
高济健康:基于Flashcat增强IT服务故障管理能力实践
我们公司是一家专注大健康领域的医药健康产业集团。在国内有覆盖广泛的连锁药店,同时拥有包括在线医疗、药品配送等医疗相关业务。在中心端我们的IT服务保障着全国药店和在线业务的高效运营。
在引入快猫的Flashcat监控平台之前,我们的IT服务监控基础设施包括Prometheus、Zabbix、Grafana、AlertManager、Zipkin、ELK等。在数据建设上主要向云原生方向看齐,并遵循云原生数据标准的最佳实践,有了良好的监控基础。
但如何更好的发挥这些监控系统和数据的价值,进一步提升IT服务端的稳定性保障能力,是我们主要思考的下一步。
通过夜莺监控社区我们和快猫团队建立了合作。结合我们的规划一起建设了面向IT服务稳定性保障场景,特别是故障处理过程的监控平台Flashcat。并基于Flashcat平台实践了一个行之有效的服务稳定性保障流程。本文将具体介绍这个流程建设的实践。
先介绍一下北京快猫星云科技有限公司基于夜莺监控实现的产品Flashcat。Flashcat是结合大型在线服务稳定性保障经验和方法实现的专业产品,聚焦服务稳定性保障场景,特别是故障处理过程,解决数字化服务故障处理中信息过载、故障发现慢、故障定位难的问题。内部包括北极星、灭火图、事件墙、特征分析等面向故障处理场景的子系统。
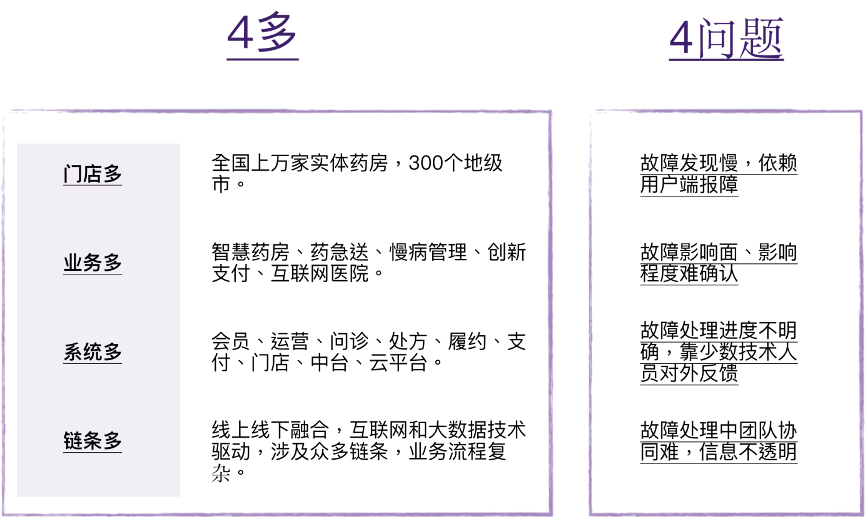
一、故障管理流程中存在的问题
为了方便管理,我们内部把故障分为两类:
- 一类是一般的问题,影响个别或局部,紧急程度一般,也就是我们的线上问题管理流程;
- 一类是重大的故障,影响主流程,比较紧急的,也就是我们的”故障管理流程”;
这里我们主要分享的是故障管理流程。
故障管理流程主要的问题包括:
1.主要依赖用户报故障
缺乏业务监控,日常报警无法区分真假故障,导致对重大故障的响应和处理有延迟。同时由于缺乏业务监控的输入,开发人员都是基于个人经验进行告警优先级的分类,虽然梳理过很多次,技术lead收到的告警仍然很多,每天少的也有十几封邮件,多的上百封。经常出现“狼来了”的情况,久而久之,大家对线上问题的处理也就疲惫了,基本都是依赖用户报障,然后去翻邮件,技术团队基本处于每天都在救火的被动状态中。
2.缺乏基于业务视角的全链路监控,故障定位耗时较长
由于都是以BU为单位,各自为战,导致跨BU的故障响应和处理就特别耗时。而现在都是微服务的架构,强调复用性,导致依赖关系很多。
我记得有一次A业务的服务发版,开发人员只回归测试了A业务,但不知道B业务也依赖这个服务,因此未对B业务进行回归验证。结果B业务当时正好有一个项目合作方的验收,进入到该功能页面时,直接报500的错误,排查了很长时间才发现是A业务的发版导致的。这个问题差点导致丢失该项目的合作机会。因此缺乏全局的依赖管理和核心监控、事件监控,要维护微服务的稳定性会很有挑战。
3.缺乏对重要故障场景的应急预案的梳理和演练
每次出现重大的故障,大家都乱成一团。经常出现技术lead重启各自服务,运维重启全部服务,每次重启全部服务特别耗时,而且还会有服务漏掉重启的情况,导致二次故障。
二、针对问题制定解决方案
针对上述问题,我们基于故障管理的全生命周期流程,进行了整体解决方案的制定,目标就是缩短故障的影响时间。
从业界稳定性通用的衡量标准看,有两个非常关键的指标:
- MTBF,Mean Time Between Failure,平均故障间隔时间;
- MTTR,Mean Time To Repair, 故障平均修复时间;
其中MTTR可以按照故障发现、故障定位、故障恢复三个大的节点,进一步拆分出MTTI、MTTK、MTTF三个主要子时间段。
MTTI (Mean Time To Identify,平均故障发现时间) 也就是故障从实际发生,到我们真正开始响应的时间。这个过程可能是用户或者客服反馈、舆情监控或者是监控告警等渠道触发的。
MTTK (Mean Time To Know,平均故障认知时间)可以理解为我们常说的平均故障定位时间。这个定位指的是root cause,也就是根因被定位出来为止。
MTTF (Mean Time To Fix,平均故障解决时间) 也就是从我们知道了根因在哪里,到我们采取措施恢复业务为止。这里采取的手段就很多了,比如限流、降级、熔断、重启等。
最终我们围绕这几个关键指标和故障管理的主流程,自顶向下制定了故障管理的体系规划。
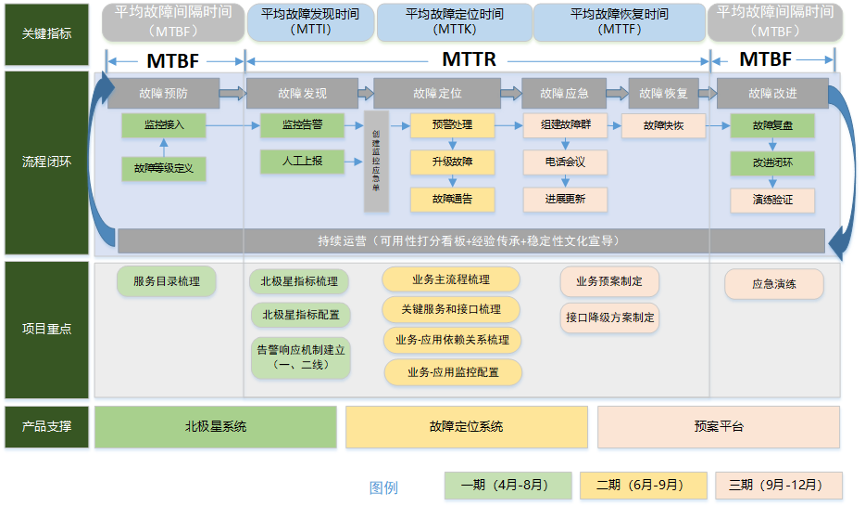
我们的目标就是缩短平均故障发现时间(MTTI)、平均故障定位时间(MTTK)、平均故障恢复时间(MTTF),从而缩短整体故障中断时间(MTTR),提升故障间隔时间(MTBF)。
规划路线图:
-
一期:建立业务关键指标监控,目标:缩短故障发现时间(MTTI)。
- 通过Flashcat北极星系统的支持,梳理服务目录,识别核心的A级服务,针对每个服务梳理出关键的北极星指标;
- 同时通过事后的故障复盘,进一步完善北极星指标;
-
二期:与北极星指标关联的技术全链路的监控补充,目标:缩短故障定位时间(MTTK)。
- 结合核心业务主流程的梳理,进行关键服务和关键接口的梳理和配置,在北极星发出告警的同时,检测其依赖服务和接口的状态(Flashcat灭火图系统)正常与否,缩短故障定位时间;
- 考虑后续这些链路关系的时效性和准确性,devops团队开发了流量接口的主动发现功能,帮助相关技术团队及时标记接口与服务目录、北极星指标的关联关系;
-
三期:核心故障场景梳理、预案制定、故障演练,目标:缩短故障恢复时间(MTTF)。
- 结合一期、二期成果,进一步梳理核心故障场景,以及对应的预案操作,集成到统一的预案平台,支持“一键恢复”;
- 建设演练,形成机制,纳入日常运营、形成体系闭环,持续改进;
三、落地效果
通过和快猫团队合作,建设并落地Flashcat平台,我们已达成了重要的里程碑。
一、二期工作落地后,目前公司A级产品线北极星指标监控实现了全覆盖,P3级及以上故障北极星监控发现率为100%,MTTI控制在5分钟以内。真正做到了先于用户发现问题,让故障处理变被动为主动。
解决了故障及时发现的问题后,故障定位能力建设也已取得重要进展。我们和业务一起梳理了公司A级产品线核心主流程依赖的接口和模块,并将梳理结果落地到Flashcat灭火图系统。并建立了北极星和灭火图的关联,完成了服务全景图的建设,加速了故障处理和团队间的协同效率。
下一步,我们将继续推进公司A级产品线核心故障场景和预案全部识别,配置至预案平台,并打通Flashcat平台实现监控和预案的联动,进步一加速故障处理的效率。
四、结语
与快猫团队共建的Flashcat平台,特别是北极星、灭火图等系统,对于实施我们整个稳定性保障能力建设的计划起到了重要的作用。特别感谢快猫团队的及时响应和支持,确保我们的项目顺利交付,达到预期效果。
本文作者是资深的医药集团科技部基础运营平台ITIL团队负责人,负责推进IT服务流程和制度建设,提升IT服务的效率和稳定性保障能力。出于用户企业的保密要求,文中隐去了作者及公司的名称。



