

Kubernetes监控手册10-使用 kube-state-metrics 监控 Kubernetes 对象
写在前面
前面的系列文章我们花费了大量篇幅介绍了 Kubernetes 各个组件的监控指标,Node 节点上的 Kube-Proxy、Kubelet,Master 节点的 APIServer、Controller-manager、Scheduler、ETCD。但是,如果我想知道总共有几个 Namespace,有几个 Service、Deployment、Statefulset,某个 Deployment 期望有几个 Pod 要运行,实际有几个 Pod 在运行,这些既有的指标就无法回答了。
这些信息需要读取 Kubernetes 的 Metadata 才可以,有需求就有解法,kube-state-metrics(KSM) 就是专门解决这个需求。KSM 会调用 kube-apiserver 的接口,监听各个 Kubernetes 对象的状态,生成指标暴露出来,下面我们部署测试一下。
安装 KSM
KSM 既然要访问 APIServer,读取相关的信息,那就需要有权限控制,需要有 ServiceAccount、ClusterRole、ClusterRoleBinding 这些东西。在 KSM 的代码仓库中可以直接找到这些 yaml,而且还有 deployment 和 service 相关的 yaml,一步到位:
git clone https://github.com/kubernetes/kube-state-metrics
kubectl apply -f kube-state-metrics/examples/standard/
指标样例
KSM 在 service 文件中明显可以看到暴露了两个 HTTP 端口:
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
- name: telemetry
port: 8081
targetPort: telemetry
我们可以分别去请求一下,看看返回的内容:
curl -s ${ip}:8080/metrics
curl -s ${ip}:8081/metrics
8080 端口返回的内容就是各类 Kubernetes 对象信息,比如 node 相关的信息(我截取了一部分内容作为样例):
kube_node_created{node="10.206.0.11"} 1.641960541e+09
kube_node_annotations{node="10.206.0.11"} 1
kube_node_labels{node="10.206.0.11"} 1
kube_node_role{node="10.206.0.16",role="control-plane"} 1
kube_node_role{node="10.206.0.16",role="master"} 1
kube_node_spec_taint{node="10.206.0.16",key="node-role.kubernetes.io/master",value="",effect="NoSchedule"} 1
kube_node_spec_unschedulable{node="10.206.16.3"} 0
kube_node_status_allocatable{node="10.206.0.11",resource="pods",unit="integer"} 110
kube_node_status_capacity{node="10.206.0.7",resource="cpu",unit="core"} 4
而 8081 端口,暴露的是 KSM 自身的指标,KSM 要调用 APIServer 的接口,watch 相关数据,需要度量这些动作的健康状况,样例如下:
kube_state_metrics_watch_total{resource="*v1.Deployment",result="success"} 14567
kube_state_metrics_watch_total{resource="*v1.Endpoints",result="success"} 14539
kube_state_metrics_list_total{resource="*v1.VolumeAttachment",result="error"} 1
kube_state_metrics_list_total{resource="*v1.VolumeAttachment",result="success"} 2
抓取 KSM
了解了指标的暴露方式了,我们通过 prometheus agent mode 来抓取一下,就仿照之前抓取 apiserver、controller-manager、scheduler 的 scrape 规则就可以了:
- job_name: 'kube-state-metrics'
kubernetes_sd_configs:
- role: endpoints
scheme: http
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-state-metrics;http-metrics
- job_name: 'kube-state-metrics-self'
kubernetes_sd_configs:
- role: endpoints
scheme: http
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-state-metrics;telemetry
监控大盘
之前我整理了一个监控大盘,地址在这里,dashboard.json,当然,这个目录下还有其他的监控大盘,那是社区小伙伴贡献的,欢迎大家导入夜莺测试。
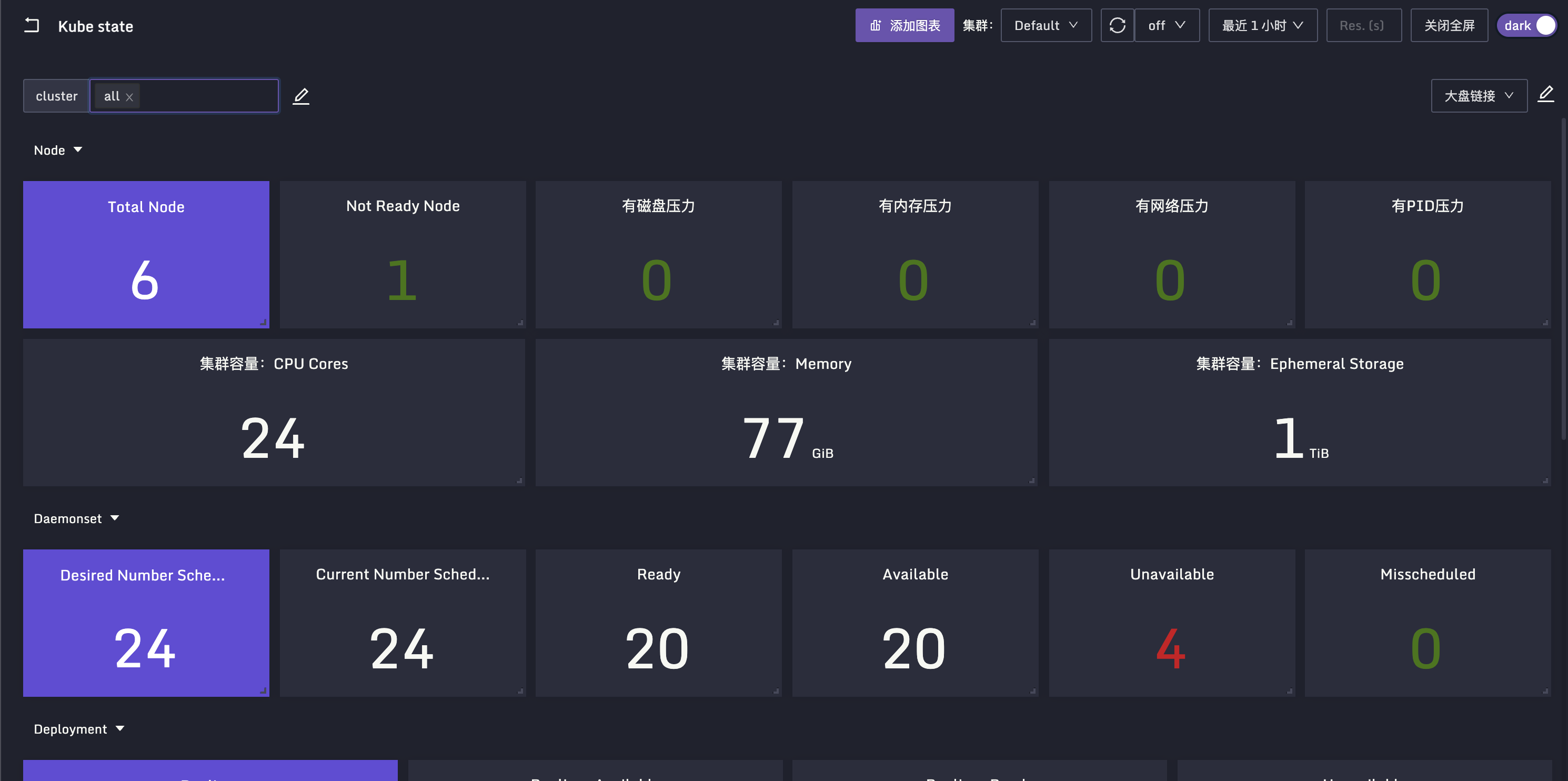
分片逻辑
KSM 要从 Kubernetes 中读取所有对象的信息,量是很大的,稍微大点的集群,调用 8080 端口拉取的数据会特别大,可能需要拉取十几秒甚至几十秒。最近发现 KSM 支持了分片逻辑,上面的例子我们使用单副本的 Deployment 来做,分片的话使用 Daemonset,每个 Node 上都跑一个 KSM,这个 KSM 只同步与自身节点相关的数据,KSM 的官方 README 里说的很清楚了,Daemonset 样例如下,不做过多介绍了:
apiVersion: apps/v1
kind: DaemonSet
spec:
template:
spec:
containers:
- image: registry.k8s.io/kube-state-metrics/kube-state-metrics:IMAGE_TAG
name: kube-state-metrics
args:
- --resource=pods
- --node=$(NODE_NAME)
env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
KSM 自身运行是否健康,也需要有告警规则来检测,官方也提供了相关的 alerting rule:
groups:
- name: kube-state-metrics
rules:
- alert: KubeStateMetricsListErrors
annotations:
description: kube-state-metrics is experiencing errors at an elevated rate in list operations. This is likely causing it to not be able to expose metrics about Kubernetes objects correctly or at all.
summary: kube-state-metrics is experiencing errors in list operations.
expr: |
(sum(rate(kube_state_metrics_list_total{job="kube-state-metrics",result="error"}[5m]))
/
sum(rate(kube_state_metrics_list_total{job="kube-state-metrics"}[5m])))
> 0.01
for: 15m
labels:
severity: critical
- alert: KubeStateMetricsWatchErrors
annotations:
description: kube-state-metrics is experiencing errors at an elevated rate in watch operations. This is likely causing it to not be able to expose metrics about Kubernetes objects correctly or at all.
summary: kube-state-metrics is experiencing errors in watch operations.
expr: |
(sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics",result="error"}[5m]))
/
sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics"}[5m])))
> 0.01
for: 15m
labels:
severity: critical
- alert: KubeStateMetricsShardingMismatch
annotations:
description: kube-state-metrics pods are running with different --total-shards configuration, some Kubernetes objects may be exposed multiple times or not exposed at all.
summary: kube-state-metrics sharding is misconfigured.
expr: |
stdvar (kube_state_metrics_total_shards{job="kube-state-metrics"}) != 0
for: 15m
labels:
severity: critical
- alert: KubeStateMetricsShardsMissing
annotations:
description: kube-state-metrics shards are missing, some Kubernetes objects are not being exposed.
summary: kube-state-metrics shards are missing.
expr: |
2^max(kube_state_metrics_total_shards{job="kube-state-metrics"}) - 1
-
sum( 2 ^ max by (shard_ordinal) (kube_state_metrics_shard_ordinal{job="kube-state-metrics"}) )
!= 0
for: 15m
labels:
severity: critical
过滤资源
KSM 提供了两种方式来过滤要 watch 的对象类型,一个是白名单的方式指定具体要 watch 哪类对象,通过命令行启动参数中的 --resources=daemonsets,deployments 表示只 watch daemonsets 和 deployments,虽然已经限制了对象资源类型,如果采集的某些指标仍然不想要,可以采用黑名单的方式对指标做过滤:--metric-denylist=kube_deployment_spec_.* 这个过滤规则支持正则写法,多个正则之间可以使用逗号分隔。
相关文章
- Kubernetes监控手册01-体系介绍
- Kubernetes监控手册02-宿主监控概述
- Kubernetes监控手册03-宿主监控实操
- Kubernetes监控手册04-监控Kube-Proxy
- Kubernetes监控手册05-监控Kubelet
- Kubernetes监控手册06-监控APIServer
- Kubernetes监控手册07-监控Controller-manager
- Kubernetes监控手册08-监控Scheduler
- Kubernetes监控手册09-监控ETCD
关于作者
本文作者秦晓辉,Flashcat合伙人,文章内容是Flashcat技术团队共同沉淀的结晶,作者做了编辑整理,我们会持续输出监控、稳定性保障相关的技术文章,文章可转载,转载请注明出处,尊重技术人员的成果。


