

最佳实践:SLO新解,一种行之有效的故障处理方法
近年来 SLO(Service Level Objective)的概念日趋流行,国外不少公司效仿 Google 的最佳实践落地 SLO,很多服务商也支持了 SLO(如 Datadog),甚至有创业公司专门聚焦 SLO 的产品化方案(如 NOBL9、Sloth 等)。
本文主要不是普及 SLO 概念,而是分析"跟风"SLO方法时可能出现的错误,并介绍一种应用于故障处理场景,并行之有效的"类SLO"实践。
Google SRE 方法中所倡导的 SLO 实践,我们称之为 CSLO(Classical SLO), 将在文末总结一些简要介绍,感兴趣可以参考。
注:本文提到的故障处理,特指业务或服务出现明显异常,需要进行紧急响应和快速恢复的情况。
CSLO的要点
先简单介绍一下CSLO相关的要点:
- 通常是一个量化的“目标”,用来表示某个Service可靠性要达到的程度;
- 基于该"量化目标"计算出一个时间区间内服务可以接受的错误预算(Error budget);
- 研发和运维等团队基于"错误预算"做出日常工作的决策,或某个阶段的工作重点,如是共同推进产品迭代还是共同推进稳定性治理,SLO达标则是前者,SLO不达标或即将不达标则是后者;
其中错误预算的消耗被放在很重要的位置,是决策的关键,工作协同是方法的重要目的。
CSLO常见落地方法
CSLO 涉及核心指标、用户视角的稳定性、可靠性目标、报警策略这些概念和方法,这些同时也是服务稳定性保障所需要的。
因此很多公司实际未必将CSLO的方法应用于工作协同,而是用于服务稳定性保障和故障处理场景。
但直接将CSLO作用于稳定性保障,可能会出现如下问题:
- 制定和调整难:CSLO首先要在多个团队间达成协议,这并不太容易,要调整则通常需要再协商,因此制定和调整难度都很大;
- 约束多:CSLO方法注重“错误预算”的消耗,所有相关工作都聚焦于此,包括报警和报警策略;强调从用户侧,从服务层来选取核心指标;不建议所有的功能/模块都纳入,指标要少而精;
SLO的制定和调整方法,以及相关的"约束"用于达成CSLO的"工作协同"目标时是正确的。
但用于服务稳定性保障,目的变了,方法就要跟着变,如果还完全遵照原来的方法去落地,就会发现束手束脚,难以达到理想的效果。
总结起来CSLO应用于服务稳定性保障,有可能出现的情况是:把坦克当交通工具,既笨重又难用。
服务稳定性保障中的SLO
下面我们变换思路,介绍一种把解决服务稳定性保障问题作为核心目标,把产生团队协同作为附加功能的SLO方法。
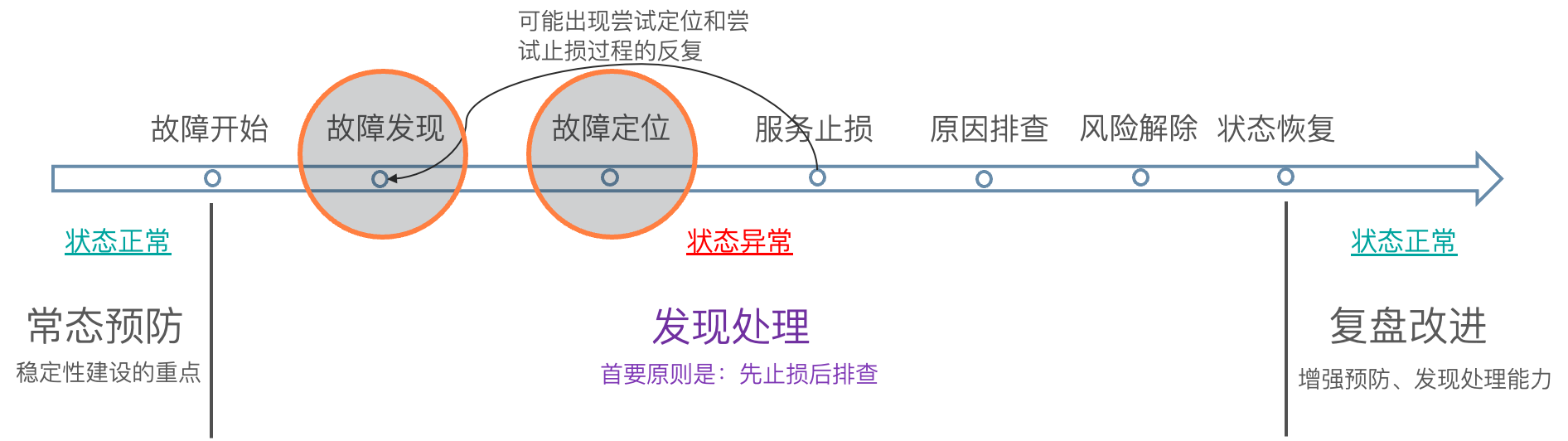
核心目的:故障发现和故障定位
- 将故障处理的过程拆分,主要聚焦在故障发现和故障定位两个环节;
- 故障发现对应一套量化的核心业务指标,这套核心业务指标的核心功能是量化并报警发现故障;
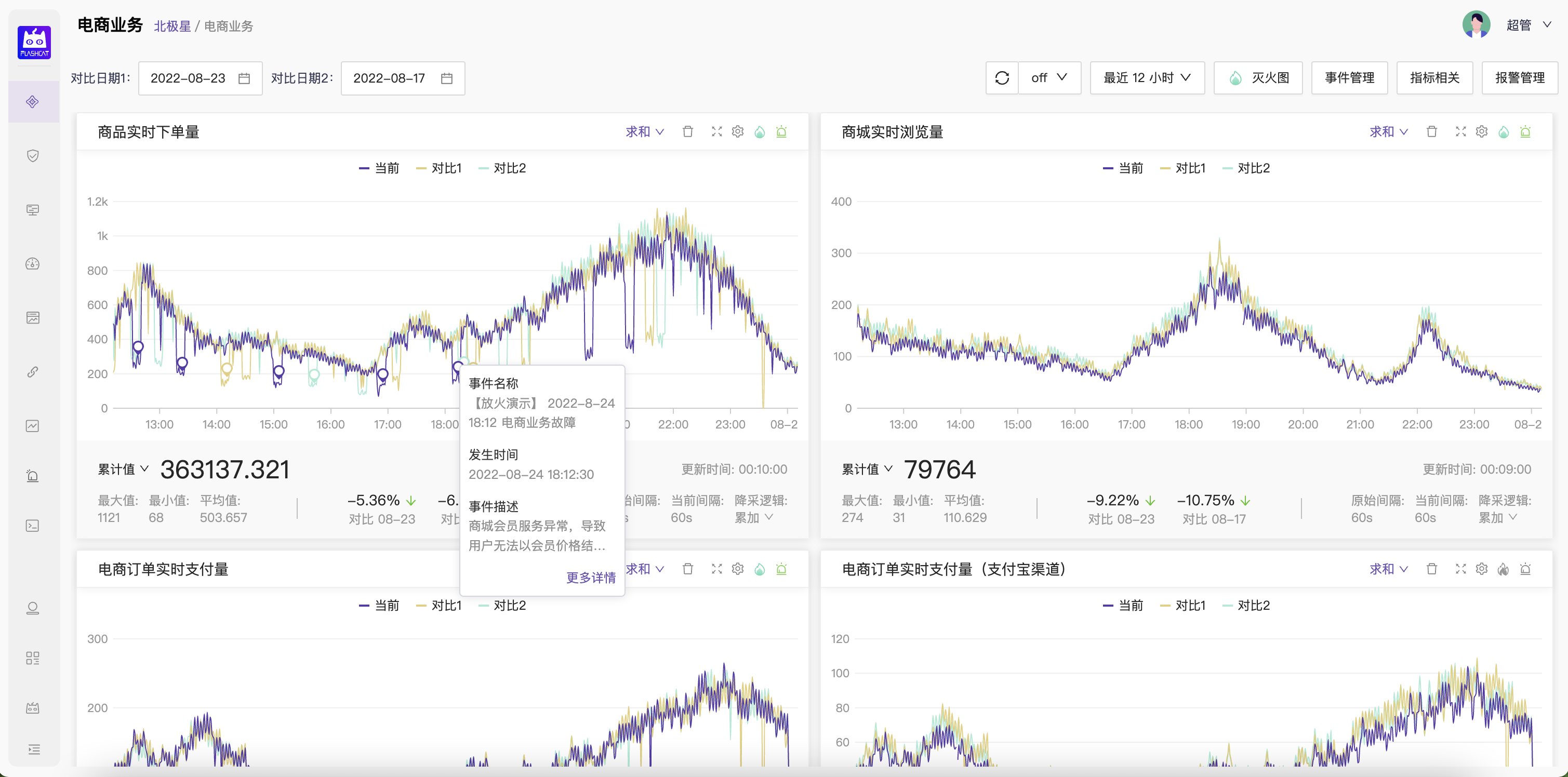
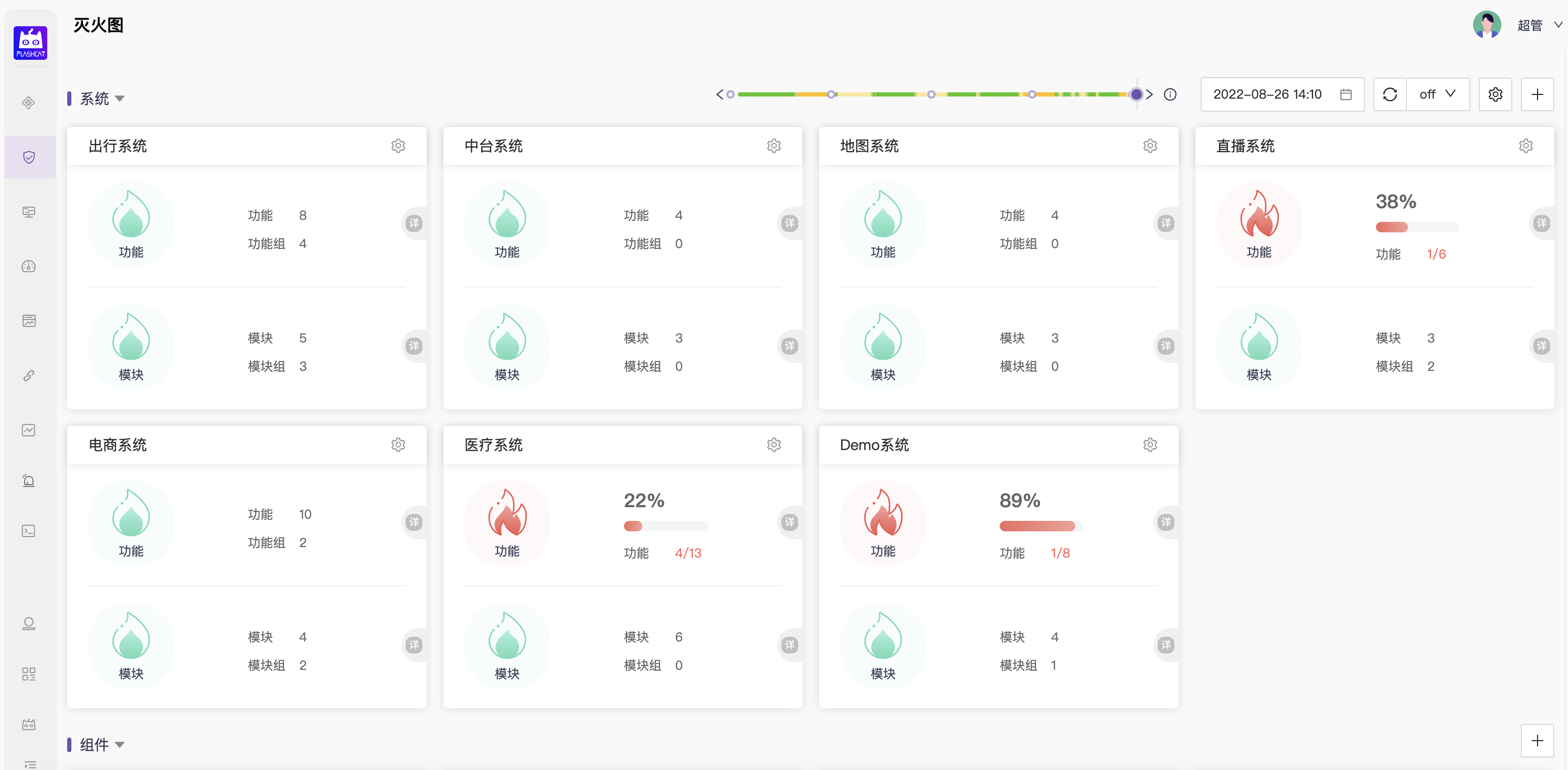
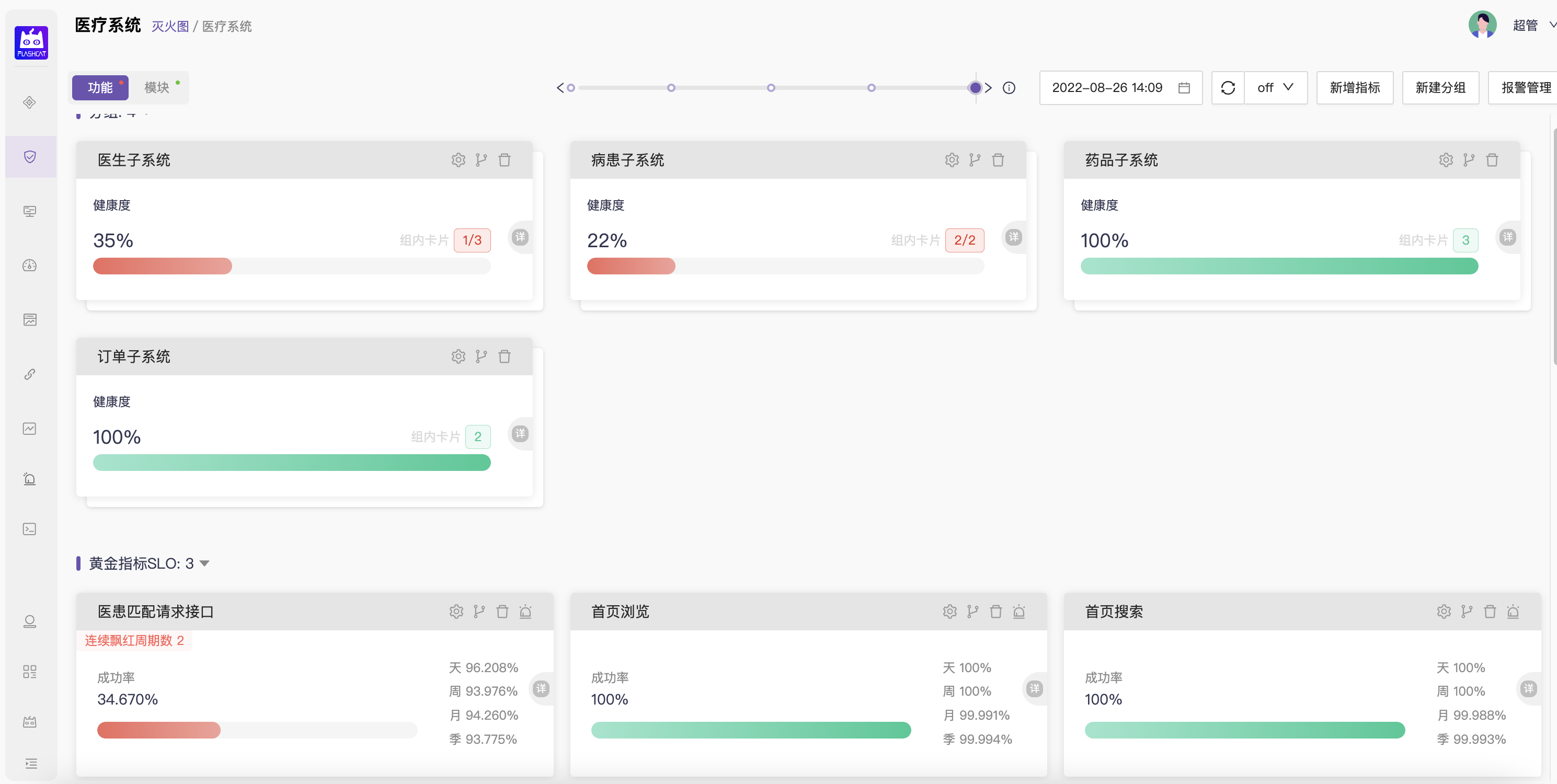
- 故障定位则下沉到服务(service)/系统层面,在这个层面通过三大黄金指标(请求成功率、流量、响应延迟)量化全部核心功能和核心模块的健康状态,通过设置一个简单的目标值来辅助快速收敛故障源的范围;
业务指标:通常是指业务运营相关的指标,如电商业务的在线用户数、订单量、支付量、在线商品数、GMV 等。
这两个层面的量化,理想情况下的效果是:
- 凡是出现了明显影响业务或用户体验的故障,故障发现层都及时产生报警;
- 凡是故障发现层产生了报警,故障定位层都出现飘红,准确的指向系统中的故障源;
如果以上任一效果没有达成,则说明需要对指标的选取、指标的准确性、指标的覆盖面或报警的准确性进行优化。
附加功能:基于稳定性配额的团队协同
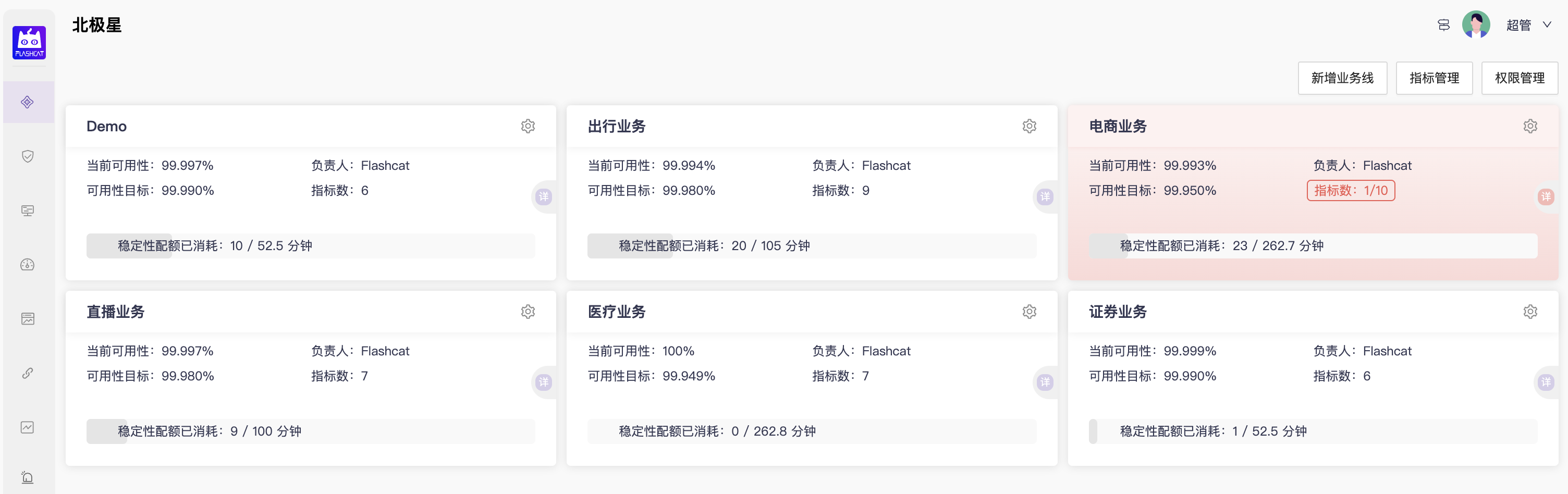
用于发现故障的核心业务指标首先要能够量化故障,既然这些指标已经量化了故障,那就可以基于这个量化来制定稳定性的目标(SLO)和配额(Error budget)。
计算公式:
全年可用性目标 =(365*24*60 - 全年故障时长配额)/ (365*24*60) * 100% = 99.**%
全年故障时长配额 = 365*24*60 * (1- 全年可用性目标)= x分钟
对比来看,这个方法和CSLO有以下几点相同和不同。
相同:
- 都对服务的健康状态进行了量化
- 都基于量化实现了预算配额管理,并基于此在各团队间产生协同
以上两点即是CSLO的核心方法和目标。
不同:
- 抽象了一个业务视角的目标,这一层准确来讲可以叫
BLO(business level objective,业务层目标),而不是服务层目标SLO; - 在故障处理的场景里,BLO的核心目的是发现故障,而不是团队协同;
- BLO层面的报警追求实时、准确、快速的发现故障,不考虑错误预算消耗的问题,更不基于错误预算来产生报警;
- 服务层(SLO)的差异则包括:
- 不再服务于团队协同决策,而是服务于故障定位;
- 量化的指标不局限于单个,使用相关的3大黄金指标更好(有利于做相关性分析);
- 覆盖面不再需要“克制”,而是要覆盖全部的核心功能和核心模块;
- 不注重这层的报警实现,取而代之用dashboard上的实时飘红效果来标识目标达成状态(而非错误预算的消耗),起到引导收敛故障源的作用即可;
以上异同的核心是:多了一个BLO层,这层的核心目的不是用来做团队协同,但覆盖了CSLO的核心目标和特点(会有相同的约束,如目标和配额的调整需要协商等),而将service层的SLO则没有这些约束,会更为灵活自由。
方法演进和分析
虽然故障发现这层建议用"业务指标",但其实这层如替换成CSLO的"服务指标",只要能做到在整体上从服务角度、从用户角度准确的量化一个服务的健康状态,也未尝不可。
那使用业务级别的指标,或服务级别的指标来量化和发现故障会有什么不同吗?
- 视角不同:服务级别是从用户的视角来看,而业务级别是从业务的运营者,或公司老板的视角来看;
- 指标形态不同:用户视角的量化指标通常是一个“百分比”,如用户请求的成功率。业务视角的量化指标通常是一个“量”,如实时的下单量;
- 报警难度不同:百分比类的指标通常设置一个简单的绝对阈值就可以准确报警,但"量"相关的值则需要通过类似同环比对比或智能检测来发现异常;
- 采集点不同:业务指标的数据通常来源于线上服务的数据库等存储中。而服务指标的数据采集点可能有很多,比如服务网关、app/pc端等;
- 数据准确性:业务指标如果是直接采自业务的存储,通常数据准确性极高,不会因为用户端和服务端的网络异常、服务攻击等问题影响其准确性;而服务指标则可能刚好相反;
使用哪类指标来做故障发现更适合自己的服务和环境呢?
很可能启动的时候偏向于采集容易的指标,而后向数据准确性去演进,最后的效果可能全部是业务指标,可能全部是服务指标,也可能是二者兼而有之。很认同CSLO的实施理念:先落地,后优化,逐步迭代。
就做服务稳定性保障同学一个普遍的痛点:难以说清楚稳定性工作对业务的价值。则严重推荐首选业务指标来做故障的量化和管理。
这样可以将稳定性的影响和业务实现了挂钩,使服务稳定性保障工作对业务的“直接”影响进行了量化(间接影响是巨大而不可估量的),能够从数据上证明稳定性对业务的支持是在持续变好还是变坏。
面向故障处理的SLO产品
以下的内容有一定的广告嫌疑,但确实能更好的理解这种SLO实践。
Flashcat 北极星 - 对应故障发现的SLO/BLO系统
Flashcat 灭火图 - 对应故障定位的SLO系统
结束语
本期文章分析了CSLO落地的可能问题,并介绍了服务稳定性保障中的SLO实践。
后面还将全面的介绍服务于故障处理场景的监控产品,介绍如何将最佳实践和经验沉淀到平台,如何联动企业内部已有的各种监控平台做到1+1>2,如何降低故障处理的门槛加速故障处理的效率。
合作进步
都看到这里了,相信你对监控体系的建设,对SLO的实践,对服务稳定性保障是感兴趣的。
我们正在招募更多的企业用户和我们一起完善云原生监控体系,一起打造极致的、面向数字化服务故障处理场景的监控产品。
如果您的企业对这方面有需求,欢迎通过以下方式联系我们,体验我们的产品。期待和热衷探求新知的你,和优秀的企业伙伴共同进步!
联系方式:
微信:myrainhua
邮箱:contact-us@flashcat.cloud
附录
-
CSLO相关概念:
- SLI:service level indicator,服务级别指标,是量化SLO的具体指标;
- SLA:service level agreement,服务级别协议,即SLO目标跌破后的行动约定;
- Error budget:错误预算,用于量化一定时期内可以容忍产生的错误量/失败量;
- SLO = SLI + 目标值;
- SLA = SLO + 目标值跌破后的协议行动;
- Error budget =(100%-SLO)x 时间总量或请求总量
-
CSLO主要特点:
- 通常是一个百分数(0~100%),如用户请求的成功率要达到99.9%、用户请求在100ms内完成的占比要达到90%;
- 强调从"服务"和“用户”视角来定义SLO,关注的是"Service"所提供的核心功能是否达标;
- 用于量化SLO的指标不应过多,但要能代表服务整体的健康状态,覆盖用户的核心流程;
- 核心目标是基于"错误预算"来做团队协同;
-
CSLO主要理念:
- 量化目标,用数据说话;
- 合适就好,不能盲目的追求过高甚至于完美的稳定性目标(必要性和投入产出比);
- 设定SLO的目的是为了以“量化”的方式驱动科学决策,而非定责;



