
使用 Fluent Bit 3.0 采集日志、跟踪和指标的最佳实践

这篇博文将向您介绍 Fluent Bit 3.0 以及在可观察性管道(Pipeline)中使用它的一些最佳实践。最近发布的 Fluent Bit 3.0 为 Fluent Bit 最佳实践提供了一些新的机会。让我们看一下 Fluent Bit 以及 v3 的新增功能。
什么是 Fluent Bit?
Fluent Bit 是一种遥测代理(telemetry agent),旨在接收数据(日志、跟踪和指标)、处理或修改数据并将其导出到目的地。在将数据发送到存储之前,Fluent Bit 可以充当代理。但是,您也可以使用 Fluent Bit 作为处理器,因为您可以对数据执行各种操作。 Fluent Bit 旨在帮助您调整数据并添加适当的上下文,这对可观察性后端很有帮助。
Fluent Bit 和 Fluentd 有什么区别?
Fluent Bit 和 Fluentd 的创建目的相同:收集和处理日志、跟踪和指标。然而,Fluent Bit 被设计为轻量级、多线程并在边缘设备上运行。
Fluent Bit 是在 Kubernetes 出现之前创建的,当时物联网 (IoT) 还是一个新的流行词。不幸的是,他们的市场预测并不正确。云比物联网更成功。
Fluent Bit 3.0 中的新增功能
Fluent Bit 最近发布了 3.0 版本,其中提供了一系列更新:
- HTTP/2 支持: Fluentbit 现在支持 HTTP/2,通过 OpenTelemetry 数据的 Gzip 压缩实现高效数据传输,从而增强管道性能。
- 新处理器:引入新处理器,包括指标选择器和内容修改器,用于选择性数据处理和元数据调整,提高数据相关性和存储效率。
- SQL处理器:集成SQL处理功能,用于精确的数据选择和路由,允许用户根据优化后端存储的特定标准过滤日志和跟踪。
- 增强过滤:通过指标包含/排除过滤、高效元数据调整和精确数据路由来简化数据收集,确保仅将相关数据传输到可观察性后端。
- 可扩展性和效率:改进的可扩展性和性能增强、优化的压缩和高效的数据路由有助于使用 Fluentbit 3.0 提供更精简且更具成本效益的可观测性解决方案。
在下面的段落中,我们将介绍一些最佳实践,特别是在使用 Fluent Bit 3.0 时。
Fluent Bit v3.0 最佳实践
以下是我们的内部专家 Henrik Rexed 推荐的使用 Fluent Bit 3.0 的一些最佳实践。
了解你想要完成什么
在使用 Fluent Bit 之前,您应该清楚地了解您想要用数据实现什么目的。如果您有日志,Fluent Bit 是正确的选择。对于指标,Fluent Bit 有一些限制。对于追踪,采样是不可能的。确保您可以使用 Fluent Bit 实现您想要的目标;否则,您可能需要考虑其他选择。问问自己,Fluent Bit 应该处理多少数据?将数据发送到其他地方(例如 Dynatrace)并让 Grail 处理它会更好吗?
使用 Expect 插件
从小处开始,通过使用 Expect 插件来测试您是否达到了预期的效果,Expect 插件是一个看门人,可以通过阻止不遵循您制定的规则的内容来帮助您提高管道(Pipeline)效率。
在读取预期日志之前,您可以创建一个包含用于测试的日志数据的文件,或者使用虚拟输入插件将虚拟数据发送到管道(请参见下面的示例)。
pipeline:
inputs:
- name: dummy
dummy: '{"message": "custom dummy"}'
outputs:
- name: stdout
match: '*'
直接在源头修改
在 INPUT 和 OUTPUT 区块放置 processor,可以让你直接针对源端应用修改,从而提高效率。在日志通过解析器之前可以进行本地化修改,这意味着您可以:
- 制定全局规则
- 节省 CPU 时间
- 拥有更稳健可靠的 pipeline
从源头进行处理,减轻了 Fluent Bit agent 的压力。
其他类型的修改
Traces
极少情况下要对 Traces 做修改,如果非要这么做,可以考虑使用 content 修改器,content 修改器可以用于 traces 和 logs,不能用于 metrics。
Metrics
使用标签处理器删除、添加指标,并降低基数和指标成本。但是没法进行指标转换,比如 cumulative 或 delta。
Logs
SQL 处理器可以让您的 pipeline 更易于管理,因为您可以使用 select 来精确过滤您要修改的日志。
理解标签 tags 的概念
如果您了解标签的工作原理,您对 Fluent Bit 的体验将会得到改善,特别是如果您以前从未使用过 Fluent。标签使路由成为可能,并在 INPUT 定义的配置中设置。它们可用于仅对特定数据应用特定操作。
例如,您已经提取了OpenTelemetry指标、日志和跟踪,因此您可能拥有:
- Otlp.metrics
- Otlp.logs
使用标签“metrics”,您可以仅针对某些操作定位 otlp.metrics。
还有一个名为 rewrite_tag 的过滤器插件,顾名思义,您可以使用该插件重写标签。
使用 service 部分检查管道的运行状况
在 service 部分,您可以启用两个关键的功能: Health_Check 和 http_service。这些可以帮助您更深入的了解管道的运行状况。参考下面的示例:
apiVersion: v1
kind: ConfigMap
metadata:
annotations:
meta.helm.sh/release-name: fluent-bit
meta.helm.sh/release-namespace: fluentbit
labels:
app.kubernetes.io/instance: fluent-bit
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: fluent-bit
app.kubernetes.io/version: 2.2.1
helm.sh/chart: fluent-bit-0.42.0
name: fluent-bit
namespace: fluentbit
data:
custom_parsers.conf: |
[PARSER]
Name docker_no_time
Format json
Time_Keep Off
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L
fluent-bit.yaml: |
service:
http_server: "on"
Health_Check: "on"
pipeline:
inputs:
- name: tail
path: /var/log/containers/*.log
multiline.parser: docker, cri
tag: kube.*
mem_Buf_Limit: 5MB
skip_Long_Lines: On
processors:
logs:
- name: content_modifier
action: insert
key: k8s.cluster.name
value: ${CLUSTERNAME}
- name: content_modifier
action: insert
key: dt.kubernetes.cluster.id
value: ${CLUSTER_ID}
- name: content_modifier
context: attributes
action: upsert
key: "agent"
value: "fluentbitv3"
- name: fluentbit_metrics
tag: metric.fluent
scrape_interval: 2
filters:
- name: kubernetes
match: kube.*
merge_log: on
keep_log: off
k8s-logging.parser : on
k8S-logging.exclude: on
- name: nest
match: kube.*
operation: lift
nested_under: kubernetes
add_prefix : kubernetes_
- name: nest
match: kube.*
operation: lift
nested_under: kubernetes_labels
- name: modify
match: kube.*
rename:
- log content
- kubernetes_pod_name k8s.pod.name
- kubernetes_namespace_name k8s.namespace.name
- kubernetes_container_name k8S.container.name
- kubernetes_pod_id k8s.pod.uid
remove:
- kubernetes_container_image
- kubernetes_docker_id
- kubernetes_annotations
- kubernetes_host
- time
- kubernetes_container_hash
- name: throttle
match: "*"
rate: 800
window: 3
print_Status: true
interval: 30s
outputs:
- name: opentelemetry
host: ${DT_ENDPOINT_HOST}
port: 443
match: "kube.*"
metrics_uri: /api/v2/otlp/v1/metrics
traces_uri: /api/v2/otlp/v1/traces
logs_uri: /api/v2/otlp/v1/logs
log_response_payload: true
tls: On
tls.verify: Off
header:
- Authorization Api-Token ${DT_API_TOKEN}
- Content-type application/x-protobuf
- name: prometheus_exporter
match: metric.*
host: 0.0.0.0
port: 2021
启用 http_server 还会公开许多 API endpoints。
利用热重载来节省更改时间
默认情况下,您所做的任何更改都需要重新启动代理,这可能非常耗时。如果启用Hot Reload ,则会发送 HTTP 请求来重新加载 Fluent Bit 并读取管道文件,这使得整个过程更加流畅。如果您处于裸机环境中,这尤其有用。
使用 Fluent Bit Metrics 公开 Prometheus 数据
如果您想从 Prometheus 的角度公开数据,请使用 Fluent Bit Metrics 插件,该插件要求 Fluent Bit 成为 Prometheus 导出器。该插件非常出色,因为它产生有趣的指标。
service:
flush: 1
log_level: info
pieline:
inputs:
- name: fluentbit_metrics
tag: internal_metrics
scrape_interval: 2
outputs:
- name: prometheus_exporter
match: internal_metrics
host: 0.0.0.0
port: 2021
注意你的内存和其他资源占用
当您修改数据并拒绝不需要的数据时,重试逻辑会将拒绝的数据保留在内存中。但是,如果存在太多异常,Fluent Bit 代理将变得不稳定并崩溃。因此,定期查看 Fluent Bit 的stdout并消除噪音非常重要;否则,日志可能会变得不可靠。
在每个日志和跟踪的输入插件中,我们都会看到一个(内存)缓冲区。数据的摄取速度比发送到目的地的速度快,这可能会产生背压,从而导致高内存消耗。计划避免内存不足的情况。默认情况下,您有一个存储类型内存,但如果您有大量数据,则可能会超出此缓冲区限制。微调此内存缓冲区限制以避免不稳定至关重要。
同样,请注意 agent 的资源使用情况(CPU、行为、限制)和管道指标。创建一个仪表板来查看这些指标,如下面来自 Dynatrace 的示例所示:
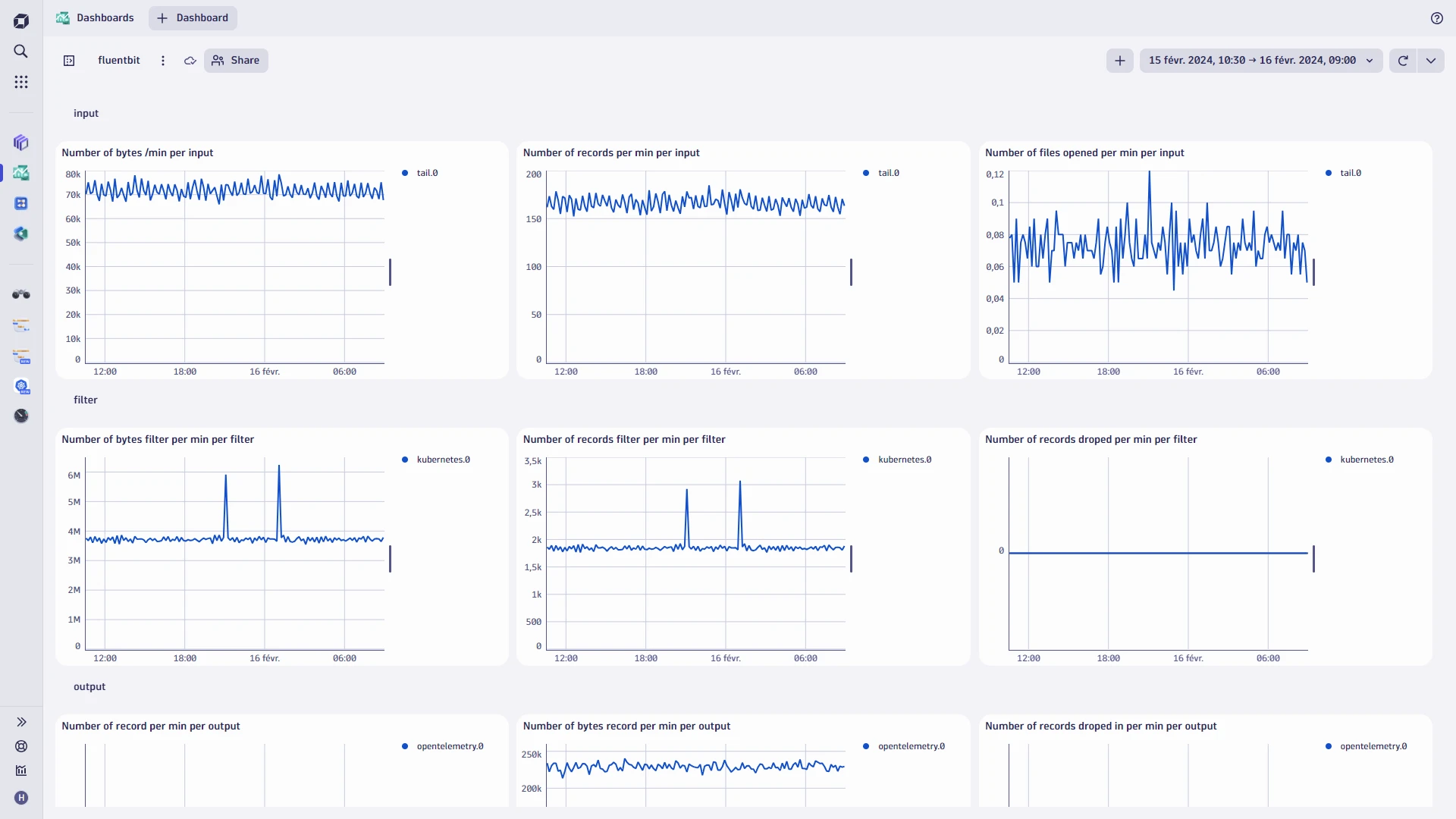
这样的概述可以帮助您了解是否丢失了数据。例如,“我收到了 100 个指标,但只输出了 30 个,这意味着我丢失了 70% 的数据。”这是故意的吗?重试次数多吗?重试可能是导致此问题的原因。
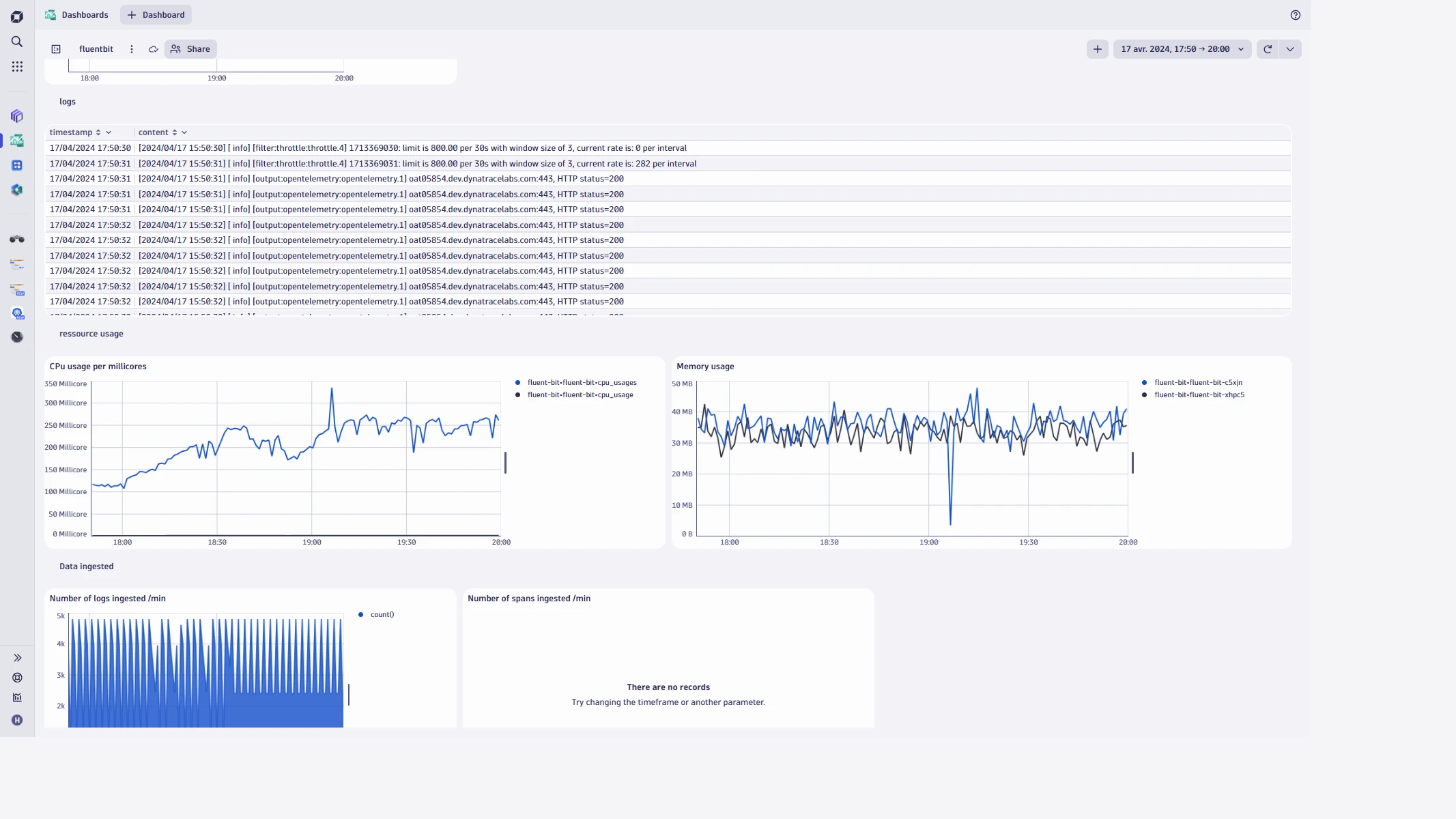
在仪表板中,Fluent Bit 日志非常能说明问题。日志信息丰富,可以帮助您识别可能导致 Fluent Bit 不稳定的问题。例如,您可以查看发送到 Fluent Bit 的数据与到达 Dynatrace 的数据之间是否存在重大差异。
在这篇博文中,我们深入研究了 Fluent Bit 3.0 的最新更新,并概述了在可观察性管道(pipeline)中有效利用其功能的一些最佳实践。
原文连接:https://www.dynatrace.com/news/blog/best-practices-for-fluent-bit-3-0/



