


夜莺项目整体介绍
🔴 注意:夜莺V8版本的文档,已经在整理中,草稿地址在:https://n9e.github.io 等整理完成也会放到 Flashcat 站点。实际上 V8 和 V7 很多功能是一样的,兼容的,如果 V8 文档里有不懂的地方可以参考当前的 V7 文档。
项目介绍
夜莺监控,英文名字 Nightingale,是一款侧重告警的监控类开源项目。类似 Grafana 的数据源集成方式,夜莺也是对接多种既有的数据源,不过 Grafana 侧重在可视化,夜莺是侧重在告警引擎。比如把 Prometheus、VictoriaMetrics、ElasticSearch 等作为数据源接入夜莺,即可在夜莺里配置告警规则做指标、日志的告警。当然了,夜莺也不止做告警,还提供了 ad-hoc 查询、指标视图、仪表盘等可视化能力,不过在可视化方面没有 Grafana 道行深。
另外夜莺团队还开源了一个采集器 Categraf,用于采集监控数据,支持 Linux、Windows、SNMP、MySQL、Redis、Postgres、ElasticSearch、Kafka 等各类监控对象的数据采集。Categraf 当前已经支持了近百种插件(插件列表),和夜莺丝滑对接,共同组成了一个完整的监控系统。如果你是 Exporter 重度用户,可以继续使用原来的采集方案,如果是新用户,建议使用 Categraf 作为采集器。
夜莺监控最初于 2020 年 3 月 20 日由滴滴开源,后来捐赠予中国计算机学会开源发展委员会(CCF ODC),依托基金会运作。夜莺项目至今已经发布了 100 多个版本,有 CCF 的支持,有快猫星云等公司的持续投入,相信夜莺项目会越来越好。
项目截图


项目代码
夜莺项目已收获 10000 多 github stars,1000 多 forks,100 多 contributors 参与其中,欢迎大家在 GitHub 上关注夜莺项目,及时获取项目更新动态,有任何问题,也欢迎提交 issues,以及提交 pull requests,开源社区需要大家一起参与才能有蓬勃的生命力。
最新进展
夜莺最新版本是 v8 的 beta 版本,虽说标记的是 beta 版本,实际是可以上生产的。2025 年上半年计划再完善一下告警通知部分的逻辑,于 2025 年七八月份发布 v8 正式版。
关于文档
该文档站点是最权威的文档,V5 V6 V7(V8 的文档揉到 V7 里了) 三个版本的文档都在这里。请各位小伙伴先通读文档,大部分问题就可以解决了。SRETalk 视频号中也有一些小的视频教程供大家参考,强烈建议关注收藏。另外,之前在极客时间开设过一个专栏,系统性的讲解了运维监控相关知识,建议大家也都看一下:《运维监控实战笔记》,尤其是前几节,专栏里提过的基础知识,本文档将不再赘述。
架构简介
夜莺依赖 mysql 存储各类用户配置,比如告警规则、屏蔽规则、仪表盘,依赖 redis 存储一些机器心跳上来的元信息以及 jwt token,除此之外,没有别的依赖。当然了,如果你安装的是 v8 版本,默认使用的 sqlite 和 miniredis,这意味着,不需要 mysql 和 redis 就可以直接运行夜莺的二进制启动,方便测试,当然如果要上生产,还是需要 mysql 和 redis 的。
姿势一:仅把夜莺作为告警引擎
如果只是把夜莺当做告警引擎,对接多个数据源做告警判断,其架构如下:
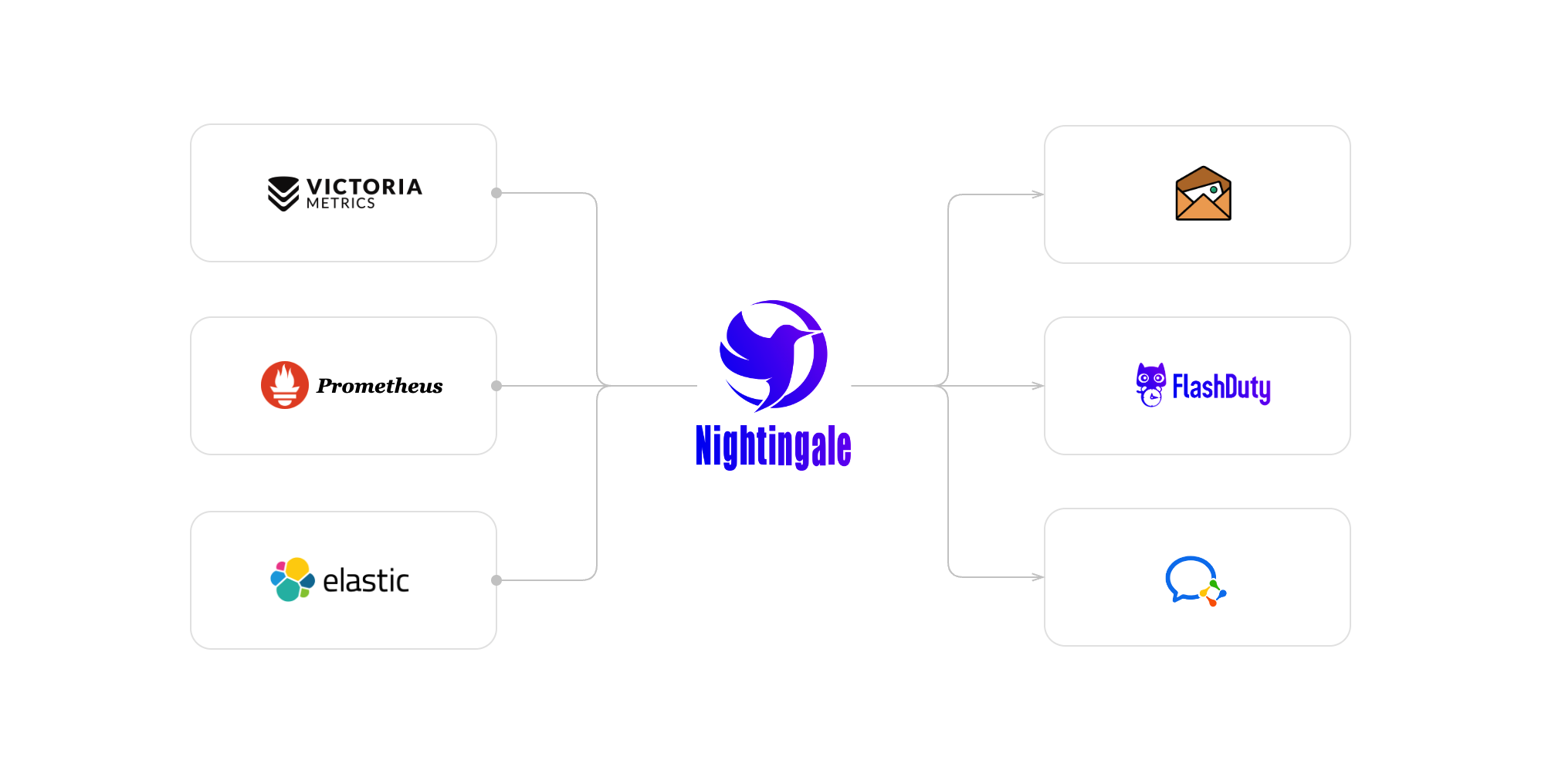
- 这个架构下,夜莺就类似 Grafana(Grafana 侧重看图,夜莺侧重告警),可以接入多种不同的数据源,比如 Prometheus、VictoriaMetrics、M3DB、Loki、TDEngine 等等,在夜莺中配置管理告警规则,夜莺周期性去查询各个存储,判定异常数据,产生告警事件
- 夜莺可以直接通过钉钉、企微、邮件等方式发出告警事件,也可以对接 FlashDuty,做告警聚合降噪之后再由 FlashDuty 做后续分发。
- 这个架构下,数据不流经夜莺,n9e 进程的配置文件中无需配置
[[Pushgw]]相关配置,只需要 MySQL、Redis 就位即可启动 - 如果你之前的数据采集是使用 Prometheus 生态的各类 Exporter,数据已经完成采集进入了 TSDB,那就很适合这种使用姿势。这种方式下,核心就是使用夜莺作为告警引擎,把各种监控数据源的告警规则集中管理,统一告警事件的分发,而监控数据的采集、传输,夜莺都没有介入。
- 这个方式下,无需 categraf 组件,机器列表为空,无法使用告警自愈功能,不过基本的告警、看图都是支持的。这种模式下的用户,其实看图一般会继续沿用 Grafana,仅使用夜莺作为告警引擎,统一管理各个时序库的告警规则配置。
如果我们想让夜莺把监控数据的采集、传输也做了,那就要使用姿势二了。
姿势二:时序数据流经夜莺
夜莺本身其实不做监控数据采集,只是提供各类监控数据接收接口,然后转存到时序库。监控数据采集社区有很多选择,夜莺社区推荐大家使用 Categraf 作为采集器,通过心跳方式自动上报信息,填充夜莺里的机器列表,也支持使用告警自愈功能。当然,也可以使用其他采集器,比如 Grafana-agent、Telegraf 等,使用这些采集器的话,也可以在夜莺中看到机器列表,只不过机器列表中的大部分字段都是 unknown,无法使用告警自愈功能,基本的机器失联告警、指标告警、看图等,都没问题。
社区经常有人问,夜莺可以监控 xxx 吗?从上面的解释可以看出,夜莺啥都可以监控,又啥都监控不了,因为夜莺本身不做监控数据采集,只要你通过某个采集器采集到了监控数据,夜莺就可以对这些数据做告警判断。这个方式下,其架构图如下:
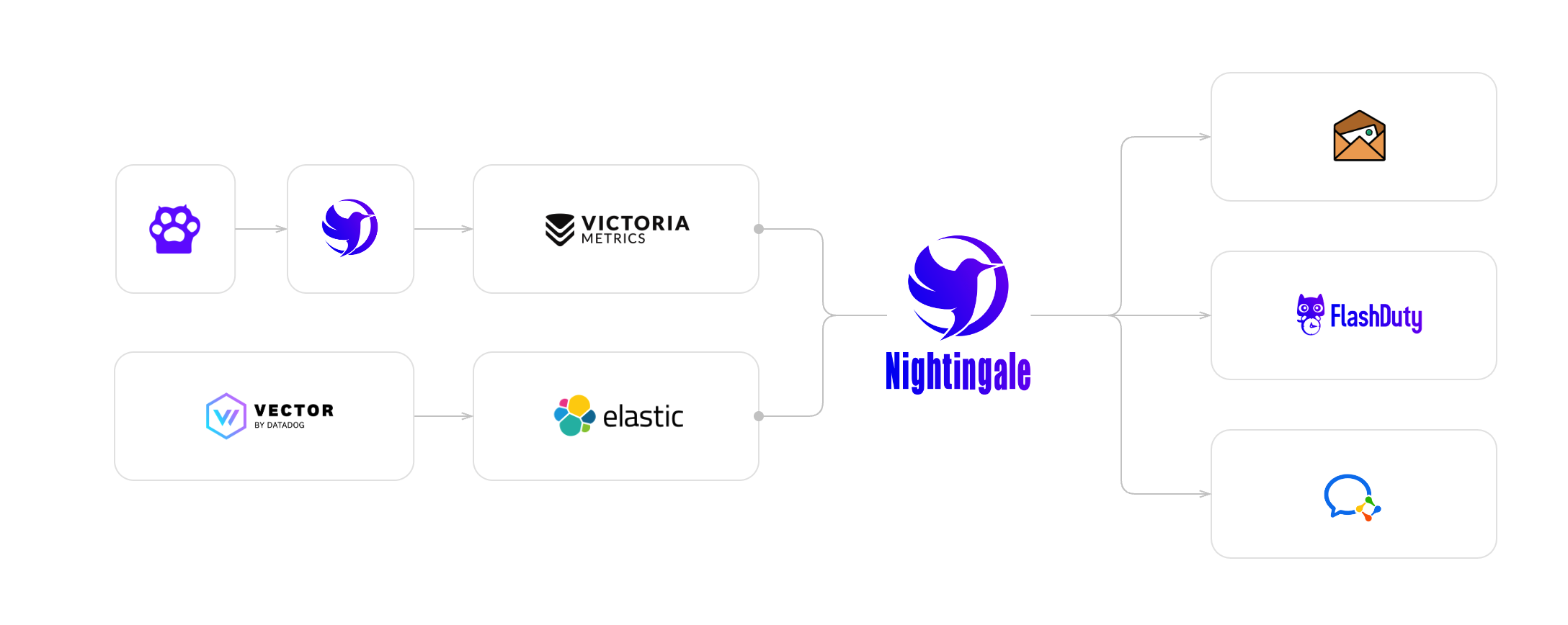
上例中同时举例了指标和日志两种数据的处理流程。
- 指标使用 Categraf 采集(就是那个猫爪样式的图标),推送到夜莺(通过 Prometheus remote write 协议,需要在夜莺的配置文件中配置
[[Pushgw]],可以配置多个时序库,即配置多份[[Pushgw.Writers]],夜莺就会把数据同时分别转发给 Writers 中的地址),夜莺把数据转存到时序库(此处以 VictoriaMetrics 举例,也可以写入 Prometheus 等其他时序库),之后把 VictoriaMetrics 作为一个数据源接入夜莺 - 日志使用 Vector 采集推送给 ElasticSearch,然后把 ElasticSearch 作为一个数据源接入夜莺。开源版本中,日志类型的数据不流经夜莺,采集器建议使用 Vector,也可以使用 Filebeat、iLogtail、Loggie、Fluentbit、Categraf 等其他采集器,最终数据进入 Loki 或者 ElasticSearch,然后把 Loki 或者 ElasticSearch 作为数据源接入夜莺
当然了,实际生产场景可能会更复杂,比如有多个数据中心,每个数据中心都有多个时序库多个日志库,不同数据中心之间要考虑机房网络割裂的问题,如果发生网络割裂,希望机房内部告警自闭环不受网络故障影响,平时网络链路好的时候,又希望在中心端统一查看指标、日志。这些问题都是可以解决的,后续在其他章节详述更复杂的架构设计。
对比 Prometheus
这是经常被问到的问题。如果您当前使用的是 Prometheus,而且没有痛点,那么就不需要考虑夜莺了,用好现在的体系就可以了。如果您用了多个时序库,比如 Prometheus、VictoriaMetrics、Thanos 等等,需要一个统一的平台来管理告警、看图,夜莺是一个选择。如果您想把监控的能力开放给公司所有研发团队,让研发团队自助服务,觉得 Prometheus 使用配置文件的告警规则管理方式不方便,夜莺是一个选择。如果您需要更为灵活的告警策略配置,比如控制生效时间、一套规则生效多个集群,夜莺是一个选择。如果您需要告警自愈能力,告警之后自动执行个脚本啥的,夜莺是一个选择。如果您需要一个统一的事件 OnCall 中心,聚合各个监控系统的告警,做统一的告警聚合降噪、排班认领升级、灵活的分发和协同,FlashDuty 是一个选择。
另外,相比 Grafana,夜莺的看图能力还是差一些,因为 Grafana 是 agpl 协议,我们也没法封装 Grafana 进夜莺,所以夜莺的看图是自研的,和 Grafana 没法 100% 兼容,当然,夜莺支持导入 Grafana 的仪表盘 JSON,基础的图表都是兼容的(但是导入体验做的还不好,这是一个巨大无比的工程)。另外,夜莺设计了内置告警规则和内置仪表盘,方便用户开箱即用,现在覆盖了常用组件,后面随着时间推移,这个体验也会越来越好,期待大家一起共建。
以笔者观察来看,很多公司是一套组合方案(成年人的世界,没有非黑即白,都要):
- 数据采集:组合使用了各种 agent 和 exporter,比如使用 Categraf,辅以各类 Exporter
- 存储:时序库主要使用 VictoriaMetrics,因为 VictoriaMetrics 兼容 Prometheus,而且性能更好且有集群版本,对大部分公司,单机版就足够用了
- 告警引擎:使用夜莺,方便不同的团队管理协作,内置了一些规则开箱即用,告警规则的配置比较灵活
- 看图可视化:使用 Grafana,图表更为炫酷,社区非常庞大,从 Grafana 站点可以找到很多别人做好的仪表盘,直接导入即可
- 告警事件 OnCall 分发:使用 FlashDuty,聚合了 Zabbix、Prometheus、夜莺、Open-Falcon、云监控、Elastalert 等各类告警事件,统一聚合降噪、排班、认领升级等。
企业版
快猫星云技术团队是夜莺监控的创始团队。 点击查看以下 PDF 材料,了解更多企业版功能。
点击 联系我们,与快猫团队交流 !
有预算的公司可以支持一下我们的企业版,企业版功能更丰富,其定位是一套统一的可观测性平台,没预算的公司用开源版本,我们也会持续迭代支持,开源版的定位主要是一个告警引擎,一个指标监控系统。
获得帮助
- 方式1:github issue,提问题提 Bug 都可以从这个入口进入,信息给的尽量详细些,问题的话给出复现步骤,附上截图、日志、配置等信息,这样大家才能帮你解决问题
- 方式2:微信用户互助交流群,加我微信好友(搜索我的微信:
picobyte,我已关闭好友验证,或者扫下面的二维码),备注:夜莺群-您的公司-您的姓名,我会拉你入群。








 联系我们
联系我们
{kind=link}