
核心要点
- 系统是否稳定,最终要回到用户和业务是否感知稳定;内部指标正常但用户无法完成关键动作,仍然是稳定性问题。
- 微服务和云原生提高了迭代效率,也让全局故障的上下文更分散,单靠某个团队或少数内部指标很难判断整体可用性。
- 稳定性体系需要同时建设用户视角的北极星指标、系统视角的灭火图、事件与变更关联、应急协同和智能辅助分析。
- 目标不是替换监控、日志、Trace、变更和云平台,而是把这些系统的关键信息组织成故障现场能看懂、能协作、能决策的上下文。
「我不要你觉得稳定,我要我觉得稳定」,这一届用户要求越来越高了。在系统稳定性这个话题上,如果用户觉得你的系统不稳定,那么系统就是不稳定的,哪怕技术人员自己从内部来看,各项指标都是正常的,那也无济于事。
同样的,这一届老板和业务方要求也高,老板和业务要的不是你觉得稳定,如何把这个非常主观的沟通变成客观的、量化的沟通过程,是技术保障团队要面临的重要挑战之一,在我的前一篇文章建立云原生组织的8个要素 中详细解释了如果沟通不到位、不顺畅,会给技术保障体系建设带来长期的影响。
微服务在云原生时代,在业务迭代更快、研发团队效率更高方面,带来了空前的优势。但这个优势也是有代价的,即不可避免的,给系统的可维护性,带来了巨大的挑战,系统整体复杂度变得更高,关联关系更加难以维护和追踪。当系统中微服务的数量达到一定数量时,量变引发质变,整个系统的可维护性,已经超出了”人“的最佳工作主频,这时候增加再多的 headcount 到技术保障团队,其边际收益充其量也就是线性的了(我们暂且忽略增加 headcount 的难度) 。
受限于此,各个技术团队,都只能做到对自己所负责的系统熟悉,而当公司核心业务发生全局故障时,没有一个独立技术团队有能力、有足够的 Context, 可以为此次故障的应急处理全权负责,从而拉长了故障止损的时间。
更困难的还有一点,这么多的微服务,我们很难再通过几个有限的系统内部指标,组合起来量化系统的整体可用性。也就是说,如果我们无法简单、准确地定义复杂系统的整体可用性,这会反过来影响到技术团队介入故障应急处理的反应速度和投入的资源。
我们试着回顾一下,最近的几次故障复盘详情,下面的三个现象是否似曾相识?
- 一、关于故障预防:明明已经做了很多的高可用设计,有多重交叉防护,某个故障根因操作也经过了重重审核和检查,为什么故障的时候这些屏障都完美的避开了?
- 二、关于故障发现:明明监控都有,甚至矫枉过正不该加的报警也有,为什么大部分故障时候,都是终端用户反馈后技术团队才发现,并且最后的复盘改进项中永远都会再加一条:继续完善监控,增加对 xxx 的监控?
- 三、关于故障定位:明明已经有很多运维工具了,为什么遇到核心业务全局故障的时候,大家还是会手忙脚乱,信息满天飞,贻误时机?
究其根本,在微服务和云原生场景下,IT 可靠性保障,出现了一些新的矛盾:
- 首先,我们要认识到,故障是无法被完全规避的,我们所做的种种预防性措施,都是在企业的当前发展阶段内,努力在技术投资、稳定性保障、业务发展速度三者之间寻求平衡,找到最优解;
- 其次,不是缺好用的工具:恰恰是需要用到的工具数量太多,整个技术团队如何学好、用好这些工具,反而成为了巨大的负担;
- 再次,不是监控数据不够用:反而是数据太多,在故障处理这个争分夺秒的场景下,从中快速提取到真正有用的信息如大海捞针,费时费力;
- 最后,也不是缺少经验丰富的优秀工程师:但是优秀工程师的精力要发挥在价值杠杆更大的地方,把钢用在刀刃上,而不是无休止的每次都去故障应急;
所以,如何简单、准确的量化清楚系统的整体可靠性,以及减少信息过载、降低参与故障处理的门槛,尤为关键。
本文将尝试从以下三个方面,来探索解决方案:
| 建设方向 | 解决的问题 | 关键产物 |
|---|---|---|
| 建立全面的度量体系 | 用户感知和内部指标割裂 | 北极星指标、SLO、灭火图 |
| 加强信息协同,让数据说人话 | 故障现场上下文分散、沟通低效 | 结构化事件、关联视图、IM 协同 |
| 特定场景下的智能辅助决策 | 数据太多、人工定位慢 | 异常检测、特征分析、辅助定位 |
第一步:建立全面的度量体系
Google SRE 曾在其工程实践中,就引入了针对服务可靠性的预算机制,即「Budget」的概念。技术团队和业务团队就服务不可用时长的额度,制定合理的目标,进而指导技术投资、稳定性保障、业务发展三者的全局最优解法。OpenSLO 是对该方法论的一个典型开源抽象。
What is OpenSLO?
OpenSLO is a service level objective(SLO)language that declaratively defines reliability and performance targets using a simple YAML specification. It is released under Apache 2.0 and we welcome contributions from the reliability engineering ecosystem. SLOs are reliability targets for services that allow organizations to make better decisions in how to create, operate, and run cloud services and applications.
我在之前的一篇文章建立云原生组织的8个要素中,也把 Service Level Objectives 明确作为了其中一个关键要素。
我们可以将SLO进行更进一步的抽象,分别从外部用户视角和从内部系统视角,更全面的看待整体的可用性,我们称其为北极星指标和灭火图指标。
北极星指标,顾名思义,在夜空中指引方向,是对业务全局核心指标的量化。在发生全局故障的时刻,让所有参与者能够清楚知晓对核心业务的影响面,进而对故障级别、应急处置优先级有统一的认知。北极星本质上,就是在从用户的视角,来整体看待复杂系统的稳定性。
举几个例子:
- 对于类似 zoom 这样的在线会议业务,其北极星指标可以定义为「1分钟内的参与会议的方数」;
- 对于类似 klarna 这样的支付业务,其北极星指标可以定义为「1分钟内的交易笔数」;
- 对于类似游戏这样的游戏业务,其北极星指标可以是 「1分钟内的同时在线游戏人数」;
- 对于类似滴滴这样的出行业务,其北极星指标可以是「1分钟内的呼叫次数」「1分钟内处于行程中的订单数」;
一旦这些北极星指标发生了异常波动,就代表了核心业务受到了影响, 该事件应该要第一时间被响应并上升,故障应急小组(incident management team & incident commander)第一时间就位,相关支撑系统的工程师也要被 involve 进来。
同时,北极星指标经过一段时间的运行,其异常的时间、正常的时间,本身就是一个很客观的度量我们系统是否稳定的依据,作为技术团队和业务方沟通的桥梁,是最合适不过了。
| 业务类型 | 北极星指标示例 | 它代表的用户视角 |
|---|---|---|
| 在线会议 | 1分钟内参与会议的方数 | 用户是否能顺利进入和参与会议 |
| 支付业务 | 1分钟内交易笔数 | 用户是否能完成支付 |
| 游戏业务 | 1分钟内同时在线游戏人数 | 用户是否能持续在线和参与游戏 |
| 出行业务 | 1分钟内呼叫次数、处于行程中的订单数 | 用户是否能叫车和完成行程 |
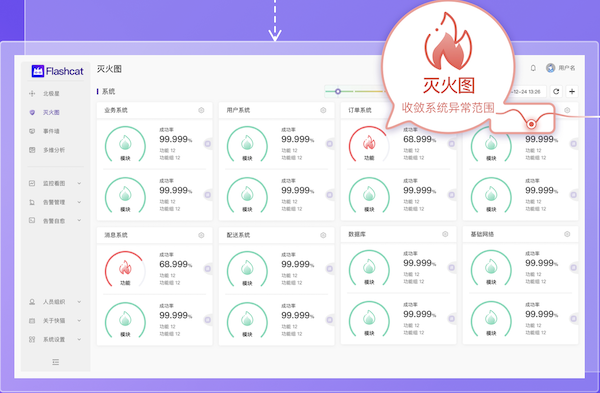
灭火图,顾名思义,聚焦于应急故障处理过程中,对关键场景、功能、系统、基础设施的状态量化,这些针对服务黄金指标的量化和结构化呈现,有助于让我们对于服务的运行状态(如系统容量、服务质量等)和预期正常目标之间的 Gap,有了清晰的量化认知。从而可以快速界定故障影响的范围和程度(从故障处理的经验来讲,缩小和界定故障的scope,是最耗时的)。
第二步:重点加强信息协同,让数据说人话
IT服务的故障处理过程中,影响故障处理效率的重要原因之一是信息同步和团队协同的低效,缺乏足够上下文信息影响判断和决策。
我们将「信息搜集」的工作自动化完成,并以结构化信息的方式,有机的组合、关联和呈现开来。对于故障定位专家,可以在系统中设置定位链路最佳模式,将最佳实践固化到系统。对于其他技术人员或新接手业务的同学,则可以直观看到全局的影响,按照最佳实践,按图索骥,完成故障定位的工作。
此外,我们把故障应急协同的过程,通过与 IM 系统打通,能够引导技术团队在平台上进行高效协同,做到 IT 服务故障的早发现和快恢复。
特别的,经验数据统计表明,故障 70% 都是由于变更引起的,这些变更包括业务代码的正常迭代上线、配置和开关的调整、网络的调整割接、infra的维护和扩容,林林总总,但凡有变更,就伴随着一定的风险。因此,在快猫云眼中,重点对「事件中心」进行了建设,包括多种数据源的接入、标准化、再丰富、并根据 Label 自动关联等实用功能,帮助技术团队,第一时间定位到相关可疑变更事件。

第三步:特定场景下的智能辅助决策
基于前两步构建的信息系统,结合 算法、数据加经验规则,在特定的点上,提供不同维度的辅助分析视角,可以大大加速故障定位过程。目前较成熟的有两块:
- 一是针对多维时序数据的智能异常检测,所有核心指标无需人工配置报警策略,报警准确率>99.99%;
- 二是智能特征分析,基础设施异常和单边异常等场景1分钟内完成自动定位的准确率>80%,结合更准确的关联关系输入,将使整体的智能定位效率实现飞跃;
随着整个故障定位信息系统的构建的越来越完善,接入的数据维度越多,结合算法和经验规则,辅助定位的效果就会越好。最后,装备这样的故障定位信息系统,不必,也不应该替换已有的成熟 IT系统,比如监控、日志分析、trace、变更、编排调度、云平台管控系统等等。借助快猫 Integration Hub, 可以实现快速对接,快速装备,快速见效。
关于快猫星云
快猫星云,一家云原生智能运维科技公司,秉承着让监控分析变简单的初心和使命,致力于打造先进的云原生监控分析平台,结合人工智能技术,提升云原生时代数字化服务的稳定性保障能力。
FAQ
Q1:为什么稳定性要从用户视角定义?
因为用户只关心关键动作是否能完成,例如下单、支付、登录、开会或叫车。内部 CPU、内存、实例状态都正常,也不能证明用户体验稳定。
Q2:北极星指标和灭火图有什么区别?
北极星指标面向业务全局,回答核心用户行为是否受影响;灭火图面向故障处理,回答关键场景、服务、基础设施和依赖对象是否健康。
Q3:智能辅助决策会替代现有监控和排障工具吗?
不会。更现实的做法是把监控、日志、Trace、变更、编排调度和云平台的信息接入并关联起来,再在特定场景下用算法和规则辅助定位。


