
提升故障应急响应速度,Flashcat平台的1-5-10实践
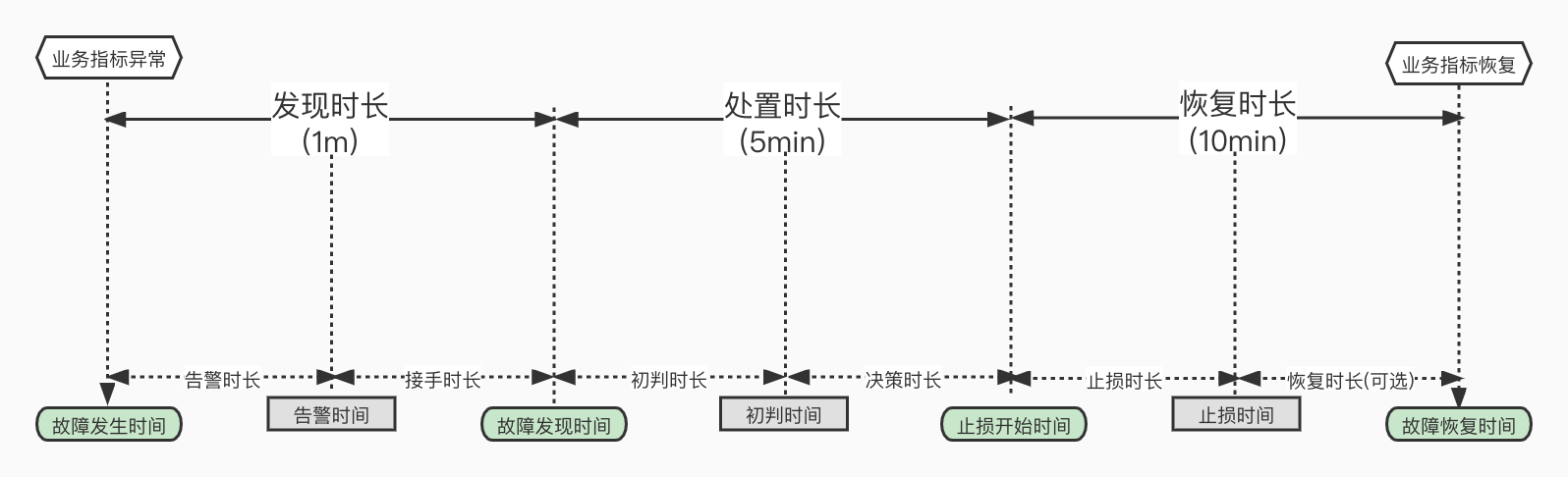
阿里巴巴提出的稳定性保障 “1-5-10” 目标是针对提升系统可靠性的一个重要牵引指标,用于缩短故障恢复时长(MTTR),降低故障影响。“1-5-10” 具体指的是:
- 1分钟发现:故障发生后,能够在1分钟内快速定位问题并开始响应。
- 5分钟处置:在5分钟内,故障能够得到有效的控制,防止问题进一步扩散。
- 10分钟恢复:在10分钟内,故障能够得到完全恢复,服务恢复正常运行。

阿里巴巴的 “1-5-10” 目标的提出在行业内具有相当大的影响力。这个目标不仅体现了阿里巴巴对自身服务质量和系统稳定性的高要求,而且也成为行业内其他企业参考和借鉴的标杆。
很多企业在借鉴阿里 “1-5-10” 目标落地的时候,容易碰到两个阻碍:
- 追求每个故障都要符合 “1-5-10”,否则就否定相关的投入和成果。这是不科学、不现实的,强如阿里巴巴、Google、Facebook 也都不可避免的会发生重大故障。“1-5-10”是一种牵引性的指标,用于不断牵引技术团队,针对性的改善故障处理过程中的短板能力,如加强自动化监控、智能告警、快速故障定位和恢复等技术的研究和落地。
- 落地过程中缺乏相应的工具,费时费力,效果不好。
回归到 “1-5-10” 的目标落地上,有没有对应的工具,能够帮助企业快速的建立相关的能力呢?
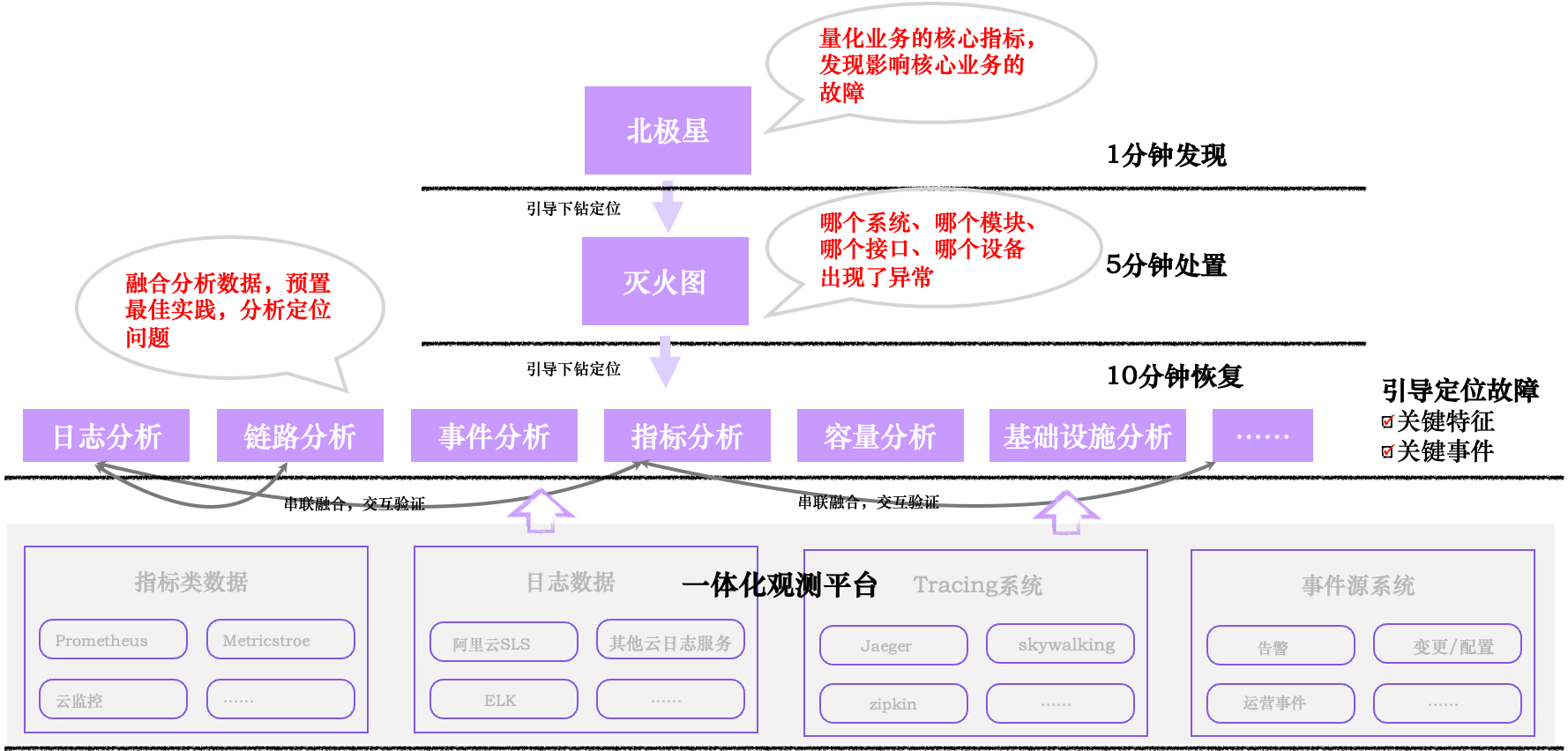
一、需要先定义清楚什么是故障
在"1-5-10"体系中,使用业务指标的异常或者恢复,作为故障的开始和结束标识,我们形象的称之为“北极星”指标。北极星指标通常是一个“量”相关的指标,如实时订单量、实时GMV、实时支付量、实时在线用户数等。这类指标非技术人员也能够直观的理解其含义,并“直接”知道其出现异常后对业务意味着什么,是业务负责人最关心的业务指标。一个好的北极星指标,必须满足下面几个条件:
- 北极星指标必须是准实时的,这样才能第一时间发现业务受损的情况。
- 针对北极星指标的异常波动检测是要非常准确的,否则就是狼来了。
- 北极星指标必须是公司上下人人都容易直观理解的,含义和重要性不言自明。
- 北极星指标的配置和生成应该是非常简便易得的。如果一个指标的生成需要研发排期写代码,那么落地和见效将遥遥无期。
北极星指标,通常来源于MySQL数据提取、日志分析结果提取、Metrics埋点等途径。针对北极星指标的异常波动,一般搭配智能检测、同环比检测、静态阈值、数据中断检测等多种组合手段,确保检测的准确性和及时性。有了北极星指标,我们就可以围绕北极星指标,构建起“真故障”的度量和发现能力。让故障的影响时间和影响面说的清、说的准。
二、在5分钟处置阶段的四个原则
- 故障定界优先于故障定位
- 定位直接原因优先于定位根因
- 寻找故障的关键特征和引发故障的关键事件优先于全面debug
- 以定位到可执行的止损预案为优先目标
遵循以上原则,在快猫星云的 Flashcat 平台中,内置了对应的工具型解决方案。
灭火图:快速故障定界
灭火图是 SLO 的一种智能化落地,通过灭火图,实时度量 IT 服务各个层次的核心功能和核心模块的健康状况,快速收敛故障范围,并且同时把可观测性数据良好的组织在一起,形成一个体系化的信息大厦。在灭火图中,根据最佳实践定义了一套量化 IT 服务健康度的指标和算法,量化对象包括功能(核心功能,如下单、查询等)、模块(核心微服务模块,通常为多个实例)、组件(如MySQL、Kafka等)、基础设施(内外网、CDN、DNS等),比如,
- 功能:黄金指标成功率、流量、响应延时,可自定义
- 模块:实例存活率、实例状态、CPU/内存/磁盘使用率,可自定义
- 组件:各类组件的量化指标不同,可自定义,和组件仪表盘联动
- 基础设施:各类基础设施的量化指标不同,可自定义,和仪表盘联动
事件墙:定位关键事件
通过各种可观测性数据标签的相关性、时间的相关性,实时的展示和推荐造成此次故障的可疑事件,这些事件可能是发布变更、配置变更、关键的基础设施告警。当我们找到这些事件后,就能针对性的展开止损动作,进而快速恢复故障。
多维分析:定位关键特征
从海量的 metrics/logging/tracings 数据中,去分析和发现可能的故障特征,有了特征,就有了调查的方向,从而顺藤摸瓜。
最后,这个故障发现定位的体系,需要不断的去建设和完善,通过故障的复盘不断的去打磨,把所有人的经验都沉淀和固化在平台上。最终让每个人都可以轻松的分析和定位故障。
关于快猫星云和夜莺
夜莺 (Nightingale) 是一款开源云原生监控工具,是中国计算机学会接受捐赠并托管的第一个开源项目,在GitHub上有9000颗星,有数千家企业用户使用。快猫星云以开源夜莺为内核打造的“Flashcat平台”,是国内顶级互联⽹公司可观测性实践的产品化落地,我们致力于让可观测性技术更好的落地和发挥价值。
你可以通过Flashcat平台,有效改善以下问题:
- 希望整个公司统一用一个工具,就可以支持指标、日志、链路追踪数据的采集、可视化、告警,免去搭建和维护多套 Prometheus、Zabbix、Grafana、ELK、Jaeger 的工作量。
- 如果有在用多云,并且在多个公有云监控控制台来回切换不方便,希望监控数据、监控视图都是统一的,有更一致的用户体验,同时降低给所有的工程师开通公有云控制台权限带来的安全隐患。
- 告警太多,工作老被打断, 可以利用我们提供的 OnCall 值班平台(类似于 PagerDuty),支持告警聚合、降噪、认领、升级、排班,可以在飞书、钉钉、企微中接收和处理告警。



