

手把手融汇贯通网络流量分析
我们生活在一个数据大爆炸的时代,网络是互联网的载体,网络流量分析也是技术人员日常最依赖的troubleshooting手段。全球最具权威的IT研究与顾问咨询公司(Gartner)曾在一份报告中明确指出“信息安全本质上是一个大数据分析问题”,而全流量分析系统就是一个大数据分析的典型技术实践。
全流量分析系统,在企业必要网络路径中进行所有流量的获取操作,通过这些流量可以对用户访问质量进行深度分析,为应用提供端到端可用性数据支持,也可以通过对流量分析,完成异常攻击的检测,并且可以根据检测结果和网络中的防火墙、入侵检测系统、入侵防御系统进行联动。
本文我们会引导大家,深入了解全流量分析系统的技术细节。整个网络流量分析系统从工作内容上基本可以分为如下两部分:
- 流量采集
- 流量分析
下面我们就此详细展开,分别来探讨这两方面内容。
进阶:快猫星云是一家云原生智能运维科技公司,由开源监控工具“夜莺监控”的核心开发团队组成。快猫星云打造的云原生监控分析平台——Flashcat平台,旨在解决云原生架构、混合云架构下统一监控难、故障定位慢的问题。Flashcat平台支持云原生架构、公有云、物理机/虚拟机、混合云等多种环境的监控数据统一采集,集告警分析、可视化、数据分析于一体,从业务到应用到基础设施,打通metrics、logging、tracing、event,提供立体的、统一的监控解决方案。
网络流量采集
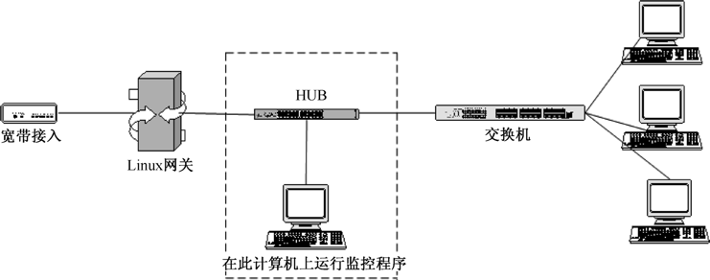
我们先从古老的共享式网络环境说起,在这种环境下,我们可以在交换机和网关之间加入一个HUB,因为每一台和HUB连接的机器都可以监听其他机器的通信,如果想获取某条通信链路上的数据包,就把通信双方设备同时接入到一个网络HUB或者交换机上,然后将抓包工具接入到HUB接口,并设置抓包工具的接口为混杂模式(在非混杂模式下,网卡会自动丢弃目标MAC不是自己的数据包;而混杂模式则可以捕捉所有流经本机网卡的数据包,包括不是发给自己的),就可以获取到他人的通信数据了,非常简单,基本无须配置,如图33-1所示。
但是在现如今的纯交换网络以及大流量环境下,采用HUB这种方式已经完全不可取了,现在我们大都采用如下解决方案。
方案一:端口镜像
SPAN(Switched Port Analyzer)直译为端口分析器,是一种交换机的端口镜像技术。为了对一个或多个网络设备端口上的流量进行一些网络流量分析(如IDS产品,网络分析仪等),通过SPAN可以把交换机、路由器上的一个或多个端口的进、出方向的数据帧完全相同地复制到一个或多个其他端口,这个过程就是端口镜像,即Port Mirroring。
如图33-2所示,端口1为镜像端口(mirror-port),端口2为被镜像端口(monitor-port),因为可以通过端口1监控到端口2的流量,所以有时我们也称端口1为监控端口,端口2为被监控端口。对于绝大多数交换机产品(如Cisco、华为),一旦某个端口被设置为镜像端口,那么接收该端口数据的流量分析服务器将无法通过该端口发送数据包到网内其他机器。也就是说,变成了单向接收模式,系统无法通过这个端口发送数据包到其他服务器或主机,而导致无法对它们进行控制。但是我们可以在流量分析服务器中再加入一块网卡,负责与网内其他机器进行通信。假设交换机镜像端口为E1/0/1,被镜像端口为E1/0/2,以下是配置过程示例。
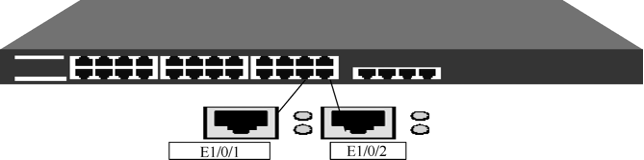
设置端口E1/0/1为端口镜像的观测端口:
[SwitchA] port monitor ethernet 1/0/1
设置端口E1/0/2为被镜像端口,对其输入/输出数据都进行镜像:
[SwitchA] port mirroring ethernet 1/0/2 both ethernet 1/0/1
整体架构基本如图33-3所示。
端口镜像技术的优点:
- 低成本部署和应用。
- 可以通过任何与交换机连接的系统进行远程配置。
- 可以获取到交换机内部交换的数据帧。
缺点:
- 接收/发送(RX & TX)信号都被拷贝成一个发送信号(TX signal)。
- 如果端口利用率超过了SPAN链路的能力,报文将被丢弃。
- 物理硬件和媒介错误相关的报文会被丢弃,影响某些类型的统计和分析。
- 拷贝端口上所有在进行交换的数据帧,会增加交换机的CPU负载。
- 交换机中SPAN端口数据的优先级低于正常端口间的数据优先级。
方案二:无源分光
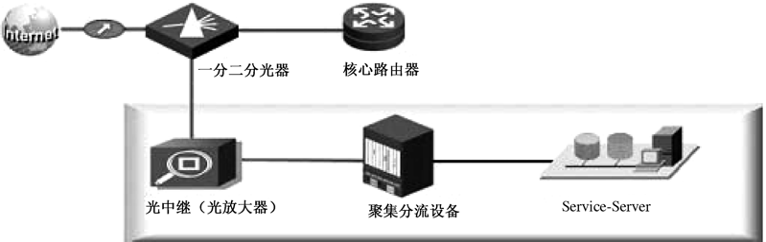
无源分光是在数据中心与运营商之间的光纤链路上借助于分光器,将光信号按照一定的比例进行重新分配的技术。分光器带有一个上行光接口、若干下行光接口。分光器是无源的,只是单纯地将上行光接口过来的光信号分配到所有的下行光接口传输出去,从下行光接口过来的光信号被分配到唯一的上行光接口传输出去。说白了就是一进多出的光缆分线器,只不过是光信号从上行光接口转到下行光接口的时候,光信号强度(即光功率)将下降,从下行光接口转到上行光接口的时候,同样如此。无源分光器使用起来也是非常简单的,无须任何配置,如图33-4所示。
无源分光的优点:
- 在网络100%带宽饱和的情况下依然能够保证完整地抓取数据,可以排除丢包风险。
- 可以抓取线路上的所有报文分组,包括物理错误。
- 接收和发送(RX & TX)信号是在独立的端口上递送的。
缺点:
- 因为对上、下行链路分别安装分光器,所以最少需要两个设备接口来接收数据,同时也需要额外购买分光器,增加了额外的成本。
- 安装分光器的时候需要短暂中断链路,不过现在一般都是双链路冗余和负载。
方案三:Flow流量采样
由于现如今各大互联网公司在骨干网络中的流量都很大,为了能够像过去那样既可以进行网络流量分析和监控,又希望在流量采集过程中对网络设备产生很小的影响,那么是否可以按照一定的采样比例对交换机上某些目标流量进行采样统计呢?答案是肯定的。比如,现有的采样技术有Netflow、sFlow、Netstream、Cflowd、Ipfix等,它们共同的特点是:能够在巨大的网络流量环境中进行流量分析;对网络带宽影响很小;可以获取完整的数据包头信息;可以获取到第2~7层协议信息;用户可以根据生产环境动态设定采样率;除了采集传统的数据包头和协议信息之外,还可以采集网络设备物理接口的传输流量信息,以及网络设备运行状态信息;在无须部署探测器的情况下就可以提供足够多的流量信息,提供给后端的流量分析服务器。
在众多的采样技术里,它们的技术实现也是有所不同的。比如Netflow和sFlow这两种比较常见的Flow采样技术,Netflow是由思科公司开发的一种专有技术,它被应用在思科网络设备的操作系统中,目前部署的版本有V5、V7和V9。如果网络设备的接口开启了Netflow功能,那么Netflow就会跟踪该接口上的进、出数据包,它根据七元组来分析数据包,如果两个数据包在七元组的判断标准上相匹配,就把它们归为相同的流量或会话,一旦会话结束或者被汇总,就会主动发送给采集器。
Netflow将该接口上成千上万的数据包组成的会话(传输流)汇集为一个Netflow V5数据包中的一个条目(最多可以包含30个会话)。换句话说,一个Netflow数据包可以描述30台主机之间的数万级个数的数据包,如果Netflow配置恰当并且硬件没有过载的话,这种技术可以近似以100%的准确性来描述当前接口上的通信信息,并且对网络设备的CPU负载影响非常小。
与Netflow对应的是sFlow,sFlow是由InMon、HP 和FoundryNetworks 于2001年联合开发的一种网络监测技术,它采用数据流随机采样技术,可以提供完整的第2~4层甚至全网络范围的流量信息,可以适应超大网络流量(如大于10Gbps)环境下的流量分析,让用户详细、实时地分析网络传输流的性能、趋势和存在的问题。如图33-5所示,sFlow的基本原理是分布在不同位置的sFlow代理把sFlow数据报文源源不断地发送给sFlow采集器,采集器对sFlow数据报文进行分析并生成丰富的、实时的、全网范围的传输流量视图。
sFlow技术优点:
- 更低的全网络监视成本。
- 具有实时分析能力的一种在线技术。
- 嵌入到网络设备的ASIC中。
- 可以看到设备或端口配置的全网络视图。
- 用户可自行配置的采样速率。
- 对设备性能影响不大。
- 完整的数据包头信息,完整的第2~7层详细信息。
- 支持多种协议(IP、MAC、AppleTalk、IPX、BGP等)
下面是一个sFlow的配置示例。
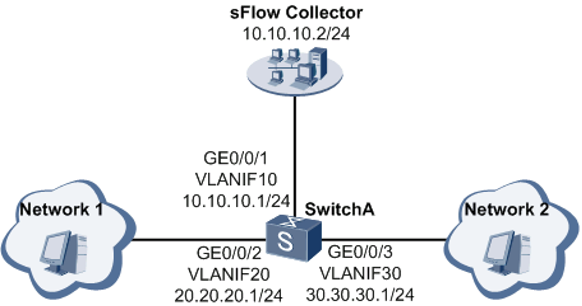
在SwitchA设备上进行sFlow Agent配置,通过在GE0/0/2上开启sFlow采样功能(包括Flow采样和Counter采样),sFlow Agent能够采集本设备上的接口统计信息和数据信息,将信息封装成sFlow报文,当sFlow报文缓冲区满或者在sFlow报文缓存时间超时后,sFlow Agent会将报文从GE0/0/1发向sFlow Collector,然后sFlow Collector根据收到的sFlow报文中携带的流量信息将网络流量状况显示出来,从而实现对GE0/0/2接口流量信息的监控。具体的操作步骤如下:
- 配置SwitchA的接口IP地址。
- 配置sFlow Agent和sFlow Collector信息。
- 配置sFlow Agent的IP地址。
- 配置sFlow Collector信息,比如:sFlow Collector的ID为2,IP地址为10.10.10.2,描述信息为netserver。
- 配置Flow采样:配置采样比。
- 配置经过Flow采样,sFlow Agent输出sFlow报文的目的sFlow Collector编号为2。
- 配置Counter采样:Counter采样的时间间隔为120秒。
- 配置经过Counter采样后,sFlow Agent输出SFlow报文的目的sFlow Collector编号为2。
- 验证配置结果:配置成功后,执行命令display sflow查看SwitchA的全局sFlow配置。
如上所述,我们介绍了三种流量采集方案。关于网络流量的采集我们就可以先告一段落了,但是最终使用哪一种流量采集方案,还是由业务需求、网络生产环境来决定的,不过上面的三种方案已经可以满足大多数应用场景了。一般来讲,Flow流量采样比较适合IDC内部和IDC之间的流量采集,而端口镜像和无源分光比较适合针对公网的流量分析。
流量分析
通过上节内容,我们已经了解了现有的流量采集解决方案和针对不同解决方案的应用场景,接下来我们就要通过这些数据来获取所需要的信息了。在分析之前,首先应该知道采集到的网络流量的内容和数据结构是什么。根据数据是经过采样的,可以将流量分为采样流量和全流量两类。
采用Flow技术获取到的是固定数据结构格式的采样数据,我们称这部分流量为采样流量;而端口镜像和无源分光得到的是全部原始数据,我们称之为全流量。下面将对全流量和Flow采样流量的还原和分析进行介绍。
全流量包捕获技术
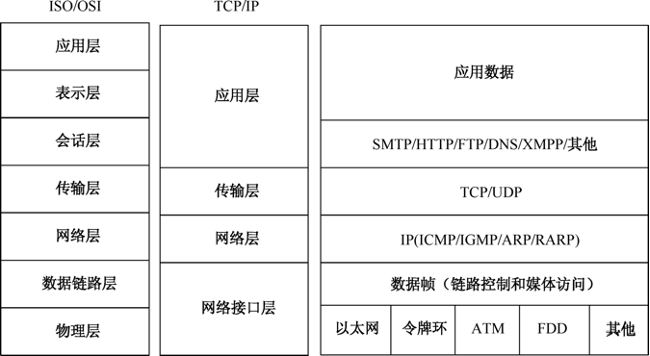
全流量即服务器端收到的是全部的原始流量,它们的数据包结构与应用服务器接收、发送的数据包格式是相同的,也就是说,是遵循TCP/IP网络协议标准的。TCP/IP 网络协议从上到下分为4层:应用层(Application Layer)、传输层(Transport Layer)、网络层(Network Layer)和数据链路层(Data Link Layer)。如图33-6所示。
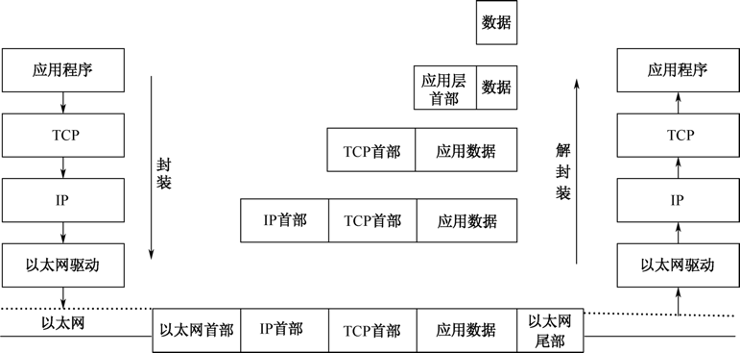
我们得到的就是具备这4层内容的一个个数据包。接下来我们就模拟Linux内核协议栈,对原始数据包按照TCP/IP协议模型进行解析,解析过程包括网络数据包获取和各层协议还原。
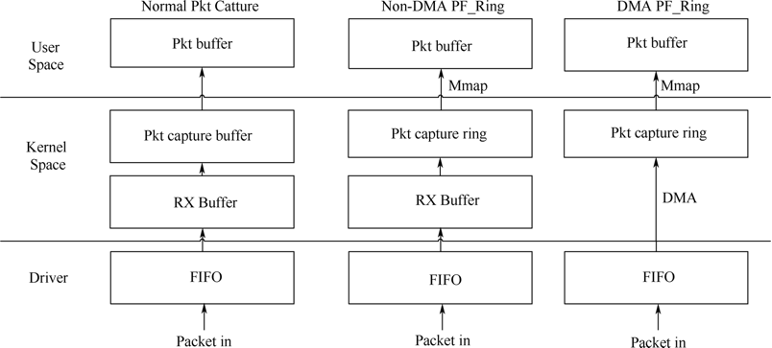
下面先来介绍数据包捕获技术的细节和演变过程,分为原始套接字、Libpcap、PF_RING和DPDK四个部分。
原始套接字
套接字是支持TCP/IP网络通信的基本操作单元,是不同主机之间的进程进行双向通信的端点,可以理解成通信双方的一种约定,用套接字的相关函数来完成通信过程。
原始套接字是网络套接字的一种,利用原始套接字可以对较低层次的协议直接访问,比如读/写ICMP、IGMP分组、自行构造数据报文和在混杂模式下进行各种数据包捕获。原始套接字从实现上分为链路层原始套接字和网络层原始套接字两类,它们的本质区别是:链路层原始套接字可以直接用于接收和发送链路层的MAC帧,在发送时需要由调用者自行构造和封装MAC首部;而网络层原始套接字可以直接用于接收和发送IP层的报文数据,在发送时需要自行构造IP报文头(取决是否设置IP_HDRINCL选项)。
链路层原始套接字:
socktet(PF_PACKET, type, htons(protocol));
其中,参数PF_PACKET用来指定地址簇类型,参数type用来指定具体使用的套接字类型,可以设置为SOCK_RAW、SOCK_DGRAM或SOCK_STREAM,SOCK_RAW说明套接字的接收和发送都是从MAC首部开始的,在发送时调用者需要从MAC首部开始构造和封装报文数据,这种情况满足了自定义二层报文的需求;SOCK_DGRAM说明套接字收到的数据报文将不包含MAC首部,同时在发送时不需要调用者构造MAC首部,只需从IP首部构造即可,内核负责填充MAC首部。最后一个参数用来指定协议类型,该参数只对报文接收有意义,参数的取值不同代表不同的意义,具体参见表33-1。
表33-1 参数Protocol指定的协议类型及其取值
| 协议类型 | 值 | 作 用 |
|---|---|---|
| ETH_P_ALL | 0x0003 | 接收本机收到的所有二层及上层报文 |
| ETH_P_IP | 0x0800 | 接收本机收到的所有IP层及上层报文 |
| ETH_P_ARP | 0x0806 | 接收本机收到的所有ARP报文 |
| ETH_P_RARP | 0x8035 | 接收本机收到的所有RARP报文 |
| 自定义协议 | 比如0x0810 | 接收本机收到的所有类型为0x0810的报文 |
| 不指定 | 0 | 不接收,只用于发送 |
| …… | …… | …… |
在表33-1中需要注意两个特殊值:当protocol为ETH_P_ALL时,表示能够接收本机收到的所有二层报文,也就是说,本机发往外部的数据包也会再收回来;当不指定protocol时,表示该套接字只用于发送,而不关注接收报文。
网络层原始套接字:
socktet(PF_INET, type, htons(protocol));
其中,参数一指定协议簇类型为PF_INET;参数二指定套接字类型为SOCK_RAW。
网络层原始套接字在接收报文时是从IP首部开始的,即接收到的数据报文包含IP首部和上层首部以及数据部分,在发送报文时,默认从IP首部到下层首部是由内核进行封装的,不过通过setsockopt()函数给套接字设置IP_HDRINCL选项,就可以自定义IP首部了,TCP/UDP等上层协议首部需要由调用者自行构造和封装。
参数三指定协议类型,该参数只对报文接收有意义,参数的取值不同代表不同的意义,具体参见表33-2。
表33-2 protocol指定的协议类型及其取值
| 协议类型 | 值 | 作 用 |
|---|---|---|
| IPPROTO_TCP | 6 | 接收TCP类型报文 |
| IPPROTO_UDP | 17 | 接收UDP类型报文 |
| IPPROTO_ICMP | 1 | 接收ICMP类型报文 |
| IPPROTO_IGMP | 2 | 接收IGMP类型报文 |
| IPPROTO_RAW | 255 | 不用于接收,只用于发送(需要手动构造和封装IP首部) |
| OSPF | 89 | 接收OSPF类型报文 |
| …… | …… | …… |
在表33-2中需要注意的是IPPROTO_RAW,它表示该套接字只能用来发送数据,不能用于接收数据,且发送数据时需要从IP首部开始构造和封装报文。
如下是最简单的数据包捕获方式,可以直接读取数据链路层的信息进行处理。
sock_fd = socket(PF_PACKET, SOCK_RAW, htons(ETH_P_ALL)));
while (1){
n = recvfrom(sock,buffer,65536,0,NULL,NULL);
//...处理
ProcessPacket(buffer , n);
}
采用原始套接字进行抓包的方式是尽可能地把所有数据包都拷贝一份给包捕获程序。在流量大的情况下,可以采用多线程设计思想,将包捕获流程与数据包处理流程分离,这样可以提高数据包处理的整体速度。但是由于Linux系统底层数据包接收的实现机制问题,以及在数据处理过程中需要解决多线程互斥的问题,所以这种方式在大流量环境下难免会造成丢包。还有一种现实应用中的特殊需求,比如只想要其中的部分数据,那么可以通过setsockopt()函数给原始套接字设置BPF过滤器机制,提高数据包捕获精准度,以免浪费资源。
Libpcap
Libpcap是UNIX/Linux/Win32平台下的另一种同样提供了用户级别且独立于系统用户层的网络数据包捕获库。我们平时最常用的两种主机网络数据包分析工具Wireshark和基于命令行的Tcpdump,以及Snort入侵检测系统,它们的底层抓包方式应用的都是Libpcap。Libpcap是一个用于网络抓包和过滤的动态库,它源于Tcpdump项目,是从Tcpdump中剥离出来的一个库,目前Libpcap也是由Tcpdump的项目组成员来维护的。应用Libpcap可以很方便地编写数据链路层上的数据包捕获程序,Libpcap主要由Network Tap和 Packet Filter两部分组成,它的工作流程可描述为:当一个数据包到达网卡时,Libpcap首先利用已经创建好的Socket从链路层驱动程序获得该数据包的拷贝,再通过Network Tap将数据包发给Packet Filter过滤器,过滤器根据用户已经定义好的过滤规则对数据包进行逐一匹配,若匹配成功则放入内核缓冲区(一次拷贝),并传递给用户缓冲区(又一次拷贝),匹配失败则直接丢弃。如果没有设置过滤匹配,所有数据包都将放入内核缓冲区,并传递给用户缓冲区。数据包的捕获过程基本包含3个主要功能,分别是:
- 面向底层的数据包捕获引擎。
- 面向中间层的数据包过滤器。
- 面向应用层的用户级接口。
Linux操作系统对于数据包的处理流程是自底而上的方式,依次经过网卡、网卡驱动层、数据链路层、IP层、传输层,最后到达应用程序。而数据包捕获机制是在数据链路层增加一个旁路处理,对发送和接收到的数据包通过Linux内核做过滤和缓冲等处理,最后直接传递到上层应用程序进行交互。不管是Linux原生态的原始套接字还是Libpcap,它们都基于这种原理,所以不会影响Linux操作系统中网络协议栈的正常数据包的处理。
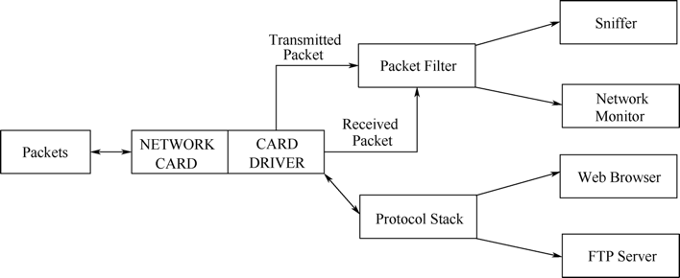
如果我们有对收到的数据包进行编辑处理的需求,那么可以采用另一种方式来获取数据包,参考NF_QUEUE,它可以经内核将数据包传递到用户层进行处理,并根据用户态的处理逻辑对数据包进行相应的操作(DROP、ACCEPT等),或者对数据包修改后再发送给内核,最后经由协议栈将数据包发送出去,如图33-7所示。
Libpcap有一个值得一提的功能就是它的数据包过滤机制,这也使它的工作效率高于原始套接字,因为当程序运行在用户态时,实际上抓包处理过程是在内核态进行的,每当内核从网卡驱动获取数据包时,它都要将数据包从内核态复制到用户态。这是一种时间上的浪费,并且网卡收包处于一个软中断的环境中,在网络流量很大的情况下,不但造成操作系统的整体性能下降,还会造成数据包在内核态中被丢弃的可能。如果我们想获取所有数据包的话,则需要优化抓包程序,但这都是内核态处理的,我们能做的工作很少。如果我们对其中的特定类型的数据包感兴趣的话,那么Libpcap的过滤机制恰到好处,我们可以按照特定的规则来告诉内核过滤哪些数据包,于是就得到了与规则相匹配的数据包拷贝。那么过滤规则是由谁定义和设置的呢?规则主要是由用户定义的,然后通过调用Libpcap提供的设置过滤器API来完成设置的,当内核收到数据包时,该规则将被匹配,如果验证数据包与规则相符,数据包将会被传递到应用程序;否则就只会被传递到内核网络协议栈中,进行正常方式处理。其实每种操作系统都有它们自己的数据包过滤机制,不过基本上都基于相同的架构——BPF过滤机制,它被设计成一种类似汇编形式的语言,大家都称它为伪汇编。它是一组基于状态机的匹配过滤序列,并以最简单的方式进行数据包模式匹配。Libpcap不仅完全支持BPF过滤器,还提供给用户一套高级且极其简单易用的API接口。
Libpcap应用程序框架实例,必须以root用户身份来运行。
- 查找可以捕获数据包的设备,如果手动设定捕获接口,此步跳过。
(device = pcap_lookupdev(errBuf); - 创建捕获句柄,准备数据包捕获。
pcap_t * dev = pcap_open_live(device , 65535, 1, 0, errBuf); - 如果用户设置了过滤条件,则编译和设置过滤规则;否则请跳过本步。
struct bpf_program filter; const char *filter_string=”dst port 80”; Pcap_compile(dev,&filter, filter_string,1,0); pcap_setfilter(dev, &filter); - 进入数据包捕获环节。
pcap_loop(device, -1, Process_Packet, (u_char*)&id); - 对原始数据包进行解析。
void Process_Packet(u_char * arg, const struct pcap_pkthdr * pkthdr, const u_char * packet); - 关闭捕获句柄,释放资源。
Pcap_close(dev);
通过对Libpcap的学习,我们就可以轻松地写出自己想要的数据包捕获引擎。但是随着互联网的发展以及大数据的慢慢形成,有一天,网络生产环境从百兆升级到了千兆,最终我们发现以前的抓包程序已经不堪重负了,由于它们底层实现的原因,当流量大到一定程度的时候,流量捕获系统难以处理,导致大量丢包。原因基本可以归结为两点:一是大部分CPU时间都用于处理频繁的软中断;二是因为数据包从驱动到内核态再到用户态被多次拷贝,浪费了大量的时间和资源。知道了原因,那么改善数据包捕获机制的思路也就很明确了。
因此,基于Libpcap-mmap的数据包捕获方案应运而生。为了减少内核拷贝次数和系统调用带来的开销,提高CPU的利用率,洛斯阿拉莫斯国家实验室开发了一个Libpcap的改进版本Libpcap-mmap。Libpcap-mmap采用了mmap映射技术优化内存拷贝,建立核心态内存和用户态内存之间的映射,将系统分配给网卡设备文件的核心态内存映射到一块用户态内存中,这样,应用程序可以通过调用系统函数recvfrom()把数据包从网卡直接传送到用户态内存中,减少了一次数据拷贝,降低了系统资源消耗,提高了数据包捕获效率。此外,Libpcap-mmap设计了一个大小可以配置的环状缓冲区,允许用户程序和内核程序同时对环形缓冲区的不同数据区域进行直接读取,减少了因缓冲区溢出而造成的丢包,提高了整个系统的数据包捕获性能。
总体来讲,要想提高数据包捕获效率,需要在两个方面加以优化和改进:减少内存拷贝次数,节省CPU开销;改进中断方式,减少不要的CPU中断周期。
进阶:eBPF包捕获过滤技术,请进一步参考快猫星云更多博客文章。
PF_RING
PF_RING是Luca研究出来的基于Linux内核级的第三方高速数据包捕获技术,网络数据包在发送和接收过程中,会发生多次内存拷贝以及频繁的终端处理操作,这将占用大部分CPU时间,PF_RING在一定程度上进行了改进,极大地改善了数据包捕获速度,按照其官方网站上的测试数据,在Linux平台上,其效率至少高于Libpcap 50%~60%,甚至是1倍。它还提供了一个修改版本的Libpcap,使之建立在PF_RING 接口之上。这样,原来使用Libpcap的程序,就可以平滑地移植到PF_RING基础平台,并且它还具备如下特征。
- 支持Linux内核2.6.32或者更新版本。
- 不再需要给Linux内核打任何补丁,直接加入模块即可使用。
- 可以兼容现有的基于Libpcap开发的应用程序。
- 支持商用万兆级网络适配器的硬件包过滤。
- 设备驱动无关性,即可以使用经过优化的网卡驱动来提高性能(推荐使用支持NAPI的Intel官方网卡)。
- 支持基于内核的数据包捕获和数据包采样。
- 可以设置BPF上百条头过滤规则。
- 支持内容检查,只有数据包负载内容匹配成功的才可以通过。
- PF_RING的插件可以用于丰富数据包解析和数据包内容过滤功能。
本质上PF_RING的行为就是从驱动模块直接抓取每个数据包,然后放入一个环行缓冲区中,这也是为什么叫RING的原因。这个环形缓冲区有两个接口:一个供网卡向其中写数据包;另一个为应用层程序提供读取数据包的接口。读取数据包的接口是通过mmap函数实现的,这就减少了在数据包传递过程中内存拷贝的次数,或者说PF_RING直接将一个构建好的以太网帧投放到网卡驱动的发送队列,实际上它对应用层提供了一个数据包的直接获取路径,没有它,按照以往常规的协议栈逻辑,一个数据包必须串行地经过协议栈各层,然后经过层层协议头的剥离,才能让应用程序识别出当前应用数据。与基于原始套接字和Libpcap抓包方式不同的是,PF_RING机制显得更为灵活,因为PF_RING支持三种工作模式。
(1)基于PF_RING的NAPI模式
NAPI(New Application Program Interface)是Linux 采用的一种提高网络处理效率的技术,它的核心概念就是不采用中断的方式读取数据,而是采用中断唤醒的数据接收模式,然后采用Poll的方式来轮询数据。丢包主要是因为CPU一直忙于处理中断,而没有把时间花在用户数据包处理上,利用NAPI技术可以解决这个问题。但是使用NAPI机制也是存在先决条件的:
- 网卡设备必须具备DMA(Direct Memroy Access)硬件,要支持使用DMA的环形队列- ring_dma),并有足够的内存空间缓存数据包。
- 在发送/接收数据包产生中断的时候有能力关闭NIC中断的事件处理,并且在关闭NIC中断以后,保- 不影响数据包接收到网络设备的环形缓冲区(以下简称rx-ring)处理队列中。
- 有防止NIC队列中排队的数据包冲突的能力。
数据包发送/接收事件中断的时候,NAPI将在POLL中被调用处理,由于 POLL 方法正在调用的时候,NIC中断通知包已经不能到达,那么这个时候如果完成轮询,并且中断打开以后,会马上有一个NIC中断产生,从而触发一次POLL事件。这种在中断关闭时刻到达的包我们称为“rotting”。这样就会在POLL机制和NIC中断之间产生一个竞争,解决的方法就是利用网卡的接收状态位,继续接收环形缓冲区中的数据,直到没有数据接收以后,才启用中断。
经过实践分析,使用NAPI机制减少了中断的数目,也就是说,让操作系统可以节省在中断现场的保护和恢复时间,把更多的CPU时间用在处理网络层的数据包上,这样做确实大幅度提高了数据包捕获能力和系统响应速度。但同时问题也暴露出来了,对于上层应用程序而言,系统不能在每个数据包接收到的时候及时去处理,而且随着网络流量的增大,累积的数据包将会消耗大量的内存。这种问题还是普遍存在的。在网络环境中大包数量远大于小包数量的情况下,因为把大包传递到网络层要比传递小包耗时,所以NAPI机制比较适用于小包高速率传递的网络环境中,如图33-8所示。
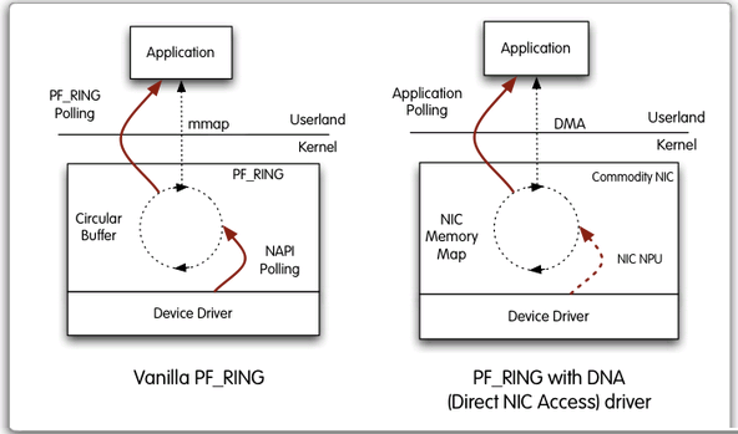
(2)基于PF_RING的DNA模式
PF_RING DNA(Direct NIC Access)通过把网卡内存和寄存器直接映射到用户空间,这样就可以直接绕过NAPI和内核网络协议栈的所有路径。也就是说,直接利用NIC NPU(Network Process Unit)从网卡拷贝数据包到DMA的环形缓冲区中,比非DNA模式减少一次数据拷贝,内核也将看不到任何数据包,这样会进一步降低CPU的利用率;并且现在的网卡都支持多RX/TX队列,因此可以通过启动多个应用程序,让每个应用程序对应一个RX/TX队列。这种方式可以大大提高数据包捕获速度。根据这几种工作方式,PF_RING官方提供了下面的对比图。
从图33-8和图33-9我们可以看出PF_RING DNA模式所做的改进之处。但是由于在DNA模式下,不再使用NAPI Poll,所以PF_RING无法进行数据包过滤了。目前可以使用硬件层的数据包过滤,但是只有Intel的82599网卡支持,而且这种方式仅限于以二进制形式提供的测试版本,不过通过付费是可以得到源代码的,想使用它还有点难度。
(3)基于PF_RING的TNAPI模式
随着多核平台的出现,先前的方法在内核网络层并没有利用多核这个硬件的优势,Luca设计了一个新的针对多核数据包捕获的模块,即TNAPI(Threaded New Application Program Interface),它是NAPI的一种技术上的改进,应用TNAPI的数据包捕获效率大概是PF_RING的两倍。不过,使用TNAPI需要硬件支持,包括多核CPU支持,支持I/OAT、MSI-X、DCA的多队列Intel网卡(1Gbit: Intel 82575/76/80;10Gbit: Intel 82598/82599),如图33-10所示。
TNAPI模式具有以下特点:
- 分发数据包流量到各个CPU核心来提高扩展性。
- 可以同时从每个RX队列轮询数据包,从而提高数据包捕获效率。
- 通过PF_RING,可以实现用户态的每个线程对应一个RX队列,避免使用信号量。
鉴于PF_RING的诸多优点,我们可以利用PF_RING来改进原来使用Libpcap的应用程序,比如使用
--daq pfring方式来优化Snort入侵检测系统,提高Snort的整体性能;在Suricata入侵检测系统中应用PF_RING技术来提升数据包捕获效率;应用PF_RING开发高性能流量分析系统等,但凡需要对网络流量进一步分析的,都可以借助PF_RING来优化。
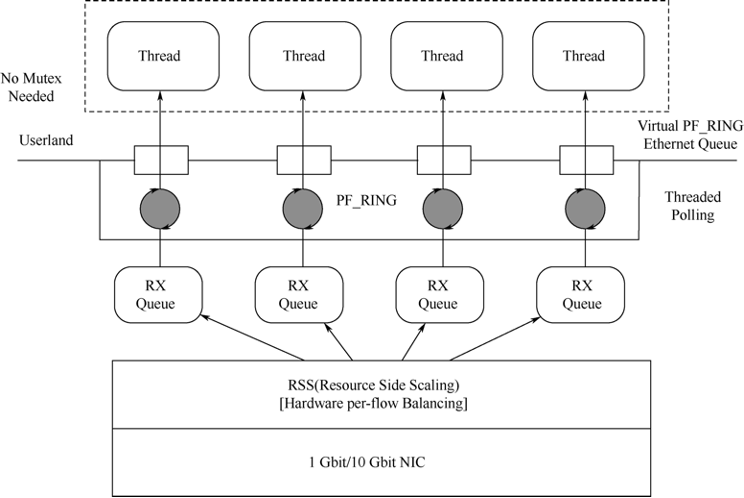
当然,PF_RING也有不足之处。目前大部分网卡都支持MSI-X技术,可以把接收数据包的队列分成多个RX队列,每个队列对应一个CPU核心。RSS技术可以通过per-flow实现各个RX队列间的负载均衡。这样的好处是可以充分利用多核CPU的优势,提高对数据包的处理速度。但是目前PF_RING不能充分发挥这个优势,原因是驱动程序仍然需要依次轮询RX队列,而不能同时访问所有的RX队列,操作系统需要把这些RX队列合流到一个接口供应用程序读取。当需要处理超大流量数据的时候,多核CPU的单核占用率很高,不能充分发挥多核性能。
基于这一点,PF_RING也做了改进,利用TNAPI技术可以做到以下几点:
- 把流量分发到不同的核心上,具有更好的扩展性。
- 同时从每个RX队列轮询数据,从而提高数据包读取性能。
- 实现用户态的每个线程对应一个RX队列,避免使用信号量。
DPDK
DPDK(Intel Data Plane Development Kit)是Intel数据平面开发工具套件,它是一套简单、完整、高度优化的用户空间库和驱动程序,帮助用户将控制和数据进行平台整合,并在Intel x86架构的通用处理器上有效地提高数据包处理能力。DPDK核心组件是由一系列库和驱动模块组成的,内核态模块主要对PCI设备进行初始化,并实现轮询模式的网卡驱动和接口;用户态模块则是以库的形式给用户提供大量的函数接口。
DPDK架构示意图如图33-11所示。

DPDK各模块介绍如下。
- Buffer Management:在DPDK程序工作时,预先从EAL上分配多个固定大小的内存对象,避免在运行过程中进行动态分配和回收内存,用来提高数据包处理速度。
- Queue Management:DPDK实现了基于无锁的环形队列,支持一个生产者与多个消费者模型,并且支持批量无锁操作。
- Packet Flow Classification:DPDK基于多元组(源IP地址、目的IP地址、协议、源端口、目的端口)实现的高效Hash算法,用来快速匹配到每个接收到的包所属的连接或会话,该API在路由查找过程中的最长前缀匹配中以及一些产品中需要根据五元组来标识在不同会话的场景下被频繁应用。
- NIC Poll Mode Driver(PMD):Linux操作系统默认的收发数据包方式是通过中断来通知CPU从队列中读取或者发送数据包的,而DPDK则针对Intel网卡实现了基于轮询(PMD)的方式,并充分利用CPU指令与网卡芯片相结合的特性,该驱动由运行在用户空间的驱动和API组成,在用户程序中使用无中断方式直接操作网卡的接收和发送队列(除了链路状态通知使用的中断),进行接收、处理和发送数据包。这样做带来的好处是:可以降低中断对系统的影响,减少操作系统内核的开销,避免了内核态与用户态之间的多次数据拷贝,消减了IO瓶颈。PMD通过利用CPU向量指令(Vector Instance)能够在一条指令中完成128bit/256bit的数据读/写,等同于4/8个Int类型变量的读/写操作,原本需要4/8条指令,明显地降低了内存等待开销,提升了CPU的流水线效率。这在解析报文的时候作用非常明显,比如业务程序通常需要解析报文的Ethernet头部、IP头部、TCP/UDP头部,以往在提取报文字段时,最快的方式就是按照字节对齐模式,逐步提取每个报文头部,并从报文头部中抽取出关键字段来计算下一个报文头部的位置。这种方式编写困难,尤其是要保证字节对齐。而向量指令提供了封装函数,不需要考虑字节对齐,在代码编写方面更加方便,操作效率也得到提高;并且与逐个报文字段的解析相比,采用向量指令可以提升1.5倍性能。但是目前PMD驱动也只是支持Intel的一部分网卡芯片,具体的网卡芯片型号可以从官网查询。
- Environment Abstraction Layer(EAL):EAL实现了DPDK运行时的初始化工作,DPDK 通过EAL对用户空间应用程序提供了一个通用的接口,并隐藏了与底层硬件访问的相关细节,比如基于大页的内存分配、多核CPU affinity设置(注:让指定的进程运行在“绑定”的CPU上),以及PCI设备地址映射到用户态等。通过修改配置文件和Makefile 可以创建一套特定的EAL,比如它能够指定x86架构(32位/64位)、Linux系统或者其他特定系统平台的用户空间的编译器,当EAL创建完成后,就可以通过动态链接这些库进一步开发自己的应用程序了。
DPDK通过一个简单的架构模型提供了充足的数据包处理性能,它不仅仅提高了数据包获取方面的性能,在数据包的后续处理方面也是非常高效的,典型的应用包括:Open vSwitch、安全网关、网络流量分析以及TCP/IP协议栈,有了协议栈之后就能够被更广泛的网络服务所应用了。
全流量分析
为了更好地了解网络上的数据细节,在一定程度上是需要我们能够对数据包进行协议解析的,协议解析的前提就是要了解目标网络的基础环境以及所用的网络协议栈,对每种协议以及对应的网络协议数据结构有清晰的认识。
从图33-12中可以看出,以太网数据帧属于OSI参考模型中数据链路层的协议封装,是TCP/IP模型中的网络接口层的协议封装。现今最流行的局域网通信网络标准当属以太网,它是现有局域网采用的最通用的通信协议标准,并且该标准定义了在局域网中采用的电缆/光缆类型和信号处理方法。以太网已经将其他的比如令牌环网和FDDI等网络标准基本完全替代了,以太网的传输速率也从标准以太网十兆bps发展到了万兆bps,并且据说如果采用波分复用技术的话,可以在单对光缆上以4倍的光波长发送信号。
下面我们先来了解一下以太网的发展历程。
从Ethernet V1标准开始,是由Xerox PARC提出的3Mbps CSMA/CD以太网标准的封装格式,然后在1980年由DEC、Intel和Xerox标准化形成Ethernet V1标准,这也是最原始的一种数据帧格式,如图33-13所示。
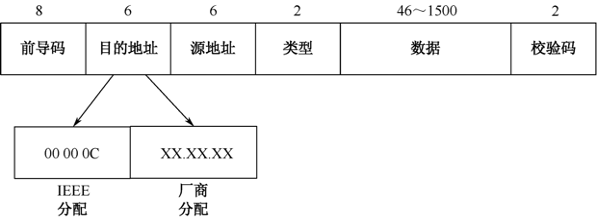
Ethernet V1数据帧中每个字段的详细解释如下。
- 前导码:包括同步码(用来使局域网中的所有节点同步,7字节长)和数据帧标志(1字节表示下一字节为目的MAC地址)两部分。
- 目的地址:此数据包的目的MAC地址,6字节。
- 源地址:此数据包的源MAC地址,6字节。
- 类型:上层协议类型标识,表示网络层使用的协议,2字节。
- 数据:包括上层协议、数据和填充符,范围为46~1500字节。
- 校验码:数据帧校验序列,用于确定数据包在传输过程中是否有损坏,如有损坏,由以太网驱动程序丢弃此数据帧,4字节。
**Ethernet V2:**是1982年由DEC、Intel和Xerox公布的新的网络标准,在数据帧格式上并没有发生变化(见图33-14),主要修订了Ethernet V1的电气特性和物理接口,Ethernet V2采用CSMA/CD的媒体介入和广播机制。Ethernet V2的出现,迅速取代Ethernet V1并成为了最通用的以太网通信协议标准。需要注意的是,在交换机的汇聚连接上,是可以对数据帧附加VLAN信息的,位于数据帧的源MAC地址与类型之间,大小为4字节,所以在计算IP首部地址偏移时,需要把VLAN 首部的大小也跳过。
**原始Ethernet 802.3:**是1983年Novell发布其Netware/86网络套件时采用的私有以太网帧格式。该数据帧格式是以当时尚未正式发布的 IEEE 802.3标准为基础的,但是两年以后,IEEE正式发布802.3标准时情况却发生了变化(IEEE在802.3帧头中又加入了802.2 LLC头),使得Novell的Ethernet 802.3协议与正式的IEEE 802.3标准互不兼容;Ethernet 802.3只支持IPX/SPX协议,是当时使用的最普通的一种帧格式,在802.2之前是IPX网络事实上的标准数据帧类型。
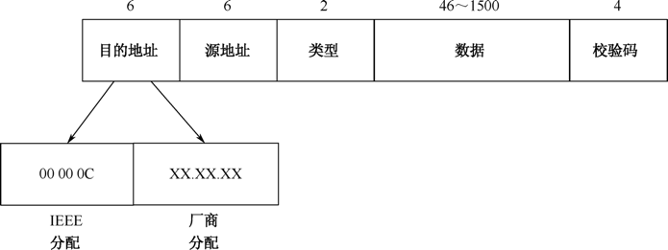
**Ethernet 802.3/802.2 LLC:**这是IEEE正式的802.3标准,它是基于Ethernet V2发展而来的,最大的修改是将Ethernet V2数据帧中的类型字段替换为数据帧长度字段(取值为0000~05DC;十进制的0~1500),并加入802.2 LLC头用以标志上层协议,LLC字段中包含DSAP、SSAP以及控制字段,如图33-15所示。
Ethernet 802.3/802.2 LLC数据帧中每个字段的详细解释如下。
- 目的地址:此数据包的目标MAC地址,6字节。
- 源地址:此数据包的源MAC地址,6字节。
- 长度:数据帧包含的数据量必须小于或等于1500(十六进制的05DC)。
- LLC:Logical Link Control的缩写,意为逻辑链路控制。
- DSAP:目标服务存取点(Destination Service Access Point)。
- SSAP:源服务存取点(Source Service Access Point)。
- 控制:无连接或面向连接的LLC。
- 数据:包括上层协议、数据和填充符,范围为43~1497个字节。
- 校验码:数据帧校验序列,用于确定数据包在传输过程中是否有损坏,4字节。
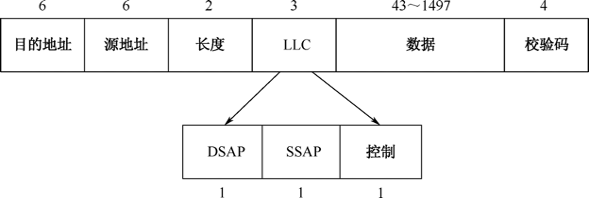
Ethernet 802.3/802.2 SNAP:该协议是IEEE为保证在802.2 LLC支持更多的上层协议的同时更好地支持IP协议而发布的标准。与802.3/802.2 LLC一样,802.3/802.2 SNAP也带有LLC头,但是扩展了LLC属性,新添加了一个2字节的协议类型域(同时将SAP的值置为AA),从而使其可以标识更多的上层协议类型;另外添加了一个3字节的厂商代码字段用于标记不同的组织。RFC 1042定义了IP报文在802.2网络中的封装方法和ARP协议在802.2 SANP中的实现方法。
Ethernet 802.3/802.2 SNAP数据帧格式如图33-16所示。
对更新字段的详细解释如下。
- 数据:包括上层协议头、数据内容和填充符,范围为38~1492字节。
- 厂商代码:用于硬件厂商标识。
在现如今的实际网络环境中大多数网络设备都使用Ethernet V2格式的数据帧,这是因为第一种大规模使用TCP/IP协议栈的系统(4.2/3 BSD UNIX)的出现时间介于RFC 894和RFC 1042之间,它为了避免不能和别的主机互相通信的风险而采用了RFC 894的实现;也由于大家都抱着这种想法,所以802.3标准并没有如预期那样得到普及。
上面我们介绍了以太网的发展历程、协议结构以及它与OSI参考模型中数据链路层的关系,下面我们将对根据OSI七层参考模型继续向上层(网络层)协议封装的知识进行讨论。前面我们讲到Ethernet V2格式的数据帧中有一个2字节的类型字段,网卡驱动程序使用它来标识上层所使用的网络协议,常见的协议类型包括0800 IP、0806 ARP、8137 Novell IPX、809b Apple Talk等。Novell IPX和Apple Talk是这两家私有的网络协议,并在现如今的网络环境中也是很少见的;如果标识的是ARP/RARP请求/应答的话,则通过相应的协议进行应答处理;如果标识的是IP数据报文的话,则脱去数据帧头和数据帧尾,将其交给TCP/IP协议栈,首先由IP处理程序对IP数据报文进行校验,并决定丢弃该报文还是继续向上层传递。在这里我们还是先了解一下IP数据报文的格式,如图33-17所示。
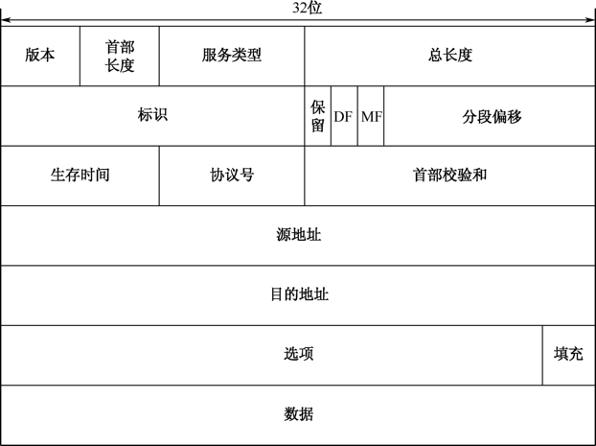
IP数据报文与网络硬件无关,由首部和数据两部分组成,首部中的前20字节是长度固定的,是所有IP数据报文必须具有的。在其后面还有一些可选项字段,选项部分长度是可变的。下面详细介绍IP数据报文各个字段的含义。
版本表示IP协议的版本,通信双方使用的IP协议版本务必一致,目前广泛使用的还是IPv4,IPv6的应用需求目前也在持续增长。首部长度用4位代表首部有多少32位字长,由于IPv4首部可能包含数目不定的选项,这个字段也用来确定数据的偏移量。这个字段的最小值是二进制的0101(十进制5),最大值是二进制的1111(十进制15),那么选项字段的最大长度为40字节。服务类型字段之前一直没有被应用,后被(RFC 2474)重新定义为Differentiated Services,VoIP是应用此字段的一个典型的例子。总长度表示IP数据报文的总长度包含IP首部长度和数据长度;标识字段主要被用来唯一地标识一个报文的所有分片;
DF和MF标志位说明如下。
如果DF标志被设置但路由要求必须分片报文,此报文会被丢弃。当一个报文被分片后,除最后一个分片外的所有分片都设置MF标志,不被分片的报文不设置MF标志;它可能是该数据包的最后一个分片。生存时间(TTL)表示避免报文在互联网中永远存在,防止陷入路由环路。生存时间以秒为单位,小于1秒的时间均向上取整到1秒。在现实应用中,这实际上成了一个跳数计数器,报文经过的每个路由器都将此字段减1,当此字段等于0时,报文不再向下一跳传送并被丢弃。协议号表示定义了该报文的数据区(上层)使用的协议。16位的首部检验和用来对IP首部查错,无论是网络设备中的哪一跳,都需要计算出首部检验和与该值进行比较,如果不相等,此报文将被丢弃。需要注意的是,因为IP首部的生存时间字段在每一跳都会发生变化,所以IP首部检验和在经过IP转发设备时必须被重新计算。源/目的地址表示通信双方的IPv4源和目的地址。选项字段在平时工作中并不被经常使用,所以具体的选项内容可以查阅TCP/IP详解等。
IP协议是构成Internet的基础,但是它提供的是不可靠、无连接的数据报文传送服务。IP协议的不可靠传输是指它不能保证每个IP数据报文都能成功地到达目的地,如果发生某种错误如路由器暂时用完了缓冲区,IP有个简单的处理算法,就是丢弃这个数据报文,然后发送一个ICMP消息给源端;无连接的意思是指在IP数据报文中不维护任何后续数据报文的状态信息,每个数据报文的处理都是相互独立的。而可以维护这种数据报文状态信息的协议是上层的TCP协议;基于IP协议的上层协议是传输层协议,传输层的主要功能就是分割并重组上层提供的数据流,并为数据流提供端到端的服务。它包括两大协议:TCP(传输控制协议)和UDP(用户数据报协议),这两种传输层协议以及网络层协议在做网络流量分析时都是必须要用到的,所以下面简单介绍一下这两种传输层协议首部格式。
UDP协议格式,如图33-18所示。
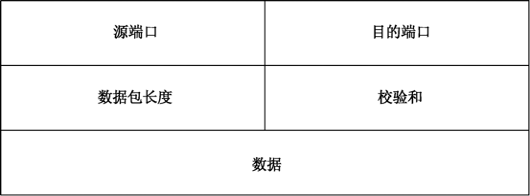
- 源/目的端口:数据的发送方和接收方的端口号,大小为各占16位。
- 数据包长度:UDP协议首部长度,大小为16位。
- 校验和:UDP首部校验,用于计算数据的有效性,大小为16位。
- 数据:由UDP协议封装进来的应用数据,数据内容包含应用协议首部和应用数据。
TCP协议格式,如图33-19所示。
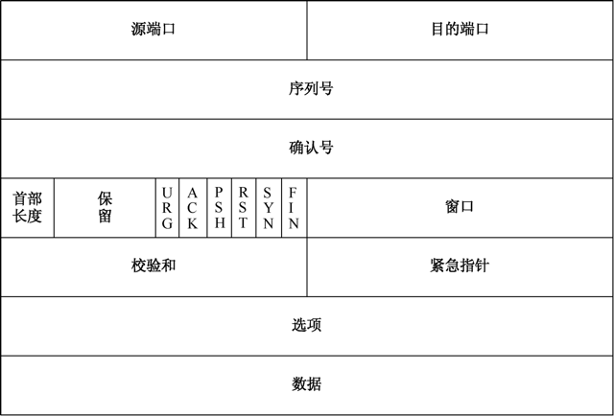
- 源/目的端口:与UDP协议相同,数据的发送方和接收方的端口号,大小为各占16位。
- 序列号:由数据发送方使用,大小为32位。
- 确认号:数据接收方返回给数据发送方的确认通知,会在序列号的基础上加1,大小为32位。
- 首部长度:与IPv4首部长度的意义基本相同。 下面是TCP的功能状态位。
- 保留:以后增加新功能时使用。
- URG:紧急指针位,1代表这是紧急数据,0代表是普通数据。
- ACK:确认位,1代表这是一个确认包,0则相反。
- PSH:表示有数据传输并通告接收方立即将收到的数据段连同TCP接收缓存中的数据段递交给应用程序。
- RST:连接重置位,当接收方收到不属于该主机的任何一个连接的数据时,则向对方发送这个连接重置包,该位取值为1,相反取值为0。需要注意的是,通过计算序列号,可以手动制造并发送RST包重置任意TCP连接。
- SYN:初始化连接请求位,值1代表这是一个TCP三次握手中的请求包,0则相反。
- FIN:连接关闭位,值1代表这是一个TCP断开连接的包,0则相反。
- 对于TCP功能状态,这里需要注意的是,在一些数据段中,不一定带有唯一状态标识的,比如有可能是ACK+PUSH、ACK/FIN连用等。
- 窗口:发送方与接收方经过协商之后确定的滑动窗口大小,表示准备接收多大的TCP数据段,大小为16位。
- 校验和:用来校验TCP首部的有效性,大小为16位。
- 紧急指针:表明字段中包含紧急信息,发送方需加速传递,而接收方需要加速接收给应用程序,只有当URG状态值为1时才生效,大小为16位。
- 选项:因为该字段在平时工作中并不被经常使用,所以具体的选项内容可以查阅TCP/IP详解等。
- 数据:由TCP协议封装进来的应用数据,数据内容包含应用协议首部和应用数据。
经过上面的介绍,我们对传输层协议首部格式已经有了基本的认识。其实我们不关心应用程序采用哪一种传输层协议,那不是我们的工作,两种协议各有优缺点,而我们做流量分析需要的是解析用户使用的传输协议,实现数据分析需求而已。
通过对网络层IP协议和传输层TCP/UDP协议的认识,我们已经可以做一些能够满足网络层的双向流量分析工作了。比如:
- 对常见的网络流量(TCP、UDP、ICMP、Other)进行统计查询。
- TCP各状态流量统计查询。
- 应用发现,根据分析TCP/UDP各端口的流量进行统计查询。
- TOP N 流量统计查询,比如查看TCP各状态的TOP 10等。
- 动态流量基线的生成和查询,作为异常流量发生时的依据。
- TCP 协议连接建立响应时间。
- 根据源IP对运营商流量进行统计查询。
- 单IP(公网服务器/LVS)流量统计查询。
上面是目前最基本的网络流量分析功能,通过对网络层和传输层的协议进行分析就可以做到。如果我们还想进一步了解网络中的内容,就需要对应用层协议进行解析了,比如对最常见的HTTP Web应用协议进行分析,仍然从HTTP协议首部格式开始,由于HTTP协议首部字段有很多是我们不需要关注的,所以这里只列出一些常用的字段。
(1)HTTP请求
- 请求行
格式:GET /index.html HTTP/1.1 字段一:表示HTTP请求方法,常用的有GET、POST、HEAD、PUT等。 字段二:表示请求服务器资源的URI,注意一定以“/”开头。 字段三:客户端标识的HTTP版本。 - 请求头
Accept:用于指定客户端可以接收的数据类型。 Accept-Charset:用于指定客户端接收数据的字符集。 Accept-Encoding:类似于Accept,但是它用于指定可接收的内容编码,是否支持压缩等。 Accept-Language:请求报头域类似于Accept,但是它用于指定一种自然语言。 Host:主要用于指定被请求资源的Internet主机和端口号。 User-Agent:列出了操作系统以及浏览器的名称、类型和版本。 Referer:用一个URL作为其值,代表用户是从该URL发出的当前HTTP请求。 Cookies:因为HTTP自身是无状态的,所以经常用Cookies中的信息来维护客户端与服务器之间的会话状态标识。 Connection:表示是否需要持久连接。 Content-Length:如果采用的是POST请求方式,该字段表示用户提交的数据长度。 - 请求体
用来表示客户端向服务器端提交的内容。
(2)HTTP响应
- 响应状态行
格式:HTTP/1.1 200 OK 字段一:表示HTTP服务器采用的HTTP协议版本号。 字段二:表示HTTP服务器响应状态码,具体意义请查看RFC 2616。 字段三:表示对第二个字段返回状态码的简要描述信息。 - 响应头
Server:表示应用服务器软件信息。 Connection:表示是否需要持久连接。 Content-Encoding:表示返回内容的编码方法。 Content-Length:表示服务器返回的内容长度。 Content- Type:表示服务器返回文档属于什么MIME类型。 Location:当服务器返回状态为302跳转时,该字段表示客户端应该跳转到哪个URL。 - 响应体
用来表示服务器端返回的数据内容。
如上所述,我们对应用层(HTTP)协议首部格式有了基本的理解。其实,对网络流量分析的过程就是对每一层协议首部和数据部分进行解析,再将这些数据进行汇总,结合业务类型进行垂直业务分析。根据获取到的HTTP协议数据,我们可以实现满足如下需求的功能。
- 某个域名的正常访问流量、异常访问流量的统计查询。
- 域名访问来源的统计查询。
- 某些域名TOP N计算。
- 域名对应后端应用服务器的响应质量计算。
- 域名对应后端服务器的响应状态统计查询。
- 应用安全事件的统计查询。
- 安全事件关联分析。
其实能够实现的功能还有很多,因为我们已经拿到了原始数据包,并对每一层协议都有了清晰的认识,后续需要做的就是对业务需求的评审与实现。
Flow流量分析
通过前面对几种Flow技术的讲解和比较,以及对sFlow采样报文在设备上是如何进行采集介绍,我们对Flow技术有了基本的认识,本节将介绍作为sFlow Collector 是如何对sFlow采样数据包进行接收和分析的。对sFlow数据包进行分析的思路与我们对基于流量镜像网络数据包的分析是基本相同的,sFlow相当于应用层协议,传输层采用UDP传输协议封装,基本报文格式如图33-20所示。

sFlow 是基于UPD传输协议的C/S架构模式的应用程序,客户端就是运行在设备或者主机端的数据采集代理,而服务器端则负责对sFlow数据报文进行接收和解码。下面我们看一下开源sFlow tools 服务器端对sFlow V5版本sFlow数据报文解析的处理流程。
- ① 判断程序启动方式,是否是从本地读取pcap文件进行解析的;否则创建UDP服务器,同时支持IPv6版本,并且使用select I/O复用技术处理客户端请求。
- ② 获取上报数据,并且初始化SFSample结构体。
- ③ 判断是否开启了sFlow转发;否则进行SFSample数据结构解析流程。
- ④ 按照数据位偏移获取结构体中的各个字段。
- ⑤ 根据sampleType的值来读取具体的采样信息。
- ⑥ 解析结束。
在上述流程⑤中,sFlow支持两种数据采样方式供用户从不同维度来分析网络流量使用状况,分别是Flow采样和Counter采样。因版本不同共有4种数据结构格式,分别为Flow sample、Expanded Flow sample、Counter sample、Expanded Counter sample,其中Expanded Flow sample和Expanded Counter sample是sFlow V5中新增的内容,是对其老版本的扩展,但是不向前兼容。所有扩展的采样必须使用Expanded数据结构格式对数据进行封装,sFlow Agent分别以这几种数据结构格式填充sFlow Datagram应用数据字段进行发送。下面我们对这两种数据结构中的主要字段进行分析。
(1)Flow采样:
- Sampledethernet
eth_len:MAC包长度。 src_mac:源MAC地址。 dst_mac:目的MAC地址。 eth_type:在采样数据包中以太网的上层协议类型。 - Sampledipv4
length:IP包长度。 ip_protoco:在采样数据包中网络层的上层协议类型。 src_ip:源IP地址。 dst_ip:目的IP地址。 ip_tos:网络服务器类型。 ip_ttl:IP生存时间。 src_port:源端口。 dst_port:目的端口。 tcp_flags:TCP状态位。
(2)Counter采样
ifIndex:采集对象上的设备接口号。
ifType:标识接口的类型。
ifSpeed:传输速率,单位为bps。
ifDirection:0 = unknown,1=full-duplex,2=half-duplex,3 = in,4=out。
ifStatus:用于配置接口的状态(可读/写)up(1),down(2)bit0,testing(3),提供接口的当前工作状态up(1),down(2),testing(3)bit1。
ifInOctets:在接口上收到的总字节数。
ifInUcastPkts:接收到高层协议上的(单点发送)包的总数目(单播)。
ifInMulticastPkts:接收到高层协议上的多点发送包(多播)。
ifInBroadcastPkts:接收到高层协议上的广播总数目。
ifInDiscards:由于资源紧张导致丢弃的包的数目。如果一个接口的包丢弃率较高,则表示该设备存在拥塞问题。
ifInUnknownProtos:未知的二层封装协议的包。
ifInErrors:由于出错而导致丢弃的接收包的数目。错误率较高时表示存在接收器问题或坏线路问题。
ifOutOctets:从该接口上发送的字节总数。
ifOutUcastPkts:发送到一个子网单播地址的包的总数。
ifOutMulticastPkts:发送的多播包的总数。
ifOutBroadcastPkts:发送的广播包的总数。
ifOutDiscards:由于资源局限而导致丢弃的发出包的总数目。高丢包率表示需要为该接口分配更多的缓冲区空间。
ifOutErrors:由于出错而导致丢弃的发出包的总数目。高错误率表示存在硬件问题。
ifPromiscuousMode:接口是否处于混杂模式工作状态。
以上是我们对sFlow关于网络流量方面的采样。当然了,除了网络流量方面的采样,sFlow也可以采集设备的物理资源使用情况,比如设备CPU、内存等,还可以用于监控主机端的流量采样。采样技术与全流量技术相比,在大流量分析需求的强烈推动下,大家还是应该尝试应用一下,在这方面也有开源技术,比如InMon官网提供的sFlowTool与sFlowTrend,还有针对Netflow的开源实现NFsen,它也支持sFlow采样流量的收集,以及Ntop项目中的nProbe和ntopng结合使用,将原始流量转换成Flow再处理。总之,不论使用哪一种流量分析解决方案,首先都必须了解网络生产环境和用户需求,或者说是产品定位。
网络流量分析其实没有想象的那么难,但是实现更有价值的功能还是比较复杂的,如果组内有研发人员,并对网络结构有一定的认识,则完全可以自研,并可以满足全部需求。流量分析系统与传统的IDS和IPS等入侵检测系统不太一样,流量分析系统更关注大数据量的统计和关联分析,实时性要求不高;而入侵检测系统则更加侧重于实时特征匹配和实时防御。流量分析系统在部署的时候完全可以采用旁路的方式,这不会给现有的生产网络带来负面影响。流量分析系统给用户带来的好处是,可以更加透明和真实地了解当前网络流量的使用情况、应用服务器的服务质量、安全威胁等。最后希望本节内容在你日后建立网络流量分析系统时能有帮助。
总结
从网络设备端采集到后端数据分析平台,我们对每个环节分别介绍了相应的技术发展历程。在网络设备端采集方面,介绍了从最原始的HUB,到交换机SPAN,再到分光技术,以及现在比较流行的Flow采样技术,这也是在互联网企业流量爆发式增长背景之下应运而生的技术。服务器端的流量获取和分析也是如此,介绍了从Linux原生态的原始套接字抓包到Libpcap,再到PF_RING技术,以及目前比较火热的基于多核高性能数据包处理技术DPDK,当然具体采用什么技术方案,还是要看当前的业务需求和网络环境。
进阶:关于eBPF包捕获过滤技术,后续文章分解,请关注快猫星云博客站点。
本文遵循「知识共享许可协议 CC-BY-NC-SA 4.0 International」,未经作者书面许可,不允许用于商业用途的转载、分发、和演绎。本文内容,由 Wilbur、VicLai、GuanYu 等共同撰写,仅代表相关个人见解和立场,与任何公司、组织无关。


