
第二届CCF·夜莺开发者创新论坛成功举办,免费领取 PPT

第二届CCF·夜莺开发者创新论坛于 2024.7.26 在京召开,来自字节跳动、滴滴、小米、作业帮、知乎、Zenlayer、国泰君安期货、大搜车、快猫等众多企业的讲师分享了各自对可观测性的理解和实践经验。即便是会议结束时,上座率依然超过 90%,可见大家对可观测性的重视程度。
本次会议的议题如下:

我用文字记录了一下会议的精彩内容,分享给大家。(文末附 PPT 领取方式)
首先是 CCF 计算机学会常务理事章文嵩博士代表学会致辞,并介绍了学会筹备的计算机博物馆。我个人还在抠一个个的 IT 细节呢,学会大佬们在王院士带领下,做的是计算机的全民普及教育和推广,致敬!

之后是秦晓辉代表夜莺开源社区,发布夜莺 v7 正式版,介绍了 v7 更新的功能以及后续的规划。夜莺项目从 2020 年开源,到现在已经 4 年多了,累计收获 9000 多个 github stars,1000 多 forks,100 多 contributors 参与其中,在国内可观测性/监控这个小众圈子里,算是一个非常活跃的开源社区啦。
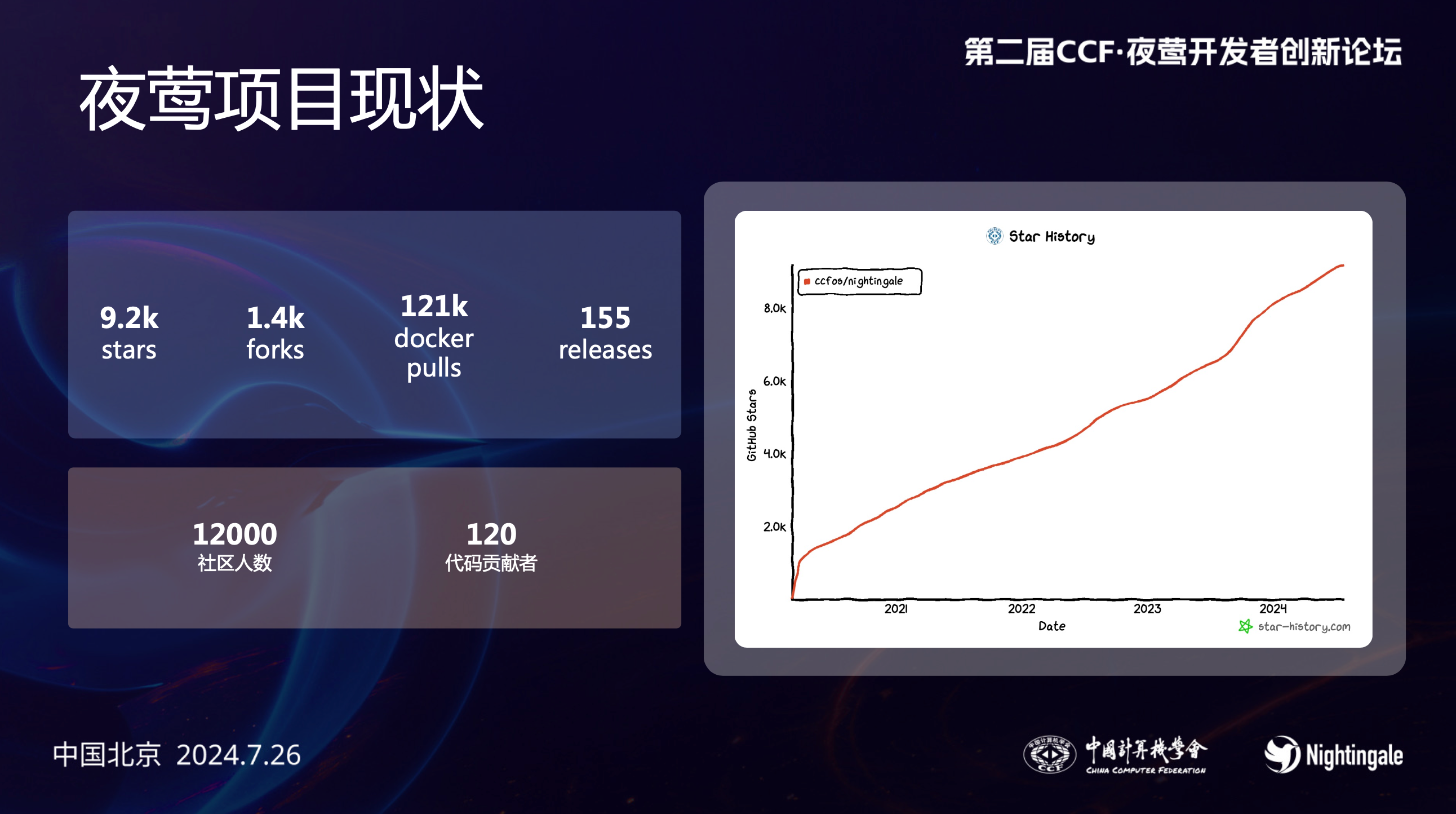
你如果还没听过夜莺项目,可以收藏 star 一下其项目地址:
夜莺 v7 是一个 LTS 版本,社区会持续支持 2 年,另外,v5 版本已经达到了两年支持时限,建议大家尽快升级到 v7。
之后是来自字节跳动的舒博,分享了字节在埋点标准化方面的一些实践经验。字节非常非常大,标准化工作推进难度巨大,不过一旦全部服务的可观测性埋点标准化了,带来的收益也是巨大的。
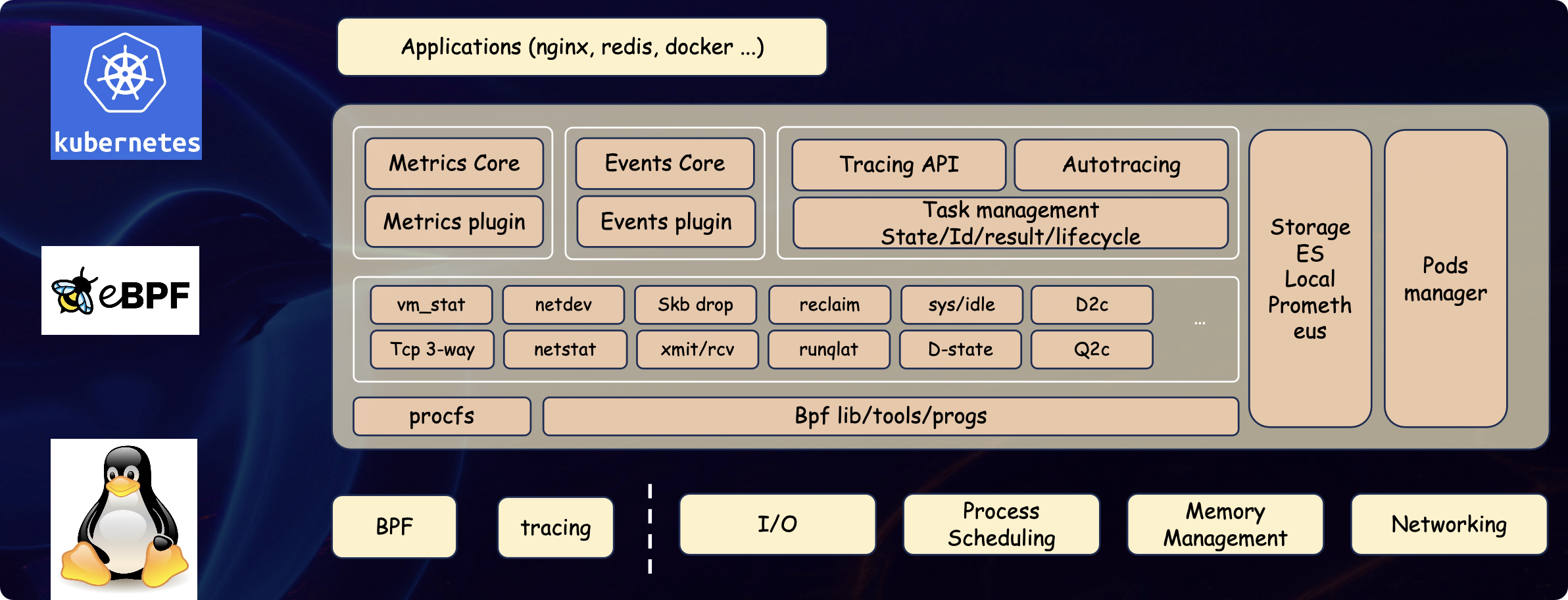
之后是来自滴滴的张同浩,为大家分享了滴滴在内核层面使用 eBPF 做可观测性的实践经验。eBPF 是 Linux 内核的一个功能,可以在不修改内核代码的情况下,动态加载一些程序,用于监控、分析、过滤等。
上午场最后两个 topic,都是跟 OnCall 话题相关,首先是来自国泰君安期货的宋庆羽老师,分享了期货行业 OnCall 玩法。
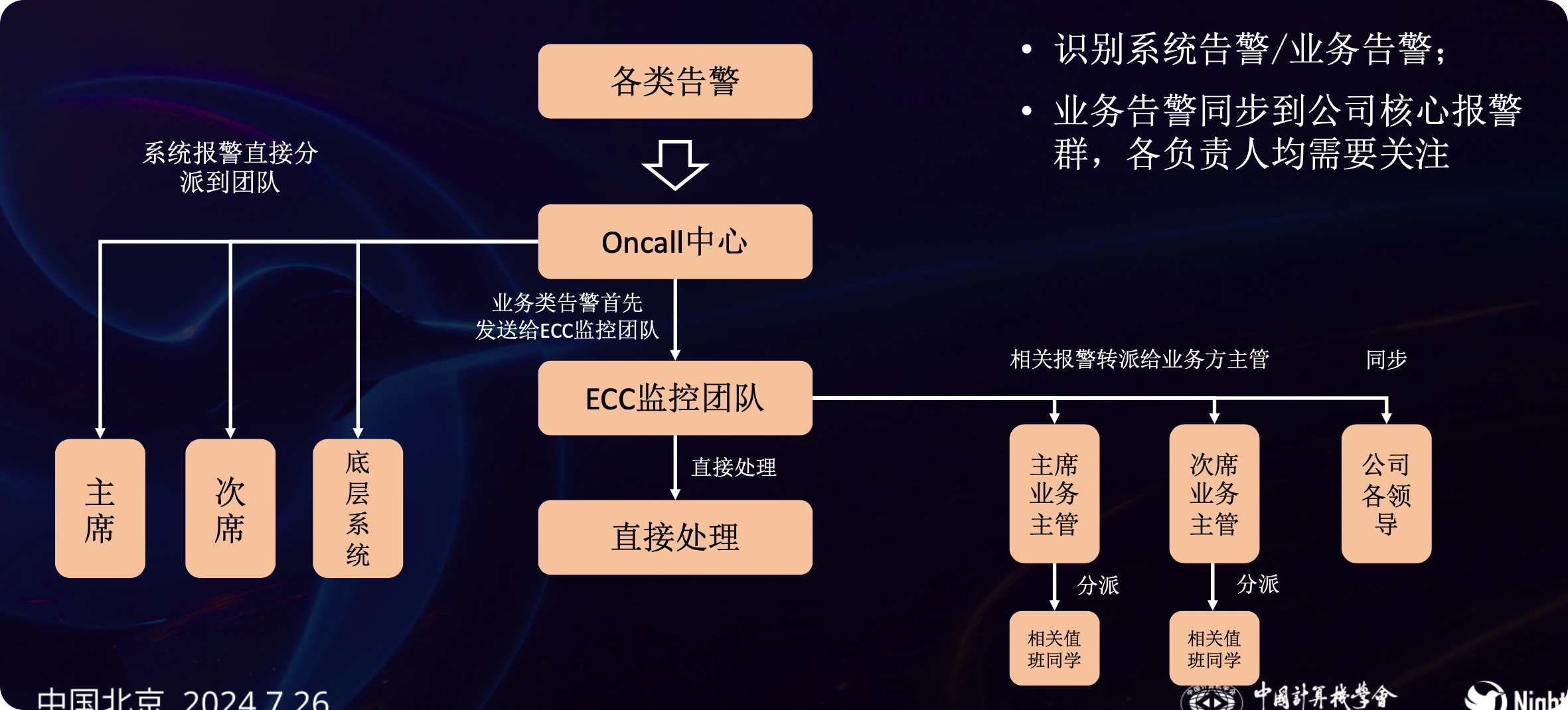
双羽给大家分享的是统一 OnCall 平台的建设逻辑,从 Google SRE OnCall 方法讲起。

Google 有个 OnCall 工具叫 Outalator,不过是对内的,如果咱们想拥有 Outalator 那样的能力,可以考虑使用 Flashduty,Flashduty 可以对接 Zabbix、夜莺、Prometheus、各类云监控、蓝鲸、Graylog 等众多监控系统,把告警事件收集到一个中心,统一做告警收敛降噪、排班认领升级等事情。
然后就是午餐环节了,朗丽兹的午餐自助真挺不错的,可惜光顾着吃了,忘了给大家拍照,求绕过 🙏
下午开场,是小米工程师马千里为大家带来的小米多机房可观测性实践经验的分享。小米用的很杂,除了最开始的 Open-Falcon,还有 Prometheus、ElasticSearch、Loki、Sentry 等等。
小米后来把 Open-Falcon 基于 RRD 的那套存储换成了 VictoriaMetrics,还分享了使用 VictoriaMetrics 遇到的一些坑。
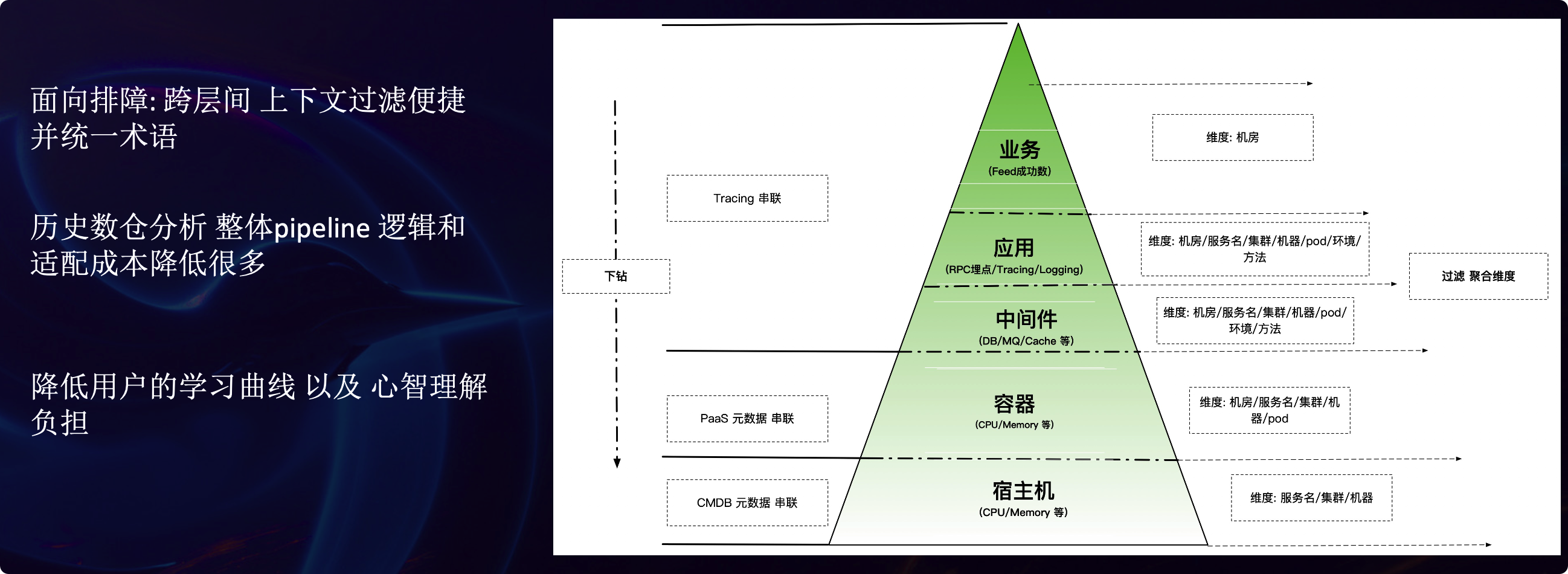
之后是来自知乎的邱天罡,分享了知乎的可观测性实践。知乎的体量挺大的,每秒上报的数据点有 3000 万,监控系统的规模如下:

知乎分享的北斗可观测性系统让我印象深刻:
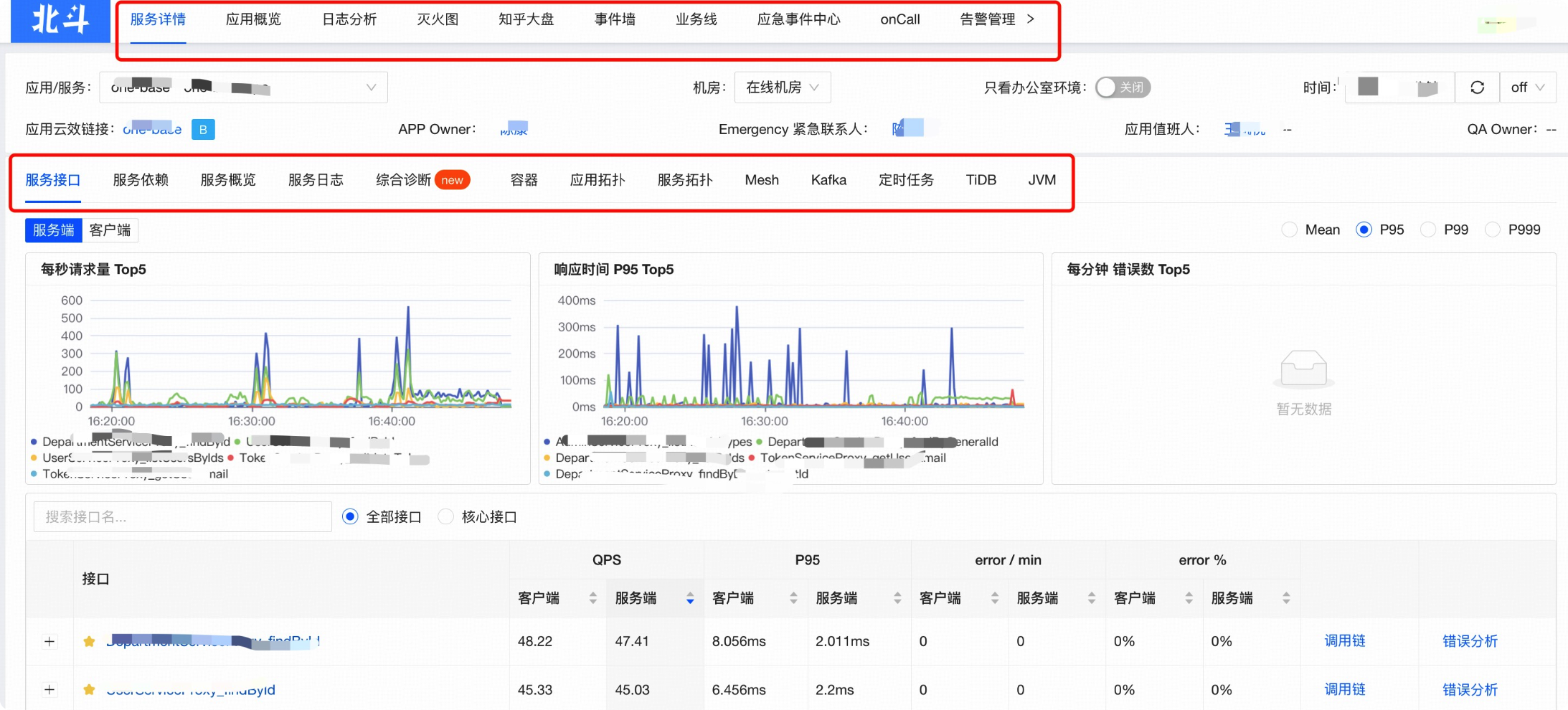
他们的数据也挺规范的,标签也很规范,这样就不用给每个服务单独创建仪表盘了,直接把相关类别的数据根据服务名称渲染出来即可。
接下来是来自大搜车的杨华分享的网络设备监控中的陷阱及解法,杨华有个公众号叫“网络小斐”,很多关注网络设备监控的朋友可能都关注过他。一听到网络设备、SNMP、OID 这样的名词就脑壳疼,不过杨华分享的内容还是挺通俗易懂的。
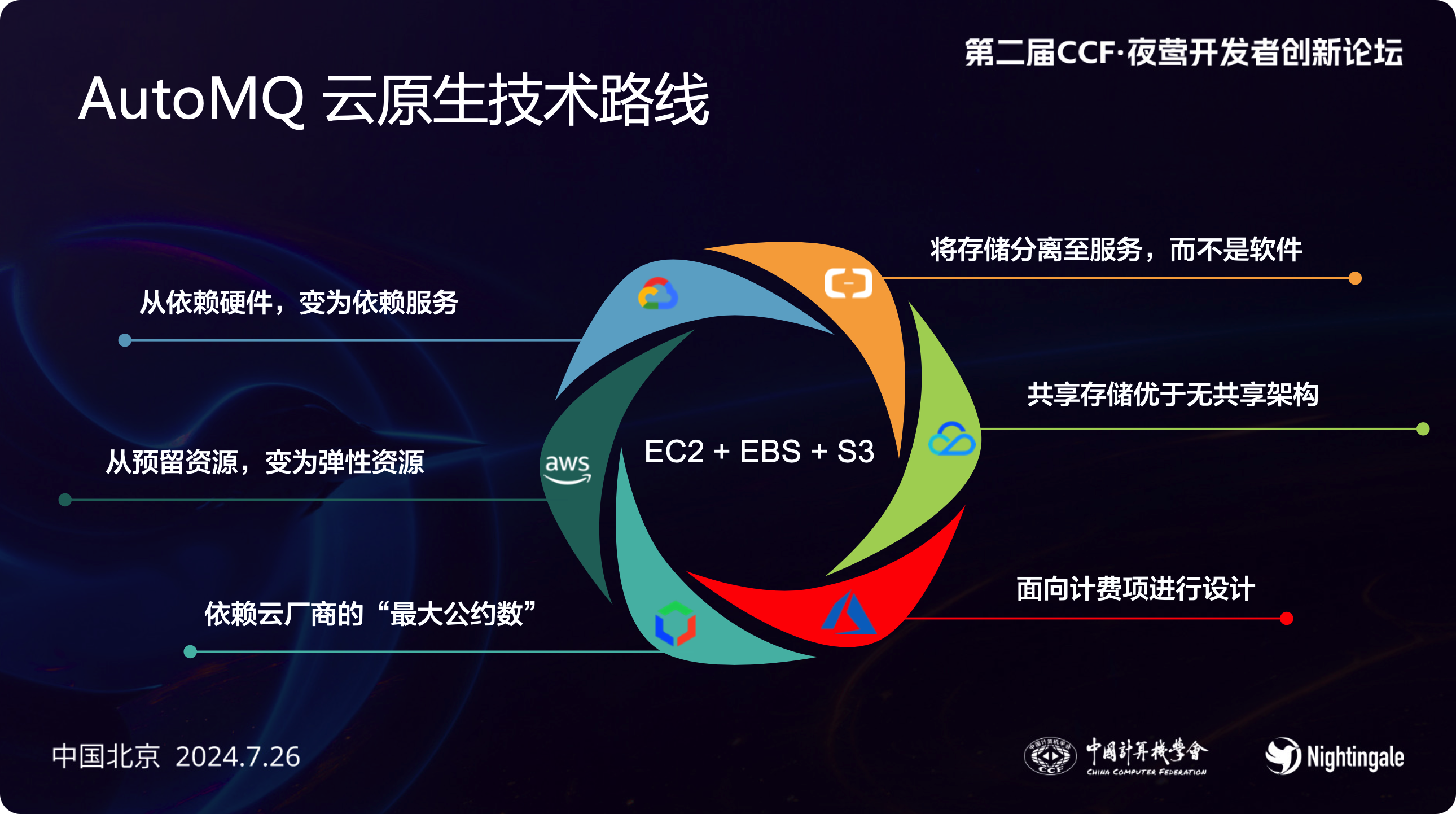
可观测性数据,尤其是日志数据,量很大,业内通常使用 Kafka 做数据搬运,有些体量大的公司,Kafka 集群的机器就有几百台,成本高昂。AutoMQ 的朋友分享了他们解决 Kafka 成本的方案。核心就是 WAL 数据写在块存储,持久化数据写入对象存储。
然后是作业帮运维总监聂安给大家带来的分享:观测数据治理。从观测数据的全生命周期来看,各个环节应该如何治理,比如:
- 数据生产阶段:尽量利旧,在服务治理框架层面统一埋点
- 数据收集阶段:引入 pipeline,比如 telegraf,统一规范化指标命名
- 数据处理阶段:标签 enrichment,流式聚合,场景化聚合
- 存储使用阶段:建议参考数据分析领域的实践思路

接下来是 Zenlayer 的高级网络技术专家钱誉老师,带来的 AI agent 在运维体系中的探索与实践,感觉好高级,小编都听不懂。

最后是快猫的联创华明老师,分享最近这三年做可观测性产品的一点心得,内容很干,我把大纲截个图给各位看官瞧瞧。

好了,今天的分享就到这里,如果你想领取论坛的 PPT,可以联系我同事:



