

科普篇:运维稳定性体系建设
稳定性体系建设是一个巨大的话题,实际上不止是运维人员关注,整个技术体系都非常关注,这个话题慢慢聊,今天我们先着眼在运维视角,看看如何构建稳定性体系。
🚀 运维稳定性是关注什么
运维,是对生产系统的运行维护,运维稳定性,自然是指生产系统的稳定性。比如网站、App、小程序等,都是要求7x24在线的,这些站点如果出问题,客户体验受到影响,可能会造成资损、舆论等严重后果。运维,是在保障业务连续性,更是在保障客户体验。
有很多老板只关注订单量是否下跌,支付交易量是否下跌,只看到冷冰冰的数字,其实稳定性的影响远远不止于此,比如某外卖网站,某个行动不便的老人可能依赖外卖小哥买应急药物,比如某打车软件,某个没车一族可能在等着上医院急诊,越是大型的站点,做好稳定性,其实更多的是一种社会责任了。
🚀 怎么衡量稳定性做的如何
客户在访问我们的站点或App的时候,从稳定性角度来看,有两个影响客户体验的指标,一个是成功率,一个是延迟。通俗点讲,就是要访问的数据是否都成功返回,要做的操作是否都成功完成,而且,响应要快,一个请求虽然最终完成了,但是花费了3秒以上,客户是无法忍受的,有的客户连1秒都无法忍受。
所以要衡量稳定性做的如何,重点就看成功率和延迟这两个指标就可以了。当然,这里要注意,从技术角度来看,全站有很多接口,如果只有全站平均的成功率或99分位延迟,就容易忽略一些问题,个别接口的指标可能被平均掉了。所以,通常我们既要统计全站均值,也要对重要接口单独统计。
🚀 有哪些因素影响了稳定性
影响站点稳定性的因素有很多,比如用户自己的环境问题(设备卡顿了、家庭带宽不稳定)、网络运营商的问题、机房的问题、接入层硬件的问题、接入层软件的问题、业务程序的问题、业务程序所在机器的问题、业务程序依赖的第三方服务的问题、人为误操作、上线变更、、、等等等等。
上面罗列的因素,有些因素可以用有限的几个指标来衡量是否出了问题,有些则需继续细分,有非常多的细节。多年的老运维会深有感触,故障五花八门,真的很难穷举,比预测股票涨跌都难,虽说故障复盘的时候我们都讲究举一反三,实际上,就算举一反十,也很难预测所有的场景。
🚀 通常有哪些手段保障运维稳定性
查理·芒格有句话,叫 “如果我知道我会死在哪里,我就永远都不会去!” 这是一种反向思维。同理,我们做稳定性,其实就是跟故障做斗争,如果我知道如何避免故障发生,如何降低故障影响,那就好了。那怎么才能降发生、降影响呢?
从大面上来说,包含五部分:量化风险常态预防、做好监控提前发现问题、做好可观测性及时定位故障原因、做好预案及时止损、做好复盘举一反三。这五部分工作其实就是围绕故障的生命周期开展的,《CTO药方:如何搭建运维/SRE能力》文中有一张故障生命周期的图,再次拖出来给大家参考:
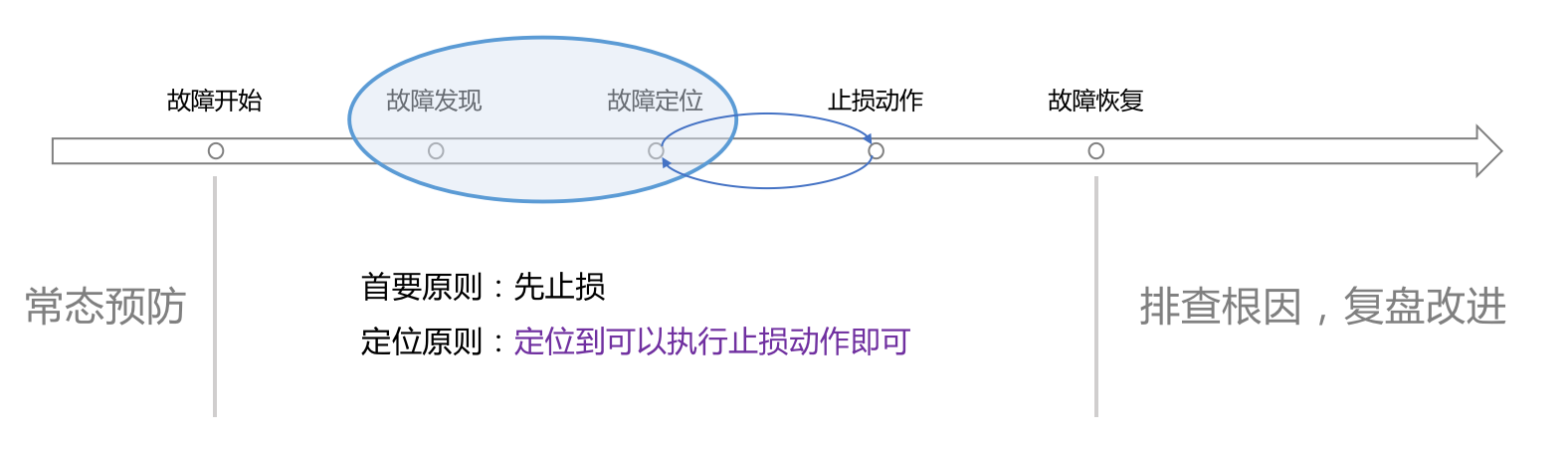
⭐️ 量化风险常态预防
这是降发生的核心手段。如果我们提前知道有哪些风险点,就可以尽快做出改进,避免问题发生。比如架构 review,提前发现架构上的不合理性,尽快改进;提前评估监控的完备性、可观测性体系的完备性,如果发现缺失尽快补齐;通过部署系统分析往常部署行为,看是否经常做一些风险高的事情,比如跳过审批,不分批次,批次之间检查时间太短;提前梳理预案完备性,看每个重要告警是否都对应预案,如果预案预置率太低,显然是有问题的。
另外,还可以组织定期放火演练,不定期得注入一些故障,来检验系统的健壮性。在预知的情况下的故障,相比未知的情况下的故障,显然更可控。
⭐️ 做好监控提前发现问题
要想通过监控覆盖所有的细节方面,显然是不合理的,但是覆盖客户的主流程体验,是必须的。换句话说,只要客户的主流程没问题,其他都是小问题,某个机器的CPU飙高了、磁盘用满了,在微服务、Kubernetes架构下,都不是太大的问题,机器挂掉了都可以把Pod自动漂走;但是如果客户主流程有问题,比如下单下不了了,即使监控系统此时告诉你没有告警也是有重大问题的。
当下业界的实践来看,很多公司都是奔着大而全的监控方向发展的,但是不知道大而全的标准是什么,疲惫不堪。其实业务监控、核心应用监控是四两拨千斤的做法,相比多配置几个SNMP oid、几个mysql status指标,业务监控、核心应用监控在最终价值贡献度上来看,无疑是更为关键的。
⭐️ 做好可观测性及时定位故障原因
通常,我们说监控的作用,是帮我们发现问题,告诉我们系统不正常了。而可观测性,是帮我们找到直接原因(注意是直接原因,知道直接原因就可以止损了,后续的故障复盘才需要找到根因)。可观测性数据的建设,更多的是面向分析的,数据不止是应采尽采,而是可采尽采,如果数据不完备,可观测性是无从谈起的。所以,只有metrics通常就不够了,traces、logs,都要上,统一的完备的可观测性平台,对稳定性体系的建设,就仿佛任督二脉。
⭐️ 做好预案及时止损
预案是一个预先设置好的流程动作,可能是个文档,也可能是个脚本,或者是页面上的一个按钮,或者chatbot里的一个命令。正常来讲,分布式系统可能遇到各种问题,对于一些预知的问题,是可以在架构层面解决的,如果架构层面不好解决或者成本太高,也可以做成预案,当故障发生的时候,也可以在很短的时间内完成止损。
不管是架构层面的鲁棒性设计,还是预案设计,其实都是需要提前预知到问题的,这需要对架构、infra、周边依赖有深刻的认知,外加一些通用经验。SRE团队理应成为这个方面的专家,给业务研发一些建议。
⭐️ 做好复盘举一反三
很多公司对故障的处理有一个明确的1-5-15要求,即:1分钟发现,5分钟定位,15分钟恢复,但是对故障的复盘,缺少明确的管理性的要求。而实际上,故障复盘也非常重要,Google 倡导 postmortem 5why,我觉得挺好的,核心就是问原因背后的原因,找到最本质的问题,有点第一性原理的味道。
另外,对事不对人,一切都是为了改进,而不是为了指责。
🚀 小结
本文是科普篇,让大家对运维稳定性有个基础认识。本文作者秦晓辉,Open-Falcon、Nightingale 创始研发,极客时间《运维监控系统实战笔记》作者,公众号 SRETalk 主理人,快猫星云创业合伙人,创业方向是稳定性保障方向。


