

二十年里12个开源监控工具大对比
过去20年开源的或者商业的监控系统很多,具体可以参考维基百科的条目。一个完整的监控系统,往简单了讲,主要包括三个主要部分:数据采集、告警、数据图表展示。我们围绕这三个方面,对其中12款典型的开源工具做一些介绍和分析(按照星星排序索引如下):
Nightingale 夜莺监控 ⭐ ⭐ ⭐ ⭐ | Grafana全家桶 ⭐ ⭐ ⭐ ⭐| Prometheus ⭐ ⭐ ⭐ ⭐ | VictoriaMetrics ⭐ ⭐ ⭐ ⭐ | Zabbix ⭐ ⭐ ⭐ ⭐ | InfluxDB ⭐ ⭐ ⭐ | TDengine ⭐ ⭐ ⭐ | OpenFalcon ⭐ ⭐ ⭐ | Collectd ⭐ ⭐ | OpenTSDB ⭐ ⭐ | Cacti ⭐ ⭐ | RRDtool ⭐ ⭐ | Nagios ⭐ ⭐
注:本文会不定期持续更新,目前已经增加到为 13 个工具的对比。
1. Cacti
推荐指数: ⭐ ⭐
Cacti,最悠久的监控系统之一,2001年9月,一个名叫Lan Berry的高中生,当时他还在为一家小的ISP厂商工作,为了更好地监控网络质量,开发了Cacti的第一个版本,基于RRDtool,提供更友好的使用体验。
Cacti的数据采集,采用的是Server端poll的方式,在默认安装情况下,会有一个PHP的Poller,来定期执行相关的数据采集脚本,或者直接采集SNMP的接口输出,采集到的数据会以RRDtool的格式存储到磁盘上,供后续绘图、展示。在要采集的数据较多的情况下,PHP版本的Poller效率较低。为了解决这个问题,Cacti官方提供了一个组件Spine(早期叫Cactid),这是一个用C语言编写的多线程程序,用来代替PHP版本的Poller,有效地提升了数据采集效率。用户可以在Cacti提供的设备管理页,对设备列表进行增、删、改操作,来控制Poller要拉取的任务。
Cacti的数据图表展示,底层是基于RRDtool的,Cacti提供了一个用PHP开发的页面,可以让用户很方便地查看每个数据采集项的历史趋势图。Cacti提供了一个树状的graph列表,方便用户高效地组织、管理多个graph。另外,Cacti的graph预览功能很强大,允许在一个页面中放置大量的graph预览图,便于用户了解其所关注的指标全貌。
Cacti之所以很强大,原因在于其强大的插件。比如aggregate插件可以对多个采集项进行聚合展示,discovery插件用来自动发现设备,thold插件用来配置告警策略,slowlog插件可以方便地用来分析MySQL的慢查询等。完整的插件列表可以在 http://docs.Cacti.net/ plugins 查看,包括官方支持的和社区支持的。
2. RRDtool
推荐指数: ⭐ ⭐
RRDtool,在时间序列数据(time-series data)的存储、展示方面,其独创的round-robin database数据存储格式,曾经是事实上的工业标准。包括Cacti、MRTG、Collectd、Ganglia、Zenoss等系统,都是采用RRDtool的格式来存储数据,以及使用RRDtool的Graph工具来绘图的。
RRDtool使用的数据存储格式,大家也常常称之为环状数据库,其工作方式有三个显著的特点:第一,RRD文件在创建的时候,其文件大小就确定下来了,随着数据的不断写入,RRD文件的大小一直保持不变;第二,数据每次更新到RRD文件的时候,都会触发RRD文件中的归档策略,也就是数据采样策略;第三,查询历史数据的时候,会自动选择最优化的采样数据,而不是全量获取数据,查询效率很高。
RRDtool包含了一组工具集,用于创建RRD文件,更新RRD文件,获取RRD文件中的数据,根据RRD文件直接生成相应的图片等,具体可以参考http://oss.oetiker.ch/rrdtool。
使用RRDtool的过程中遇到过一些问题,RRDtool的数据是以文件的形式存储在磁盘上,以单机的形式来提供服务的,这样就存在容量上限。该上限的决定因素较多,比如磁盘容量、磁盘IO、CPU等,但是最核心的制约因素就是磁盘IO,用户每push一次数据,都会转化为对相应的RRD文件的一些全量的读/写,磁盘IO会最先遇到瓶颈。在一台普通的Linux服务器上,在1分钟push数据的频率下,一般20万条的Counter上报就会跑满磁盘IO。这显然无法满足较大规模数据下的监控需求。
为了在一定程度上缓解磁盘IO压力的问题,RRDtool官方提供了一个组件rrdcached,这是一个常驻内存的后台程序,用户可以把读/写请求通过网络发送给rrdcached,而不是直接操作磁盘。rrdcached内部做了一些优化措施来减轻对磁盘的读/写压力,包括:缓存RRD文件的header部分,每次数据push上来的时候可以减少一次读取操作;对RRD文件的写入,提供了用户态的缓存,即把用户的多次写入操作合并成一次flush到磁盘上,这样有效地提高了写入效率。通过该项优化,使得单机的容量提升不少。 不过上述优化,也只能解决一定程度上的问题,整体容量仍然局限于单机的容量上限。
3. Collectd
推荐指数: ⭐ ⭐
Collectd相比Cacti、RRDtool来说,较为年轻一些,项目最早是在2005年由Florian Forster开发的,之后便蓬勃发展成为一个开源的项目,很多开发者对其做了大量的改进和扩展。Collectd的定位是收集和传输数据。在告警方面不是Collectd的设计初衷,不过它也支持一些简单的阈值判定,并发送告警信息。要支持更高级的一些告警需求,Collectd可以和Nagios配合使用,有一个名为collectd-nagios 的插件可以很方便地完成这个功能。
Collectd是一个用C语言开发的常驻内存的程序,由一堆功能强大的插件组成,其架构示意图如图1所示。
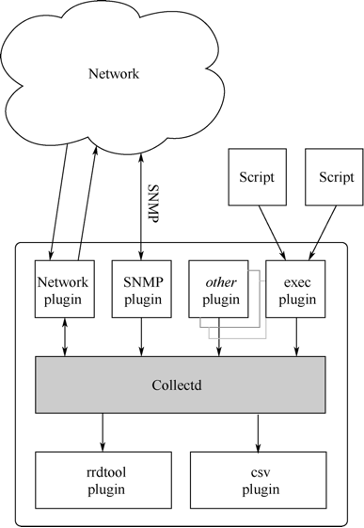
插件化是Collectd最重要的一个设计思想,Collectd的所有功能都是通过插件来支持的,Collectd自身没有任何额外的依赖,这使得它几乎可以跑在大多数的操作系统上,包括一些嵌入式系统如OpenWrt。从图1来看,用户可以通过各种插件push数据到Collectd,然后通过RRDtool插件存储为RRD的格式,或者通过CSV插件存储为CSV的格式。Collectd支持的上百个插件,可以在该列表中查阅。
4. Nagios
推荐指数: ⭐ ⭐
前面讲到的几个系统,都专注于数据的采集、传输、聚合、存储和展示。说到告警,Nagios可谓是事实上的工业标准,可以用来监控主机和网络基础设施,以及各种应用服务。在监控对象出现问题时,及时发送邮件或者短信通知相关人员;当问题解决后,发送恢复信息。
Nagios 从结构上来说,可以分为核心和插件两个部分。Nagios 的核心部分只提供了很少的监控功能,因此要搭建一个完善的监控管理系统,用户还需要在Nagios服务器上安装相应的插件,插件可以从Nagios官方网站http://www.nagios.org 下载,也可以根据实际要求自己编写所需的插件。
Nagios可以监控各种网络服务,比如SMTP、POP3、HTTP、NTP、ICMP、FTP、SSH等,也可以监控主机资源,比如CPU、Load、磁盘使用、Syslog等。基本工作模式如图2所示。
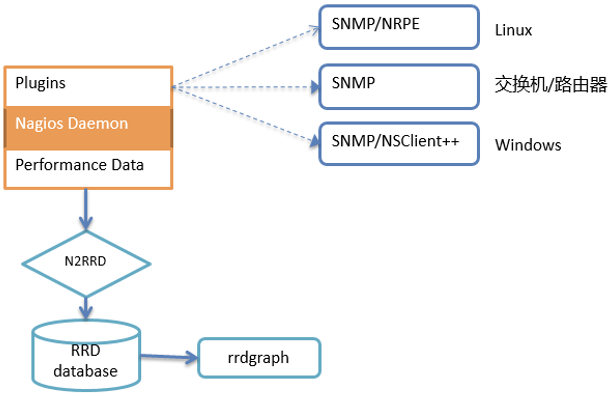
这里介绍两个比较重要的概念:NRPE和SNMP。
NRPE的全称是Nagios Remote Plugin Executor,是Nagios的Agent,这可以让Nagios具备监控远程主机和设备的能力。Nagios服务端,通过check_nrpe插件会定期地调用运行在远程主机上的NRPE,执行具体的脚本来获取数据,比如check_load、check_disk、check_ftp等。
SNMP(Simple Network Management Protocol,简单的网络管理协议)是一种应用层协议,被路由器、交换机、服务器、工作站、打印机等网络设备广泛支持,主要用于管理和监控网络设备。SNMP的工作方式主要有三种:管理员需要向设备获取数据,SNMP提供了“读”操作;管理员需要向设备执行设置操作,SNMP提供了“写”操作;设备需要在重要状况改变的时候,向管理员通报事件的发生,SNMP提供了“Trap”操作。
SNMP的基本思想是:为不同种类的设备、不同厂家生产的设备、不同型号的设备,定义一个统一的接口和协议,使得管理员可以使用统一的方式对这些需要管理的网络设备进行管理。通过网络,管理员可以管理位于不同物理空间的设备,从而大大提高了网络管理的效率,简化了网络管理员的工作。Nagios很好地利用了SNMP的读和Trap功能,很容易地获取各种网络设备的运行数据,达到监控的目的。

进阶:关于SNMP监控更多内容,可以查看快猫星云系列文章《网络监控:交换机监控新姿势》、 《SNMP(简单网络管理协议)简介》、《SNMP命令相关参数介绍》、《通过 Categraf SNMP 插件采集监控数据》
5. Zabbix
推荐指数: ⭐ ⭐ ⭐ ⭐
Zabbix作为一款企业级分布式监控系统,功能齐全,用户体验良好,文档完善,API强大,适合于中小规模的公司或者团队使用。
进阶:关于Zabbix和夜莺监控的详细介绍,请阅读快猫系列文章《Zabbix 和夜莺监控选型对比》
Zabbix的主要特点有:
- 文档齐全,安装、维护、学习成本低。
- 多语言支持。
- 完全免费开源。当然,如果需要技术支持的话,Zabbix官方是收费的。
- 自动发现服务器和网络设备,便于用户配置。
- 支持告警策略模板的概念,方便用户对一批服务器的监控策略进行管理。
- 用户体验良好的Web端,用户可以进行集中配置、维护和管理。
- Zabbix Agent功能强大,默认的采集项足够丰富,且支持用户自定义插件扩展。
- 不用Agent配合,也可以完成监控任务,支持SNMP、JMX等标准的协议,用户也可以自行推送数据- 控系统中。
- Web端也提供了良好的Dashboard功能、绘图查看功能。
- 可以配置历史数据的存储周期,历史数据支持采样存储。
- 支持分布式监控,比如多个IDC之间,或者有防火墙阻隔。
- 强大、完善的API支持。
在以上特点中,尤其是API功能,完善程度很高,基本上Zabbix的大部分操作都提供了相应的API接口,方便用户编程,和现有的一些系统进行整合。比如以下一些场景。
- 利用历史数据查询API,定期从Zabbix中获取线上服务器的各项资源使用情况,生成每日检查报表;同时,对某些资源使用率不达标的服务器和业务进行筛选,每周进行通报,有效地促进资源利用率的提高。
- 利用Zabbix graph的API,可以对关注的指标获取对应的趋势图,嵌入到各个运维系统中,方便运维人员快速地了解服务情况。
- 利用Zabbix的告警添加API,可以让监控系统和部署系统联动起来。比如某个模块增加了一个实例,那么可以自动添加所需要的监控策略;反之,下线一个实例,可以自动删除关联的监控策略。
Zabbix主要由Server、Agent、Proxy和Web-portal几个部分组成。典型的Zabbix的部署模式如下图所示。
Zabbix的数据采集,主要有两种模式:Server主动拉取数据和Agent主动上报数据。以前者为例,用户在Web-portal中,配置好机器,并给机器应用相应的模板后,Zabbix-server就会定期地去获取Agent的数据,存储到MySQL中,同时根据用户配置的策略,判定是否需要告警。用户可以在Web端,以图表的形式,查看各种指标的历史趋势。
在Zabbix中,将Server主动拉取数据的方式称之为active check。这种方式配置起来较为方便,但是会对Zabbix-server的性能存在影响,所以在生产环境中,一般会选择主动推送数据到Zabbix-server的方式,称之为trapper。即用户可以定时生成数据,再按照Zabbix定义的数据格式,批量发送给Zabbix-server,这样可以大大提高Server的处理能力。
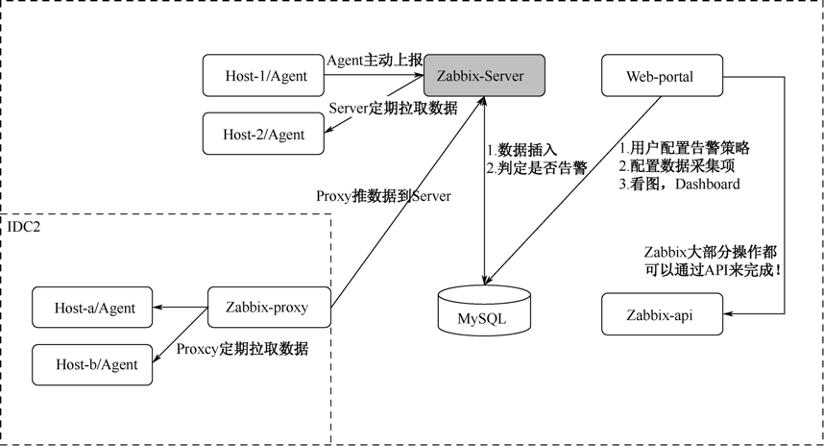
Proxy是Zabbix具备分布式监控能力的一个必备条件,试想我们有一批服务器和网络设备位于防火墙之后,Zabbix-server无法直接访问这些Agent,这时候我们可以选择在防火墙的后面放置一个Zabbix-proxy,那么Proxy就会充当Server的角色,定期收集它所负责的这些Agent的数据,然后定期推送回Zabbix-server。另外,Proxy还可以分担Server的压力,代替Server定期拉取数据,再统一push给Server,这样可以有效地降低Server的开销。
在Zabbix的设计中,以下几个概念是最重要的。
- Host:主机,是Zabbix里面的监控主体,可以是服务器,也可以是网络设备,通过DNS或者IP地址连接。
- Item:Host的某个数据采集项,比如hostA的cpu_idle就是一个Item。
- Template:这是Zabbix的一个很先进的概念,是对具有相同属性和资源的Host的一种抽象。即与Template关联的Host,会自动具备该Template所具有的Item、Trigger、Graph等属性。同时Template具备继承的能力。
- Trigger:触发器,具有三种状态,即unknown、problem和ok。只有当状态从problem变为ok时候,或者ok变为problem的时候,才会触发相关的Action。当Zabbix-server每次取到Item的值与这个Item相关的Trigger都会被检查一次,并生成相应的Event。
- Action:顾名思义,就是执行动作,Zabbix的Action支持多种动作的执行,用户可以配置满足什么的条件,做什么样的动作,动作包括发短信、发邮件、执行脚本等。
- Event:当Trigger的状态每发生一次变化时,就会产生一个Event。
Zabbix在业务处于较小规模的时候,效果还是相当不错的。但是当监控的对象超过上千台设备,并且还包括一些服务自身的业务指标也推送到Zabbix的时候,我们遇到了两个严重的问题——Zabbix的性能问题和用户的“使用效率”低下问题。
Zabbix的性能问题主要存在两个方面,一是Zabbix-server处理能力有限,尤其当active check模式的采集项较多的时候,会显著消耗Server的Puller线程,使得数据采集延迟,产生堆积,造成报警延迟。我们可以调大Puller的线程数,缓解这个问题,但Zabbix-server自身无法水平扩展,所以不能解决根本问题;二是Zabbix的数据存储引擎存在性能瓶颈,我们线上采用的是MySQL,当数据采集项过多的时候,比如在每分钟大概有20万采集项的规模下,MySQL的写入会达到瓶颈。
综上所述,在业务规模较小的前提下,Zabbix是一个很可靠的开源解决方案。在业务规模不断增长的情况下,需要投入较多的精力在其性能优化上。
6. OpenTSDB
推荐指数: ⭐ ⭐
OpenTSDB是最具代表性的时间序列数据(time-series data)存储和展示的分布式解决方案之一,遵守LGPL开源协议。OpenTSDB具有以下特点。
- 数据存储:基于HBase,并且存储的都是用户上报的原始数据,不会对数据进行采样和钝化处理,历史数据可以一直保存。支持毫秒级别的数据上报频率。
- 可扩展性:由于后端的数据存储引擎是HBase,因此可以轻易地支撑每秒上百万次的数据更新操作,并且处理能力随着HBase节点数量的增加而增加。
- 数据查询:OpenTSDB提供了友好的用户访问界面,方便用户查看相关的数据趋势。另外,也提供了HTTP方式的数据获取接口,方便用户通过编程,自动化地获取HBase中的历史数据,用作其他用途。不仅可以查询单个指标的历史数据,OpenTSDB还提供了强大的聚合功能,比如可以查看多个指标求和后的数据。
OpenTSDB的部署结构和工作流程如下图所示。
HBase为数据存储引擎,TSD是OpenTSDB最核心的组件,和HBase的所有数据交互都通过TSD来完成。TSD是一个常驻内存的进程,是无状态的,可以水平扩展。
我们可以通过tcollector来收集每台服务器的各个指标,然后推送给TSD;也可以通过SNMP来获取网络设备的各项指标,推送给TSD。TSD收到数据后,会更新到后端的HBase中。
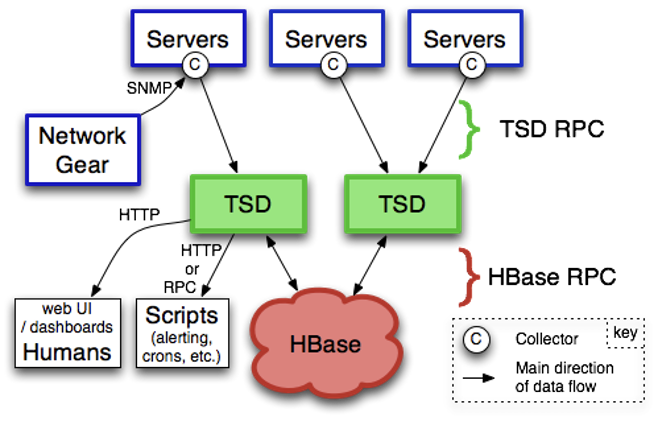
OpenTSDB提供了Web界面,通过HTTP的接口向TSD查询数据;我们也可以编写一些插件,比如告警插件,从TSD中获取某个指标的数据来判定是否满足阈值,以及是否需要告警。
OpenTSDB的出现,让时间序列数据的存储和展示多了一个很好的选择。对于大量写入的场景非常有用。不过也存在一些不足的地方,比如历史数据的查询速度较慢:由于OpenTSDB存储的是原始数据,没有做任何采样,因此在需要查询某几个指标在过去一个月甚至一年的历史数据的时候,TSD真的就会去HBase中扫描相应时段的所有数据。首先,数据量很大;其次,读操作并不是HBase最擅长的;最后,费了好大力气获取到大量的数据,也无法很好地展现给用户,仍然需要应用程序对数据做采样,造成无谓的一些消耗和浪费。
7. TDengine
推荐指数: ⭐ ⭐ ⭐
TDengine 是一款开源、云原生的时序数据库,专为物联网、工业互联网、金融、IT 运维监控等场景设计并优化。它能让大量设备、数据采集器每天产生的高达 TB 甚至 PB 级的数据得到高效实时的处理,对业务的运行状态进行实时的监测、预警,从大数据中挖掘出商业价值。
TDengine 能够与开源数据可视化系统 Grafana 快速集成搭建数据监测报警系统,整个过程无需任何代码开发,TDengine 中数据表的内容可以在仪表盘(DashBoard)上进行可视化展现。关于 TDengine 插件的使用您可以在GitHub中了解更多。
此外,TDengine也可以作为Prometheus的分布式时序数据库,来解决存储的扩展性问题。Prometheus 是一款流行的开源监控告警系统。Prometheus 于2016年加入了 Cloud Native Computing Foundation (云原生云计算基金会,简称 CNCF),成为继 Kubernetes 之后的第二个托管项目,该项目拥有非常活跃的开发人员和用户社区。
Prometheus 提供了 remote_write 和 remote_read 接口来利用其它数据库产品作为它的存储引擎。为了让 Prometheus 生态圈的用户能够利用 TDengine 的高效写入和查询,TDengine 也提供了对这两个接口的支持。
通过适当的配置, Prometheus 的数据可以通过 remote_write 接口存储到 TDengine 中,也可以通过 remote_read 接口来查询存储在 TDengine 中的数据,充分利用 TDengine 对时序数据的高效存储查询性能和集群处理能力。
注意:Prometheus数据在写入到TDengine的时候,需要经过taosadapter的转发。
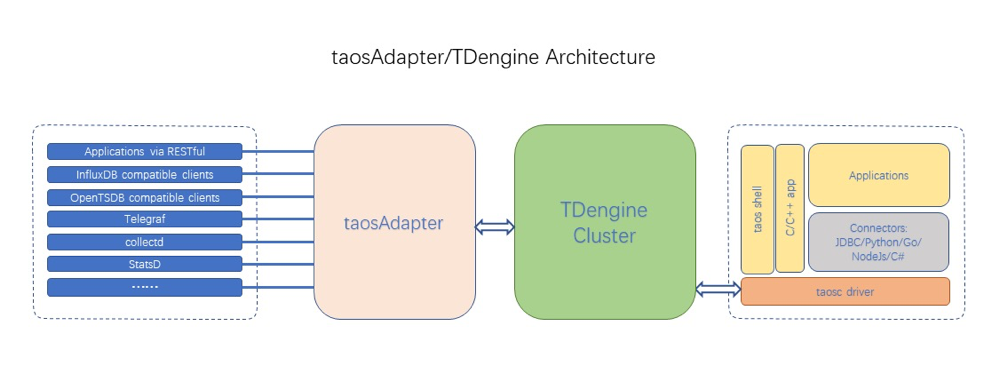
8. InfluxDB
推荐指数: ⭐ ⭐ ⭐
influxdb 是一个现代化的开源时序数据库(相比rrdtool、opentsdb等),他有以下特点:
- 创新性的定义了表达能力更强的时序数据模型,引入了
Label标签; - 配套的数据采集器 telegraf,是监控数据采集领域内领先的开源工具;
- 定义和实现了强大灵活的数据查询和处理语言 FluxQL,用户可以像使用SQL查询关系型数据库那样,采用FluxQL来查询Influxdb;
使用开源版本的Influxdb,你需要关注两点:
- 开源版本的Influxdb是单机版本,不支持水平扩展,因此如果您的数据量过大,要么采用部署多个Influxdb来分担承载数据,要么购买其企业版本或者使用Influxdb Cloud;
- Influxdb 是支持字符串数据类型的,所以相应的 telegraf 采集的很多 field 是字符串类型,另外 influxdb 的设计,允许 labels 是非稳态结构,比如 result_code 标签,有时其 value 是 0,有时其 value 是 1,在 influxdb 中都可以接受。但是上面两点,在类似 prometheus 的时序库中,处理起来就很麻烦。
9. VictoriaMetrics
推荐指数: ⭐ ⭐ ⭐ ⭐
VictoriaMetrics 是一款开源的、可扩展的、与Prometheus无缝兼容的时序数据库。其架构简单,可靠性高,在性能,成本,可扩展性方面表现出色,社区活跃,且和 Prometheus 生态绑定紧密。如果单机版本的 Prometheus 无法在容量上满足贵司的需求,可以使用 VictoriaMetrics 作为时序数据库。
VictoriaMetrics 提供单机版和集群版。如果您的每秒写入数据点数小于100万(这个数量是个什么概念呢,如果只是做机器设备的监控,每个机器差不多采集200个指标,采集频率是10秒的话每台机器每秒采集20个指标左右,100万/20=5万台机器),VictoriaMetrics 官方默认推荐您使用单机版,单机版可以通过增加服务器的CPU核心数,增加内存,增加IOPS来获得线性的性能提升。且单机版易于配置和运维。
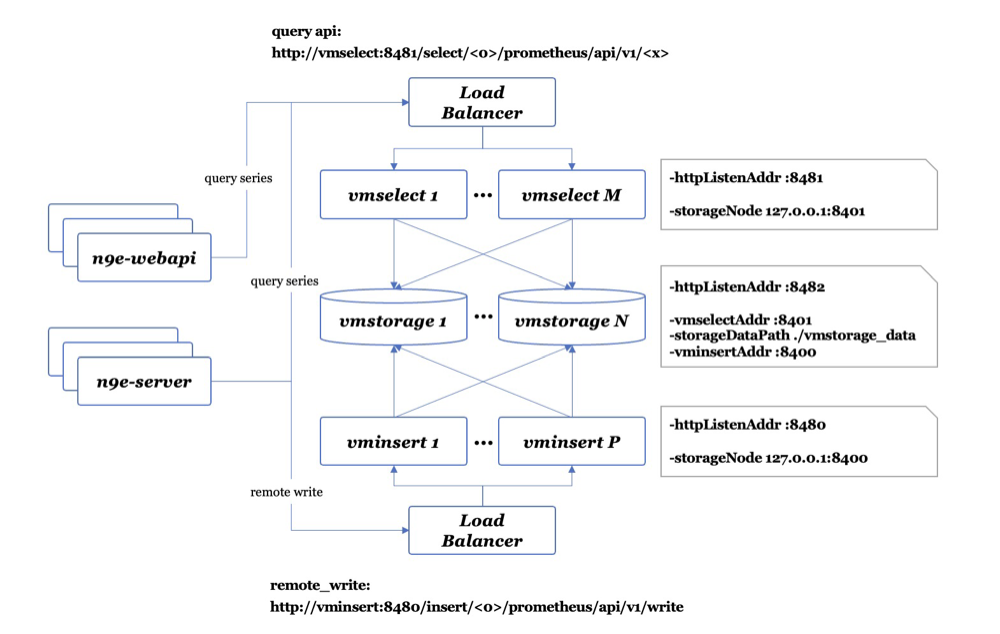
vmstorage、vminsert、vmselect 三者组合构成 VictoriaMetrics 的集群功能,三者都可以通过启动多个实例来分担承载流量,通过要在 vminsert 和 vmselect 前面架设负载均衡。
vmstorage 是数据存储模块:
- 其数据保存在
-storageDataPath指定的目录中,默认为./vmstorage-data/,vmstorage 是有状态模块,删除 storage node 会丢失约1/N的历史数据(N 为集群中 vmstorage node 的节点数量)。增加 storage node,则需要同步修改 vminsert 和 vmselect 的启动参数,将新加入的storage node节点地址通过命令行参数-storageNode传入给vminsert和vmselect - vmstorage 启动后,会监听三个端口,分别是
-httpListenAddr :8482、-vminsertAddr :8400、-vmselectAddr :8401。端口8400负责接收来自 vminsert 的写入请求,端口8401负责接收来自 vmselect 的数据查询请求,端口8482则是 vmstorage 自身提供的 http api 接口
vminsert 接收来自客户端的数据写入请求,并负责转发到选定的vmstorage:
- vminsert 接收到数据写入请求后,按照 jump consistent hash 算法,将数据转发到选定的某个vmstorage node 上。vminsert 本身是无状态模块,可以增加或者删除一个或多个实例,而不会造成数据的损失。vminsert 模块通过启动时的参数
-storageNode xxx,yyy,zzz来感知到整个 vmstorage 集群的完整 node 地址列表 - vminsert 启动后,会监听一个端口
-httpListenAddr :8480。该端口实现了prometheus remote_write协议,因此可以接收和解析通过remote_write协议写入的数据。不过要注意,VictoriaMetrics 集群版本具有多租户功能,因此租户ID会以如下形式出现在 API URL 中:http://vminsert:8480/insert/<account_id>/prometheus/api/v1/write - 更多 URL Format 可以参考 VictoriaMetrics官网
vmselect 接收来自客户端的数据查询请求,并负责转发到所有的 vmstorage 查询结果,最后将结果 merge 后返回:
- vmselect 启动后,会监听一个端口
-httpListenAddr :8481。该端口实现了prometheus query相关的接口。不过要注意,VictoriaMetrics 集群版本具有多租户功能,因此租户ID会以如下形式出现在 API URL 中:http://vminsert:8481/select/<account_id>/prometheus/api/v1/query。 - 更多 URL Format 可以参考 VictoriaMetrics官网
10. Prometheus
推荐指数: ⭐ ⭐ ⭐ ⭐
Prometheus 是由前 Google 工程师从 2012 年开始在 Soundcloud 以开源软件的形式进行研发的系统监控和告警工具包,自此以后,许多公司和组织都采用了 Prometheus 作为监控告警工具。Prometheus 的开发者和用户社区非常活跃,它现在是一个独立的开源项目,可以独立于任何公司进行维护。为了证明这一点,Prometheus 于 2016 年 5 月加入 CNCF 基金会,成为继 Kubernetes 之后的第二个 CNCF 托管项目。
Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。 相比于传统监控系统Prometheus具有以下优点:
1. 易于管理
Prometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。
Prometheus基于Pull模型的架构方式,可以在任何地方(本地电脑,开发环境,测试环境)搭建我们的监控系统。对于一些复杂的情况,还可以使用Prometheus服务发现(Service Discovery)的能力动态管理监控目标。
2. 监控服务的内部运行状态
Pometheus鼓励用户监控服务的内部状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
3. 强大的数据模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。 如下所示:
http_request_status{code='200',content_path='/api/path', environment='produment'} => [value1@timestamp1,value2@timestamp2...]
http_request_status{code='200',content_path='/api/path2', environment='produment'} => [value1@timestamp1,value2@timestamp2...]
每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识。每条时间序列按照时间的先后顺序存储一系列的样本值。
表示维度的标签可能来源于你的监控对象的状态,比如code=404或者content_path=/api/path。也可能来源于的你的环境定义,比如environment=produment。基于这些Labels我们可以方便地对监控数据进行聚合,过滤,裁剪。
4. 强大的查询语言PromQL
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
通过PromQL可以轻松回答类似于以下问题:
- 在过去一段时间中95%应用延迟时间的分布范围?
- 预测在4小时后,磁盘空间占用大致会是什么情况?
- CPU占用率前5位的服务有哪些?(过滤)
5. 高效
对于监控系统而言,大量的监控任务必然导致有大量的数据产生。而Prometheus可以高效地处理这些数据,对于单一Prometheus Server实例而言它可以处理:
- 数以百万的监控指标
- 每秒处理数十万的数据点。
6. 可扩展
Prometheus是如此简单,因此你可以在每个数据中心、每个团队运行独立的Prometheus Sevrer。Prometheus对于联邦集群的支持,可以让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)可以对其进行扩展。
7. 易于集成
使用Prometheus可以快速搭建监控服务,并且可以非常方便地在应用程序中进行集成。目前支持: Java, JMX, Python, Go,Ruby, .Net, Node.js等等语言的客户端SDK,基于这些SDK可以快速让应用程序纳入到Prometheus的监控当中,或者开发自己的监控数据收集程序。同时这些客户端收集的监控数据,不仅仅支持Prometheus,还能支持Graphite这些其他的监控工具。
同时Prometheus还支持与其他的监控系统进行集成:Graphite, Statsd, Collected, Scollector, muini, Nagios等。
Prometheus社区还提供了大量第三方实现的监控数据采集支持:JMX, CloudWatch, EC2, MySQL, PostgresSQL, Haskell, Bash, SNMP, Consul, Haproxy, Mesos, Bind, CouchDB, Django, Memcached, RabbitMQ, Redis, RethinkDB, Rsyslog等等。
8. 可视化
Prometheus Server中自带了一个Prometheus UI,通过这个UI可以方便地直接对数据进行查询,并且支持直接以图形化的形式展示数据。同时Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案Promdash。最新的Grafana可视化工具也已经提供了完整的Prometheus支持,基于Grafana可以创建更加精美的监控图标。基于Prometheus提供的API还可以实现自己的监控可视化UI。
9. 开放性
通常来说当我们需要监控一个应用程序时,一般需要该应用程序提供对相应监控系统协议的支持。因此应用程序会与所选择的监控系统进行绑定。为了减少这种绑定所带来的限制。对于决策者而言要么你就直接在应用中集成该监控系统的支持,要么就在外部创建单独的服务来适配不同的监控系统。
而对于Prometheus来说,使用Prometheus的client library的输出格式不止支持Prometheus的格式化数据,也可以输出支持其它监控系统的格式化数据,比如Graphite。
因此你甚至可以在不使用Prometheus的情况下,采用Prometheus的client library来让你的应用程序支持监控数据采集。
上述 prometheus 介绍文字,引用自:prometheus book by yunlzheng
不过prometheus在落地生产环境的过程中,目前存在以下痛点:
- 现有开源组合方案 Prometheus + Alertmanager + Grafana 多个系统较为割裂,无法开箱即用;
- 通过修改配置文件来管理 Prometheus、Alertmanager ,学习曲线大,用户量多时,协同有难度;
- 数据量过大而无法有效扩展 Prometheus 集群;
- 生产环境运行多套 Prometheus 集群,面临分区管理和使用成本高的问题;
- Metric、Log、Trace 等数据要素贯通,对于故障定位、性能分析至关重要;
11. Open-Falcon
推荐指数: ⭐ ⭐ ⭐
监控系统是整个运维环节,乃至整个产品生命周期中最重要的一环,事前及时预警发现故障,事后提供翔实的数据用于追查定位问题。监控系统作为一个成熟的运维产品,业界有很多开源的实现可供选择。当公司刚刚起步,业务规模较小,运维团队也刚刚建立的初期,选择一款开源的监控系统,是一个省时省力,效率最高的方案。之后,随着业务规模的持续快速增长,监控的对象也越来越多,越来越复杂,监控系统的使用对象也从最初少数的几个SRE,扩大为更多的DEVS,SRE。这时候,监控系统的容量和用户的“使用效率”成了最为突出的问题。
open-falcon是小米技术团队开发开源的一款互联网企业级监控系统,重在解决日益增长的监控数据量和监控系统的容量限制之间的矛盾。open-falcon在架构设计上,一个最关键的考量点就是“如何做到水平扩展”。
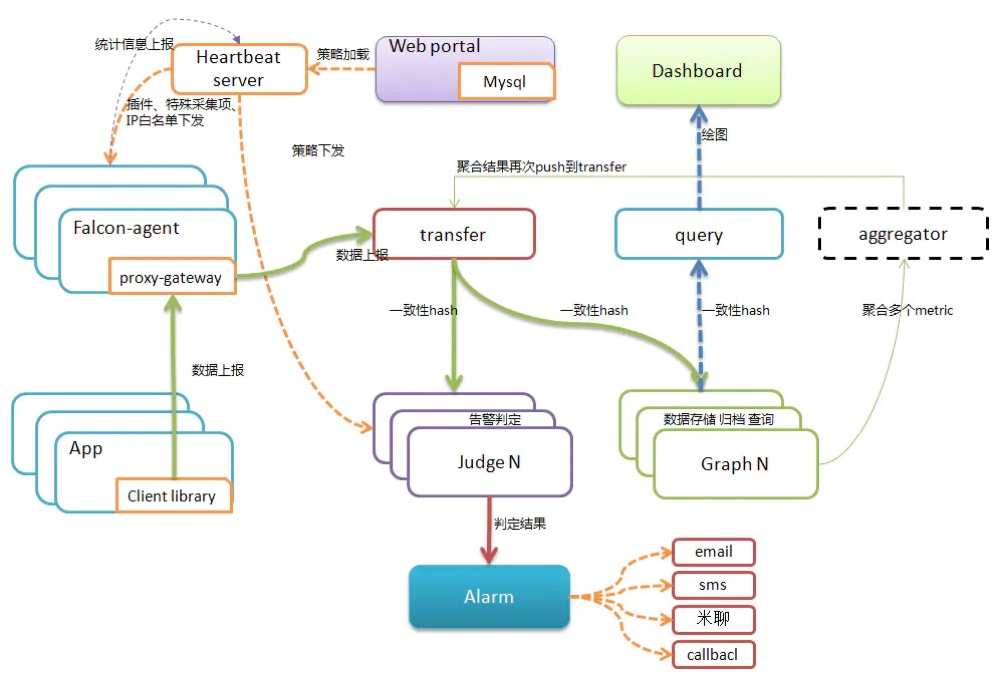
open-falcon的优势
- 强大灵活的数据采集:自动发现,支持falcon-agent、snmp、支持用户主动push、用户自定义插件支1. 持、opentsdb data model like(timestamp、endpoint、metric、key-value tags)
- 水平扩展能力:支持每个周期上亿次的数据采集、告警判定、历史数据存储和查询
- 高效率的告警策略管理:高效的portal、支持策略模板、模板继承和覆盖、多种告警方式、支持1. callback调用
- 人性化的告警设置:最大告警次数、告警级别、告警恢复通知、告警暂停、不同时段不同阈值、支持维护1. 周期
- 高效率的graph组件:单机支撑200万metric的上报、归档、存储(周期为1分钟)
- 高效的历史数据query组件:采用rrdtool的数据归档策略,秒级返回上百个metric一年的历史数据
- dashboard:多维度的数据展示,用户自定义Screen
- 高可用:整个系统无核心单点,易运维,易部署,可水平扩展
- 开发语言: 整个系统的后端,全部golang编写,portal和dashboard使用python编写。
open-falcon在架构设计上的特点
- 定义了可扩展的数据模型(label),引入了标签的概念,可以大大增强监控指标的表达能力;
- 从一开始就设计了专属的数据采集器falcon-agent,数据采什么、怎么采、采了怎么用,都考虑到了,做到了开箱即用,知识沉淀。
- 数据采用“推”的方式;falcon-agent采集到的数据,直接推送到transfer组件,当然用户也可以通过transfer的api来推送自定义数据;(保障了时效性、方便研发团队接入数据)
- transfer 组件,是数据传输网关,可以水平扩展,同时transfer会根据一定的数据分片规则,将数据推送给存储模块graph、以及告警判定模块judge。
- 在整个open-falcon的架构中,核心思想是采用数据分片架构解决扩展性问题。比如 transfer 模块本身是无状态的,可以水平扩展;graph组件是按照一致性hash算法对数据进行分片存储,judge模块也是按照一致性hash算法来处理特定分片的数据和任务;
- 最后,open-falcon 不仅仅是一个工具,更多的是一个产品,将互联网公司的运维经验沉淀到产品中,同时具有较高的产品完成度,在数据采集、管理portal、可视化、告警判定、告警通知、等方面,都有不错的表现;
open-falcon的不足
- 在数据模型上,虽然很早(2013年)就引入标签的维度,但是未能和Prometheus的数据模型看齐,导致后续在生态的融合上出现额外的障碍
- 采用推的数据模型,在“控制”方面会比较弱(要做好流控、脏数据控制等能力),对于数据中断的监控无法感知(增加了“nodata”的额外逻辑,Prometheus是在scrape数据的时候,提供了target_up指标)
- 流式的judge模型,天然无法很好的解决多条件组合报警等复杂判定(aggregator解决了一部分问题)
- proxy架构,没有很好的解决数据再平衡的问题(虽然提供了扩缩容时migrate数据的方案,但是运维操作比较复杂。vm采用的proxy的架构)
- 基于RRD的数据格式,环状数据库,虽然磁盘的使用效率很高,但是磁盘 IO 负载很高(虽然做了优化,将小文件的随机写入,加了写的缓存,修改为批量写入等)此外对于adhoc查询,支持比较弱。
12. Nightingale(夜莺监控)
推荐指数: ⭐ ⭐ ⭐ ⭐
夜莺监控是一款开源云原生监控分析系统,采用 All-In-One 的设计理念,集数据采集、可视化、监控告警、数据分析于一体,与云原生生态紧密集成,提供开箱即用的企业级监控分析和告警能力,已有众多企业选择将 Prometheus + AlertManager + Grafana 的组合方案升级为使用夜莺监控。夜莺监控,由滴滴开发和开源,并于 2022 年 5 月 11 日,捐赠予中国计算机学会开源发展委员会(CCF ODC),为 CCF ODC 成立后接受捐赠的第一个开源项目,在GitHub上有超过9000个Star。
夜莺监控的特点
- 夜莺监控用户界面好看,功能全面,是一个all-in-one监控产品;
- 配套开箱即用的监控数据采集器categraf,同时支持指标、日志、链路追踪数据的采集;
- 同时适合传统架构 & 云原生架构 & 混合云架构;
- 多数据源架构设计,适应灵活多变的部署环境和生态;
- 可扩展架构设计,水平灵活扩展;
- 兼顾中心化部署和边缘设备集群管理;
- Go语言开发,安全,易维护,架构简洁;
夜莺优势1:灵活的告警规则
夜莺主要是告警引擎这块做得最方便,告警规则的配置也较为灵活,告警规则支持级别抑制、生效时间配置、事件 relabel、告警屏蔽、告警订阅、告警自愈等等。告警规则的配置界面如下:
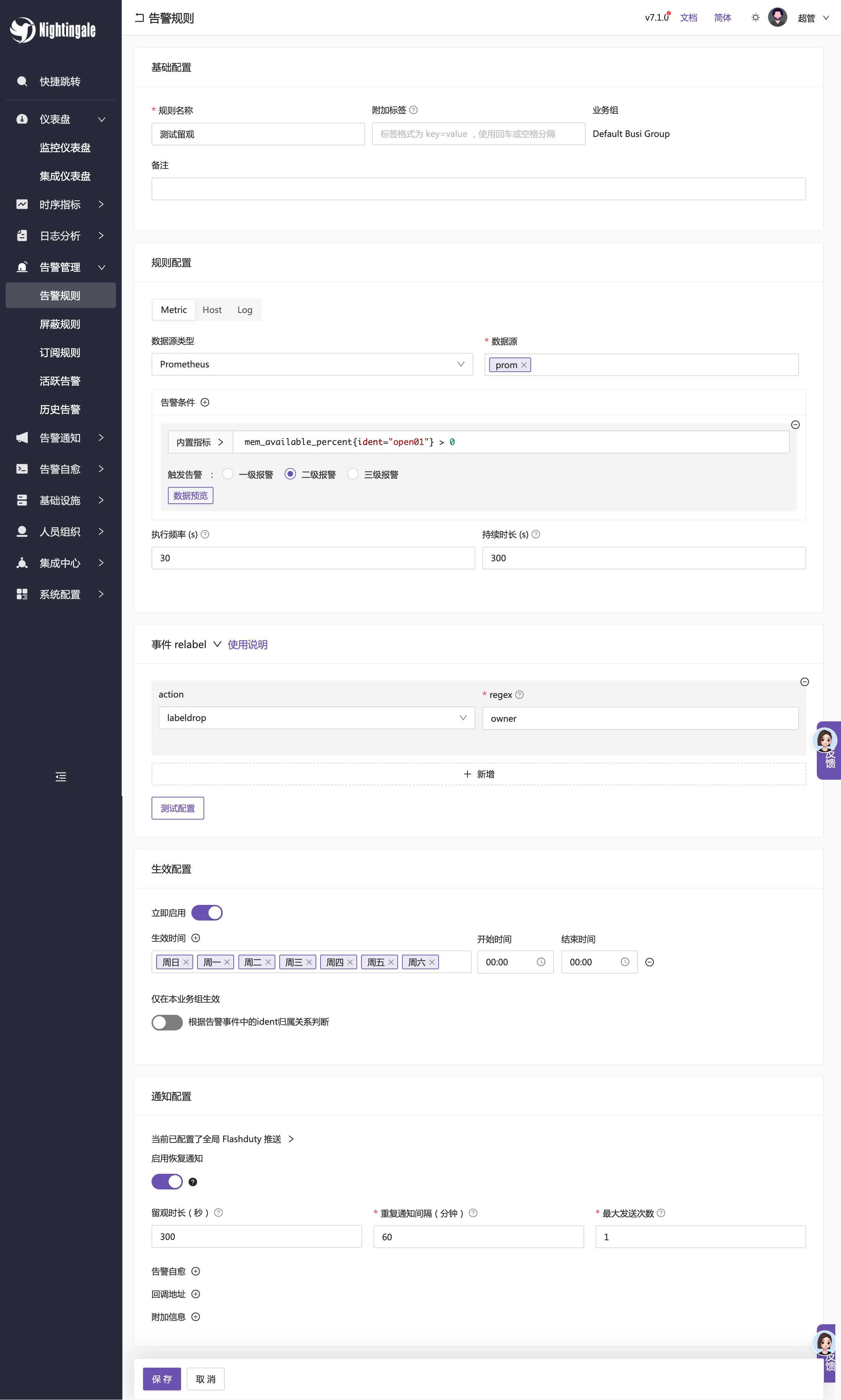
- 数据源支持配置多个,也可以选择全部,即:一条告警规则生效到多个数据源
- 告警规则支持多条,可以启用级别抑制,编写 promql 时可以调出内置指标,方便编写
- 事件 relabel 是对告警事件的二次处理,比如 drop 掉一些不想要的标签
- 生效时间用于配置告警规则的生效时间,比如只在工作日生效,周末不生效,或者只在白天生效,晚上不生效,或者不同时段不同阈值
- 告警自愈是告警触发之后,自动执行一些脚本,串联一些固定止损操作
- 回调地址是告警触发之后,调用第三方接口,比如钉钉、飞书等,进行告警通知,也可以对接各个公司自定义的接口
夜莺优势2:内置很多最佳实践
夜莺除了对接时序库,还可以对接各类采集器 agent,比如 telegraf、categraf、datadog-agent、各类 exporter 等,不同的数据库、中间件都有提供一些现成的仪表盘、告警规则,这样可以快速上手,省心不少。下面是夜莺内置的模板中心:
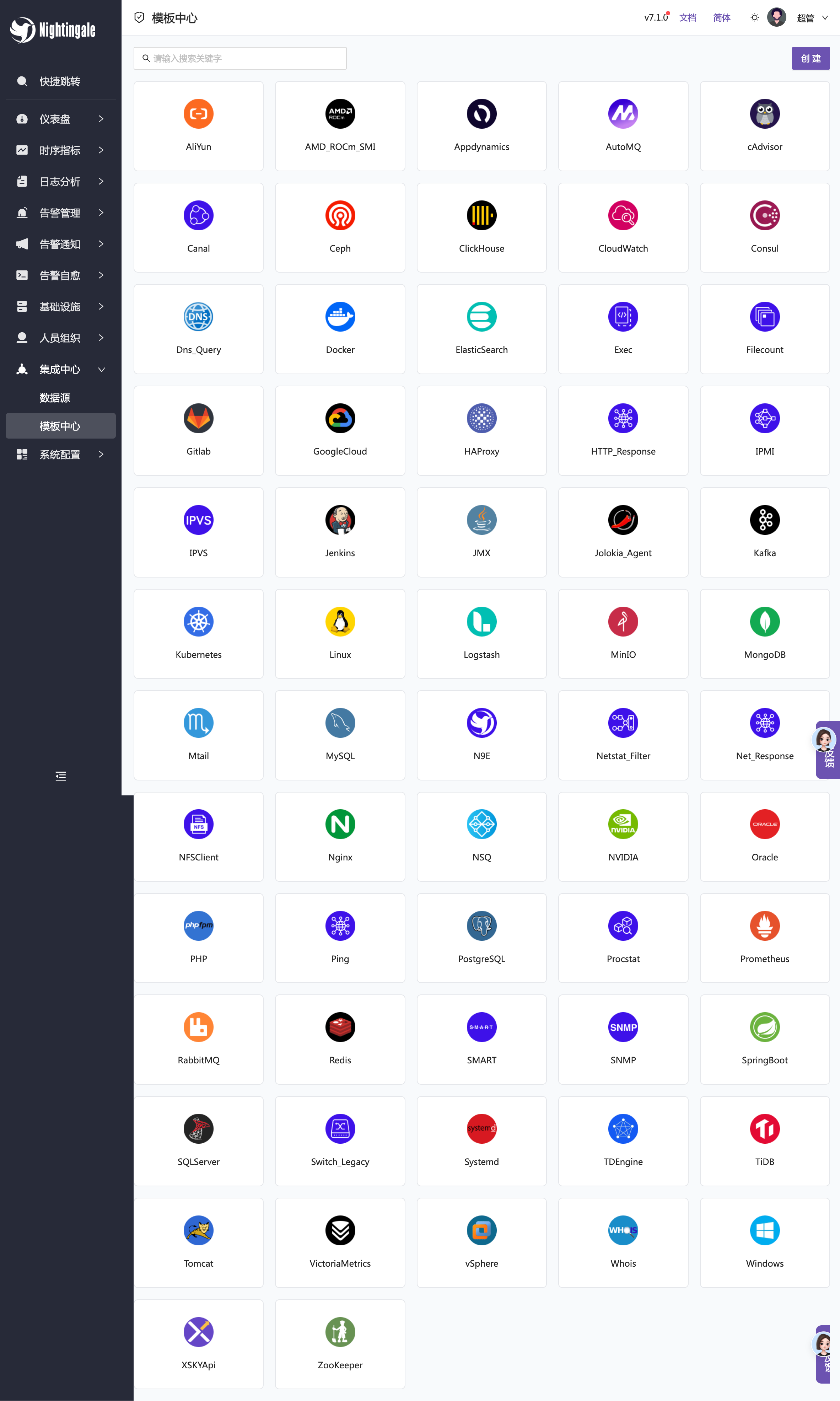
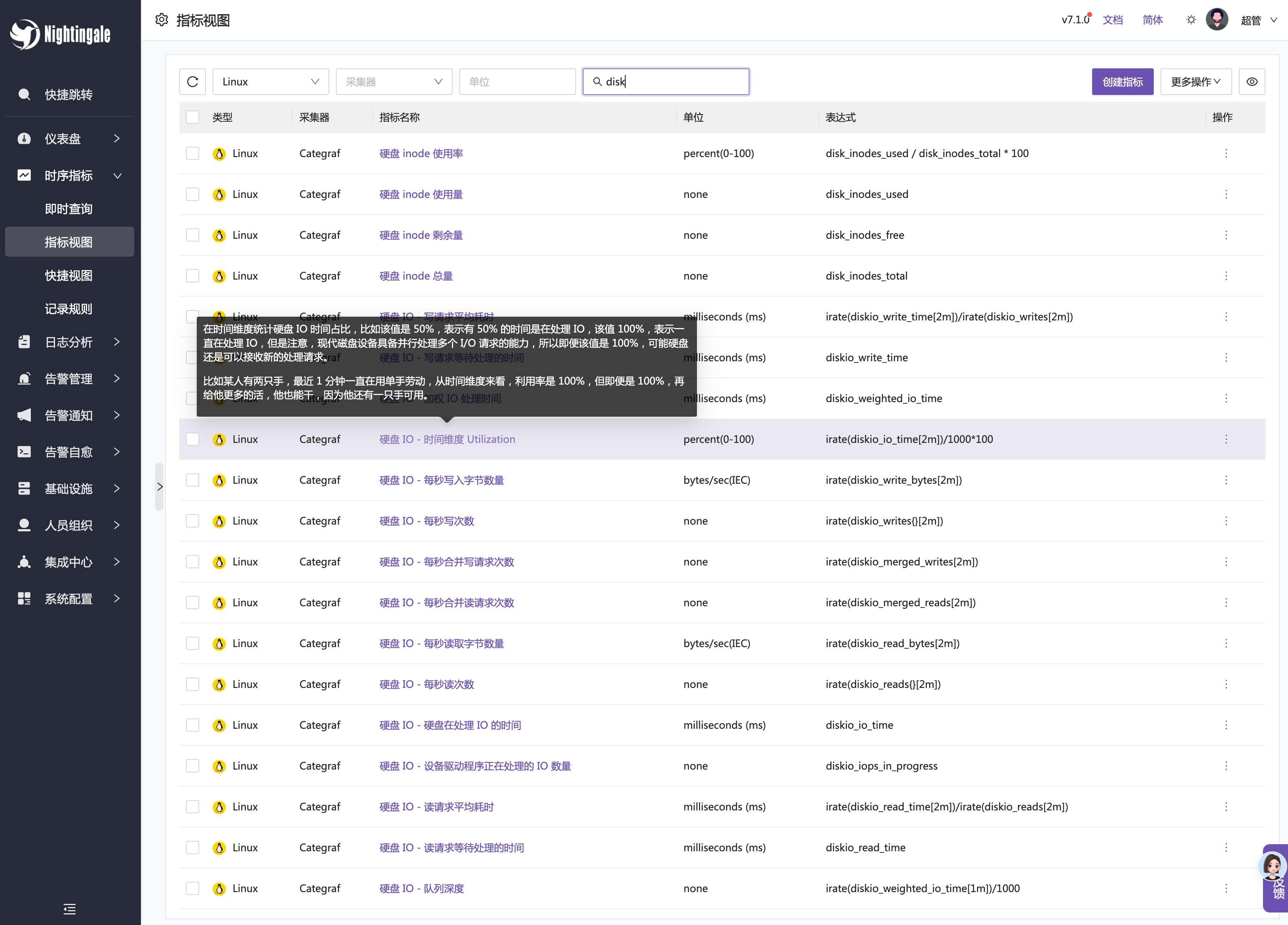
很多朋友不会写 promql,但是 promql 在 Prometheus 生态里又极为重要,那能否让一些资深工程师提前写好,沉淀下来,普通工程师直接用呢?夜莺支持的指标视图就是干这个事的,目前已经内置沉淀了几百个 promql,开箱即用。
夜莺的劣势1:仪表盘不如 grafana
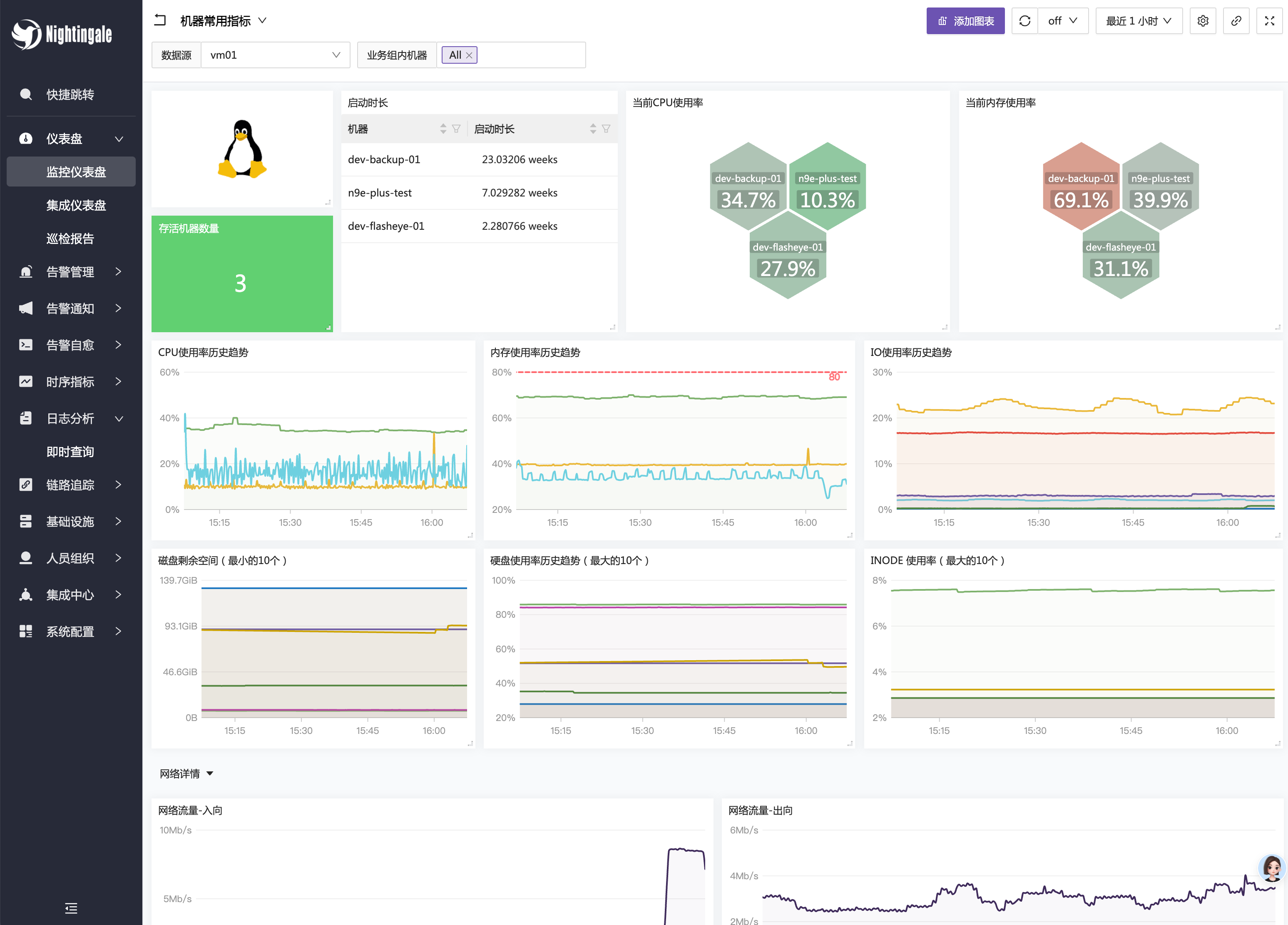
虽然已经内置了不少仪表盘了,但是还是不如 grafana 那么丰富,grafana 在看图这块确实无出其右,夜莺内置的那些仪表盘,如果你觉得够用了,就用,如果觉得不够用,建议还是上 grafana,下图是夜莺内置的一个仪表盘样例:
夜莺的劣势2:告警降噪能力不够
夜莺侧重在多数据源告警、告警规则统一管理,支持邮件、企微、飞书、钉钉等通知媒介,通过自定义通知脚本,也可以实现电话、短信通知,即常用的通知媒介都是支持的,不支持的写个脚本也可以支持。但是告警收敛降噪、排班、认领、升级、和 IM 深度打通等功能,还是不够(可能我想要的太多😂)。
夜莺核心研发团队搞了一个 FlashDuty 的 SaaS 产品,专门做这块,但是 FlashDuty 是收费的,不是开源的。FlashDuty 有免费套餐,对于小公司可以白嫖。当然,FlashDuty 就不止是针对夜莺了,也可以对接其他监控系统,比如 Prometheus、Zabbix、各类云监控、蓝鲸、SkyWalking 等。核心逻辑就是:这些监控系统负责产生告警事件,统一发给 FlashDuty,FlashDuty 负责事件后续处理,比如告警降噪、排班、认领、升级、和 IM 深度打通等功能。
13. Grafana 全家桶
推荐指数: ⭐ ⭐ ⭐ ⭐
Prometheus 可以搞定数据采集、存储问题,并提供查询接口、查询语言,但是对于数据的展示,Prometheus 本身并不是很强大,通常大家会选择使用 Grafana 作为展示工具。
Grafana 不仅仅为 Prometheus 提供了很多的 Dashboard 模板,而且还支持多种数据源,比如 InfluxDB、Elasticsearch、Loki、MySQL、PostgreSQL、CloudWatch、Zabbix 等等。Grafana 的可视化能力,基本就是开源领域的标杆甚至事实标准了。
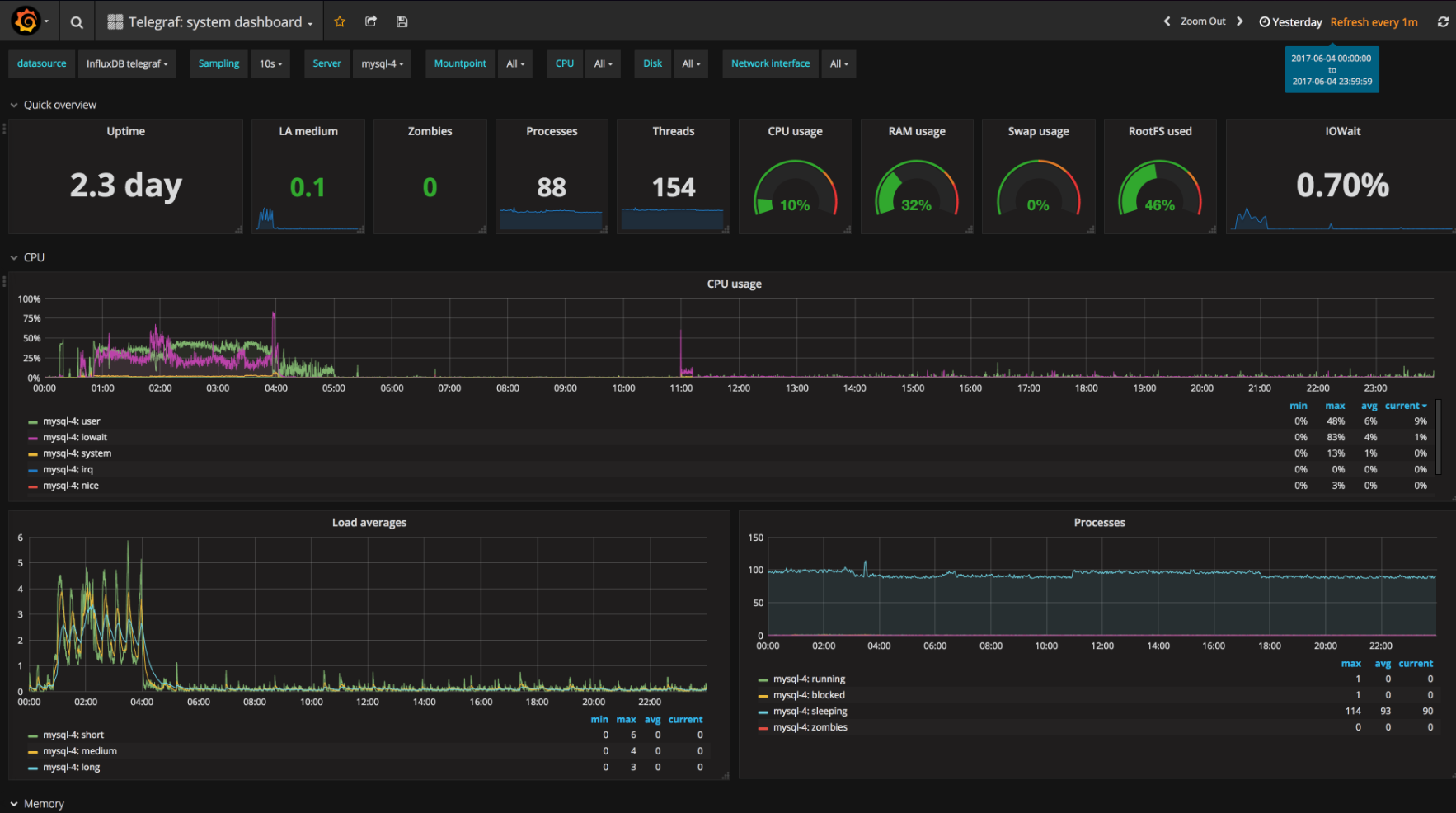
此外,Grafana 也陆续完善了 alert 相关的能力,覆盖了指标、日志、链路跟踪、oncall方方面面,是名副其实的开源可观测性全家桶方案。
进阶:快猫星云是一家云原生智能运维科技公司,由开源监控工具“夜莺监控”的核心开发团队组成。快猫星云打造的云原生监控分析平台——Flashcat平台,旨在解决云原生架构、混合云架构下统一监控难、故障定位慢的问题。Flashcat平台支持云原生架构、公有云、物理机/虚拟机、混合云等多种环境的监控数据统一采集,集告警分析、可视化、数据分析于一体,从业务到应用到基础设施,打通metrics、logging、tracing、event,提供立体的、统一的监控解决方案。
本文遵循「知识共享许可协议 CC-BY-NC-SA 4.0 International」,未经作者书面许可,不允许用于商业用途的转载、分发、和演绎。本文内容,由 Wilbur、VicLai 等共同撰写,仅代表相关个人见解和立场,与任何公司、组织无关。


