
Prometheus 聚合查询的两个方案
问题背景
多个 Prometheus 集群或者多个 VictoriaMetrics 集群,在 Grafana 和夜莺里通常需要创建多个不同的数据源,这也就意味着,数据没法聚合查询,比如统一做一下 sum 之类的运算会比较麻烦,本文讲述两种 Prometheus 生态的聚合查询方案,以供参考。
场景模拟
我在本地模拟一个这样的场景:两套时序库,比如一套采集的 tomcat 相关机器的指标,一套采集的 oracle 相关机器的指标,相当于按业务切分的两套时序库。这里涉及三个组件:
- node_exporter:仅用于模拟提供监控指标
- prometheus9090:监听在 9090 端口的 prometheus,用于采集 node_exporter 的监控指标,会为数据附加上
service="tomcat"的标签,表示这是 tomcat 业务的监控指标 - prometheus9091:监听在 9091 端口的 prometheus,用于采集 node_exporter 的监控指标,会为数据附加上
service="oracle"的标签,表示这是 oracle 业务的监控指标
prometheus9090 的配置文件 prometheus.9090.yml 如下:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "node_exporter"
static_configs:
- targets: ["localhost:9100"]
labels:
service: tomcat
prometheus9091 的配置文件 prometheus.9091.yml 如下:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "node_exporter"
static_configs:
- targets: ["localhost:9100"]
labels:
service: oracle
最后,我把这俩时序库作为数据源配置到夜莺中,你也可以使用 Grafana 测试,分别查询这俩数据源,得到预期结果。
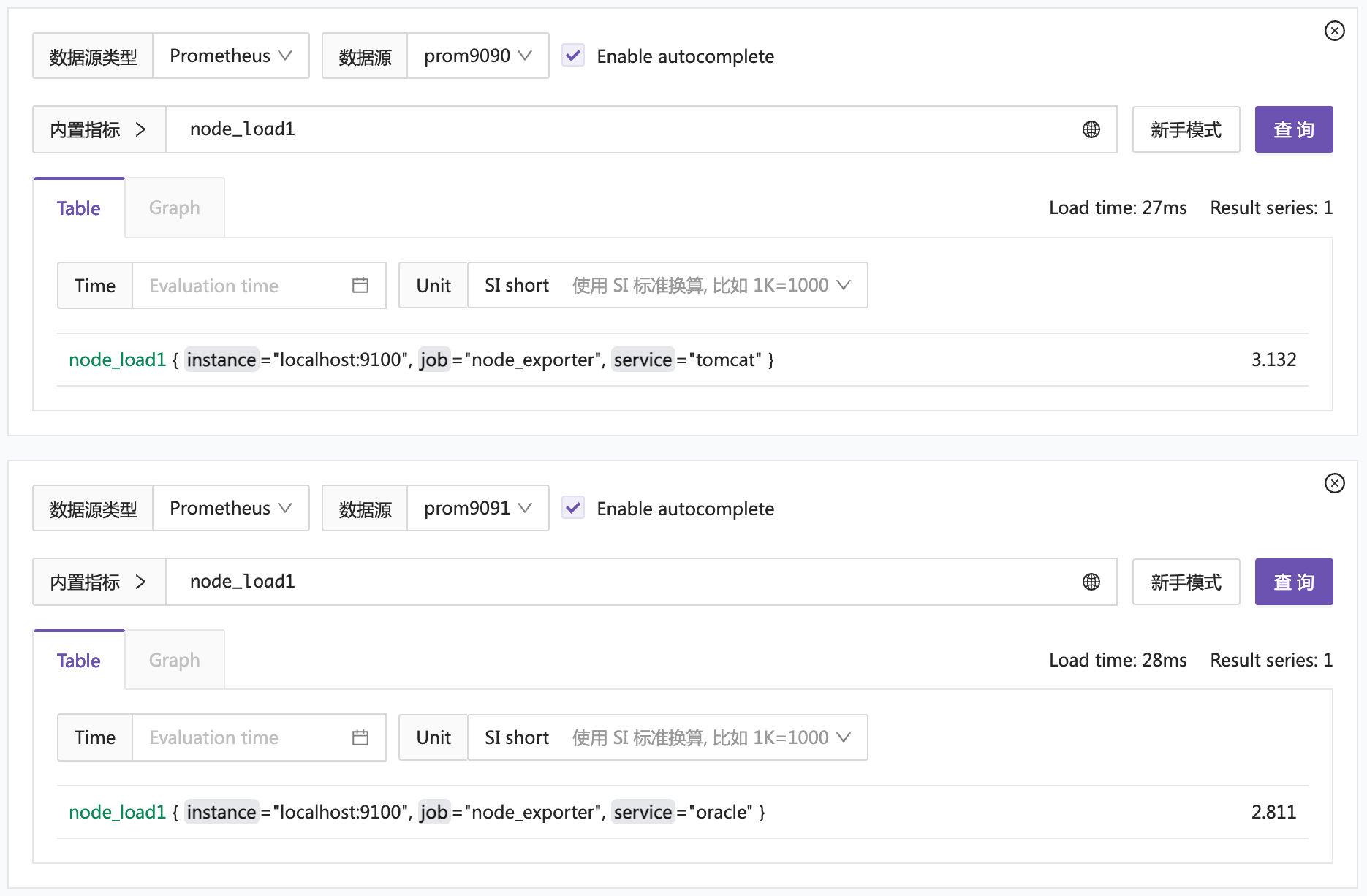
下面我们来看看如何聚合查询这两个数据源。
方案一:promxy
看这个名字就知道了,定位就是 prometheus 的 proxy,promxy 的 Github 地址是:https://github.com/jacksontj/promxy。按照 README 去安装就可以了,我的 promxy 的配置文件内容如下:
global:
evaluation_interval: 5s
promxy:
server_groups:
- static_configs:
- targets:
- localhost:9090
- static_configs:
- targets:
- localhost:9091
然后,把 promxy 作为数据源配置到夜莺或者 Grafana 中,注意 promxy 默认监听的端口是 8082,之后,就可以查询这个数据源的数据做测试了。
先查个简单的:node_load1
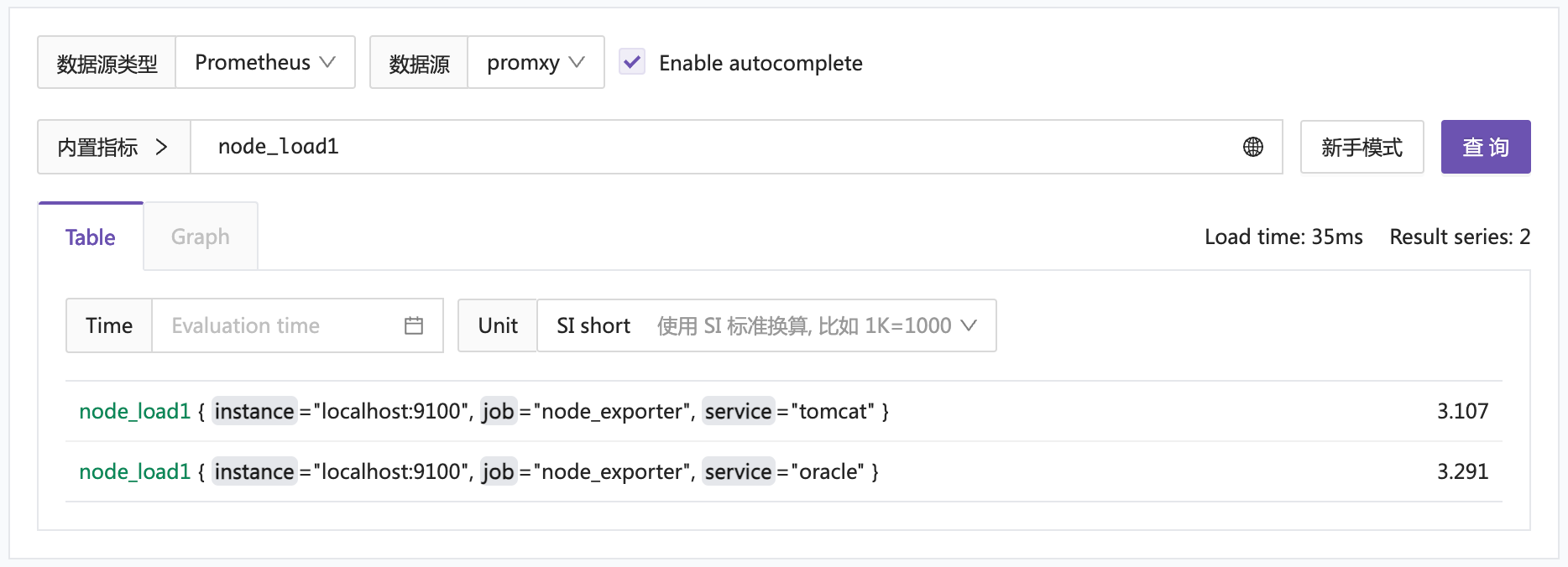
同时查到了两个时序库的数据,挺好的。然后做个聚合查询测试:
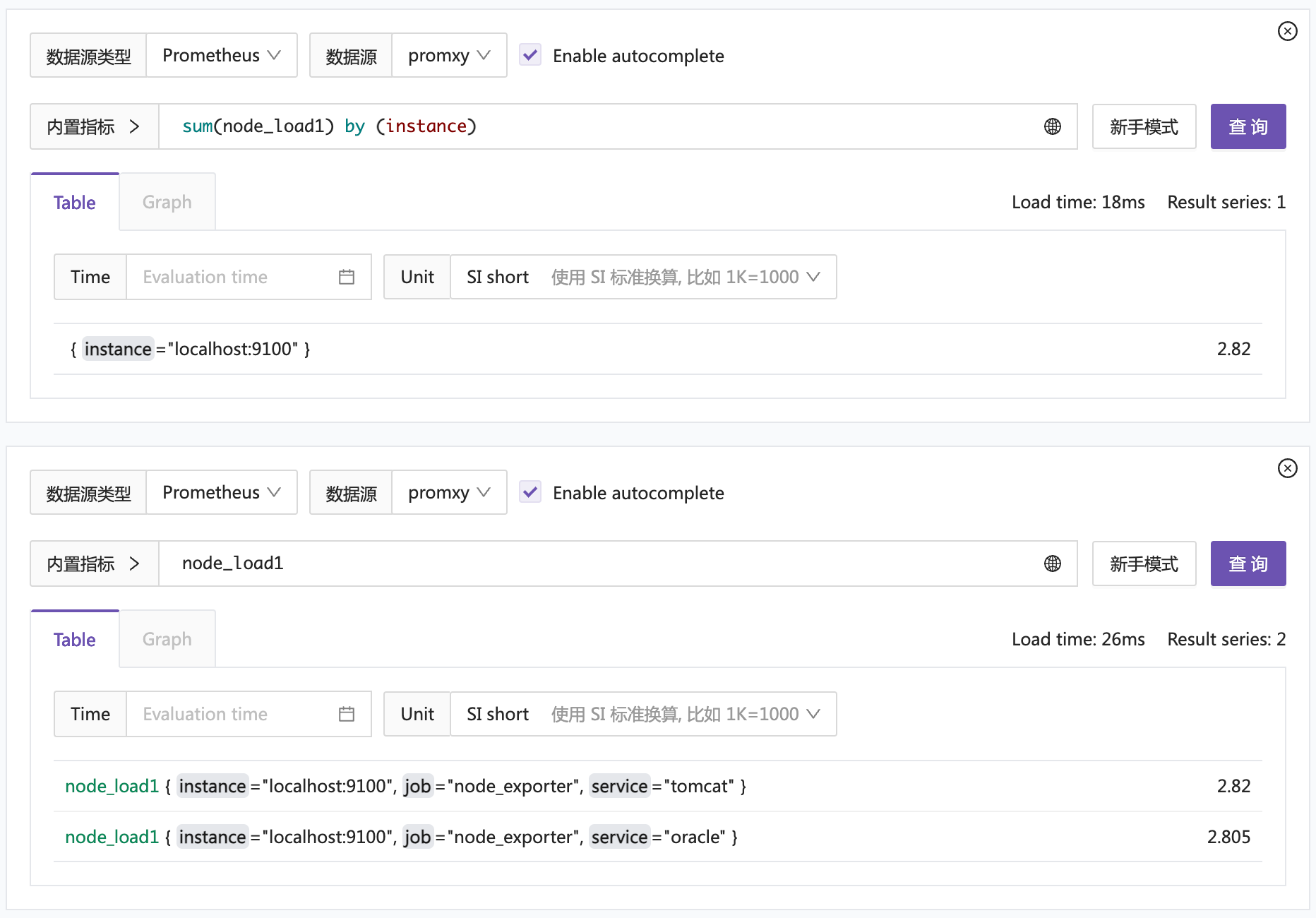
完犊子了,这个 sum 并未生效,看起来像是只查询了一个时序库的数据。这是个很基本的场景,不应该有 bug 才对,为啥会如此呢?我尝试两个解决办法:
- 在夜莺资深用户群扔了这个问题,资深群都是监控重度用户,可能有用过 promxy 的
- 下载了 promxy 的代码,准备从代码找找线索
资深群里确实有人用,有朋友提醒,promxy 中有个 server_group 的概念,是否应该为不同的 server_group 附加不同的标签呢?我直观感觉,应该是不需要的,因为这已经是多个 server_group 了,已经可以区分了才对,而且 TSDB 里已经有 service 标签做区分了。但是,我还是尝试了一下,修改 promxy 的配置文件如下:
global:
evaluation_interval: 5s
promxy:
server_groups:
- static_configs:
- targets:
- localhost:9090
labels:
region: a
- static_configs:
- targets:
- localhost:9091
labels:
region: b
额外附加了 region 的标签。然后重启 promxy 再次查询:
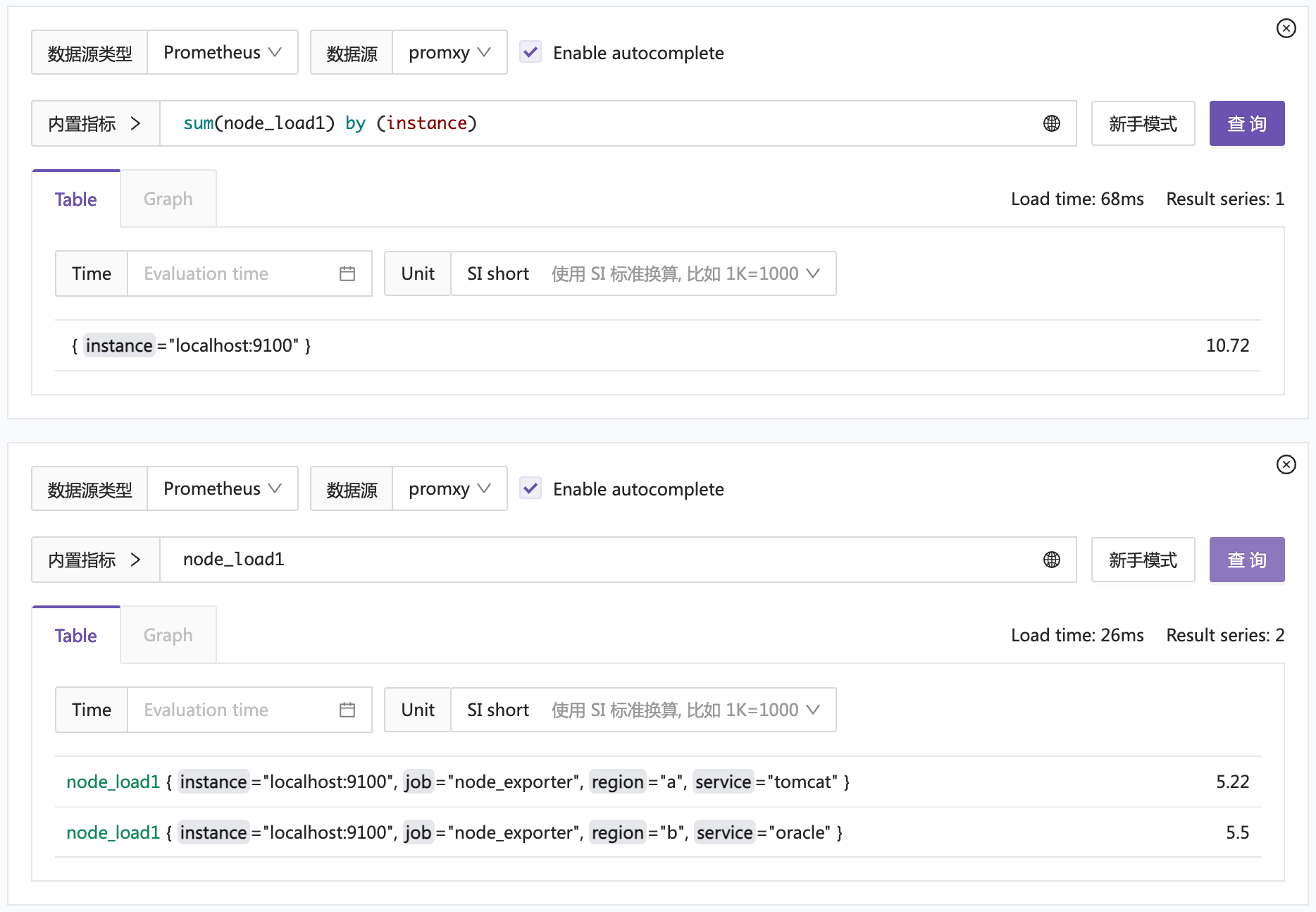
竟然就行了,哈哈。好吧,群里的朋友也反馈,之前他们没有踩到这个坑,是因为他们默认就给附加了标签。也不知道是 promxy 的 bug 还是有意为之。反正大家注意就好了。
方案二:Prometheus remote read
实际上,Prometheus 自身提供 remote read 能力,可以使用这个能力做聚合。我继续启动了一个 Prometheus 进程,监听在 9092 端口,配置文件 prometheus.9092.yml 如下:
global:
scrape_interval: 15s
evaluation_interval: 15s
remote_read:
- url: http://localhost:9090/api/v1/read
- url: http://localhost:9091/api/v1/read
把 9090 和 9091 作为 remote read 后端配上即可。然后把 9092 这个 Prometheus 作为数据源配置到夜莺或者 Grafana 中,查询这个数据源的数据做测试。
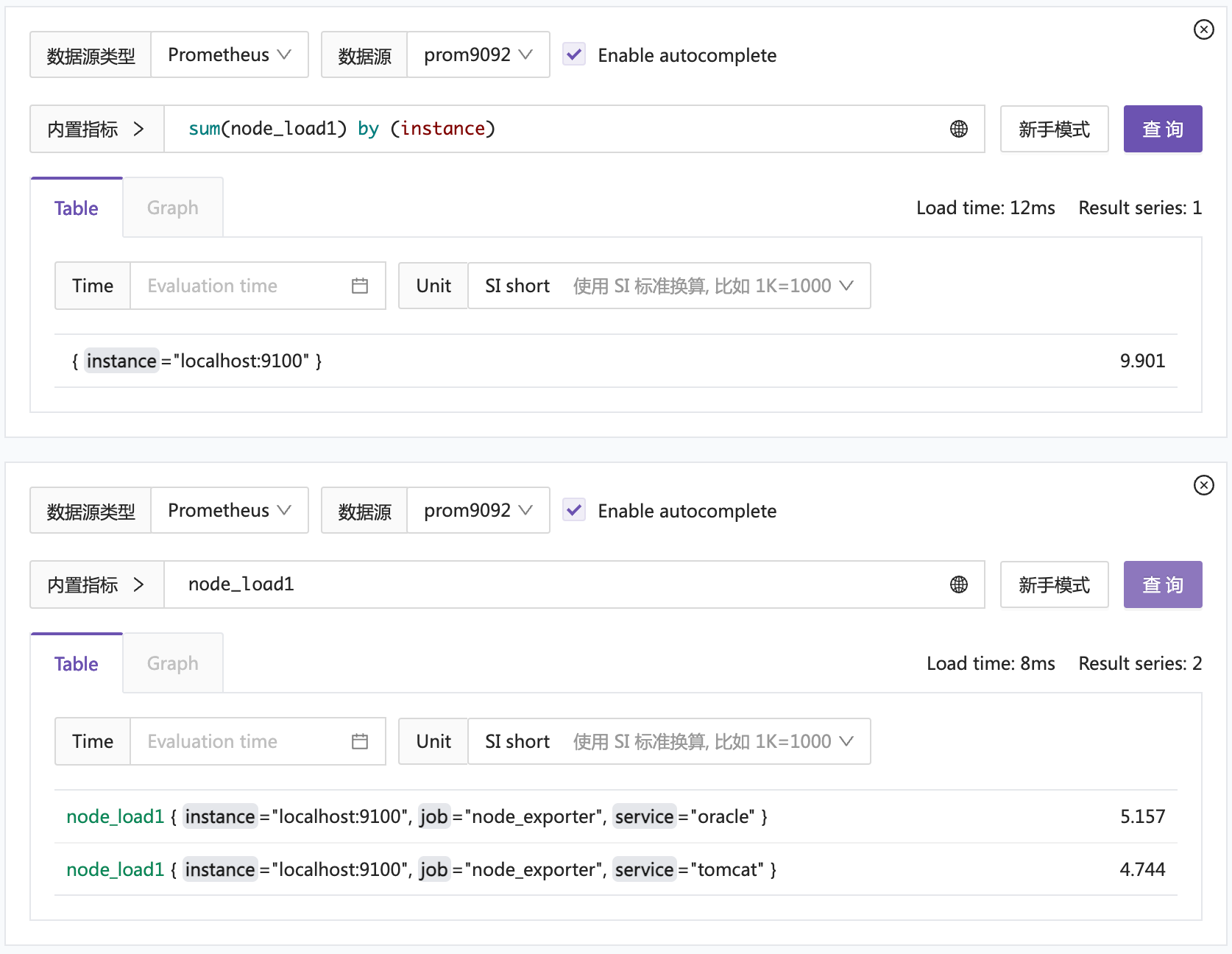
看起来是没问题的,不管是直接查询简单的 selector,还是聚合查询,都没问题。挺好的。

方案对比
首先,Prometheus remote read 方案,在编写 promql 的时候没有提示:

而 promxy 方案有提示:

这个原因是 remote read 方案只能查监控数据,没法查索引,自然也就没法有 suggestion 了。
其次,Prometheus read remote 只能查询那些支持 remote read 的后端,比如 VictoriaMetrics 就不支持 remote read,如果你的后端是 VictoriaMetrics,就只能使用 promxy 了。
如上,希望可以帮到你 :)
另外,本人创业两年了,我们公司主要是做监控、可观测性。我们希望通过合作努力,让中小公司具备行业顶尖的监控/可观测性能力,如果你有这方面的需求,欢迎联系我们:


