
开源时序库的兴起以及未来发展的观点

时间序列数据库允许您有效地存储和查询指标。例如,如果您想预测服务器上的负载,或识别生产服务的间歇性故障,时间序列数据库可以提供帮助。除了基础设施监控之外,时间序列数据库在金融、物联网应用、制造等领域也极具价值。
许多时间序列数据库(包括 VictoriaMetrics)都是开源的。在本文中,您将了解时间序列数据库是如何产生的,以及为什么这么多数据库是开源的。我们还将分享我们的内部人士对该领域未来的看法。
什么是时序库?
当人们想到数据库时,他们会想到像 PostgreSQL 和 Oracle 这样的关系数据库。关系数据库以表格式存储数据,其中每一行描述一个数据对象,每一列描述数据的不同方面。例如,您可能有一个 employees 表,该表包含 name、role、salary 列。每行代表不同的员工:
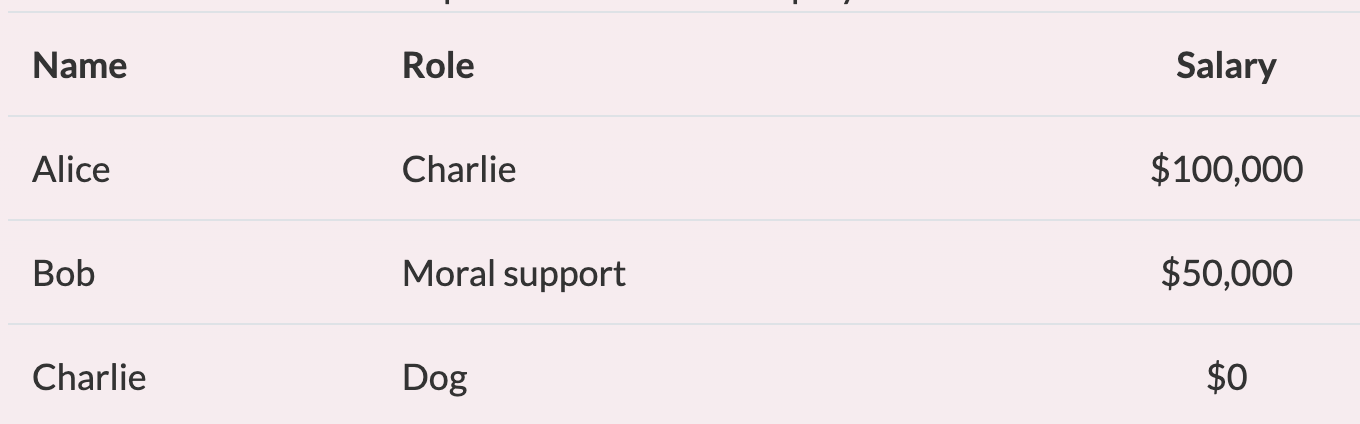
该模型适用于多种类型的数据。只要数据量不太大,它就支持快速查询特定信息,并且如果单元格的值发生变化也可以轻松更新。然而,当数据大小达到数十亿或数万亿行(时间序列数据的典型大小)时,性能会下降。
时间序列数据库是专门为时间序列数据设计的数据库。时间序列数据是一系列测量值或具有关联时间戳的观测值。在像 VictoriaMetrics 这样的数据库中,这些测量值还可以具有称为标签的关联元数据。
时间序列数据库可以摄取和查询大量数据,并使用巧妙的技巧在存储相同数据时使用比关系数据库更少的资源。当然,天下没有免费的午餐,时间序列数据库并不适合所有数据类型。以时间序列数据库为例:
- 更新已存储的数据需要很长时间
- 只能存储数字,不能存储其他类型的数据
这些权衡对于典型的时间序列数据(例如股票价格或对特定接口地址发出的请求数量)非常有效。然而,它们不适用于我们之前的员工示例。
时序库简史
为了解释时间序列数据库,我们将回到 2010 年代初,当时流行的时间序列数据库还没有出现。当时,基础设施监控通常只是实时的。如果幸运的话,您可能会有一个仪表板向您显示您正在使用的系统的当前状态,但历史数据很难获得。许多问题,例如间歇性故障,可能会在很长一段时间内都发现不了。
跟踪系统随时间的状态需要存储数十亿甚至数万亿行。2010 年初,大多数数据库都是传统的关系数据库,其设计初衷并不是为了处理如此大的数据量。
第一个时序库

InfluxDB 于 2013 年推出,是第一个主流时间序列数据库。之前有一些努力,但它们要么是未知的,要么是针对老场景的。对于我们的故事来说,重要的是,InfluxDB 过去是、现在仍然是一个开源项目。开源为 InfluxDB 和时间序列数据库的整体普及创造了奇迹。
然而,与任何软件一样,InfluxDB 并不完美。用户抱怨的主要来源之一是数据库的稳定性。搜索 “influxdb crash” 仍然会带来充满困惑和沮丧的用户的结果。更糟糕的是,每个主要版本的发布都破坏了向后兼容性,并且自动更新工具迟到、丢失或有错误。版本升级过程对于用户来说既耗时又令人沮丧。
Prometheus
大约在 InfluxDB 启动的同时,SoundCloud 的工程师正在开发自己的内部基础设施监控系统,称为 Prometheus。虽然 InfluxDB 旨在满足所有时间序列用例,但 Prometheus 明确关注指标和事件监控。例如,Prometheus 仅支持将指标记录为浮点数,而 InfluxDB 支持多种数据类型。
Prometheus 的关注范围更窄,因此比 InfluxDB 具有更高的稳定性和效率。众所周知,它比 InfluxDB 更容易运行、配置、升级和故障排除。 Prometheus 出色的开发人员体验使其成为当今事实上的可观测性解决方案。
VictoriaMetrics

虽然 Prometheus 是一款出色的产品,但在处理大量数据时仍然有可能达到其性能极限。在创立 VictoriaMetrics 之前,我与我们的另一位联合创始人 Roman 在一家广告科技公司工作。我们开发的系统每秒处理数百万个请求,这给可观察性和分析带来了挑战。
我们的团队是 Prometheus 的可观察性的早期采用者。它彻底改变了我们的工作流程,帮助我们看到的不仅仅是系统的当前状态,还使我们能够查看和分析历史数据。历史可观测性数据对于构建可靠、高性能的系统至关重要。 Prometheus 对我们来说是一个很大的帮助,我们在其中存储了如此多的数据,以至于我们已经达到了极限。
在采用 Prometheus 的同时,我们将分析工作负载从 PostgreSQL 迁移到 ClickHouse。 ClickHouse 的架构非常高效,使我们能够将 12 台服务器缩减为仅一台来运行分析。这让我们思考,“如果我们有 Prometheus,但有 ClickHouse 的架构呢?”。
这个问题催生了 VictoriaMetrics,这是一个新的时间序列数据库,它继承了 Prometheus 的遗产,同时采用了一些使 ClickHouse 如此高效的设计。例如,VictoriaMetrics:
- 使用先进的压缩技术,占用更少的磁盘空间和内存
- 以块的形式存储和处理数据以提高速度和效率
- 利用所有可用的 CPU 内核来最大限度地提高性能
VictoriaMetrics 的传统赋予了它卓越的效率、简单性和性能。我们的基准测试显示,VictoriaMetrics 使用的磁盘空间比 Prometheus 少 2.5 倍,查询服务速度比 Prometheus 快 16 倍。
全景蓝图

InfluxDB、Prometheus 和 VictoriaMetrics 只是当今可用的时间序列数据库中的三个。 VictoriaMetrics 在时间序列数据库繁荣时期诞生。 2010 年代末推出了许多开源时间序列数据库,包括 VictoriaMetrics、TimescaleDB、QuestDB 等。
许多其他类别的软件都以专有选项为主。所以您可能想知道所有专有时间序列数据库在哪里?答案是,虽然有成功的专有时间序列数据库,但它们在老场景中竞争。例如, kdb+在高频交易公司中非常受欢迎。
时序库的未来
预测未来并不容易,但审视今天的痛点可以为接下来要解决的问题提供一些提示。如今的时间序列数据库有两个众所周知的痛点——高基数问题和高时间序列流失率。
时序库高基数问题
时间序列数据库的性能通常与活动时间序列的数量直接相关。对于像 VictoriaMetrics 或 Prometheus 这样的数据库,活动时间序列的数量是唯一标签组合数量的乘积。例如,考虑以下指标:
requests_total{path="/", code="200", machine="vm01"}
上述指标计算了名为 vm01 计算机上 / 返回 HTTP 200 的请求总数。每个 path 、 code 和 machine 都是一个标签(一个包含有关指标的元数据的键值对)。指标名,加上这些标签键值对,唯一标识了一条 time series 时间线。
现在,假设您的应用程序为 1000 个路径提供服务,可能从每个路径返回 20 个不同的 HTTP 代码,并由 100 台计算机提供服务。这意味着您的监控基础设施需要处理 1000 x 20 x 100 = 2,000,000 个时间序列才能计算所服务的请求总数。
活动时间序列的数量称为基数。高基数或许多活动时间序列会导致数据库速度减慢和故障。
时序库时间序列流失
跟踪基础设施指标通常需要记录哪台机器生成了该指标。对于像 VictoriaMetrics 这样的数据库,这是通过用标签记录机器名称来完成的。当物理机运行应用程序时,机器名称相对静态,但容器和 Kubernetes 显著改变了这个领域。
Kubernetes 中的物理机相当于 pod。 Pod 是唯一可识别的容器的运行实例。由于 Pod 的轻量级特性,Pod 的创建和销毁比物理机器更容易。
在 Kubernetes 中,pod 重新启动会生成一个新名称。新的 Pod 名称会转换为新的标签值,从而使旧时间序列无效并创建新时间序列。在一年多的时间里,典型的 Kubernetes 安装预计会以这种方式生成和失效数百亿个时间序列。大量时间序列可能会导致查询历史数据变得困难并降低数据库速度。
这个问题不像高基数那么明显。时间序列数据库的典型用例涉及查询数小时或数天的历史数据,从而减少所涉及的时间序列的数量。随着用户对时间序列数据库的要求越来越多,并在更长的时间内进行更深入的分析,我们预计这个问题将变得更加普遍。
时序库宽事件需求
最近,关于宽事件的概念引起了很多讨论。宽事件有点像结构化日志条目。它记录特定时间发生的事情以及键值对形式的关联属性。它们被称为“宽事件”,而不仅仅是“事件”,因为它们应该捕获事件周围的所有上下文,从而导致每个事件有许多属性。
宽事件是可观察性的一个令人兴奋的发展,因为它们可以帮助替换难以查询的非结构化日志和跟踪。我们不认为广泛事件会取代指标,因为广泛事件所需的存储空间比指标大几个数量级。由于巧妙的压缩,单个指标值可以以不到一个字节的形式存储在 VictoriaMetrics 中。
如果您有兴趣使用宽事件来帮助增强日志记录,那么值得查看 VictoriaLogs。 VictoriaLogs 允许您为每个日志条目存储任意键值对,然后您可以在查询时对其进行过滤和分组。 VictoriaLogs 还支持非结构化日志,让您可以按照自己的节奏进行转换。
结论
时间序列数据库是任何软件工程师工具箱中必不可少的工具。它们的发展受到用户需求和无数开源贡献者的影响,形成了我们今天看到的健康的生态系统。
原文:https://victoriametrics.com/blog/the-rise-of-open-source-time-series-databases/



