
告警恢复通知里经常需要展示“当前值”。但在 Nightingale、Prometheus 这类直接用 PromQL 写告警条件的系统里,如果阈值写在 PromQL 中,恢复时很可能查不到数据:恢复意味着监控数据已经不满足阈值条件,不满足条件的时间序列不会被查询结果返回,自然也就拿不到当前值。
Prometheus 也有类似问题,可以通过 Go template 中的 query 函数绕一层查询,但这种方式不够直观,学习成本也偏高。本文以 Flashduty 的告警引擎为例,说明两种更容易理解的实现思路。
核心结论
- 如果希望告警触发和恢复时都能稳定拿到当前值,最直接的方式是:PromQL 只负责筛选原始数据,阈值放到告警引擎里判定。
- 如果必须把阈值写进 PromQL,可以在恢复时通过标签变量做二次查询,用关联查询补回当前值。
- 两种方式都不改变 PromQL 的基本语义,区别在于阈值判定发生在查询语句里,还是发生在告警引擎里。
- 关联查询不仅能取恢复值,也适合在 A 指标告警时展示 B 指标、日志详情等上下文。
背景:为什么恢复时拿不到当前值
在新版本 Nightingale 中,告警规则直接使用 PromQL 配置,阈值通常写在 PromQL 里。例如某个指标大于阈值才返回结果。告警触发时,查询结果里有数据;告警恢复时,指标已经不达阈值,查询结果为空。
这不是某一个监控产品的特殊限制,而是这类表达方式的自然结果:查询条件本身过滤掉了恢复后的数据点。
Flashduty 是一个告警事件中心,产品介绍地址:https://www.flashduty.com。它可以把 Nightingale、Zabbix、Prometheus、云监控等各类监控系统的告警汇聚到一个地方,做统一的告警收敛、聚合降噪、排班、认领、升级、派发和协作。Flashduty 也提供告警引擎能力,可以对接 VictoriaMetrics、M3DB、Prometheus、ClickHouse、MySQL、Oracle、Postgres 等数据源,直接查询数据源做告警判定。
下面用 Flashduty 的配置截图说明两种做法。
方案一:PromQL 只查原始值,阈值交给告警引擎
以 Memcached 的某个告警规则举例,查询条件里不写阈值,判定规则里写阈值,如下图所示:
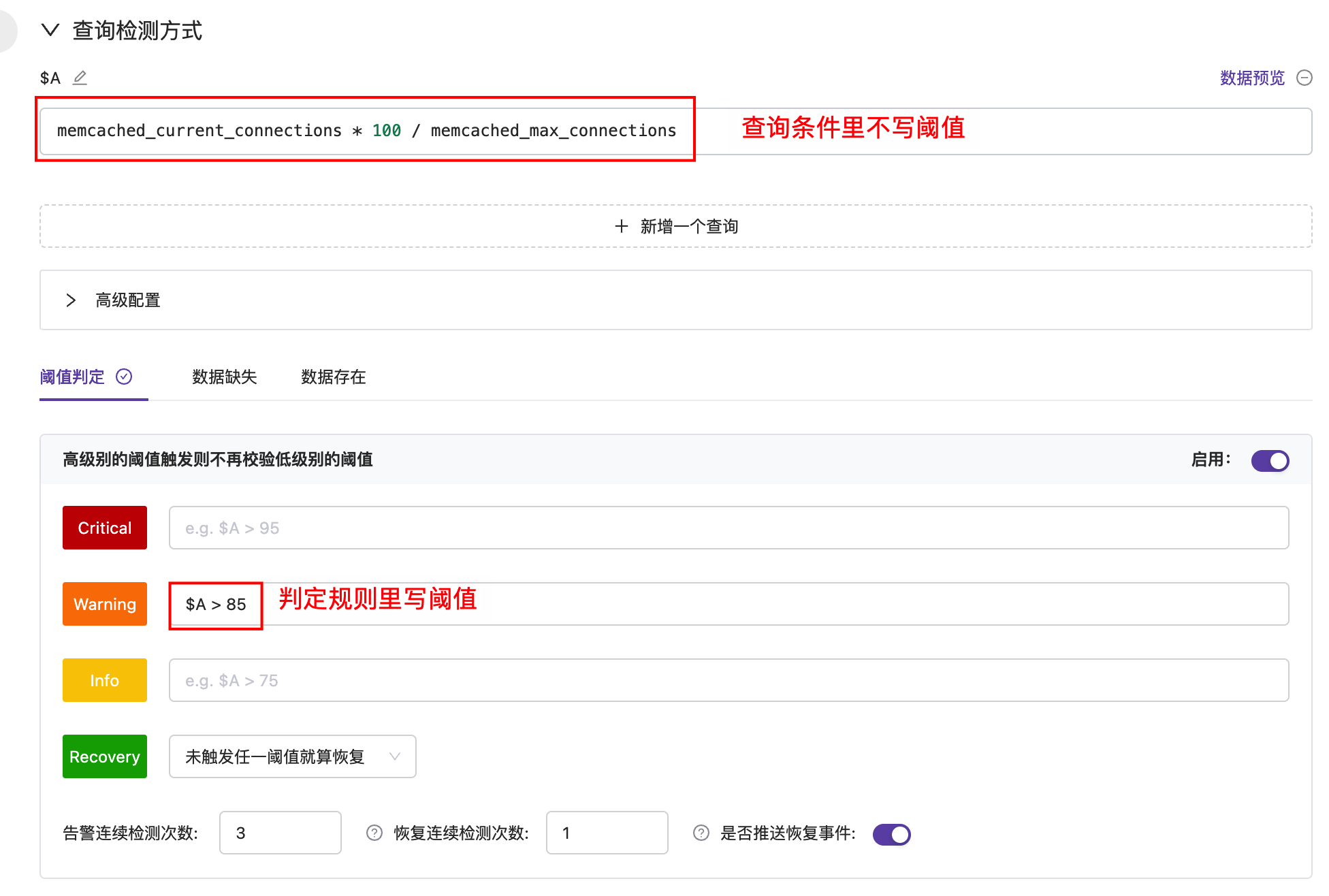
这种方式的逻辑是先查到当前值,再拿当前值做阈值判定。因此,不管处于告警状态还是恢复状态,告警引擎都能拿到当前值。
这类配置适合大部分常规告警,优点是直观、可解释、通知模板更容易写。需要注意的是,如果一个查询条件会匹配很多时间序列,告警引擎需要处理的数据量也会增大。这种情况下可以考虑方案二。
方案二:阈值写进 PromQL,恢复时用关联查询补值
在 Flashduty 中,方案二称为「数据存在」的告警方式,这种方式只要查到数据就告警。需要在查询条件的 promql 中写阈值,比如:
cpu_usage_active{ident=~"dev-n9e.*", cpu="cpu-total"} > 85
具体页面配置如下:
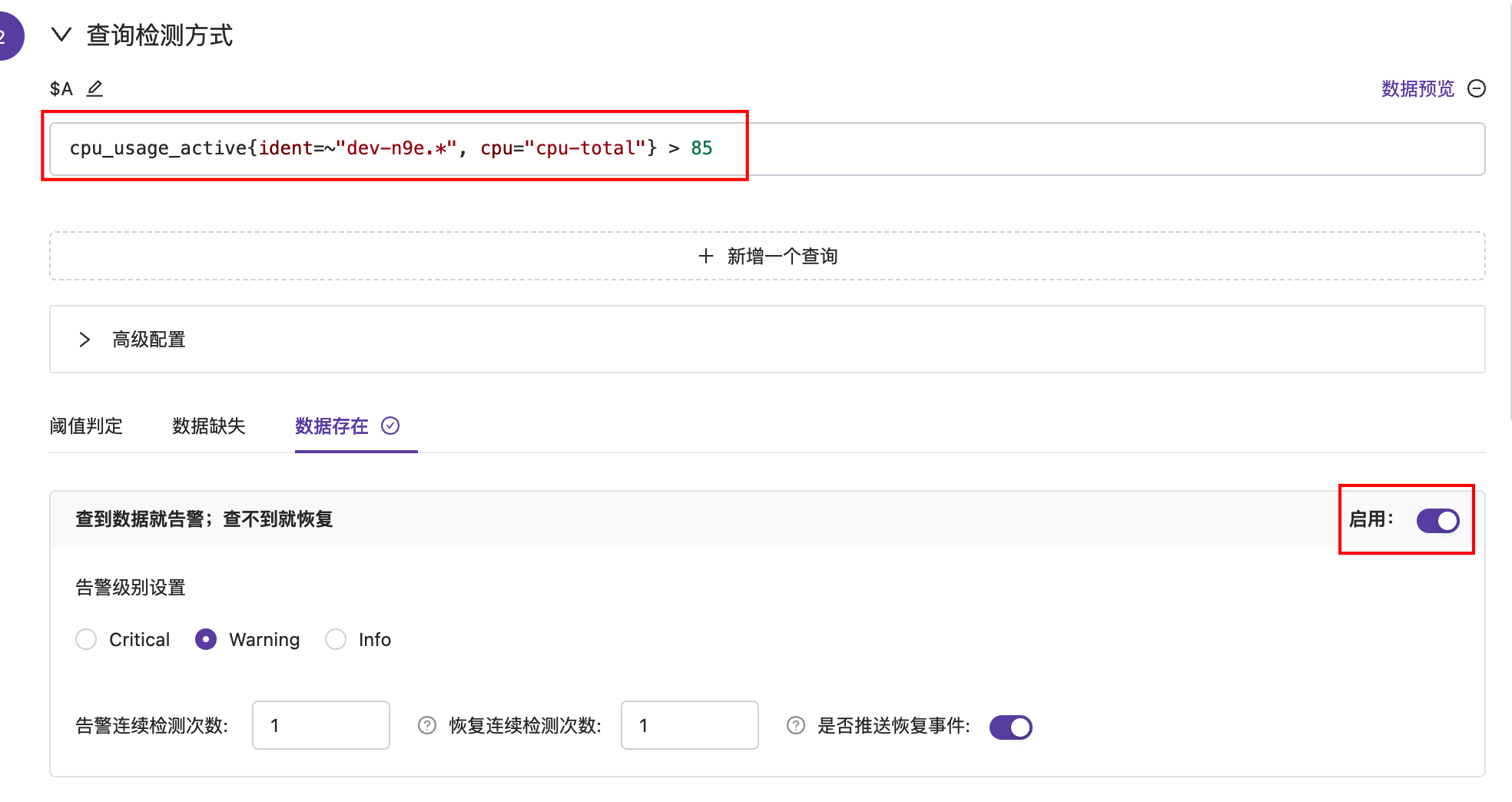
这种设置方式和 Nightingale、Prometheus 的常见写法一致,也会面临同一个问题:恢复时原查询不再返回数据,模板里无法直接取到当前值。
针对这种写法,Flashduty 提供了关联查询。仍然以 cpu_usage_active 这个指标为例,可以配置一个用于精确查询当前值的关联查询,并在备注描述里按告警和恢复状态分别展示不同取值:

其中,关联查询的名字设置为 X,也可以设置为其他名字。关联查询语句仍然是 PromQL,用于精确查询具体值。这里的 PromQL 可以引用告警事件中的标签变量,例如 ident="${ident}",${ident} 表示当前告警事件里的 ident 标签。
随后在备注描述中写 if else 逻辑,针对告警和恢复两种状态分别取值。这样既保留了“阈值写在 PromQL 里”的表达方式,也能在恢复通知中展示当前值。
两种方案怎么选
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 查询结果规模可控,希望配置直观 | 方案一 | 查询原始值后再判定,告警和恢复都能直接拿到当前值。 |
| 已经习惯 PromQL 内写阈值 | 方案二 | 保留原有写法,通过关联查询补充恢复值。 |
| 一个查询会匹配大量时间序列 | 方案二 | 避免告警引擎先拉取过多原始数据再判定。 |
| 通知里需要展示更多上下文 | 方案二 | 关联查询可以顺带查询相关指标或日志详情。 |
关联查询还能解决哪些问题
关联查询不只适合获取恢复时的当前值。常见用法包括:
- A 指标触发告警时,顺带展示 B 指标的当前值。
- 日志告警达到 Error 数量阈值时,展示相关日志详情。
- 在告警通知中补充与当前标签匹配的上下文数据。
这些信息能帮助值班人更快判断影响范围和可能原因,减少打开多个系统手动查询的步骤。
小结
告警恢复时拿不到当前值,本质原因是阈值条件过滤掉了恢复后的数据。要解决这个问题,要么把阈值判定从 PromQL 中移出来,让告警引擎先拿到原始值;要么保留原有 PromQL 写法,在恢复时通过关联查询再查一次当前值。
Flashduty 的告警引擎功能当前是公测阶段,欢迎免费体验,注册地址:
https://console.flashcat.cloud/

欢迎加我好友,交流可观测性相关话题或了解我们的商业产品,我的微信号:picobyte,加好友请备注您的公司、姓名、来意 🤝


