
PromQL教程(三)PromQL 入门操作

在 2024 年的当下,Prometheus 生态基本已成为监控领域事实上的标准,学习 Prometheus 是每个运维人员的必修课,也是每个关注服务稳定性的研发人员的必修课。PromQL 是 Prometheus 的查询语言,全称是 Prometheus Query Language,想要学习 Prometheus,PromQL 是必学知识。本文是 PromQL 系列教程的第三讲,讲解 PromQL 入门操作。本系列其他文章:
PromQL 查询选择器
PromQL 用的最多的就是查询选择器,之前文章中演示的 env="plus" 就是典型的选择器的匹配过滤方式。
监控指标中,通常包含不同的标签,用于标识不同的维度,比如 job、instance、env 等。PromQL 提供了一种灵活的方式,可以通过标签选择器来过滤数据,只查询符合条件的数据。PromQL 支持四类过滤写法:
=:完全匹配,比如app="clickhouse"!=:完全不匹配,比如app!="clickhouse"=~:正则匹配,比如app=~"n9e-.*"!~:正则不匹配,比如app!~"n9e-.*"
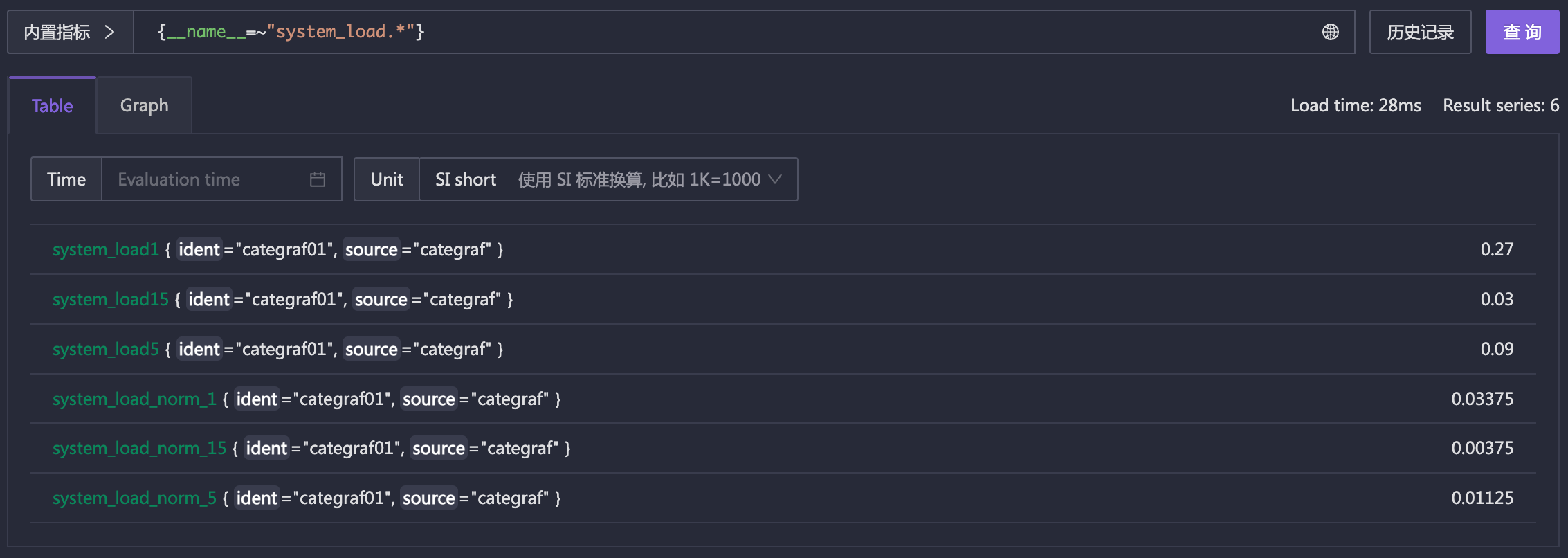
如前文所述,指标名称,通常放到大括号之外,但实际上,指标名称也是一个标签,其标签Key是 __name__,比如:
{__name__="mem_available_percent", app="clickhouse"}
有时采集的监控数据格式设计的不好,一些本该用 label 的信息,放到了 metric 名称中了,此时就可以用 __name__ 做一些正则匹配。或者有时我们想把多个类似的指标放到一张图中展示,也可以用 __name__ 来做正则匹配。
PromQL 简单聚合
除了查询选择器,PromQL 中另一个最常用的功能就是聚合计算,比如我有多台机器,我想知道所有机器的平均内存可用率,这时候就需要用到聚合计算。比如:
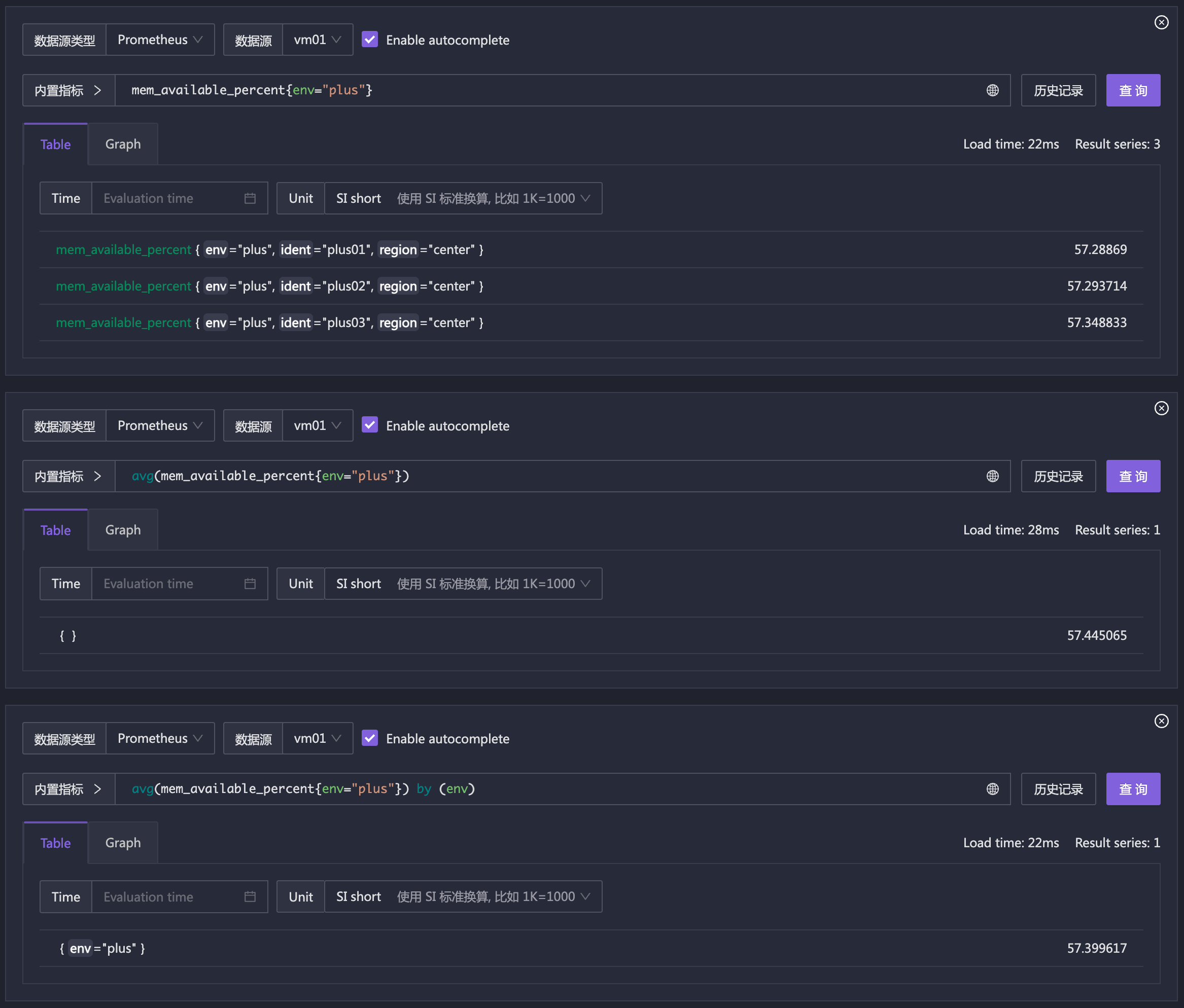
上例这个图中,第一个卡片是查询的原始数据,没有经过任何聚合,可以看到三台机器的内存可用率分别是多少。第二个卡片是对所有机器的内存可用率做了平均值计算,得到了一个平均值。因为经过了平均计算,所有的标签都会被抹掉,因为从语义上来看,经过了平均计算之后的值,其结果是一个全新的东西,无法用之前的标签来描述了。而第三张图是使用 env 做了 group by,其结果中就包含了 env 这个标签。这个逻辑和 SQL 中的 group by 是类似的。从语义上来看,相当于,不同的 env 会聚合出一个结果值(并带有 env 标签),当然,因为这里的 3 条原始数据恰好仅属于一个 env,所以结果就只有一条。
offset 关键字
监控系统里,经常会有同环比的需求,比如,当前的值相比一周之前,是否有巨大变化,那怎么才能获取历史数据呢?可以使用 offset 关键字。
offset 后面跟一个时间段,比如 5m、1d、7d、1w,offset 要紧跟查询选择器,比如:
sum(http_requests_total{method="GET"} offset 1d)
如果你使用夜莺监控的即时查询 Table 视图,要想查看历史某个时刻的数据,可以使用 offset 关键字,也可以直接在时间选择器中选择历史时间。
PromQL 运算符
PromQL 支持基本的算术运算符和比较运算符,可以对不同的即时向量做运算,这为监控系统带来了巨大的进步,算术运算符让很多计算不需要在采集端做了,可以轻易挪到服务端,而比较运算符则为告警逻辑提供了支撑。
如果服务端不支持指标运算,那这个运算逻辑就要挪到采集侧,比如 agent 侧,但是 agent 的变更是比较费劲的(毕竟要改动源码并编译升级),尤其是机器量比较大的情况下,所以,PromQL 的这个特性,让监控系统的运算逻辑变得更加灵活。
算术运算符
+(addition)-(subtraction)*(multiplication)/(division)%(modulo)^(power/exponentiation)
举一个例子来演示真实环境下的算术运算符的应用,比如之前的例子,对于内存可用率的指标 mem_available_percent 这个指标是采集器直接计算好的,如果采集器没有计算,而是上报了原始指标 mem_available 和 mem_total,我们仍然可以使用 PromQL 计算出可用率指标:
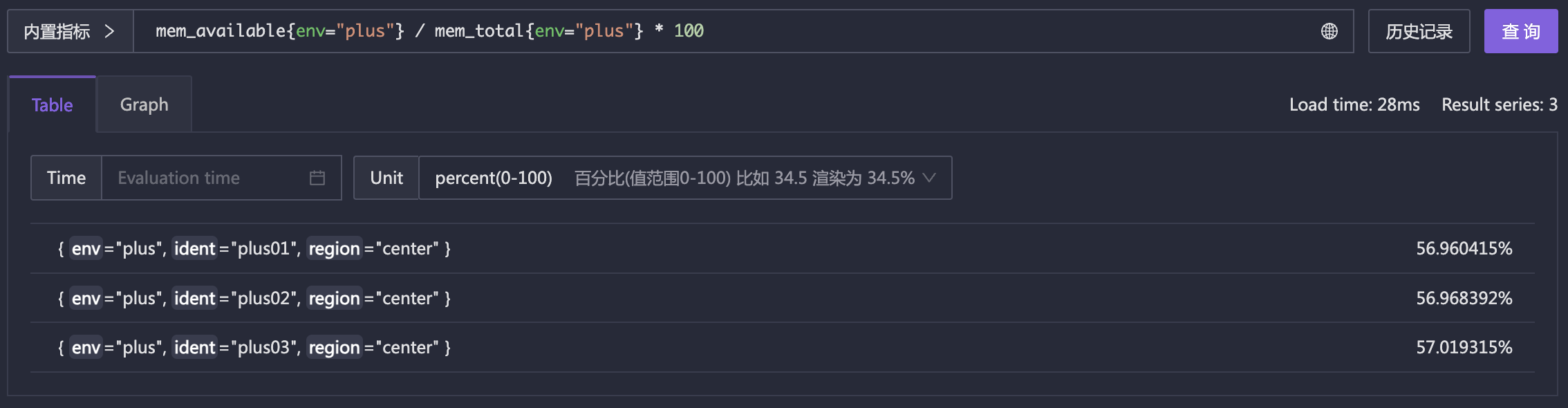
逻辑上,是先根据 mem_available{env="plus"} 找到相关指标数据,会找到3条,再根据 mem_total{env="plus"} 也能找到3条,二者相除的逻辑姑且可以理解为,循环遍历 mem_available 的3条记录,对于每一条,去 mem_total 的3条记录中找标签相同的记录,进行除法运算。除法运算得到 3 条结果(0~1之间的数字),然后跟100相乘(得到百分比大小),100这个数字称为标量,3条结果和标量计算,会把每一条结果分别乘以100,得到最终的结果,这个最终结果其实就是 mem_available_percent。
如果分子和分母对应的selector查到的数据标签不同,就没法做除法运算了,比如 net_bytes_recv 比内存相关的指标多了一个interface的标签(标明网卡),二者是没法做运算的(当然,语义上也没有意义),结果为空:
net_bytes_recv{env="plus"}/mem_total{env="plus"}
比较运算符
==(equal)!=(not-equal)>(greater-than)<(less-than)>=(greater-or-equal)<=(less-or-equal)
比较运算符通常用在告警规则中,比如:
cpu_usage_idle{env="plus"} < 10
这个告警规则的意思是,如果 CPU 空闲率小于 10%,就触发告警。不管是 Prometheus 还是 vmalert 还是 Nightingale,其告警引擎的逻辑都是类似的,以这个规则举例,其行为是:
- 告警引擎拿着这个 PromQL 周期性去查询时序库,使用
/api/v1/query接口 - 如果查询结果是空,说明没有数据符合条件,告警引擎就不会触发告警
- 如果查询结果不为空,说明有数据符合条件,即有些机器负载较高,需要告警,查到几条就产生几条告警
- 如果觉得偶发性达到阈值不算啥事,无需告警,可以设置告警规则的
for参数,比如for: 5m,表示连续 5 分钟满足条件才会触发告警
告警引擎的这个逻辑,非常清晰。但是,只要查不到数据就认为是正常的,这个可能会给你带来困扰。如果想要确保查到数据并且符合阈值才告警,可以使用 Flashduty 的告警功能,Flashduty 是快猫星云提供的一款 SaaS 产品,提供多种告警机制,既支持 Prometheus 类似的方式,也扩展了一些更加灵活的告警方式。
逻辑/集合运算符
相关运算符有三个:and、or、unless 用于 instant-vector 之间的运算。首先来解释一下各个运算符的行为。
and
vector1 and vector2,其结果是一个由vector1的元素组成的向量,对于这些元素,vector2中存在着完全匹配的标签集,其他元素被删除。metric的名称和值从左边的向量转移过来。
用于什么场景?先经过 vector1 做过滤得到一批监控数据,可能里边有一些是不想要的,可以用 and 操作符,再加一个条件,用另一个 metric 的值做一些二次过滤。举例:
disk_used_percent{app="clickhouse"} > 70
and
disk_total{app="clickhouse"}/1024/1024/1024 < 500
磁盘利用率大于 70% 就告警,对于盘不大的情况是适用的,如果盘太大,比如 16T 一块盘,使用率 70% 还有非常大的余量,所以这里我们使用 and 附加一个条件,限制一下 disk_total,即磁盘总大小,磁盘总大小小于 500GB,才适用磁盘利用率大于 70% 这个规则。
or
vector1 or vector2,其结果是一个向量,包含vector1的所有原始元素(标签集+值)以及vector2中所有在vector1中没有匹配标签集的元素。
举一个例子,比如系统负载,有最近1分钟、最近5分钟、最近15分钟的负载,需求是:最近1分钟的负载大于8或者最近5分钟的负载大于8,就告警,PromQL 写法:
system_load1{app="clickhouse"} > 8
or
system_load5{app="clickhouse"} > 8
unless
vector1 unless vector2,结果是一个由vector1中的元素组成的向量,在vector2中没有完全匹配标签集的元素,两个vector中的所有匹配元素都被删除。姑且可以理解为一个减法,vector1 - vector2。
举个例子,还是磁盘利用率的问题,对于超过1个T的大盘,剩余量小于300G就告警,PromQL 怎么写?
disk_free{app="clickhouse"}/1024/1024/1024 < 300
unless
disk_total{app="clickhouse"}/1024/1024/1024 < 1024
使用 unless 排除掉小于1个T的盘,剩下的就只剩大于1个T的大盘了,效果达成。
结语
本文讲解了 PromQL 的查询选择器、简单聚合、offset 关键字、运算符等基础操作,这些知识是学习 PromQL 的必备知识,希望对你有帮助。如果对 PromQL 教程系列的内容感兴趣,欢迎持续关注。



