
介绍
使用 Kubernetes 时,内存不足(OOM)错误和 CPU 限制(Throttling)是云应用程序中资源处理的主要难题。为什么呢?
云应用程序中的 CPU 和内存要求变得越来越重要,因为它们与您的云成本直接相关。
通过 limits 和 requests,您可以配置 pod 应如何分配内存和 CPU 资源,以防止资源匮乏并调整云成本。
- 如果节点没有足够的资源,Pod 可能会因抢占或节点压力而被驱逐。
- 当进程运行内存不足 (OOM) 时,它会因为没有所需的资源而被 Kill。
- 如果 CPU 消耗高于实际
limits,进程将开始受到限制。
OK,如何监控 Pod 快要 OOM 了,或者 CPU 快要被限制了呢?
核心要点摘要
- Kubernetes 中的 OOM 通常表现为容器被终止,常见退出码是 137,Pod 状态中可能出现 OOMKilled。
- CPU Throttling 不会像 OOM 一样直接杀死 Pod,但会让进程变慢,进而影响响应时间和吞吐。
limits和requests是判断资源风险的关键配置:limits 决定上限,requests 影响调度、资源保障和驱逐优先级。- 内存过量分配很常见,但当容器实际使用超过 request 且节点内存紧张时,Pod 可能被驱逐或进程被 OOM Killer 终止。
- 排查时应同时看 Kubernetes 事件、Pod 状态、Prometheus/cAdvisor 指标、cgroups 统计和资源配置。
关键术语说明
- OOM(Out Of Memory):进程申请或使用的内存超过可用范围,可能被系统终止。
- OOMKilled:Kubernetes 中用于标识容器上一次退出原因是 OOM 的状态。
- CPU Throttling:进程达到 CPU 限制后被限速,表现为应用变慢而不是被杀死。
- requests:容器声明的资源需求,影响调度和资源保障。
- limits:容器可使用资源的上限,超过内存 limits 可能被杀,超过 CPU limits 会被限流。
Kubernetes OOM
Pod 中的每个容器都需要内存才能运行。
Kubernetes limits 是在 Pod 定义或 Deployment 定义中为每个容器设置的。
所有现代 Unix 系统都有一种方法可以杀死进程,以此回收内存(没用空闲内存的时候,只能杀进程了)。这个错误将被标记为 137 错误码或 OOMKilled。
State: Running
Started: Thu, 10 Oct 2019 11:14:13 +0200
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Thu, 10 Oct 2019 11:04:03 +0200
Finished: Thu, 10 Oct 2019 11:14:11 +0200
退出代码 137 意味着该进程使用的内存超过允许的数量,必须被 OS 终止。
这是 Linux 中的一项功能,内核为系统中运行的进程设置 oom_score 值。此外,它还允许设置一个名为 oom_score_adj 的值,Kubernetes 使用该值来实现服务质量。它还具有 OOM Killer,它将检查进程并终止那些使用超过过多内存(比如申请了超过 limits 限制的数量的内存)的进程。
请注意,在 Kubernetes 中,进程可能会达到以下任何限制:
- 在容器上设置的 Kubernetes 限制。
- 在 namespace 上设置的 Kubernetes ResourceQuota。
- 节点的实际内存大小。
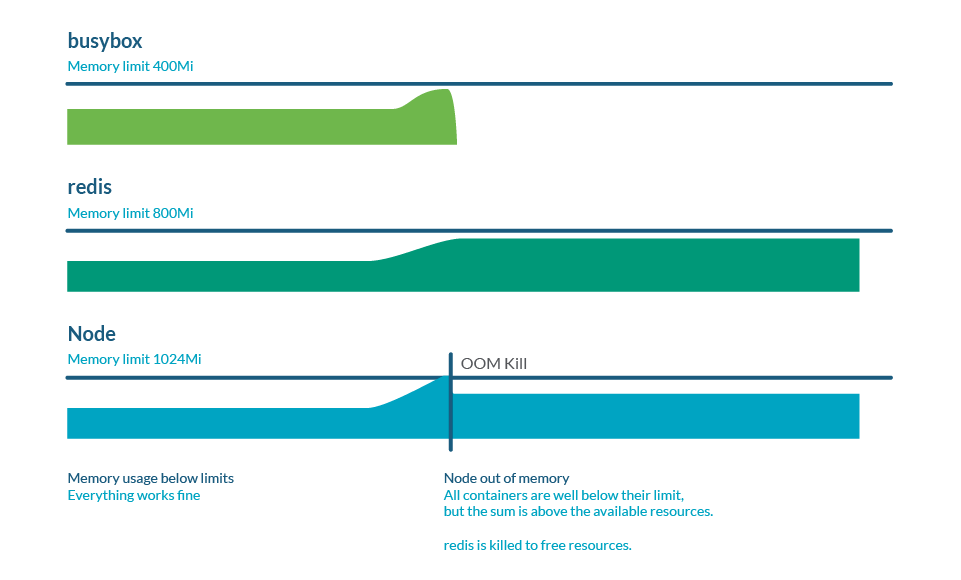
内存过量分配(overcommitment)
限制(limits)可以高于请求(requests),因此所有限制的总和可以高于节点容量。这称为过量分配,而且很常见。实际上,如果所有容器使用的内存多于 request 的内存,则可能会耗尽节点中的内存。这通常会导致一些 pod 死亡,以释放一些内存。
监控 Kubernetes OOM
在 Prometheus 生态中,使用 node-exporter 时,有一个名为 node_vmstat_oom_kill 的指标。跟踪 OOM 终止何时发生非常重要,但您可能希望在此类事件发生之前抢占先机并了解其情况。
除了记录 OOM 已经发生的次数,更重要的是观察容器资源使用量与 Kubernetes limits 的接近程度。原文给出的查询示例用于观察容器 CPU 使用量与 CPU limits 的比例:
(sum by (namespace,pod,container)
(rate(container_cpu_usage_seconds_total{container!=""}[5m])) / sum by
(namespace,pod,container)
(kube_pod_container_resource_limits{resource="cpu"})) > 0.8
Kubernetes CPU throttling
CPU 限制(throttling)是一种当进程即将达到某些资源限制时减慢速度的行为。与内存情况类似,这些限制可能是:
- 在容器上设置的 Kubernetes limits。
- 在命名空间上设置的 Kubernetes ResourceQuota。
- 节点的实际算力大小。
想想下面的类比。我们有一条高速公路,交通流量如下:
- CPU 就好比一条路
- 车辆代表 Process,每辆车都有不同的尺寸
- 多个通道代表有多个 CPU 核心
- request 将是一条专用道路,例如自行车道
这里的 throttling 被表示为交通拥堵:最终,所有进程都会运行,但一切都会变慢。
Kubernetes 中的 CPU 处理逻辑
CPU 在 Kubernetes 中通过 shares 进行处理。每个 CPU 核心被分为 1024 个 shares,然后使用 Linux 内核的 cgroups(control groups)功能在运行的所有进程之间进行划分。
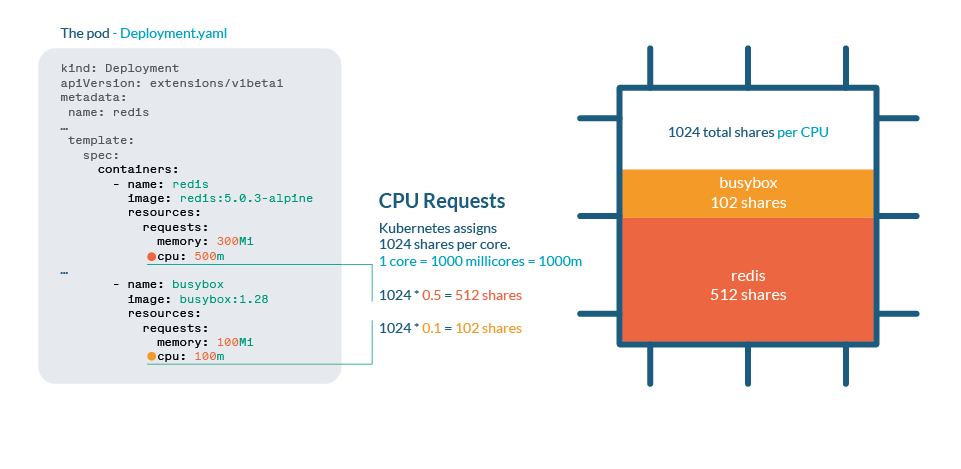
如果 CPU 可以处理当前所有进程,则无需执行任何操作。如果进程使用超过 100% 的 CPU,shares 机制就要起作用了。与任何 Linux 内核一样,Kubernetes 使用 CFS(Completely Fair Scheduler)机制,因此拥有更多份额的进程将获得更多的 CPU 时间。
与内存不同,Kubernetes 不会因为限流而杀死 Pod。
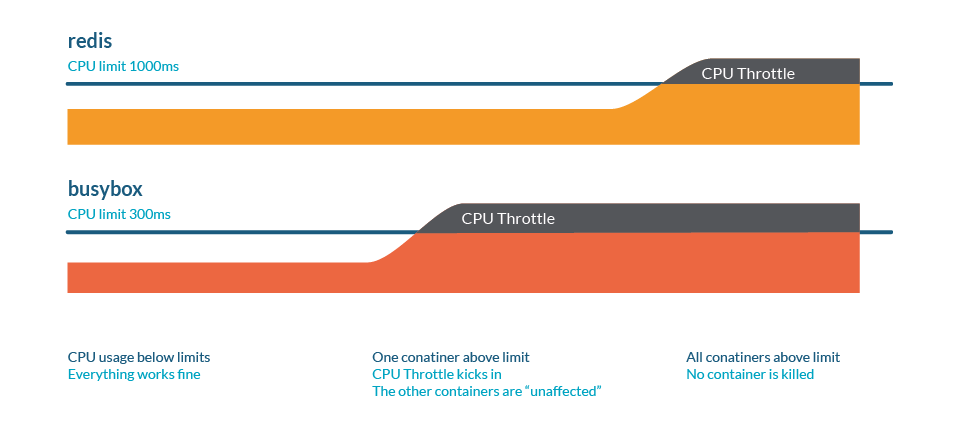
You can check CPU stats in /sys/fs/cgroup/cpu/cpu.stat
CPU 过渡分配
正如我们在limits 和 requests 文章中看到的,当我们想要限制进程的资源消耗时,设置 limits 或 requests 非常重要。尽管如此,请注意不要将总 requests 设置为大于实际 CPU 大小,每个容器都应该有保证的 CPU。
监控 Kubernetes CPU throttling
您可以检查进程与 Kubernetes limits 的接近程度:
(sum by (namespace,pod,container)(rate(container_cpu_usage_seconds_total
{container!=""}[5m])) / sum by (namespace,pod,container)
(kube_pod_container_resource_limits{resource="cpu"}))
如果我们想要跟踪集群中发生的限制量,cadvisor 提供了 container_cpu_cfs_throttled_periods_total 和 container_cpu_cfs_periods_total 两个指标。通过这两个指标,您可以轻松计算所有 CPU 周期内的限制百分比。
OOM 与 CPU Throttling 的排查路径
排查 Kubernetes 资源问题时,可以按下面的顺序收敛范围:
- 先看 Pod 状态和退出原因,确认是否出现 OOMKilled、Exit Code 137 或频繁重启。
- 再看容器的
requests和limits,判断是否配置过低,或是否与实际负载不匹配。 - 查看节点资源压力,确认是否存在内存、CPU 或磁盘压力导致的驱逐风险。
- 使用 Prometheus、cAdvisor 或 node-exporter 指标确认资源使用趋势,而不是只看单个时间点。
- 对 CPU Throttling,重点关注限流比例和应用延迟;对 OOM,重点关注内存增长趋势、OOM 事件和系统日志。
最佳实践
注意 limits 和 requests
Limits 是在节点中设置资源最大上限的一种方法,但需要谨慎对待,因为您可能最终会受到限制或终止进程。

准备好应对驱逐
通过设置非常低的请求,您可能认为这将为您的进程授予最少的 CPU 或内存。但 kubelet 会首先驱逐那些使用率高于请求的 Pod,因此就相当于您将这些进程标记为最先被杀死的!
如果您需要保护特定 Pod 免遭抢占(当 kube-scheduler 需要分配新 Pod 时),请为最重要的进程分配 Priority Classes。
Throttling 是一个无声的敌人
设置不切实际的 limits 或过度使用,您可能没有意识到您的进程正在受到限制并且性能受到影响。主动监控 CPU 用量,了解确切的容器和命名空间层面的限制,及时发现问题非常重要。
附
下面这张图,比较好的解释了 Kubernetes 中 CPU 和内存的限制问题。供参考:
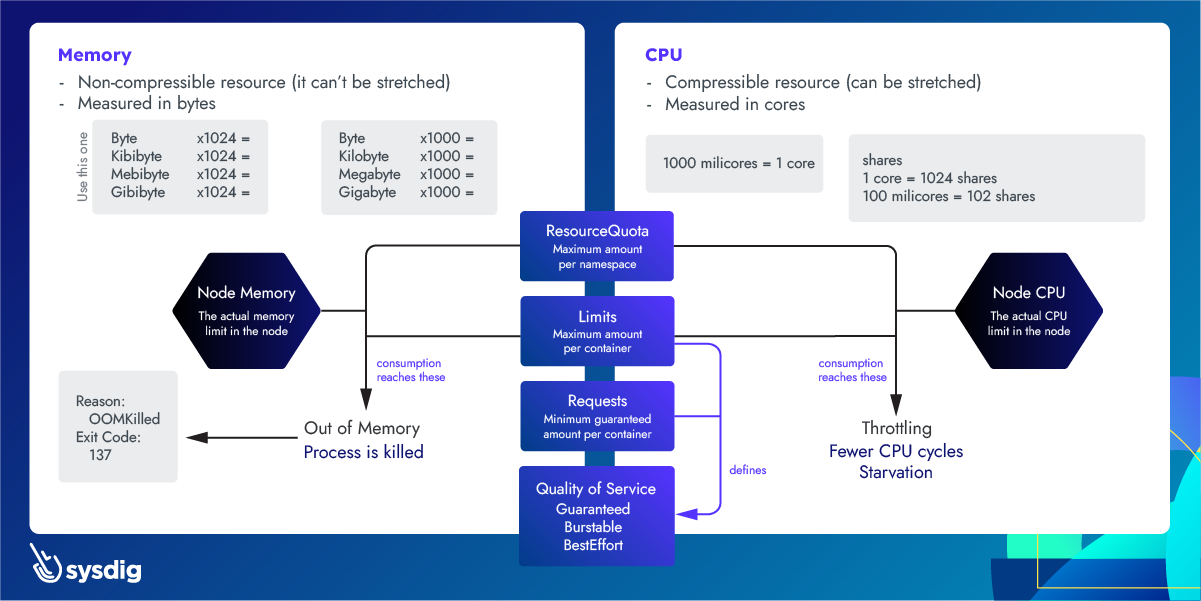
结论
Kubernetes OOM 和 CPU Throttling 都来自资源约束,但影响方式不同:OOM 会让进程被杀,CPU Throttling 会让进程变慢。治理这两类问题,不能只看告警是否触发,而要回到 requests、limits、节点容量、cgroups 统计和应用真实负载。合理配置资源、监控接近 limits 的趋势,并为关键 Pod 设置合适的优先级,才能在成本和稳定性之间取得平衡。
FAQ
Q1:Kubernetes 中 Exit Code 137 通常意味着什么? A:原文说明 Exit Code 137 通常表示进程使用的内存超过允许数量,被操作系统终止。在 Kubernetes 中,这类情况常与 OOMKilled 相关。
Q2:CPU Throttling 会杀死 Pod 吗? A:不会。与内存不同,CPU 被限流时 Kubernetes 不会因为 throttling 杀死 Pod,但应用会变慢,延迟和吞吐可能受到影响。
Q3:为什么 requests 设置太低也有风险? A:如果 requests 很低,kubelet 在节点资源紧张时可能优先驱逐那些实际使用量高于 request 的 Pod。对重要进程而言,过低的 requests 可能降低稳定性。
Q4:监控 OOM 只看 node_vmstat_oom_kill 够吗?
A:不够。node_vmstat_oom_kill 能看到 OOM 已经发生,但更好的做法是提前观察资源使用趋势、limits 接近程度、Pod 状态和系统日志。


