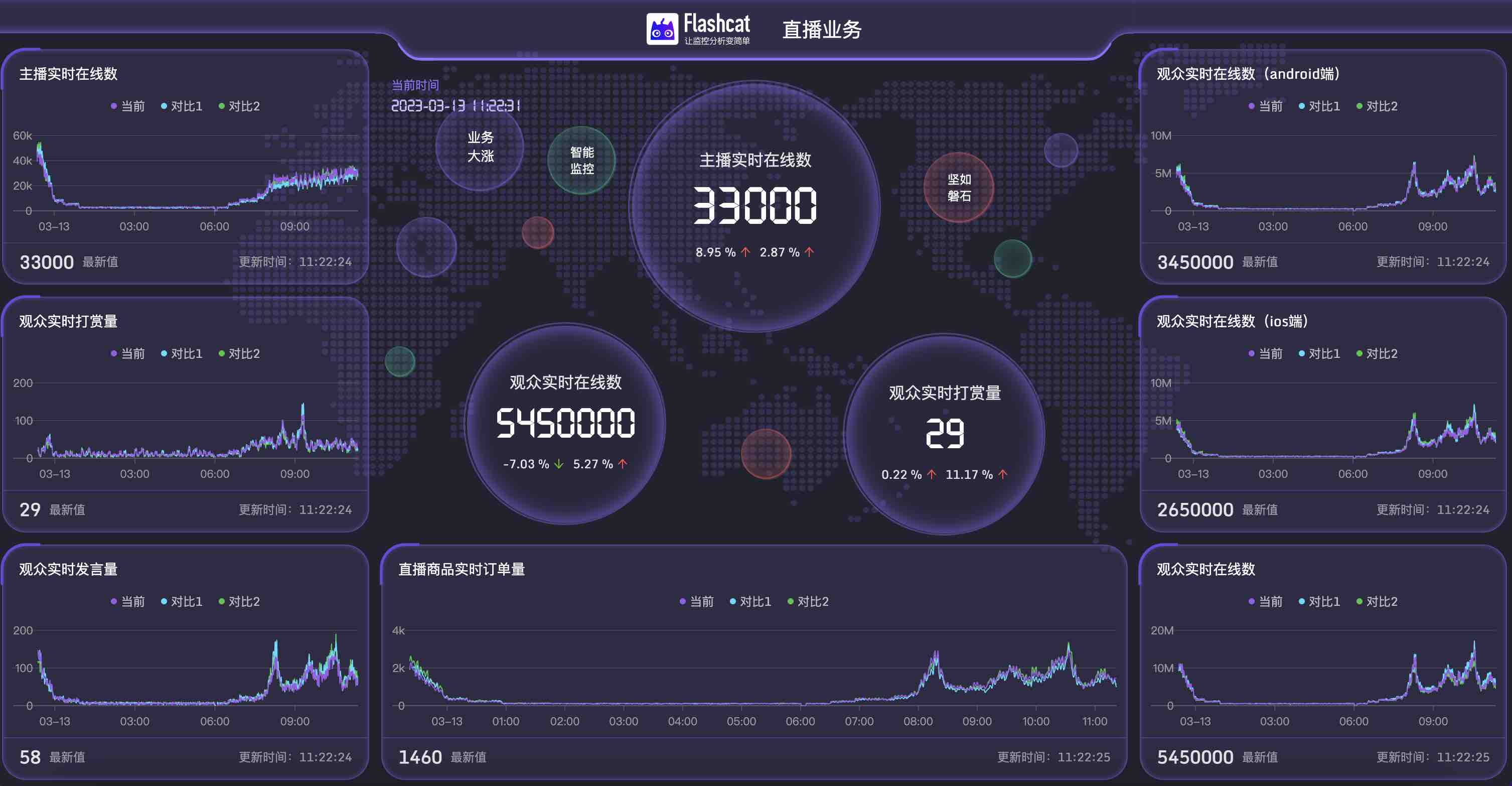
再比如,北极星指标实际就是最为核心的业务指标,无论是活动值守、日常巡检都是最佳选择,Flashcat针对北极星做了一键生成大屏的功能,让高端大屏的配置简单到极致。
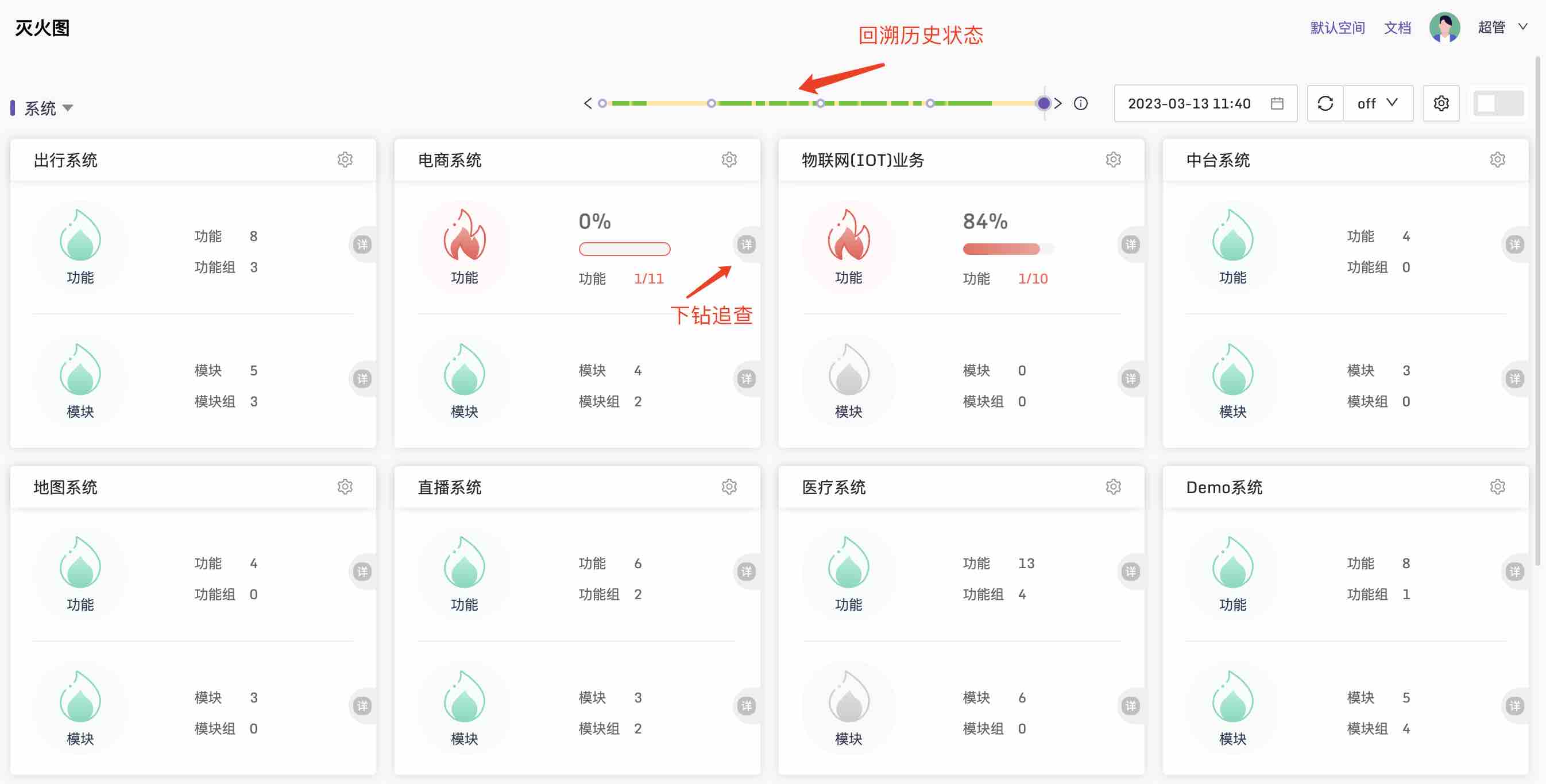
Flashcat中的另一个VIP系统是灭火图,可以量化IT系统层面的全局健康状态,并可以回放历史状态,产品设计上的考虑和北极星一致。
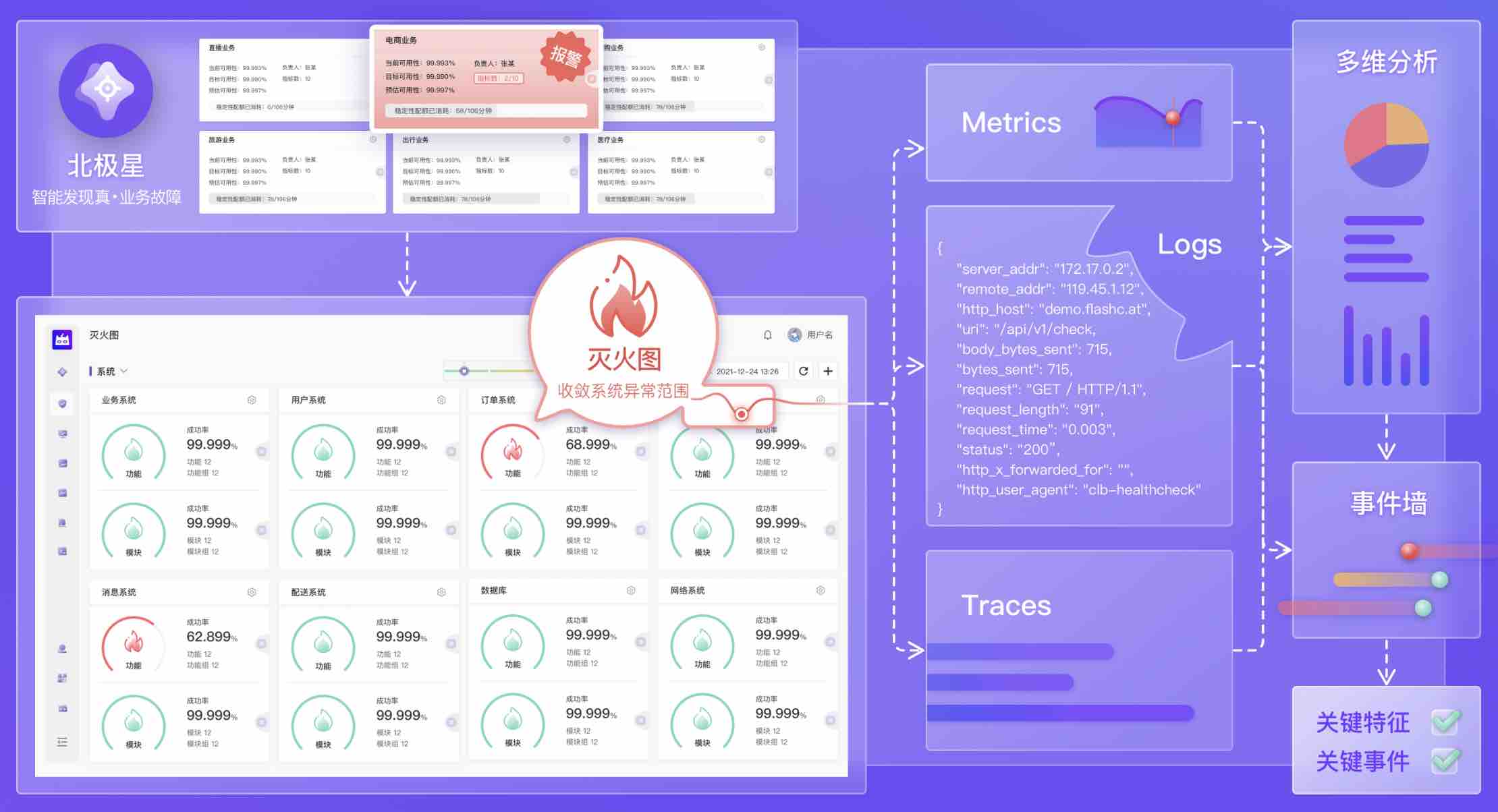
总之,产品上Flashcat让VIP功能享受真正的VIP待遇,以吸引用户的关注和重视。事实证明这种做法很有利于产品的落地和运行推广,他能产生的价值也是简单的将告警在告警系统里做个分级不可比的。
引导用户第一时间寻找故障的关键特征和引发故障的关键事件
故障处理中的首要原则是止损,而不是“根因定位”。
有效的止损途径是确定故障的关键特征和关键事件,并以此信息为基础来决策止损预案。而“根因定位”是止损后再考虑的方向。因此Flashcat会在故障定位的路径上引导用户去做关键特征和关键事件的分析,这也是Flashcat会持续增强的方向。
比如,北极星发生报警指示业务异常,此时可以做的事情是:
- 分析关键特征:看异常出现在什么范围,如果异常只局限在多活的某个单元内,切流即可快速止损;
- 分析关键特征:定位到受影响的模块,查看模块异常日志的分布,如异常日志只出现在模块的部分实例上或集中在某些来源ip上,则只要在容量允许的情况下摘除这些实例,或封禁异常的来源ip即可;
- 定位关键事件:定位到受影响的模块,查看相应模块的变更记录,将正在进行的变更回滚止损;
此时不应首先做的事情是分析异常出现的根本原因,如debug代码,分析代码逻辑等。这类工作可能严重影响服务的恢复,应该在止损后进行,或是以上分析手段都失效后的无奈选择。
预置最佳实践,并沉淀用户经验,让故障定位需要的下一步信息或应该看到的信息即时可得
Flashcat 中预置了典型的故障定位路径,如从异常的Metrics点击下钻查看具体的日志信息,从日志中依据traceid或接口信息向后trace,在trace到的异常模块上又能够跳转查看模块的Metrics或Logging信息。
同时,Flashcat也支持用户设置自定义的定位路径,如故障分析每到一步,下一步“老师傅”们会看哪一个信息,可以把这个下一步的入口牵引到这里,这样下一次即使“小白”来了,也能够顺利的走完这个定位过程。
如,在异常的灭火图模块上,配置事件墙(变更等关键生产事件)的入口,并预置好准确的参数,下次看到这个模块异常,就可以快速查看这个模块相关的变更信息。
这类可沉淀经验的产品能力,能够让产品越用越有价值,服务的稳定性保障能力也可以从依赖人,逐步转为依赖产品。
总结
以上是Flashcat产品设计的核心逻辑和部分细节上的考虑,整个产品是完全一体化的设计,这也是Flashcat区别于其它监控产品的最大不同。
Flashcat 会基于这些理念持续建设一个真正的统一监控,并服务好稳定性保障这个场景。


