

Netflix SRE 实践概述
NetFlix 的 SRE 实践是如何的?大家应该很好奇吧。NetFlix 全部采用 aws 构建他们的流媒体服务,体量巨大,他们的 SRE 文化是什么?主要干什么事情?且听本文分解。
简介
每次加载您最喜爱的Netflix电影或系列时,背后都会发生很多事情。混沌工程、性能工程和网站可靠性工程(SRE)领域的工程师们努力确保这种魔法持续发生。
📊 Netflix 的一些性能统计数据
当它在2016年独自处于流媒体世界的顶端时…
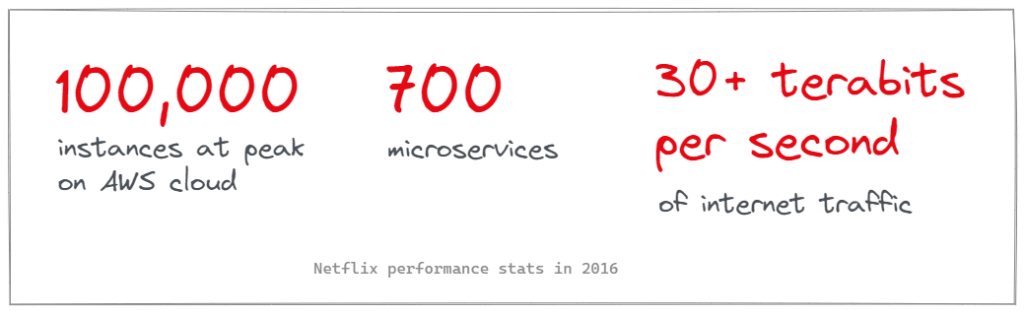
为了更好地理解,平均高清视频连接速度为8mbps,因此30+太比特/秒意味着任何时候都有3,750,000+个高清视频比特率的连接。
到2022年,这个数字肯定显著提高,但我无法获取他们当前的数字。
SRE在确保所有性能平稳运行方面发挥了至关重要的作用。
🔱 SRE如何融入Netflix文化
团队组建
Netflix的SRE团队被称为CORE(云运维可靠性工程),它属于一个更大的组别,即运维工程。

SRE(网站可靠性工程师)与SRE相关的专业角色一起工作,例如性能工程师和混沌工程师。
Netflix的SRE文化是怎样的?
Netflix的文化是自由和责任,这两者对于有效的SRE工作都很重要。
CEO里德·黑斯廷斯(Reed Hasting)采用了 radical candor 的方法(现在被金·斯科特普及),这对自由和责任之间矛盾的渴望产生了影响。
radical candor 法则是“批评他人因为你关心他们”。这可能使SRE更容易指出不良生产决策。
当同行没有没有遵循解决问题更合适路径时,SRE可以直接指出,而不会显得不礼貌。
开发人员必须遵循“you build it, you run it”的范式。 SRE充当开发人员的顾问来帮助研发人员实现“you run it”这部分。
当然,在问题影响生产时,SRE也将充当最后一道防线。
例如,测试服务崩溃会影响推送代码到生产环境的能力。SRE按照事件响应协议,会介入解决此问题。
大多数时间,Netflix 的 SRE 都是在解决那些没有直接解决方案的问题。在这种情况下,“RTFM”(read the fucking manual)可能行不通(译者注:没有既定的预案文档),愿意尝试和寻求新颖的解决方案可能会有所帮助。
修复可能需要几分钟、几小时、几天、几周或者几个月的时间——没有固定的解决时间——并且可能是其他团队没有时间完成的大型项目。
这需要阅读源代码和文档,寻找实验想法,运行实验,并测量结果。
可以作为单人任务完成,也可以组成一个暂时性的问题专项小组。
🧰 Netflix SRE 如何支持生产工具
工具精神
Netflix的运维工程师花费了多年时间开发“(paved paths)铺好的道路”(编者注:表示已经研发了很多工具)。这些路径旨在帮助开发人员利用先进的工具,而无需重新发明轮子。
这些已经有的工具包括:服务发现、应用程序RPC调用和断路器。
虽然有了很多工具,但是不会强制研发人员使用。开发人员被允许甚至被授权不用这些工具,研发人员可以为自己的服务创建其他工具。
SRE会帮助研发人员设计更好的工具,但是,注意了,SRE 提供的工具可能经受了Simian Army的攻击,已经比较稳定了,研发人员自己造的轮子,同样会被Simian Army攻击,就需要自己搞定这些稳定性因素了。
Simian Army是Netflix一套混沌工程测试工具,可测试系统在遭受内部攻击时其韧性如何。
这对于Netflix实践极端DevOps非常有用——you build it, you run it——工程师负责从头到尾地开发软件、部署和在生产环境中运行代码。
SREs将过去部署中最佳实践编码化以确保生产效果最优。
工具示例
在 SRE 世界里,NetFlix 最广为人知的是混沌工程里的 Chaos Monkey 工具。不过实际上,远不止此!
Netflix 的 SRE 还广泛使用以下工具:
- 🛠️ 金丝雀工具用于开发人员检查代码,确保没有性能问题
- 🛠️ 仪表板可用于审查服务性能,例如上游错误率、支持服务的警报
- 🛠️ 分布式系统跟踪可跟踪微服务生态系统中的性能
- 🛠️ 聊天室、值班系统和工单系统提供有趣的工程师级别支持工作
- 🛠️ 可操作警报-检查正确的事情,在适当时触发,在不需要时静音。
- 🛠️ Spinnaker - 允许使用多云设置进行蓝绿部署(非常强大)
- 🛠️ 预生产清单对进入生产之前每个方面进行评分。
以下是一个SRE编纂的工具-预生产检查清单。用于检查您的服务是否已准备就绪?

Netflix SRE 能力亮点
🔥 故障响应
Netflix工程团队的#1业务指标是SPS - 每秒开始次数 - 成功点击播放按钮的人数。
事故响应实践旨在确保此SPS指标的最高百分比。
以下是Netflix在其事故响应能力中确认的一些做法:
- 将正确的人带入房间,并确保他们能够解决故障
- 在事故期间记录所有内容,以帮助进行事后分析
- 事后分析不一定是“无过错”的——某些问题发生是因为某个人做了什么,但与其惩罚他们,不如让他们作为学习过程。
- 处理紧急情况的简短而简明的检查清单已经编码在易于访问的手册中。
- 开发人员可以为其服务指定度量标准,在达到一定阈值时由SRE处理。
🏎️ 支持性能工程师
对于 Netflix 运维来说,不仅要保证正常运行时间,还需要确保播放的稳定性和适当的性能水平。
需要提供持续良好的服务表现而非一次性胜利——用户应该获得可接受的 TTI 和 TTR。
这是这两个术语的含义:
- TTI(交互时间)- 用户可以与应用程序内容进行交互,即使并非所有内容都已完全加载或呈现
- TTR(渲染时间)- 屏幕上方的所有内容都已呈现
SRE支持性能工程师执行以下活动:
- 自动缩放用于按需扩展 - 节省资金与预购的本地计算机相比 - 用于编码、预计算、故障转移和蓝绿部署
- 处理涉及自动缩放的棘手问题,如资源欠配,以及粘性流量、突发流量和不均匀的流量分布
- 支持性能仪表板,覆盖负载问题、错误、延迟问题、资源饱和(例如CPU负载平均值)和实例数量。
👾 规模化运行混沌工程
Netflix以其广泛使用混沌工程而闻名,以确保所有上述指标(如SPS、TTI和TTR)都朝着正确的方向发展。
什么是混沌工程?
在分布式系统上进行实验,以增强对该系统在生产环境中抵御动荡条件的能力的信心
—— Nora Jones,前Netflix高级混沌工程师
混沌工程是一种能力,它在很大程度上基于 Netflix 在 2008 年至 2010 年初的工作。它建立在像单元测试和集成测试这样的常见测试价值基础之上。
混沌工作通过在服务之间的调用中添加故障或延迟,从这些旧方法中提升了一个档次。
为什么要这样做?因为它有助于发现和解决通常在服务调用另一个服务时出现的问题,例如网络延迟、拥塞以及逻辑或扩展故障。
将混沌引入 Netflix 工程,导致了一种文化转变,从“如果这个失败会发生什么”到“当这个失败时会发生什么”。
如何进行混沌工程
- 使用混沌猴工具进行优雅重启和降级
- 针对系统特定组件的有目标性混沌,例如 Kafka - “让我们看看删除主题时会发生什么”
- 级联故障检查-查看系统一部分失败如何触发其他部分的失败
- 以自动化方式向服务注入故障,并限制受影响用户数量-如果 SPS 风险低于可接受水平,则实验可以缩短
告别语
Netflix SRE们经历了所有这些惊人的壮举,以确保您可以轻松地在本周末连续观看您最喜爱的节目!
本文机翻自《Rundown of Netflix’s SRE practice》。
SRE的烦恼,我们懂
我们观察到很多公司都搭建了林林总总的监控系统,但是不成体系,故障定位不够快,老板很焦虑。我们提供的Flashcat平台通过集成这些既有的数据源,提供业务、技术双视角的全局稳定性视图和驾驶舱,让监控、可观测性体系化落地,出现问题也能快速定位,彻底去除故障焦虑。如果您有类似痛楚,快来联系我们交流试用吧!



