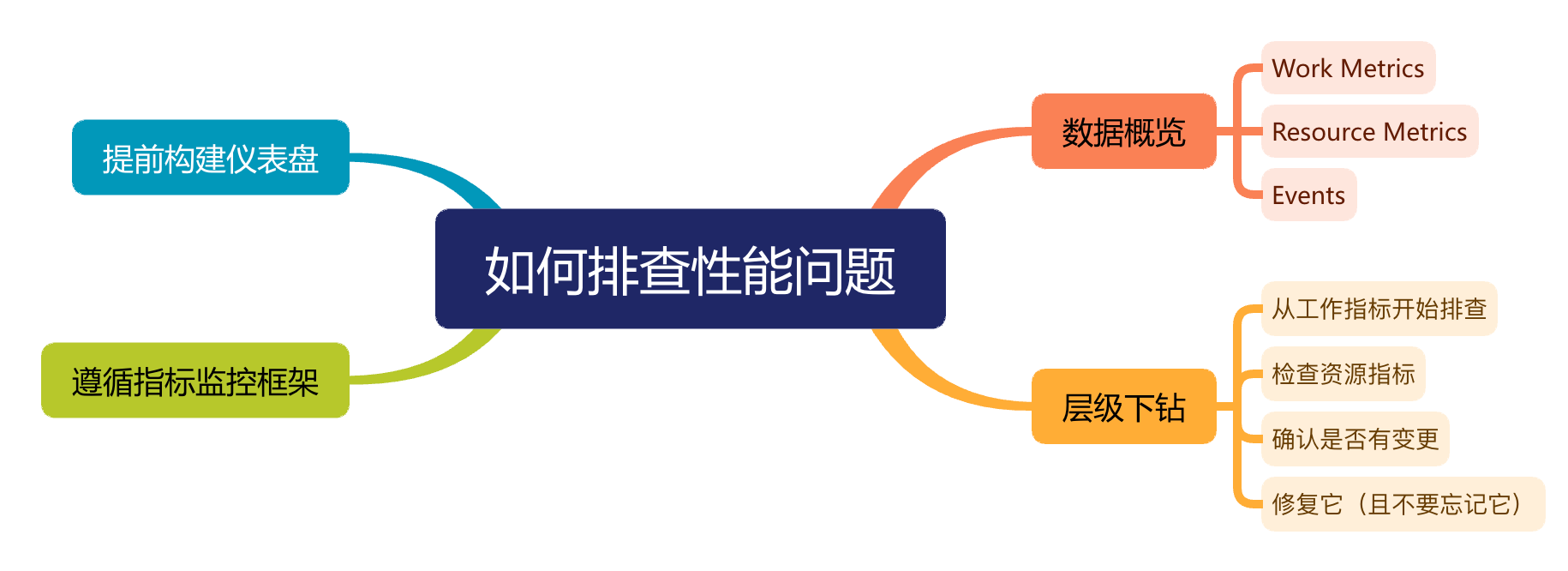
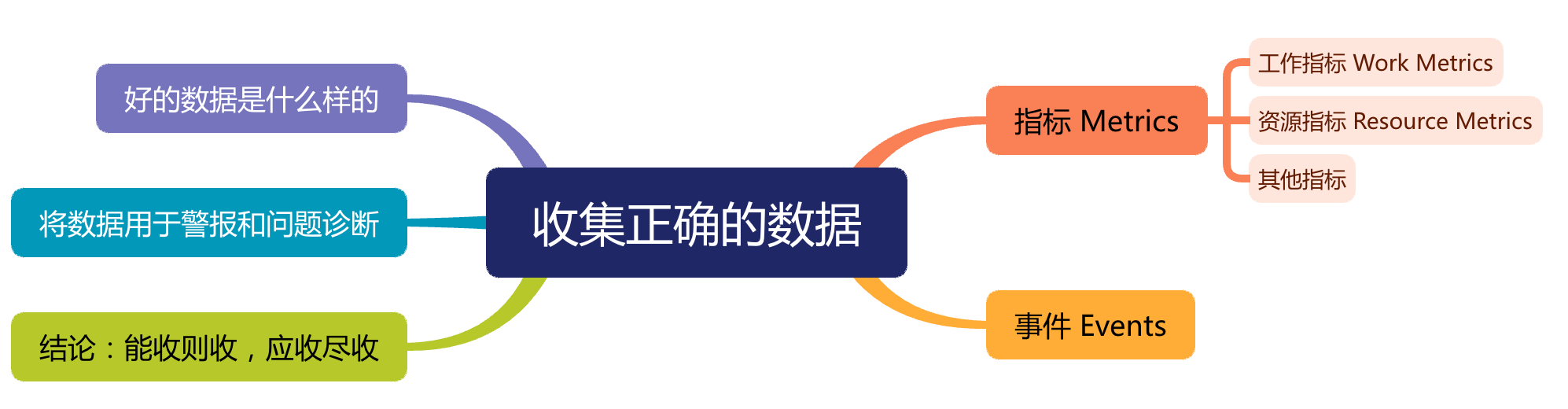
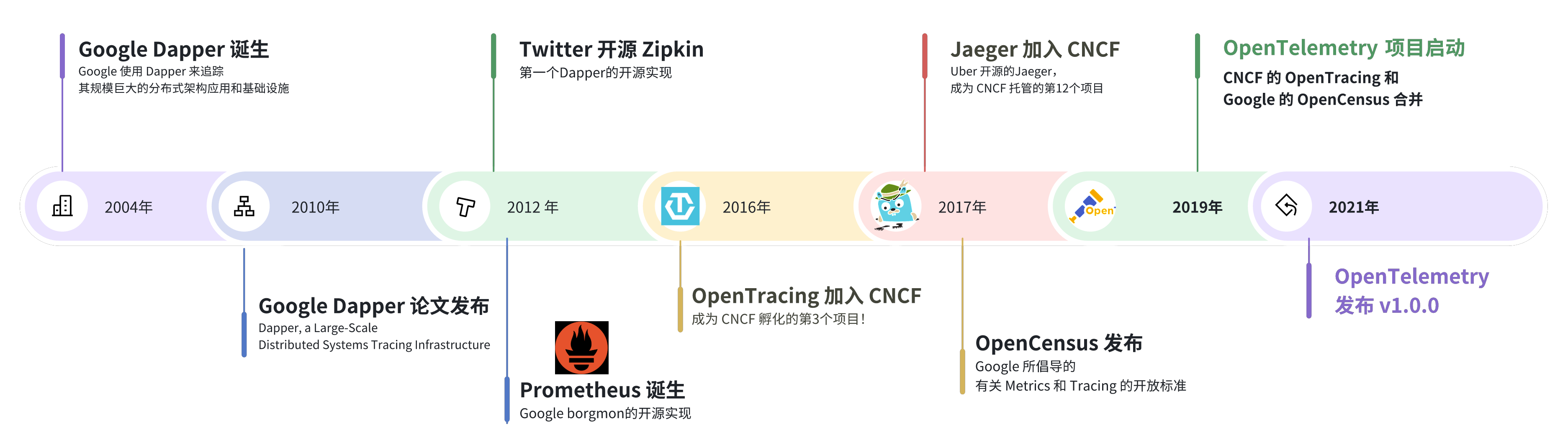
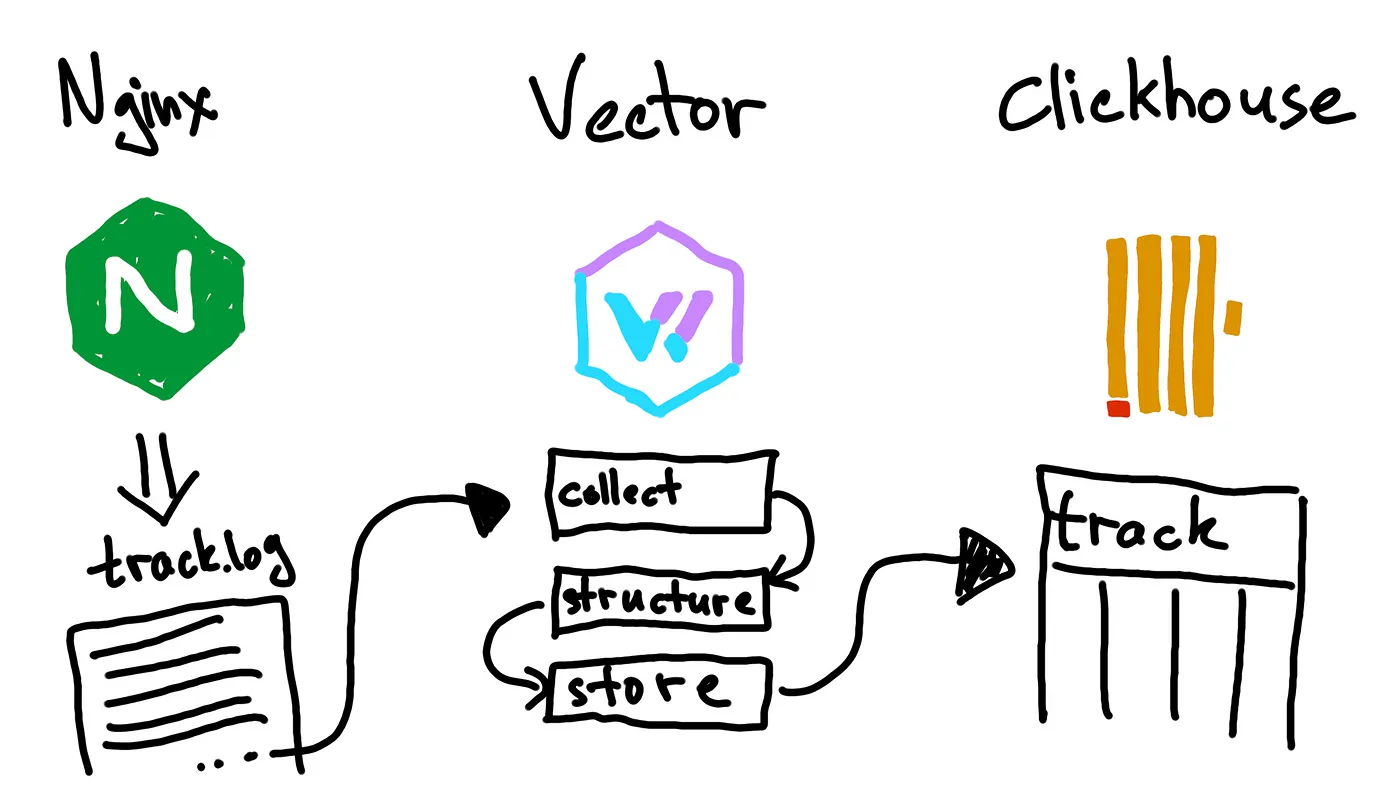
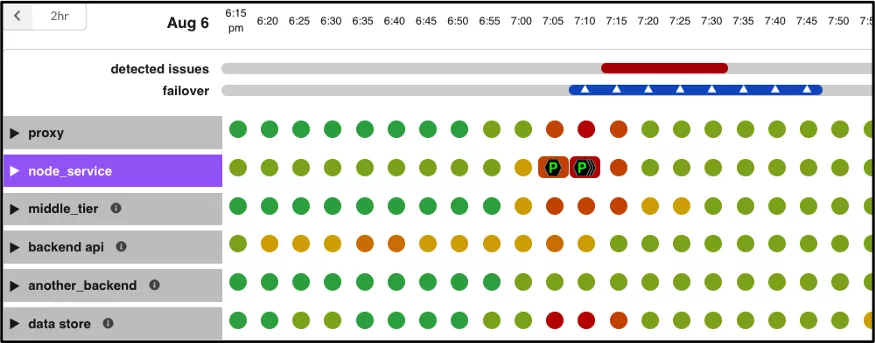
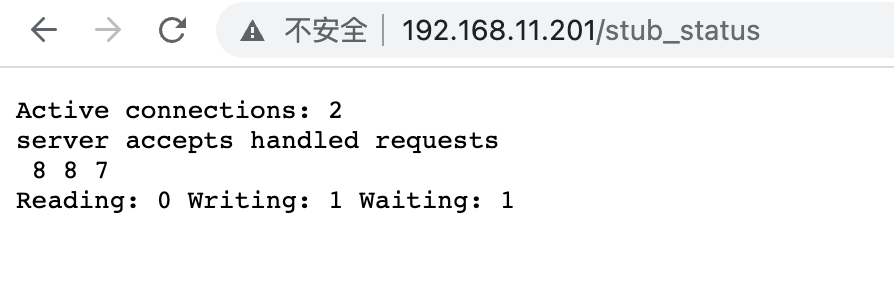
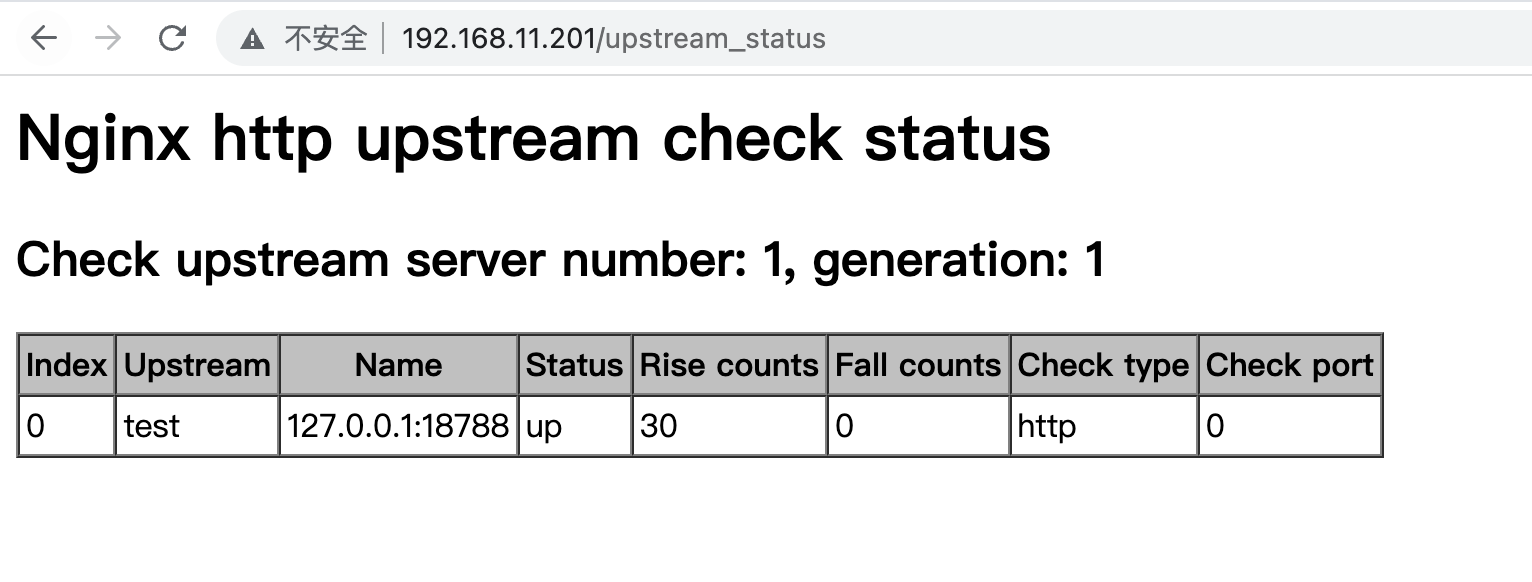
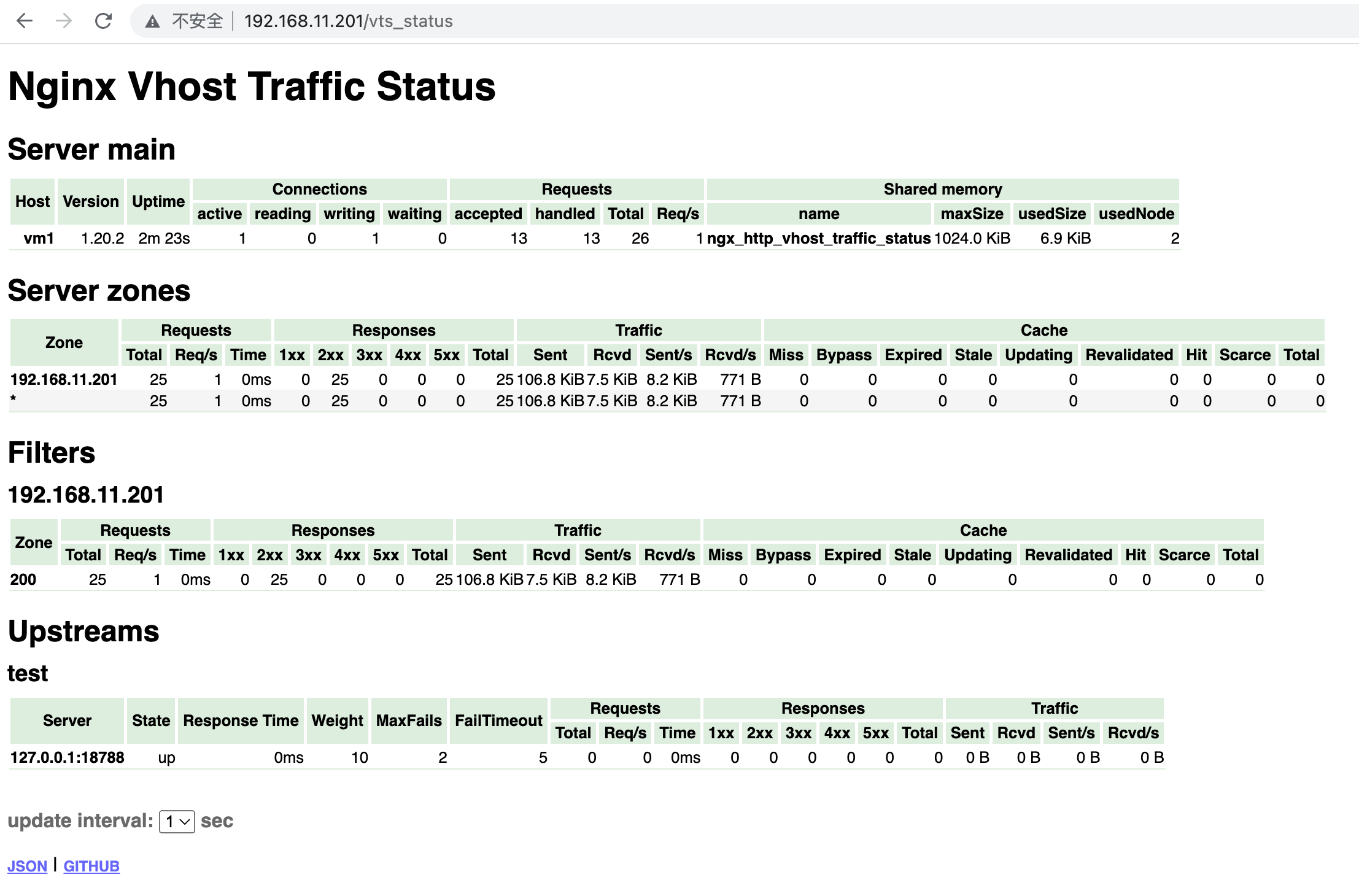
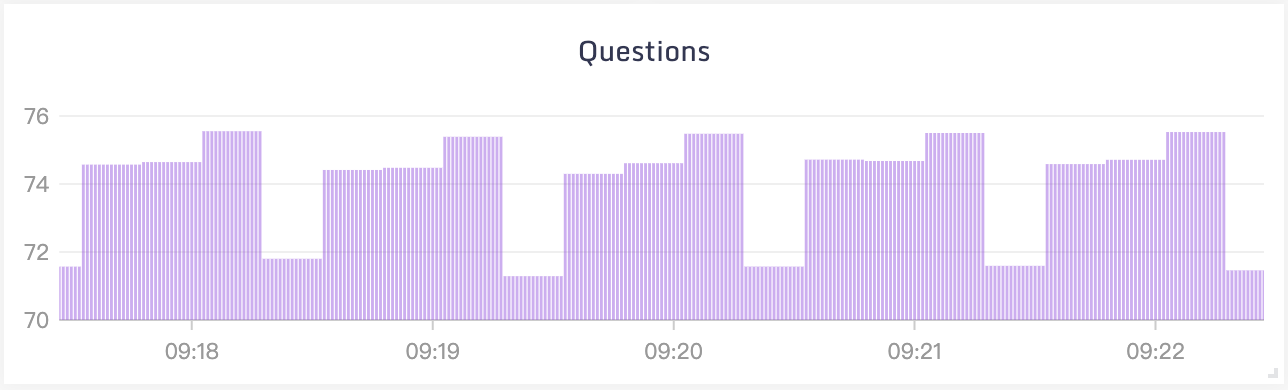
可观测性是一种了解和解释应用当前状态的能力,也是一种知道何时出现问题的方法。随着在 Kubernetes 和 OpenShift 上以微服务形式进行云部署的应用程序越来越多,可观察性受到了广泛关注。许多应用程序都有严格的承诺,比如在停机时间、延迟和吞吐量方面的 SLA,因此网络层面的可观测性是一项非常必要的功能。网络层面的可观测性由不同的编排器提供,有的是内置支持,有的是通过插件和 operator 提供。
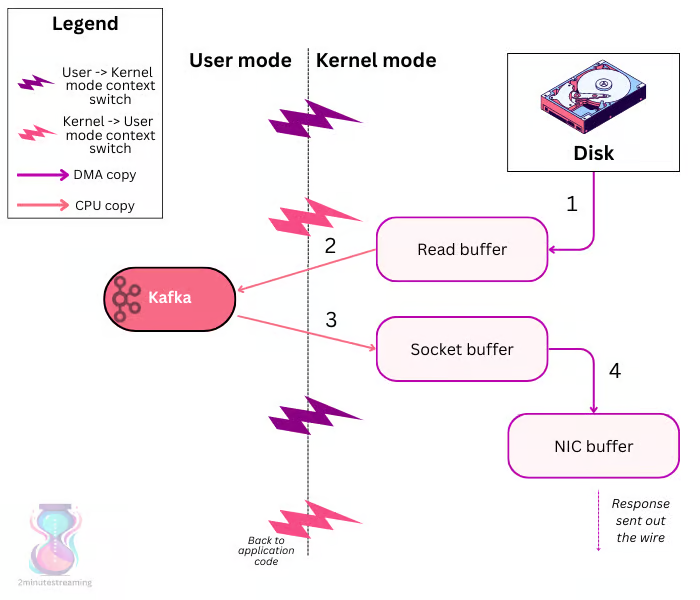
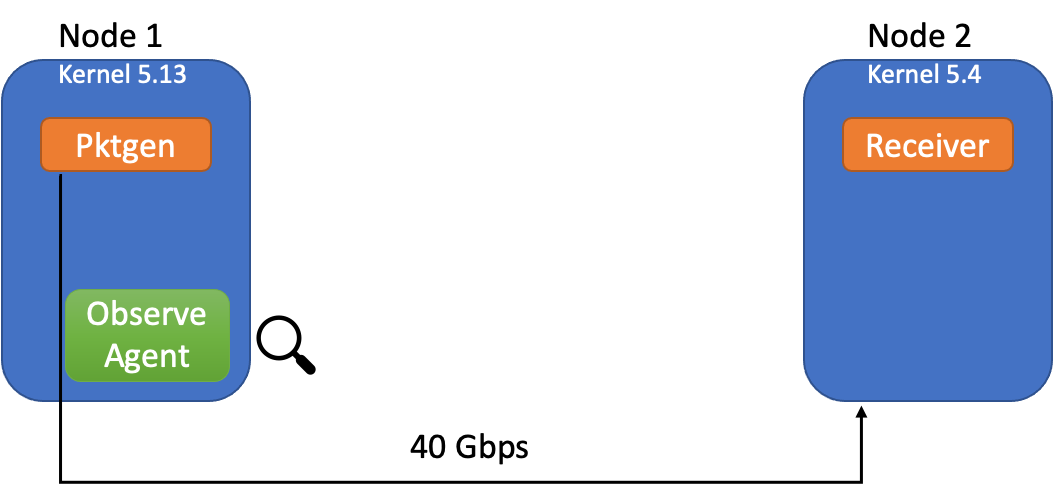
最近,eBPF(扩展的伯克利数据包过滤器)因其性能和灵活性成为在终端主机内核实现可观察性的热门选择。通过这种方法,可以在网络数据路径的某些点(如套接字、TC 和 XDP)上挂接自定义程序。目前已发布了多个基于 eBPF 的开源插件和 operator,每个插件和 operator 都可插入终端主机节点,通过云上的编排器提供网络可观察性。