知乎:SLO 运营实践
在第二届 CCF 夜莺创新论坛上,知乎基础架构研发工程师邱天罡分享了知乎的可观测性体系实践和经验,以及如何利用 SLO 持续的度量、追踪和改进系统可用性。
知乎是一家领先的在线内容社区,人们来到这里寻找解决方案、作出决定、寻求灵感并获得乐趣。 自 2010 年首次上线以来,知乎已发展成为中国顶级的综合在线内容社区之一,更是全国最大的在线问答社区。 同时,知乎目前是纽约证券交易所(NYSE: ZH)和香港证券交易所(HKEX: 2390)的双重主要上市公司。
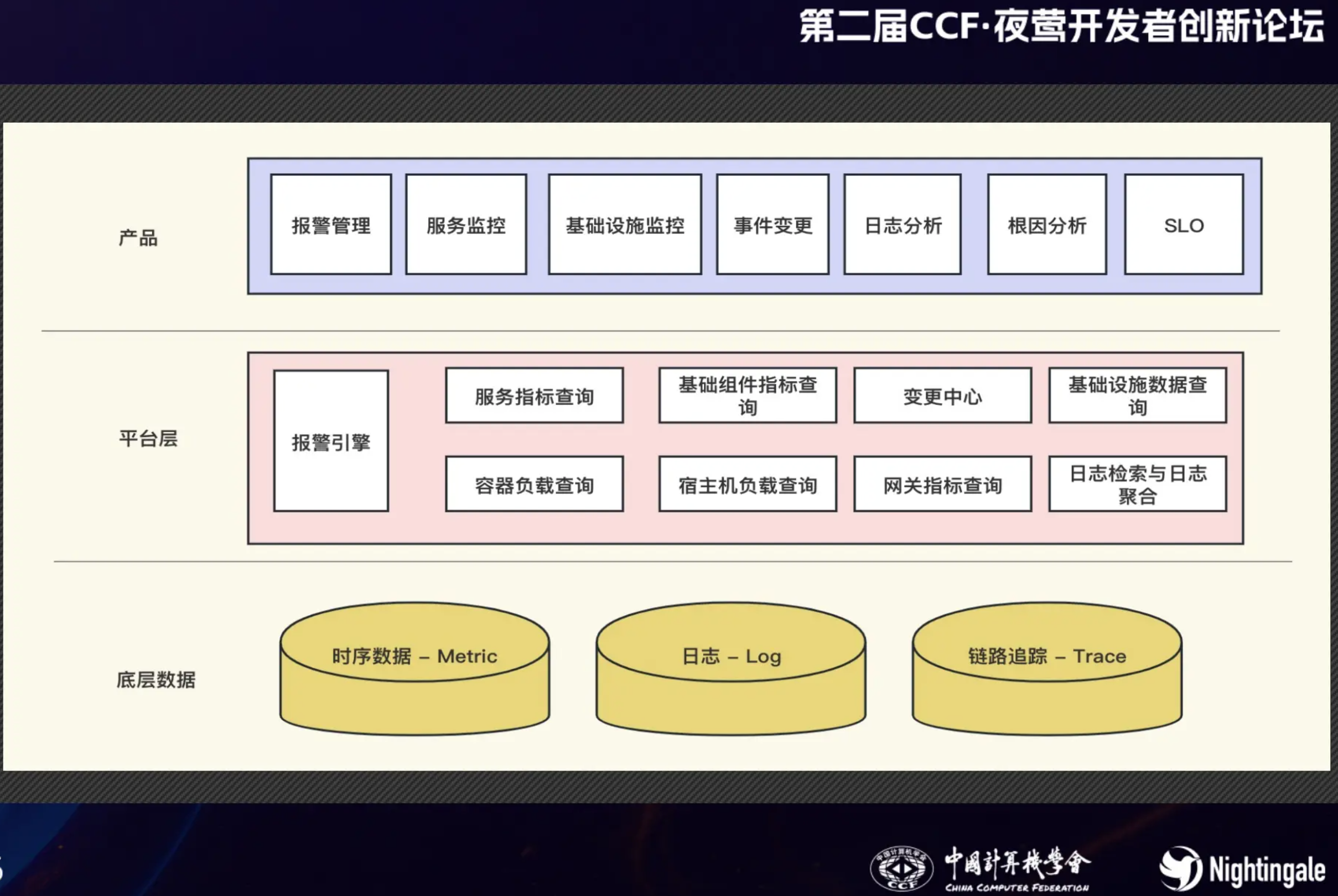
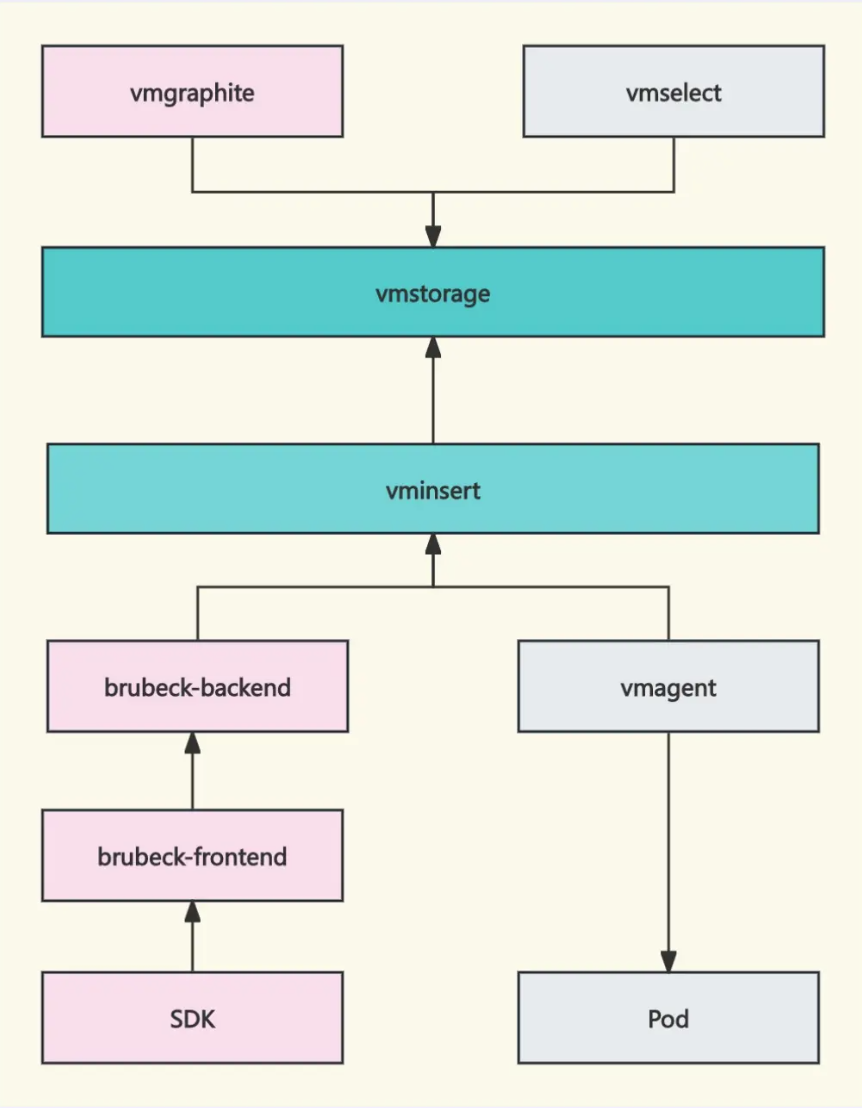
知乎的可观测性数据体量巨大,以 Metrics 为例,每秒写入 3 千万个数据点,全量存储 6 个月,知乎采用 Prometheus + Graphite + VictoriaMetrics 的组合方案来构建 Metrics 采集和存储体系。
Prometheus 主要用于发现、拉取、监控基础设施类服务的监控数据(比如 Pod 级别的指标);Graphite 主要用于采集服务级别的 metrics,通过 DNS 来发现后端服务,通过 UDP 协议上报数据;采用 VictoriaMetrics 作为统一的时序数据库。
Prometheus 作为采集器采集到的指标,写入和查询 Victoriametrics,是没有任何问题的。针对 Graphite,自研开发了 vmgraphite 组件,来和 vmstorage 通信,开发了数据转换层,把 Graphite 格式的数据转成 prom 格式,这样就把 Graphite 和 Victoriametrics 生态捏合在一起了。
有了海量的数据,建立了统一的数据存储、分析能力之后,我们将工作重心落在了“持续运营”上,即通过深入的数据发掘,建立以“服务”为维度的、持续的量化、分析、运营、改善闭环。
SLO(Service Level Objective)是度量服务可用性水平并持续跟踪的经典手段。近年来 SLO 的概念日趋流行,国外不少公司效仿 Google 的最佳实践落地 SLO,很多服务商也支持了 SLO(如 Datadog),甚至有创业公司专门聚焦 SLO 的产品化方案(如 NOBL9、Sloth 等)。
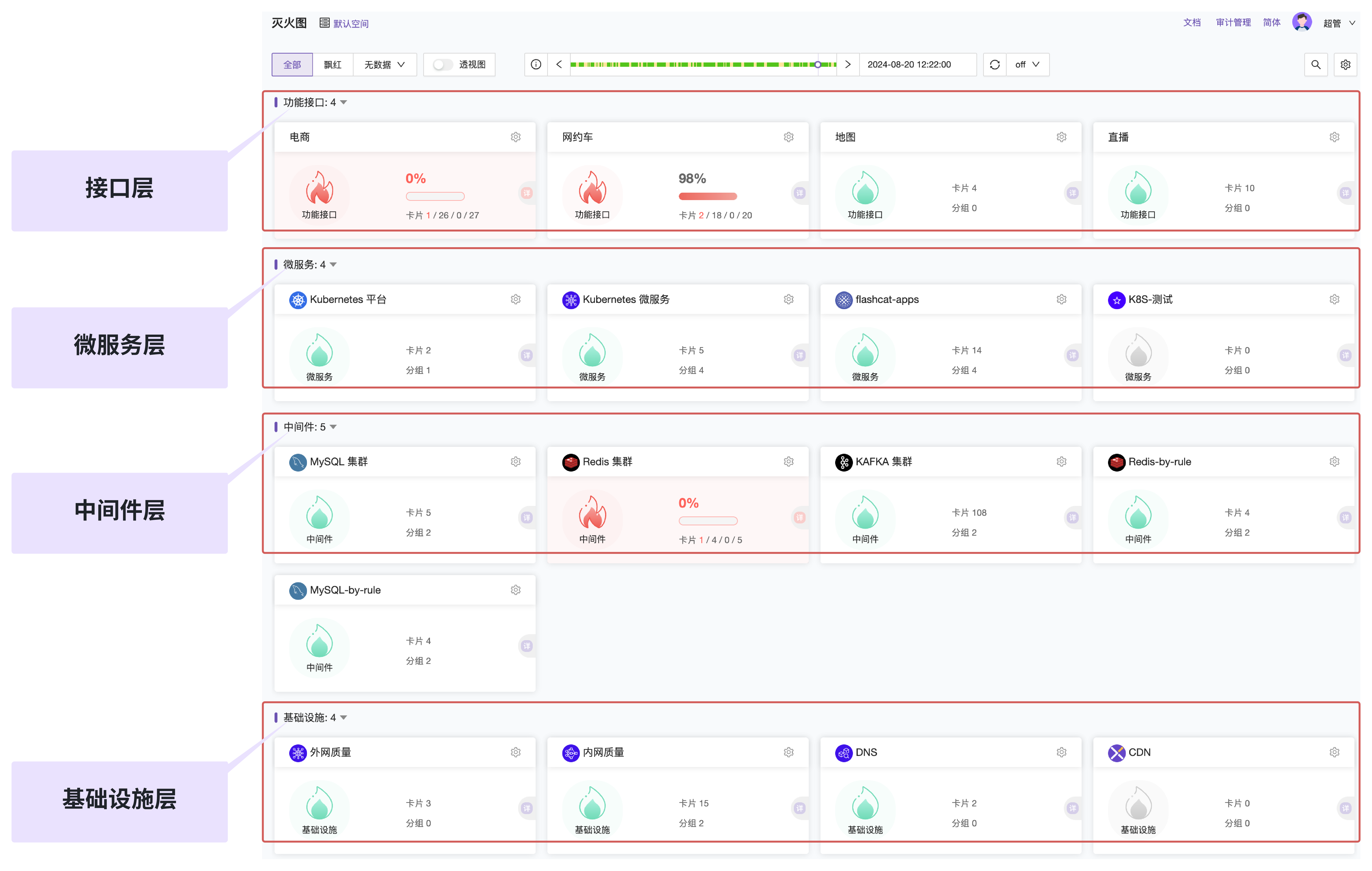
我们在调研国内的 SLO 产品方案的时候,关注到了快猫星云的 Flashcat 平台,其中有个关于 SLO 的功能模块“灭火图”,把 SLO 的抽象、创建、告警、管理、运营等全流程都覆盖了。且灭火图可以直接对接我们企业内部已有的各种监控数据源,从这些指标、日志、链路数据源,根据规则,自动化的创建和管理所需要的 SLO。
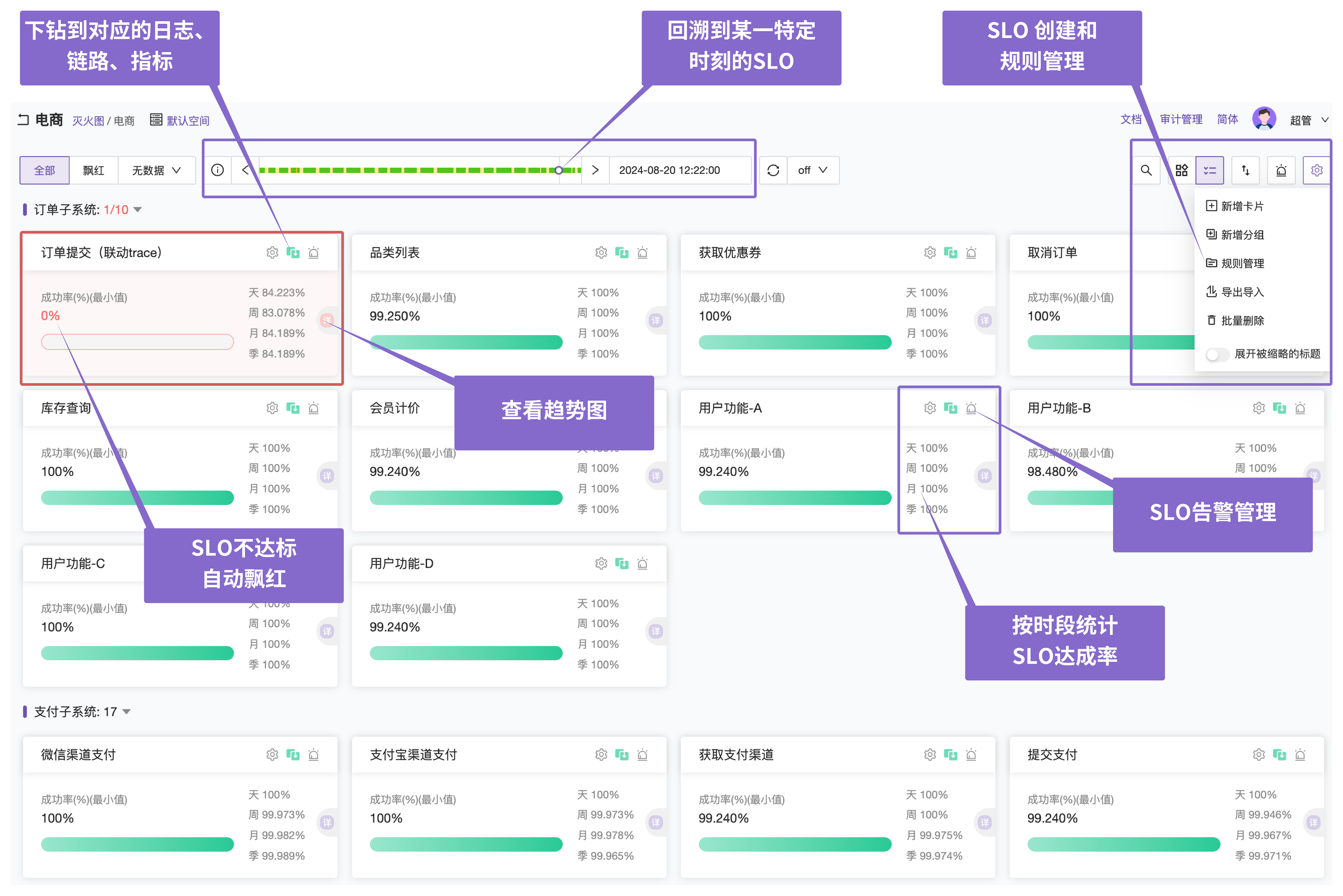
在 Flashcat 灭火图中:
- 每个 SLO,都被抽象为一个卡片,并可视化呈现和管理;
- 用户可以通过规则,来自动化的创建和维护 SLO,比如创建一个“K8s deployment”规则,当发现 depoyloyment 有创建的时候,就自动的生成对应的 SLO 来度量和追踪该 deployment;当发现 deployment 销毁的时候,就同步的删除对应的 SLO;
- 每个 SLO,可以配置灵活的告警策略,如固定阈值、动态基线、组合阈值,当 SLO 不达标时,卡片会飘红,且发送相应的告警;
- 支持回溯到过去 24 小时的每一分钟,查看那个特定分钟的 SLO,这对于日常巡检很有用,能帮助我们及时发现潜在的隐患和风险;
- 支持以 SLO 为入口,层层下钻,可以下钻到日志、链路、指标等。这种以 SLO 为中心,把可观测性各个维度的数据打通串联的能力,大大提升了问题排查的速度和准确性;
利用灭火图,不仅仅可以追踪和度量“服务”的健康度,也可以度量基础设施和各种中间件。
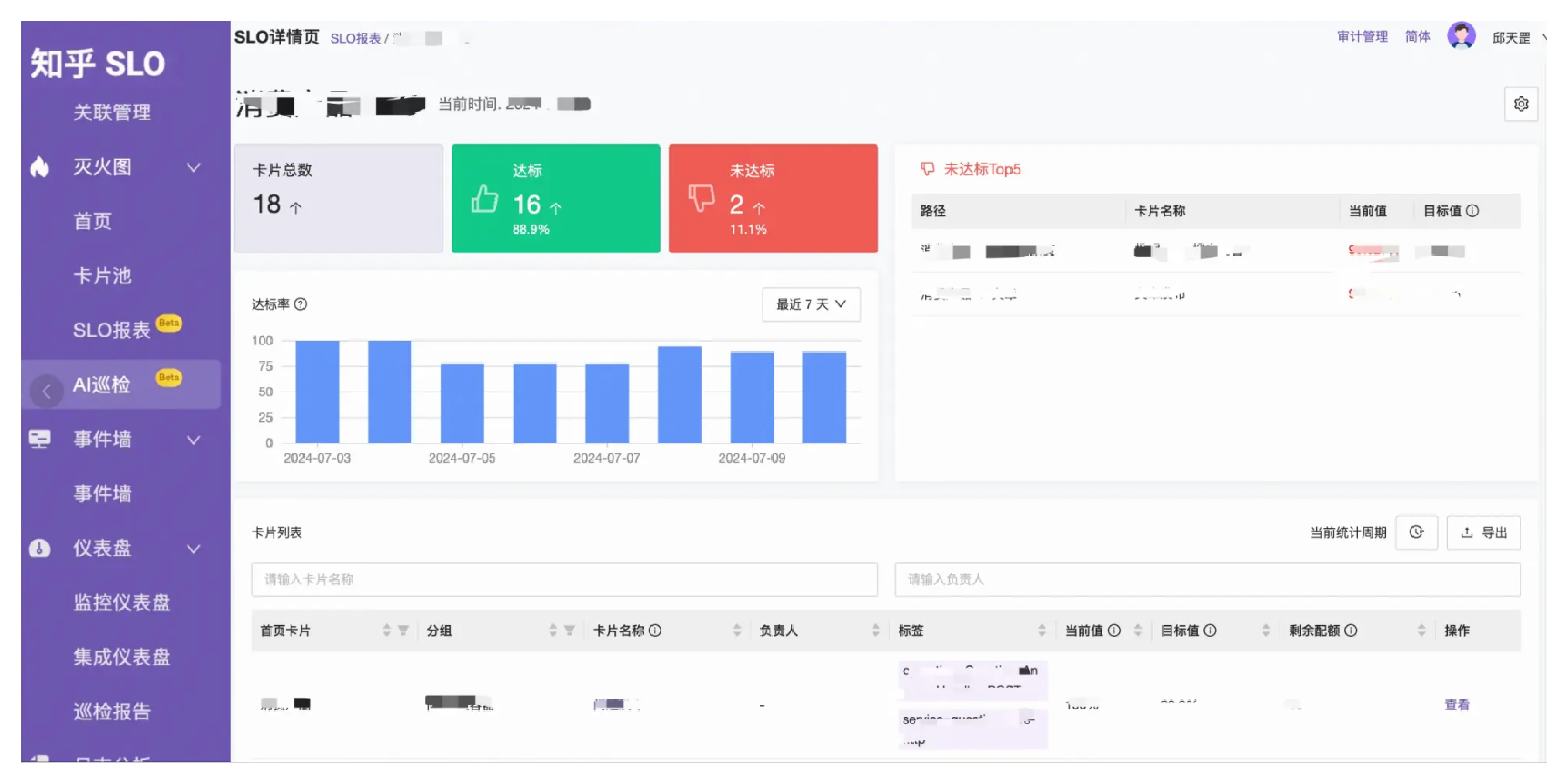
最后,我们利用灭火图,将细粒度的 SLO 按照产品线维度、和时间维度进行汇总,生成 SLO 报表。通过报表,可以从宏观层面看清楚服务可用性的变化情况,有针对性的、持续的改进,不断的提升系统稳定性,为用户提供高质量的服务。