
使用自定义 Fluent Bit 配置解析多行日志
应用程序通常逐行输出日志,但有时某些日志可能会跨越多行以使其更易于阅读。虽然这些多行日志在连续(和单独)读取时可以提高可读性,但如果和其他日志混合在一起查询的时候,就不方便看了。这就成了一个问题:难以读取的日志,阅读起来很浪费时间。
一种解决方案是将一条日志消息中的所有行合并到一条日志记录中。这样做可以清楚地分隔每个多行日志,这反过来又会使日志更易于理解并节省时间。将多行日志消息合并到单个日志条目中,通常是通过配置一些正则解析器来实现。在这篇文章中,我将引导您完成此过程。您将学习如何使用自定义 Fluent Bit 配置启用多行日志消息。
如果您不熟悉,Fluent Bit 是一个日志记录和指标处理器和转发器。New Relic agent 与 Fluent Bit 插件捆绑在一起,因此您可以通过 YAML 文件的简单配置在本地转发日志。
如果您已经在使用 Fluent Bit,您还可以借助我们的 Fluent Bit 输出插件将 Kubernetes 日志转发到 New Relic。或者,您可以将其用作独立的 Docker 镜像,我们将其称为 Kubernetes 插件。
让我们从更好地理解问题开始。
挑战:当多行日志变得难以阅读时
以此堆栈跟踪为例。它是一个由多行组成的单个日志。第一行以时间戳开头,每行新行以单词 “at” 开头。
single line...
Dec 14 06:41:08 Exception in thread "main" java.lang.RuntimeException: Something has gone wrong, aborting!
at com.myproject.module.MyProject.badMethod(MyProject.java:22)
at com.myproject.module.MyProject.oneMoreMethod(MyProject.java:18)
at com.myproject.module.MyProject.anotherMethod(MyProject.java:14)
at com.myproject.module.MyProject.someMethod(MyProject.java:10)
at com.myproject.module.MyProject.main(MyProject.java:6)
another line...
现在,检查它在未应用任何自定义配置的情况下在 New Relic 中的显示方式。请注意下图中堆栈跟踪的每一行如何显示为单独的日志条目。
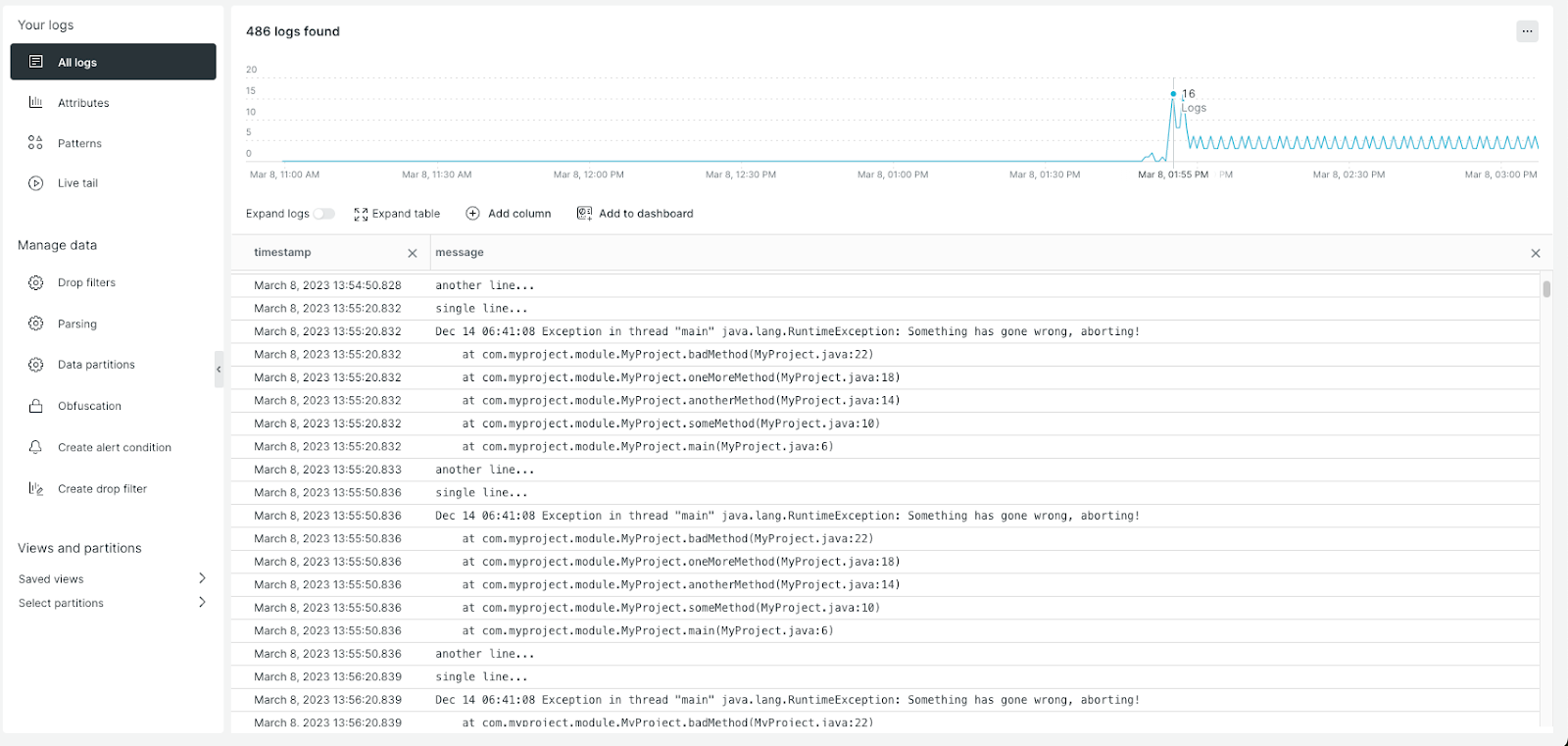
嗯,这正是问题所在:当单个多行日志显示为多个单独的日志条目时,它会使多行日志更难读取并与其他日志区分开来。
好,让我们一起解决这个问题。要在 New Relic 中处理多行日志,让我们使用前面示例中的相同逻辑创建自定义 Fluent Bit 多行解析器配置。
Fluent Bit 如何处理和解析日志
使用 Fluent Bit,您可以从各种来源收集遥测数据,应用过滤器来增强它,并将其传输到任何目标位置,例如 New Relic。Fluent Bit 提取的所有日志数据都会自动标记,因此开发团队可以轻松应用筛选、路由、解析、修改和输出协议。在所有日志处理器和转发器中,Fluent Bit 非常高效,并且以开源和供应商中立而闻名。
要合并和配置多行日志,您需要设置 Fluent Bit 解析器。Fluent Bit 的 1.8 或更高版本提供了两种方法来执行此操作:使用内置多行解析器和使用可配置的多行解析器。这两个多行解析引擎一起称为 Multiline Core,这是一个统一的功能,用于处理多行日志的所有用户极端情况。
在这篇博文中,您将使用 Fluent Bit 1.8 或更高版本的可配置多行解析器。然后,您将能够将解析器应用于支持 New Relic 的 Kubernetes 平台、New Relic 基础设施代理,或者您可以将 Fluent Bit 用作带有 New Relic Kubernetes 插件的独立 Docker 映像。
现在花点时间确定您正在使用的工具版本。New Relic 的每个版本都使用特定的 Fluent Bit 版本,不同版本的 Fluent Bit 具有不同的功能:
- 在 Fluent Bit 版本 1.7 或更低版本中,您将使用旧的多行配置参数实现多行日志配置。
- 在 Fluent Bit 版本 1.8 或更高版本中,您需要禁用任何旧的多行配置,而是设置 Multiline core 解析器。
- 任何高于 New Relic Fluent Bit 输出插件 v1.12.2、Helm 图表 v1.10.9 或基础设施代理 v1.20.3 的版本都可以使用 Fluent Bit v1.8 或更高版本中提供的 Multiline core 功能。
要确认您使用的是哪个版本的 Fluent Bit,请查看 New Relic 发行说明。
使用 Fluent Bit 创建自定义多行解析器配置
首先,请务必注意 Fluent Bit 配置具有严格的缩进要求,因此从此博客文章中复制和粘贴可能会导致语法问题。 查看 Fluent Bit 文档以了解缩进要求。
多行解析器是使用 [MULTILINE_PARSER] 节定义在解析器的配置文件中定义的,该定义必须具有每个类型的唯一名称、类型和其他关联属性。
要配置多行解析器,您必须提供正则表达式 (regex) 来标识开始行和继续行。
# rules | state name | regex pattern | next state
# --------|----------------|---------------------------------------------
rule "start_state" "/([a-zA-Z]+ \d+ \d+\:\d+\:\d+)(.*)/" "cont"
rule "cont" "/^\s+at.*/" "cont"
第一条规则始终称为“start_state”,它是捕获多行消息开头的正则表达式。在前面的 New Relic 日志示例中,您看到多行日志以时间戳开头,一直持续到行尾。
您可以设置下一个状态 “cont” 以指定可能的连续行长什么样。您可以指定这些自定义状态名称并将它们链接在一起。在本博客文章的示例中,连续行以 “at” 开头,我们配置了一个简单正则来描述之。
对于此示例,您只需要一个延续状态,但您可以为更复杂的情况配置多个延续状态定义。
确保 continuation 状态与所有可能的 continuation 行匹配。否则,当遇到意外行时,您的多行捕获可能会被截断。
要简化正则表达式的配置,您可以使用 Rubular 网站。此 Rubular 页面显示前面描述的正则表达式,以及与模式匹配的日志行。
使用自定义 Fluent Bit 多行解析器配置
现在让我们测试一下。我的示例使用 Azure Kubernetes 服务 (AKS),我在其中使用 Helm 部署了 New Relic Kubernetes 集成。但是,您可以将自定义 Fluent Bit 配置应用于任何受支持的 Kubernetes 平台,也可以将其与 New Relic 基础设施代理一起使用。您还可以将 Fluent Bit 用作独立的 Docker 映像,我们将其称为 Kubernetes 插件。
要在 Helm 中配置 Fluent Bit,我们需要更改 fluent-bit-config configmap 以告知它应用解析。
第一步是为输入消息定义正确的日志解析器。由于我在此示例中使用的是 AKS 群集,因此我需要将 CRI 定义为日志解析器。这样做可确保在将每条日志消息移交给任何筛选条件之前,首先使用 CRI 解析器对其进行解析。
[INPUT]
Name tail
Tag kube.*
Path ${PATH}
Parser ${LOG_PARSER}
DB /var/log/flb_kube.db
Mem_Buf_Limit 7MB
Skip_Long_Lines On
Parser映射到 New Relic 日志记录 daemonset 中定义的 LOG_PARSER 环境变量的值。确保在此测试中将 Parser 设置为“CRI”,因为 AKS 使用 containerd 作为容器运行时,其日志格式为 CRI-Log。
接下来,在 filter-kubernetes.conf 中添加另一个 [FILTER] 部分,就像下一个代码片段一样。此过滤器可确保输入日志解析器处理的每个日志条目随后使用我们的多行解析器进行解析。
[FILTER]
Name multiline
Match *
multiline.parser multiline-regex
接下来,在 parsers.conf 中,使用您之前创建的自定义 Fluent Bit 配置配置多行解析器。请注意多行解析器是如何按名称 (“multiline-regex” 从下一个代码片段中的 [MULTILINE_PARSER] 块到上一个代码片段中的 [FILTER] 块匹配的。
[MULTILINE_PARSER]
name multiline-regex
type regex
flush_timeout 1000
# rules | state name | regex pattern | next state
# ------|---------------|----------------------------------|-----------
rule "start_state" "/(Dec \d+ \d+\:\d+\:\d+)(.*)/" "cont"
rule "cont" "/^\s+at.*/" "cont"
fluent-bit-config configmap 现在应该如下所示。
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config
namespace: newrelic
labels:
k8s-app: newrelic-logging
data:
# Configuration files: server, input, filters and output
# ======================================================
fluent-bit.conf: |
[SERVICE]
Flush 1
Log_Level ${LOG_LEVEL}
Daemon off
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
@INCLUDE input-kubernetes.conf
@INCLUDE output-newrelic.conf
@INCLUDE filter-kubernetes.conf
input-kubernetes.conf: |
[INPUT]
Name tail
Tag kube.*
Path ${PATH}
Parser ${LOG_PARSER}
DB /var/log/flb_kube.db
Mem_Buf_Limit 7MB
Skip_Long_Lines On
Refresh_Interval 10
filter-kubernetes.conf: |
[FILTER]
Name multiline
Match *
multiline.parser multiline-regex
[FILTER]
Name record_modifier
Match *
Record cluster_name ${CLUSTER_NAME}
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc.cluster.local:443
Merge_Log Off
output-newrelic.conf: |
[OUTPUT]
Name newrelic
Match *
licenseKey ${LICENSE_KEY}
endpoint ${ENDPOINT}
parsers.conf: |
# Relevant parsers retrieved from: https://github.com/fluent/fluent-bit/blob/master/conf/parsers.conf
[PARSER]
Name docker
Format json
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L
Time_Keep On
[PARSER]
Name cri
Format regex
Regex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) (?<message>.*)$
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L%z
[MULTILINE_PARSER]
name multiline-regex
key_content message
type regex
flush_timeout 1000
#
# Regex rules for multiline parsing
# ---------------------------------
#
# configuration hints:
#
# - first state always has the name: start_state
# - every field in the rule must be inside double quotes
#
# rules | state name | regex pattern | next state
# ------|---------------|--------------------------------|-----------
rule "start_state" "/(Dec \d+ \d+\:\d+\:\d+)(.*)/" "cont"
rule "cont" "/^\s+at.*/" "cont"
作为最后一步,您需要在更改配置后重新启动 New Relic 日志记录 pod。
确认自定义多行解析器正常工作
现在,在 New Relic 中,您可以看到日志消息不再被拆分为多行,并且完整的堆栈跟踪可以被视为单个日志行的一部分。
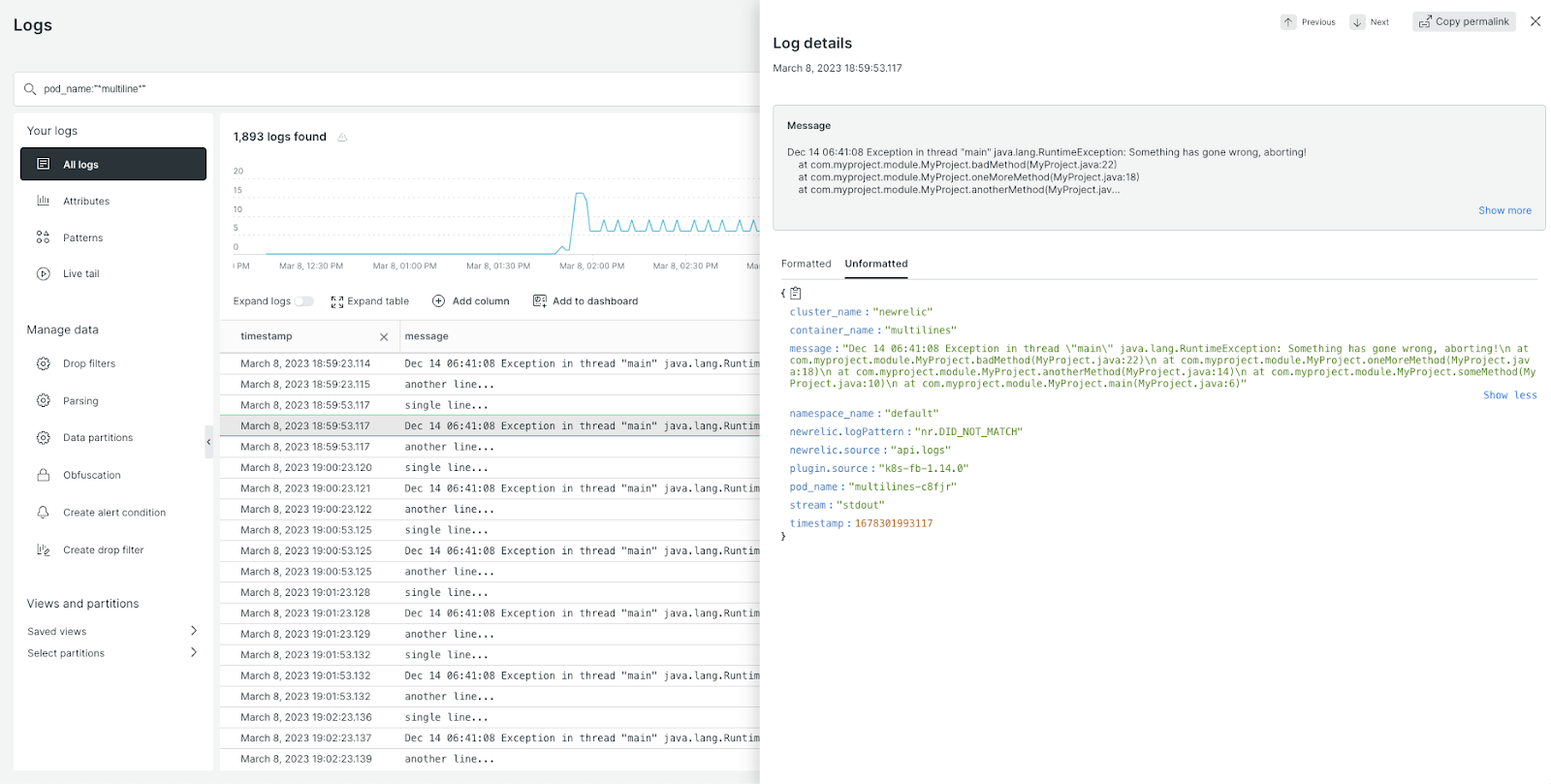
当您处理多行日志时,像这样看似很小的更改可能会产生很大影响,并最终使您的日志调试体验更加有效。值得庆幸的是,这个小小的改变实施起来很容易。
原文:https://newrelic.com/blog/how-to-relic/parsing-multiline-logs-with-fluent-bit



