
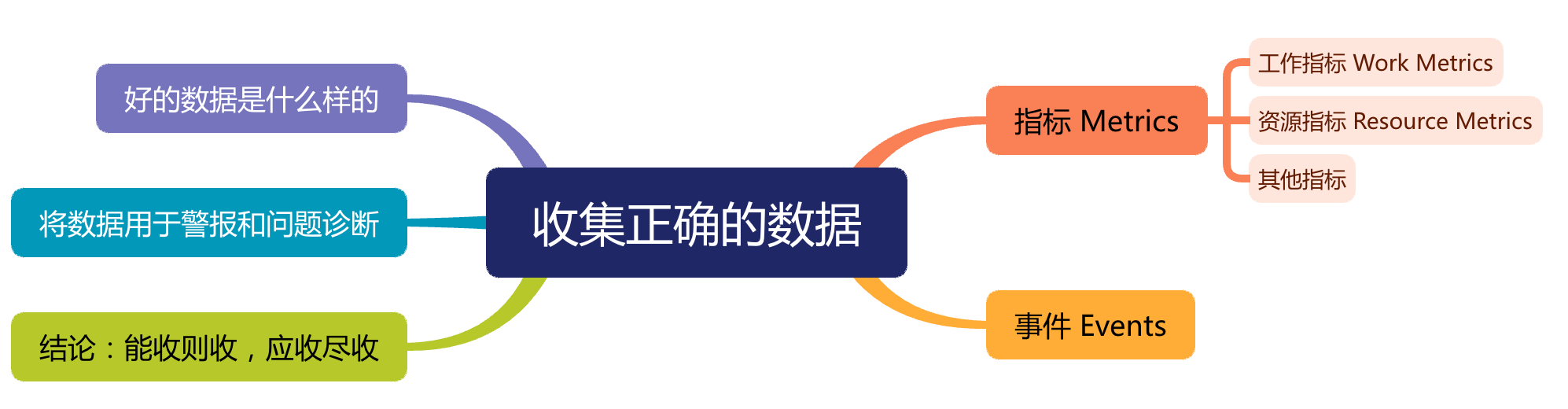
Datadog 监控最佳实践 - 收集正确的数据
本文是Datadog“高效监控”系列的第一篇,后面还会有第二篇《针对重要事项发出警报》和《调查性能问题》。
监控数据有多种形式 - 一些系统不断地输出数据,而另一些系统仅在罕见事件发生时才产生数据。有些数据主要用于识别发现问题、有些数据主要用于调查问题。更宽泛地说,监控数据是观察系统内部运行情况的必要条件。
这篇文章介绍了要收集哪些数据以及如何对这些数据进行分类,以便您可以:
- 对于潜在问题触发有意义的警报
- 快速调查并找出性能问题的根源
无论您的监控数据采用何种形式,统一的主题都是:
收集数据很便宜,但在需要时没有获得数据可能会很昂贵,因此您应该监测一切,并合理地收集所有有用的数据。
本系列文章源自我们为客户监控大型基础设施的经验。它还借鉴了Brendan Gregg、Rob Ewaschuk 和 Baron Schwartz 的工作。
指标 Metrics
指标是在特定时间点与您的系统相关的值 - 例如,当前登录到 Web 应用程序的用户数量。因此,通常每秒、每分钟或以其他固定时间间隔收集一次指标,以此监控您的系统。
我们的框架中有两类重要的指标:工作指标和资源指标。对于每个软件系统,请考虑哪些工作指标和资源指标是合理可用的,并将它们全部收集起来。

工作指标 Work Metrics
通过度量系统的输出,工作指标可以从顶层视角衡量系统的健康状况。我们可以把工作指标分成四个子类:
- 吞吐量:度量系统在某个时间段内处理的工作量。吞吐量通常记录为绝对数字。
- 成功:表示成功执行的工作的百分比。
- 错误:捕获错误结果的数量,通常使用错误率来表示。成功率和错误率貌似有重复,但是,错误也可以分类,不同的错误类型可能需要不同的处理方式,此时对错误细化分别统计就有价值了。
- 性能:量化组件的工作效率。最常见的性能指标是延迟,它表示完成一个工作单元所需的时间。延迟可以表示为平均值或百分位数,例如“99% 的请求在 0.1 秒内返回”。
译者注:总结起来就是,系统当前处理了多大量?处理成功了多少?处理失败了多少?处理速度如何?
这些指标对于可观察性非常重要。它们是比较宽泛的度量指标,可以帮助您快速回答系统内部运行状况、系统性能:系统是否可用并积极执行其设计目的?它工作的速度有多快?这项工作的质量如何?
以下是两种常见系统的所有四种子类型的示例工作指标:Web 服务器和数据存储。
工作指标示例:Web 服务器
| 类型 | 描述 | 值 |
|---|---|---|
| 吞吐量 | 每秒请求数 | 312 |
| 成功 | 自上次测量以来为 2xx 的响应百分比 | 99.1 |
| 错误 | 自上次测量以来为 5xx 的响应百分比 | 0.1 |
| 性能 | 第 90 个百分位数的响应时间(以秒为单位) | 0.4 |
工作指标示例:数据存储
| 类型 | 描述 | 值 |
|---|---|---|
| 吞吐量 | 每秒查询次数 | 949 |
| 成功 | 自上次测量以来成功执行的查询的百分比 | 100 |
| 错误 | 自上次测量以来产生异常的查询百分比 | 0 |
| 性能 | 第 90 个百分位数的查询时间(以秒为单位) | 0.02 |
资源指标 Resource Metrics
软件基础设施的大多数组件都充当其他系统的资源。有些资源是“低级”的,例如,服务器的资源包括CPU、内存、磁盘和网络接口等物理组件。但是,如果另一个系统需要更高级别的组件(例如数据库或地理定位微服务)来完成工作,则该组件也可以被视为资源。
资源指标可以帮助您重建系统状态的详细情况,这使得它们对于调查和诊断问题特别有价值。对于系统中的每个资源,尝试收集涵盖四个关键领域的指标:
- 利用率:是资源繁忙的时间百分比,或正在使用的资源容量的百分比。
- 饱和度:是对资源尚无法提供服务(通常排队)的请求工作量的度量。
- 错误:表示在资源工作中可能无法观察到的内部错误。
- 可用性:表示资源响应请求的时间百分比。此指标仅针对可以主动定期检查可用性的资源进行明确定义。
以下是一些常见资源类型的示例指标:
| 资源 | 利用率 | 饱和度 | 错误 | 可用性 |
|---|---|---|---|---|
| 磁盘 IO | 设备繁忙的时间百分比 | 等待队列长度 | 设备错误 | 可写的时间百分比 |
| 内存 | 正在使用的总内存容量的百分比 | 交换分区使用 | N/A(通常观察不到) | 不适用 |
| 微服务 | 每个服务线程繁忙的平均时间百分比 | 排队的请求 | 内部错误,例如捕获的异常 | 服务可访问的时间百分比 |
| 数据库 | 每个连接繁忙的平均时间百分比 | 排队的请求数 | 内部错误,例如复制错误 | 数据库可访问的时间百分比 |
其他指标
还有一些其他类型的指标既不是工作指标也不是资源指标,但它们仍然可能有助于使复杂的系统可观察。常见示例包括缓存命中或数据库锁定的计数。如有拿不准,先采集了再说。
事件 Events
除了或多或少连续收集的指标之外,一些监控系统还可以捕获事件:离散的、不频繁发生的事件,可以为了解系统行为的变化提供重要的背景信息。一些例子:
- Changes:变更,内部代码发布、构建和构建失败、配置更改等。
- Alerts:警报,内部生成的警报或第三方通知。
- Scaling events:扩展事件,例如添加或减少主机。
事件通常携带足够的信息,可以自行解释,这与单个指标数据点不同,后者通常仅在上下文中有意义。事件捕获在某个时间点发生的事情,并带有可选的附加信息。例如:
| 发生了什么 | 时间 | 附加信息 |
|---|---|---|
| 修补程序 f464bfe 已投入生产 | 2015–05–15 04:13:25 UTC | 经过时间:1.2秒 |
| 合入 1630 号 PR | 2015–05–19 14:22:20 UTC | Commits: ea720d6 |
| 每晚数据汇总失败 | 2015–05–27 00:03:18 UTC | 链接到失败作业的日志 |
事件有时用于生成警报 - 应向某人通知事件,例如上表中的第三个示例,这表明关键工作已失败。但更常见的是,它们用于调查问题并跨系统进行关联。通常来讲,可以把事件类比指标 - 他们都是有价值的数据,应采尽采。
好的数据是什么样的
您收集的数据应具有四个特征:
- 很好理解:您应该能够快速确定每个指标或事件的捕获方式及其代表的含义。在故障期间,您肯定不想花时间去弄清楚数据的含义。让您的指标和事件尽可能简单,使用上述标准概念,并清楚地命名它们。
- 注意颗粒度:如果您收集指标的频率太低或在很长一段时间内收集平均值,您可能会失去准确重建系统行为的能力。例如,如果将 100% 资源利用率的时段与较低利用率的时段进行平均,则这些时段将变得模糊。以不会掩盖问题的频率收集每个系统的指标,收集的频率不能太高,不能让监控明显对系统造成负担,或者采样间隔太短而使监控数据产生噪音。
- 打上范围标签:每个主机同时在多个作用域中运行,您可能需要检查任何这些作用域或其组合的总体运行状况。例如:生产总体情况如何?美国东北部的生产情况如何?特定的角色或服务怎么样?保留与数据关联的多个范围非常重要,以便您可以针对任何范围的问题发出警报,并快速调查中断情况,而不受固定主机层次结构的限制。
- 长时间保留:如果您过早丢弃数据,或者在一段时间后您的监控系统聚合您的指标以降低存储成本,那么您就会丢失有关过去发生的情况的重要信息。将原始数据保留一年或更长时间可以更容易地了解什么是“正常”,特别是当您的指标存在每月、季节性或年度变化时。
将数据用于警报和诊断问题
下表将本文中描述的不同数据类型映射到不同警报紧急级别。简而言之,record 是一种低紧急度警报,不会自动通知任何人,而是记录在监控系统中,以备以后分析或调查有用。notification 是一种中等紧急程度的警报,可以通过电子邮件或聊天等不间断方式通知解决问题的人员。page 是一种紧急警报,无论什么时间都会打断接收人的工作、睡眠或个人时间。
| Data | Alert | Trigger |
|---|---|---|
| 工作指标:吞吐量 | page | 值远高于或低于平常,或者存在异常变化率 |
| 工作指标:成功 | page | 成功处理的工作百分比降至阈值以下 |
| 工作指标:错误 | page | 错误率超过阈值 |
| 工作指标:性能 | page | 工作需要很长时间才能完成(例如,性能违反内部 SLA) |
| 资源指标:利用率 | notification | 接近关键资源限制(例如,可用磁盘空间降至阈值以下) |
| 资源指标:饱和度 | record | 等待进程数超过阈值 |
| 资源指标:错误 | record | 固定时间内的错误数量超过阈值 |
| 资源指标:可用性 | record | 资源不可用的时间百分比超过阈值 |
| 事件 | page | 应该完成的关键工作被报告为未完成或失败 |
结论:收集全部
- 检测一切并尽可能多地收集工作指标、资源指标和事件。复杂系统的可观测性需要全面的测量。
- 收集足够粒度的指标,使重要的峰值和谷值可见。具体粒度取决于您正在测量的系统、测量成本以及指标变化之间的典型持续时间(内存或 CPU 指标为秒、能耗为分钟等)。
- 为了最大限度地发挥数据的价值,请在多个范围内标记指标和事件,并以完整的粒度将它们保留至少 15 个月。
原文:https://www.datadoghq.com/blog/monitoring-101-collecting-data/
后面还有两篇,关注我,加个公众号星标,不要错过 :)



