

在 2024 年的当下,Prometheus 生态基本已成为监控领域事实上的标准,学习 Prometheus 是每个运维人员的必修课,也是每个关注服务稳定性的研发人员的必修课。PromQL 是 Prometheus 的查询语言,全称是 Prometheus Query Language,想要学习 Prometheus,PromQL 是必学知识。本文是 PromQL 系列教程的第一讲,先介绍一些基础概念。
核心摘要
- PromQL 是 Prometheus Query Language,用来查询、过滤和计算 Prometheus 时序数据。
- 一个数据点由指标名、标签、值和时间戳组成;指标名和标签共同决定一条时序。
- 时序数据库 TSDB 适合存储带时间戳、按时间范围查询、按标签过滤和聚合的数据。
/api/v1/query用于查询某个时刻的数据;只写 selector 通常返回 instant vector,加上[1m]这类范围会返回 range vector。/api/v1/query_range用于查询一段时间范围内的数据,start、end、step会共同决定返回的数据点。--query.lookback-delta会影响即时查询向前寻找最近数据点的时间范围,默认是 5m。
什么是指标、数据点
在介绍 PromQL 之前,我们先来澄清一些基础概念。
在监控领域,我们经常会听到指标(Metric)这个词。指标是对系统或服务某个特定方面进行量化的测量值。比如,服务器的 CPU 使用率、内存使用率、数据库连接数、某个 API 的 99 分位延迟,都是常见指标。指标可以反映系统运行状态,帮助我们了解系统的性能、稳定性、可用性等。
指标数据一般是周期性采集,每次采集到的数据称为一个数据点,举例如下:
{
"metric": "cpu_usage_idle",
"labels": {
"host": "10.1.2.3",
"region": "us-west"
},
"value": 82.3,
"timestamp": 1632892800
}
上例是用 JSON 格式表示的一个数据点,包含了以下几个字段:
metric:指标名称,比如cpu_usage_idle表示 CPU 空闲率labels:标签,用于标识数据点的维度,比如host表示主机名,region表示地区value:数据点的值,比如 82.3 表示 CPU 空闲率为 82.3%timestamp:数据点的时间戳,比如 1632892800 表示 Unix 时间戳
metric、labels、value、timestamp 四个字段组成了数据点的完整信息;metric、labels 两个字段组成了指标或时序的唯一标识。
就上例而言,假设 10.1.2.3 这个机器每 15 秒采集一个数据点,一分钟就会有 4 个数据点,一小时就会有 240 个数据点,一天就会有 5760 个数据点。如果我们有 10000 台机器,一天就会有 57600000 个数据点。而这,仅仅是机器的一个指标,实际上,我们还会采集很多其他指标,另外除了机器,还要采集数据库、中间件、应用程序等的指标,数据量是非常庞大的。很多大公司每秒甚至会采集数千万、上亿的数据点。
这么大的数据量,存在哪里?
时序数据库 TSDB(Time Series Database)
这类数据有个典型特点:每个数据点都带有时间戳,查询时通常会指定时间范围,比如查询最近 15 分钟还是最近 1 小时。这类数据就是典型的时序数据。
时序数据量大、查询时要根据标签灵活过滤、做聚合计算,传统的关系型数据库无法胜任,因此,时序数据库应运而生。第一个比较知名的开源时序库是 InfluxDB,Prometheus 也内置了一个时序数据库,以本地文件的特定格式存储这些数据。
关系型数据库的查询语言是 SQL,Prometheus 也为时序数据查询设计了一种全新的语言 PromQL。PromQL 非常流行,很多时序库都会兼容 PromQL,比如 VictoriaMetrics、GrepTimeDB 等。
使用 PromQL 查询时序数据的样例
既然 PromQL 是用来查询时序数据的,那我们先做一个 Hello world 级别的查询测试,用 PromQL 查询一次数据,建立直观认识。下面使用夜莺监控的即时查询来演示,你也可以直接使用 Prometheus 自带的 UI 做查询测试。
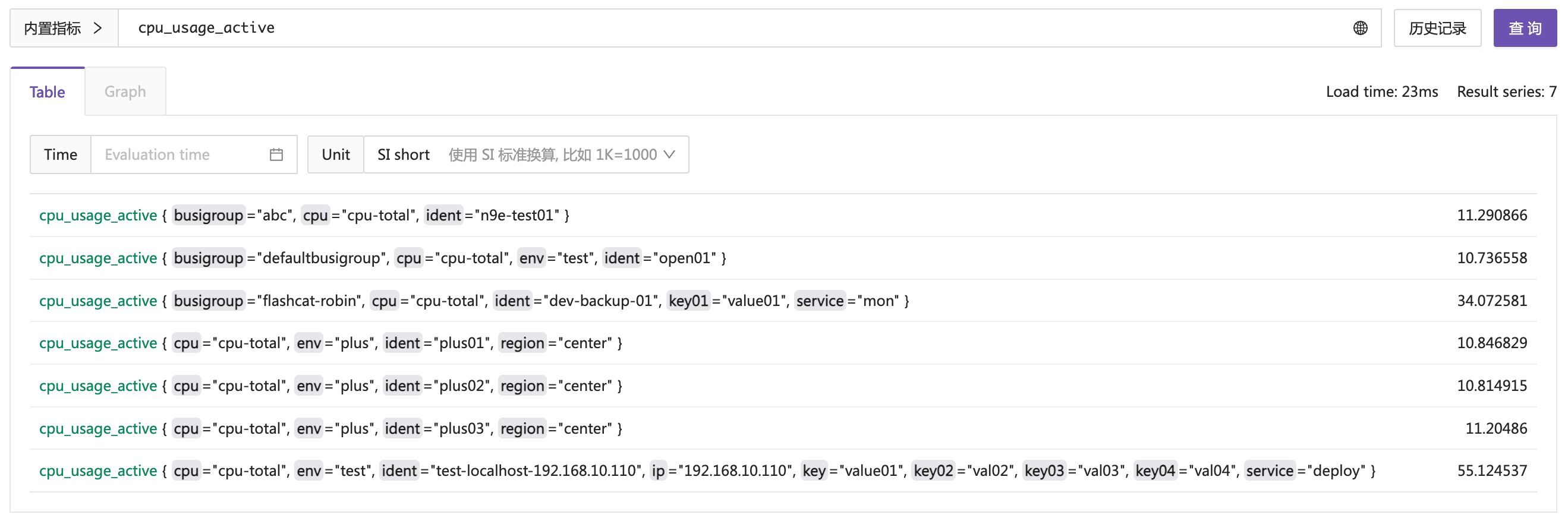
上例我是查询的 cpu_usage_active 这个指标,查到了 7 条数据。这个例子非常简单,想查什么指标,就输入对应的指标名就可以查询。因为我没有加过滤条件,就把时序库中存储的所有该指标的数据都查出来了。下面我加点过滤条件,只查询特定的一些数据。
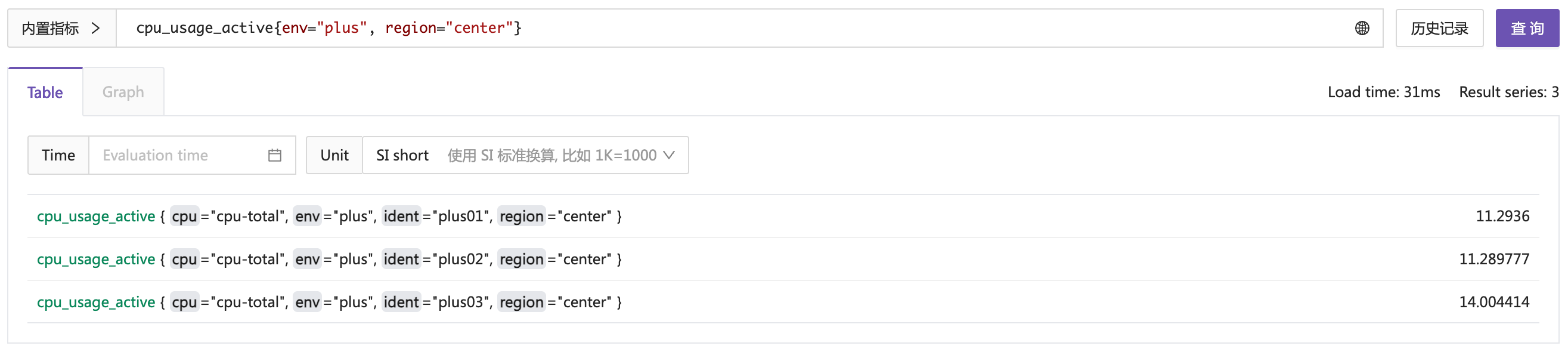
上例中,我在指标名字后面加了一对大括号,里面写了两个过滤条件:env="plus", region="center", 这样就只查询了 env 是 plus 且 region 是 center 的数据。
打开 Chrome 开发者工具,可以看到这个查询是请求的 /api/v1/query 接口,请求参数是 time 和 query:
time=1727592927&query=cpu_usage_active%7Benv%3D%22plus%22%2C%20region%3D%22center%22%7D
当然,上面的内容是 url 编码后的,解码后就是:
time=1727592927&query=cpu_usage_active{env="plus", region="center"}
返回的内容如下:
{
"status": "success",
"data": {
"resultType": "vector",
"result": [
{
"metric": {
"__name__": "cpu_usage_active",
"cpu": "cpu-total",
"env": "plus",
"ident": "plus01",
"region": "center"
},
"value": [
1727592927,
"10.795742524837411"
]
},
{
"metric": {
"__name__": "cpu_usage_active",
"cpu": "cpu-total",
"env": "plus",
"ident": "plus02",
"region": "center"
},
"value": [
1727592927,
"10.944097282143026"
]
},
{
"metric": {
"__name__": "cpu_usage_active",
"cpu": "cpu-total",
"env": "plus",
"ident": "plus03",
"region": "center"
},
"value": [
1727592927,
"10.882402563360198"
]
}
]
}
}
返回的内容,包含如下字段:
resultType是vector,后面我们做其他查询的时候,注意对比 resultTyperesult是个数组,包含多个vector,每个vector包含两部分:metric和valuemetric是个对象,包含了指标的标签信息,指标名也放到标签里的,用了一个很特殊的标签名__name__value是个数组,第一个元素是时间戳,第二个元素是值
注意,上例中 value 的时间戳是 1727592927,和查询参数里的时间戳一样,我们直观理解的话,会认为 TSDB 中的时序数据恰好有值是在 1727592927 时刻采集的,所以查询时就返回了。但是,我的指标数据是 15s 采集一次,哪有这么巧,正好在我发起查询的那一刻采集到数据?!
如果你连续点击几次查询按钮并分析发起的多次查询,会发现:值不变,时间戳一直在变,返回的时间戳和查询参数里的时间戳一直保持一致。
这是因为 Prometheus 的查询引擎在查询时,会根据查询参数里的时间戳,去找最近的数据点,而不是严格按照时间戳去查找。那也不能无限制一直往前找,最多可以往前找多久,是由 Prometheus 的启动参数:--query.lookback-delta 决定的,默认是 5m,也就是说,你发起查询时,最多只会往前找 5 分钟的数据。(这个知识点至关重要)
所以,上例中这类查询,返回的时间戳并非是 TSDB 里存储的真实时间戳。那如果我就想知道真实的时间戳,应该怎么办?
Prometheus range vector vs instant vector
上面的 PromQL 稍微变换一下,在后面加一个时间范围,比如 [1m] 表示一分钟,点击查询看到如下结果:
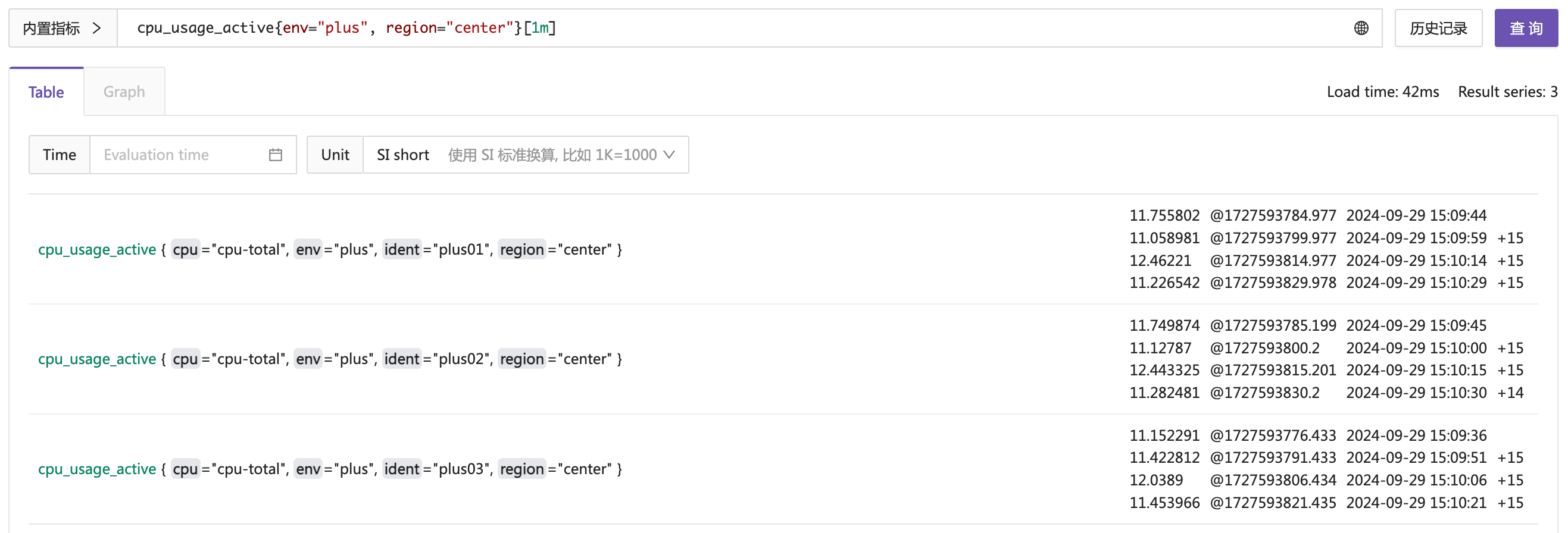
大括号里的过滤条件称为 selector,metric_name 其实也是 selector 的一部分,
cpu_usage_active{env="plus", region="center"}就相当于{__name__="cpu_usage_active", env="plus", region="center"},metric_name 写到大括号前面姑且可以看做是一种语法糖。只有 selector 的查询,其查询结果称为instant vector,加上时间范围(上例中是[1m]),其查询结果称为range vector。后面我会贴出 response,你可以看到返回的数据结构。
因为数据是每 15s 采集一次,对于每个指标,一分钟就会有 4 个点,表格里第一列展示的指标标签,后面的部分就是那 4 个点的信息,夜莺监控为了易用性考虑,会展示值以及对应的时间戳,并且把时间戳转换成了人类可读的时间格式,并且会用下面的时间戳减去上面的时间戳,展示出时间间隔。(这对于排查问题非常有用)
查看 Chrome 开发者工具,可以看到这次查询的接口仍然是 /api/v1/query,请求参数是 time、query,其中 time 是 1727593833,返回的 response 中的时间戳已经不是固定的 1727593833 了,此时返回的那多个 时间戳+数值,才是时序库里真实存储的数据。
下面贴出 response,给你参考:
{
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "cpu_usage_active",
"cpu": "cpu-total",
"env": "plus",
"ident": "plus01",
"region": "center"
},
"values": [
[
1727593784.977,
"11.755802217046362"
],
[
1727593799.977,
"11.05898123024424"
],
[
1727593814.977,
"12.462210281214825"
],
[
1727593829.978,
"11.226541553767426"
]
]
},
{
"metric": {
"__name__": "cpu_usage_active",
"cpu": "cpu-total",
"env": "plus",
"ident": "plus02",
"region": "center"
},
"values": [
[
1727593785.199,
"11.74987392595977"
],
[
1727593800.200,
"11.127869952064797"
],
[
1727593815.201,
"12.443324937122252"
],
[
1727593830.200,
"11.282481141014513"
]
]
},
{
"metric": {
"__name__": "cpu_usage_active",
"cpu": "cpu-total",
"env": "plus",
"ident": "plus03",
"region": "center"
},
"values": [
[
1727593776.433,
"11.152291106290598"
],
[
1727593791.433,
"11.42281202857196"
],
[
1727593806.434,
"12.038900067201045"
],
[
1727593821.435,
"11.453966121635645"
]
]
}
]
}
}
这次 resultType 变成了 matrix,值的部分变成了 values,values 是个数组,每个元素是一个 value,value 的第一个元素仍然是时间戳,第二个元素仍然是值。
上例的两次查询都是调用的 /api/v1/query 接口,这个接口的时间参数仅仅是一个 time 时间戳,但是对于时序数据,还有另一个非常重要的查询场景,就是查询一段时间范围内的数据,这个时候就需要调用 /api/v1/query_range 接口了。
Prometheus query_range
还是刚才的例子,我现在切到 Graph 视图,就会调用 /api/v1/query_range 接口。
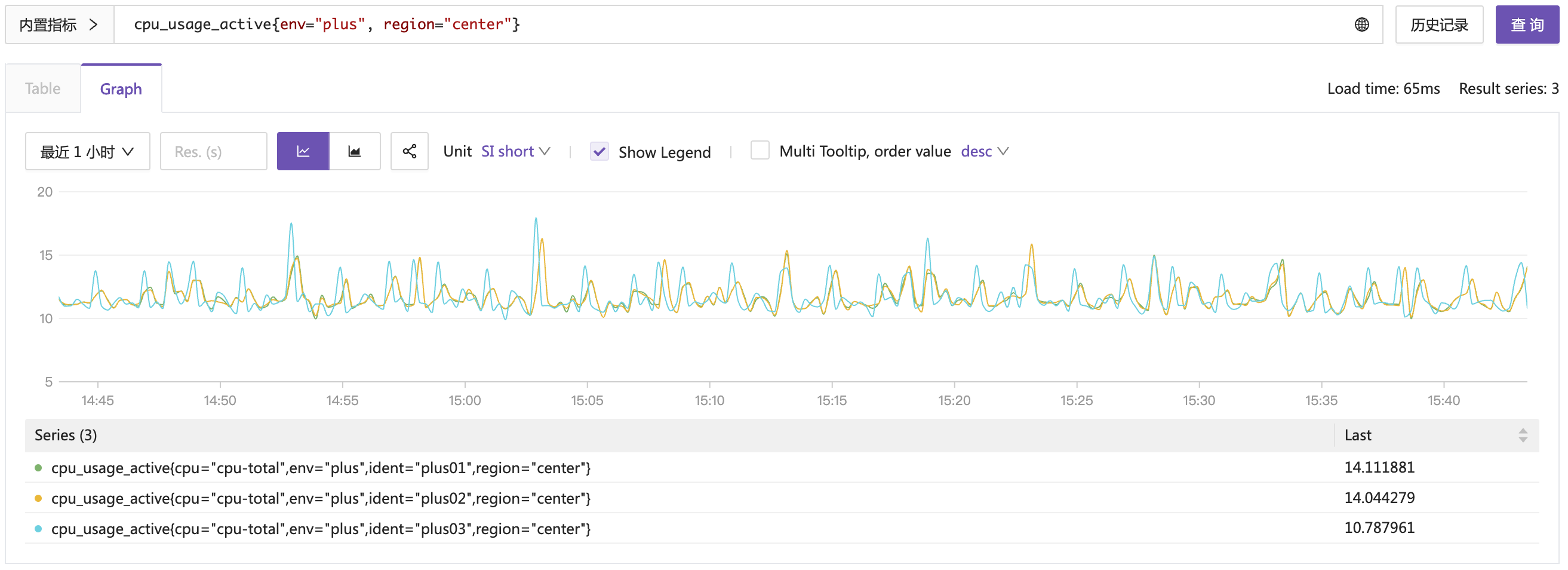
Graph 视图,不再展示为 Table 了,而是折线图。查到几个指标,就画几条线。
查看 Chrome 开发者工具,可以看到请求变成了 /api/v1/query_range,请求参数是 start、end、step、query,其中 start 是查询的开始时间,end 是查询的结束时间,step 是查询的时间间隔,query 是查询的 PromQL 语句。
这里最不好理解的是 step 参数,这个参数是用来控制返回的数据点的时间间隔的,比如 step=15,就是每 15s 返回一个数据点,step=60,就是每分钟返回一个数据点。这个参数的值,会影响到返回的数据点的数量,也会影响到返回的数据点的时间戳。
如果你查询的时间范围很大,step 很小,就会返回非常多的数据,导致浏览器崩溃。用户默认没有指定 step 的值,夜莺会自动计算一个合适的值,保证返回的数据点数量不会太多。
如果想手工指定 step 的值,也是可以的,就是 “最近一小时” 后面那个输入框,placeholder 是 Res.(s) 的那个输入框,在里边手工填写指定 step 的值即可。
我这里把时间范围设置的小一点,设置为最近一分钟,step 设置为 1,点击查询,看到如下结果:
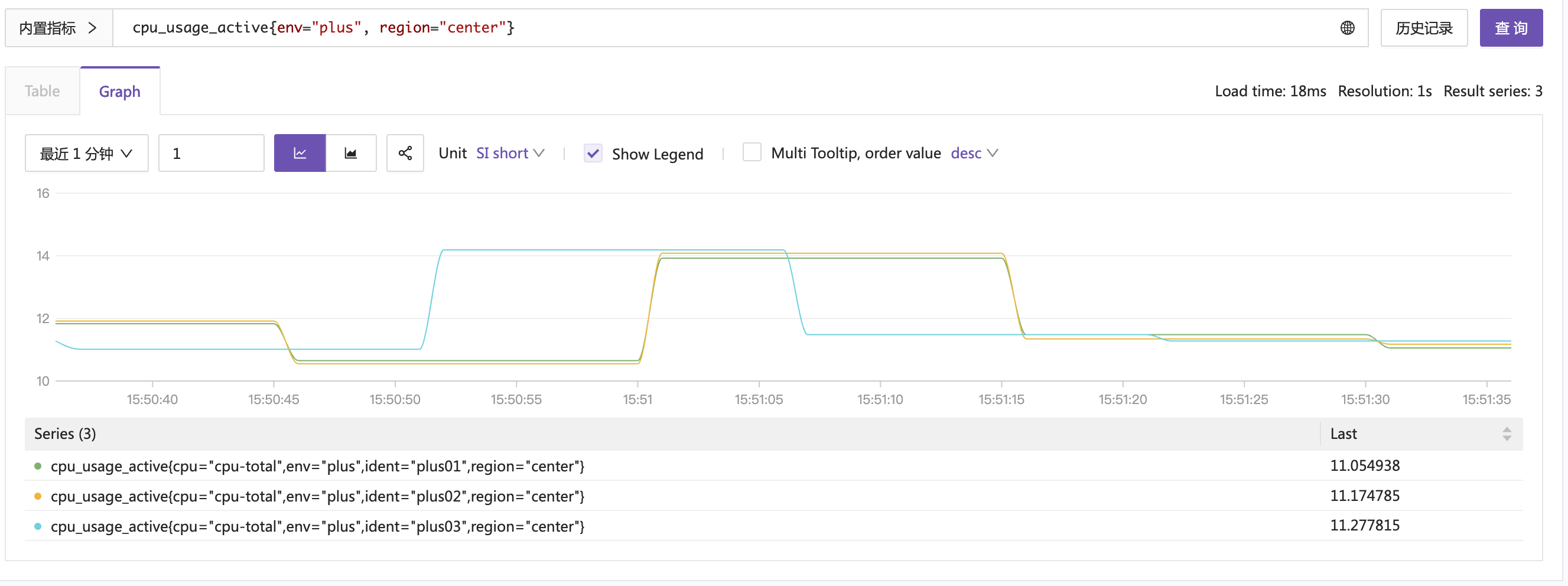
鼠标放到图上,来回移动,可以看到数据点的间隔变成了 1s。但是,我的原始数据是 15s 才采集一次,多了很多数据点,说明 Prometheus 存在自动补点渲染的逻辑。它会根据你传入的 start、end 确定时间范围,把这个时间范围内的数据点都查出来,然后根据 step 参数确定各个数据点的间隔,把这些数据点挨个补全,最终返回。
结论
本文是 PromQL 系列教程的第一篇,重点是建立时序数据和 PromQL 查询模型的基础认知。先理解指标、标签、数据点、instant vector、range vector、/api/v1/query 和 /api/v1/query_range,后续学习聚合、函数、运算符和告警规则才不会混乱。
FAQ
Q1:PromQL 是什么?
A:PromQL 是 Prometheus Query Language,用来查询和计算 Prometheus 中的时序数据。
Q2:指标和数据点有什么区别?
A:指标由指标名和标签唯一标识;数据点是在某个时间戳下采集到的具体值。
Q3:instant vector 和 range vector 有什么区别?
A:instant vector 表示某个时刻的一组时序值;range vector 表示一段时间范围内的一组时序值,例如 cpu_usage_active[1m]。
Q4:为什么即时查询返回的时间戳不是原始采集时间?
A:Prometheus 查询引擎会根据查询参数里的时间戳向前寻找最近的数据点,最多向前找多久由 --query.lookback-delta 控制,默认是 5m。
Q5:query 和 query_range 应该怎么区分?
A:/api/v1/query 查询某个时刻的数据;/api/v1/query_range 查询一段时间范围内的数据,并通过 step 控制返回点的间隔。



