
Prometheus 生态中,很多告警规则会把阈值直接写在 PromQL 里。这样做触发告警很直观,但恢复时会遇到一个常见问题:恢复消息里难以拿到“恢复时的值”。夜莺 v7.0.0.beta10 开始提供内置方式,通过 recovery_promql 和通知模板中的 recovery_value 解决这个问题。
核心要点
- 问题来源:阈值写在 PromQL 中,恢复时 PromQL 不再返回异常序列,因此恢复通知不容易拿到当前值。
- 夜莺方案:告警规则自定义字段中增加
recovery_promql,恢复时再查询一次当前值。 - 模板展示:通知模板判断
.AnnotationsJSON.recovery_value,存在时展示恢复时值。 - 适用前提:
recovery_promql需要能用告警事件标签精确匹配恢复的对象,例如通过target标签定位对应 series。
升级方法
从 v6 版本开始,程序自动创建表结构,所以 v6、v7 的各个小版本之间升级,相对容易,整体逻辑是:
- 备份数据库、二进制、配置文件、integrations 目录,以防万一。
- 下载新版本并解压,修改配置文件中的数据库连接地址、Redis 连接地址、时序库连接地址等个性化信息。
- 停掉老版本,启动新版本。建议新老版本使用不同安装目录,都保留不删,并用软链指向当前使用的版本。
拿到恢复时的值的原理
夜莺的告警逻辑,是拿规则中的 PromQL 周期性查询。查询不到数据时认为正常;查到数据时认为存在触发阈值的异常数据,进而生成告警事件。
从这个逻辑可以看出,恢复时 PromQL 已经查不到异常数据,所以也就难以直接拿到恢复时的值。
有两个办法可以解决:
- 不要把阈值放到 promql 中了,promql 查询原始数据,然后在告警引擎里边判断是否触发了阈值,而不是让时序库去判断,Flashduty 和夜莺企业版就提供了这个方式,这个方式比较容易理解,但是每次 promql 把原始数据查出来,可能会查出特别大量的数据,要小心使用
- 在告警恢复的时候,重新发起一次 promql 查询,查询当前最新值。但是要注意,比如 10 台机器同时触发了 load1 告警,某个时刻有 2 台恢复了,查询最新值的 promql 得是准确去查询恢复的 2 台,得对应起来
开源版本的夜莺提供的是第二种方式:恢复时根据规则自定义字段中的 recovery_promql 再查一次当前值。
| 方案 | 优点 | 注意点 |
|---|---|---|
| 查询原始数据,在告警引擎判断阈值 | 恢复值更容易理解 | 原始数据量可能很大,需要谨慎使用 |
| 恢复时追加一次 PromQL 查询 | 对开源版更轻量 | PromQL 必须能准确匹配恢复对象 |
如何配置
需要配置两个地方:通知模板和告警规则。
第一个是通知模板。下面以钉钉通知模板为例,其他通知模板可以参考同样的判断逻辑:
#### {{if .IsRecovered}}<font color="#008800">💚{{.RuleName}}</font>{{else}}<font color="#FF0000">💔{{.RuleName}}</font>{{end}}
---
{{$time_duration := sub now.Unix .FirstTriggerTime }}{{if .IsRecovered}}{{$time_duration = sub .LastEvalTime .FirstTriggerTime }}{{end}}
- **告警级别**: {{.Severity}}级
{{- if .RuleNote}}
- **规则备注**: {{.RuleNote}}
{{- end}}
{{- if not .IsRecovered}}
- **当次触发时值**: {{.TriggerValue}}
- **当次触发时间**: {{timeformat .TriggerTime}}
- **告警持续时长**: {{humanizeDurationInterface $time_duration}}
{{- else}}
{{- if .AnnotationsJSON.recovery_value}}
- **恢复时值**: {{formatDecimal .AnnotationsJSON.recovery_value 4}}
{{- end}}
- **恢复时间**: {{timeformat .LastEvalTime}}
- **告警持续时长**: {{humanizeDurationInterface $time_duration}}
{{- end}}
- **告警事件标签**:
{{- range $key, $val := .TagsMap}}
{{- if ne $key "rulename" }}
- `{{$key}}`: `{{$val}}`
{{- end}}
{{- end}}
这里最关键的是判断 .AnnotationsJSON.recovery_value:
{{- if .AnnotationsJSON.recovery_value}}
- **恢复时值**: {{formatDecimal .AnnotationsJSON.recovery_value 4}}
{{- end}}
如果 .AnnotationsJSON 中包含 recovery_value 就展示;展示时通过 formatDecimal 把 recovery_value 保留 4 位小数。.AnnotationsJSON 对应夜莺告警规则中的自定义字段部分,如果告警事件中有恢复时的值,就会在这个字段中体现。
第二个是告警规则。想让哪个告警规则支持获取恢复时的值,就在该告警规则的自定义字段中加上 recovery_promql 字段。
例如有一个告警规则用来侦测 HTTP 地址探测失败:
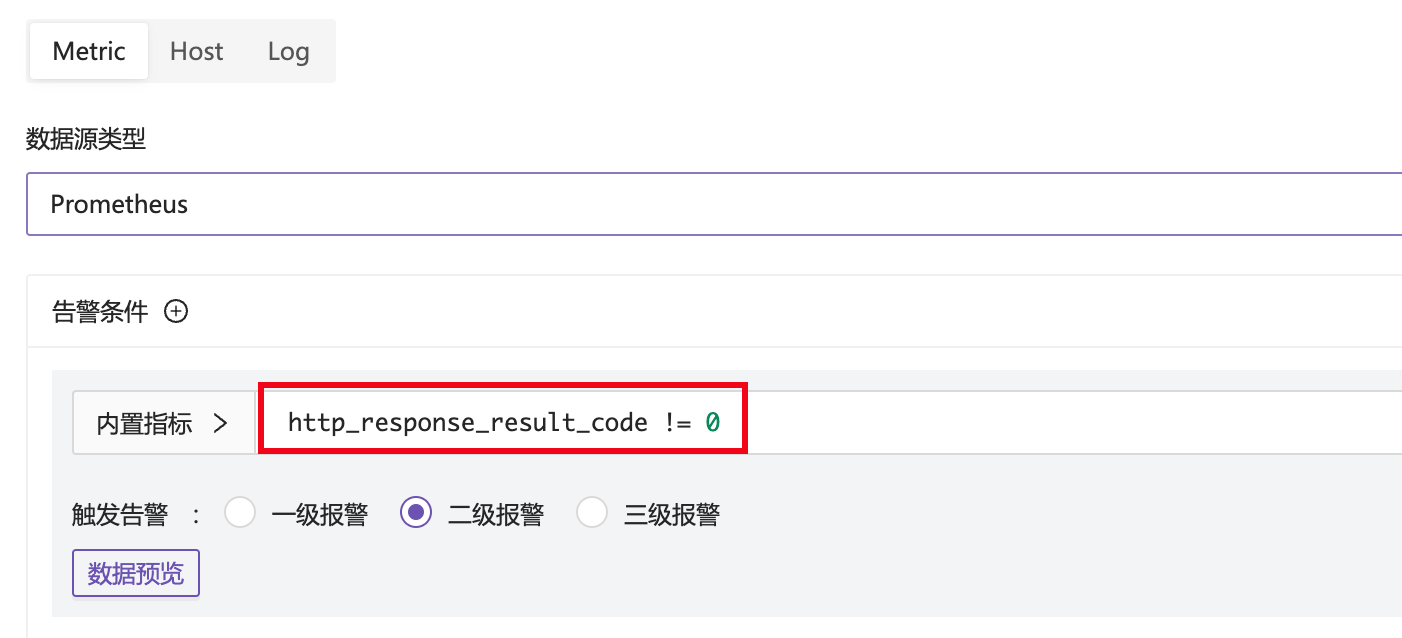
需要在告警规则最下面的自定义字段里,增加 recovery_promql 的配置,如下:

要理解这个工作逻辑,我们先来看看 http_response_result_code 这个指标的数据长什么样子:
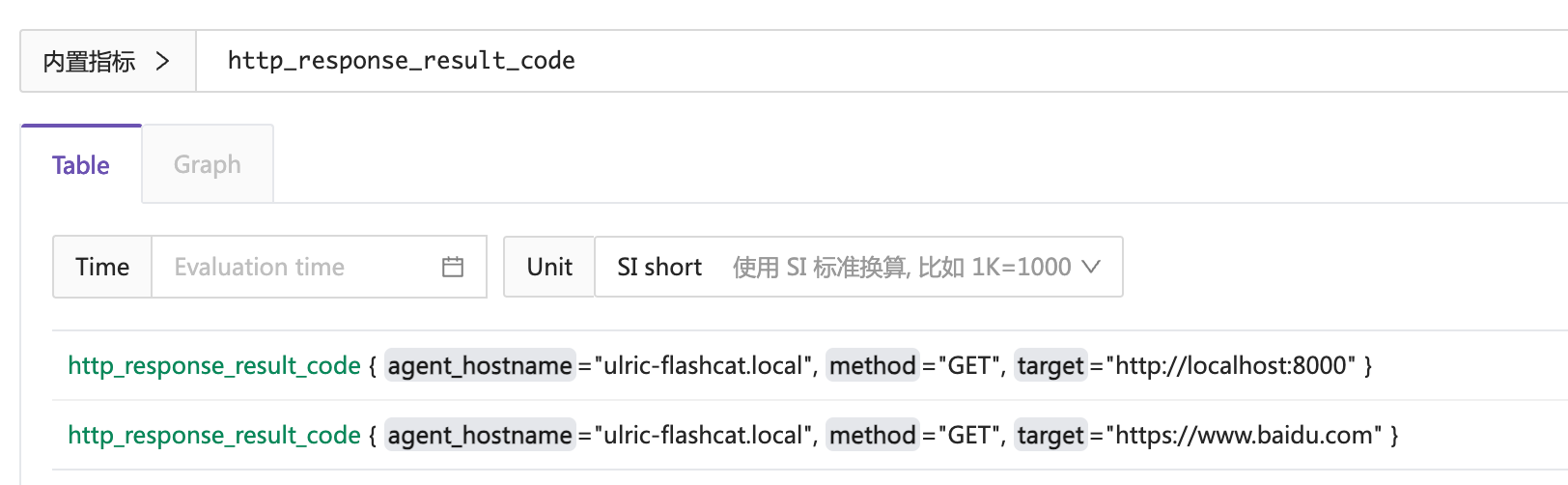
从上图可以看出,这个指标包含两个 series,其中 agent_hostname 和 method 字段相同,target 字段可以区分这两个 series。告警规则 http_response_result_code != 0 如果触发,告警事件中会带有 target 标签。
因此,告警事件恢复时,用告警时的 target 标签去查询,就可以准确查到对应对象的恢复时值。recovery_promql 配置中引用的 target 标签值,就是告警事件中的 target 标签值。
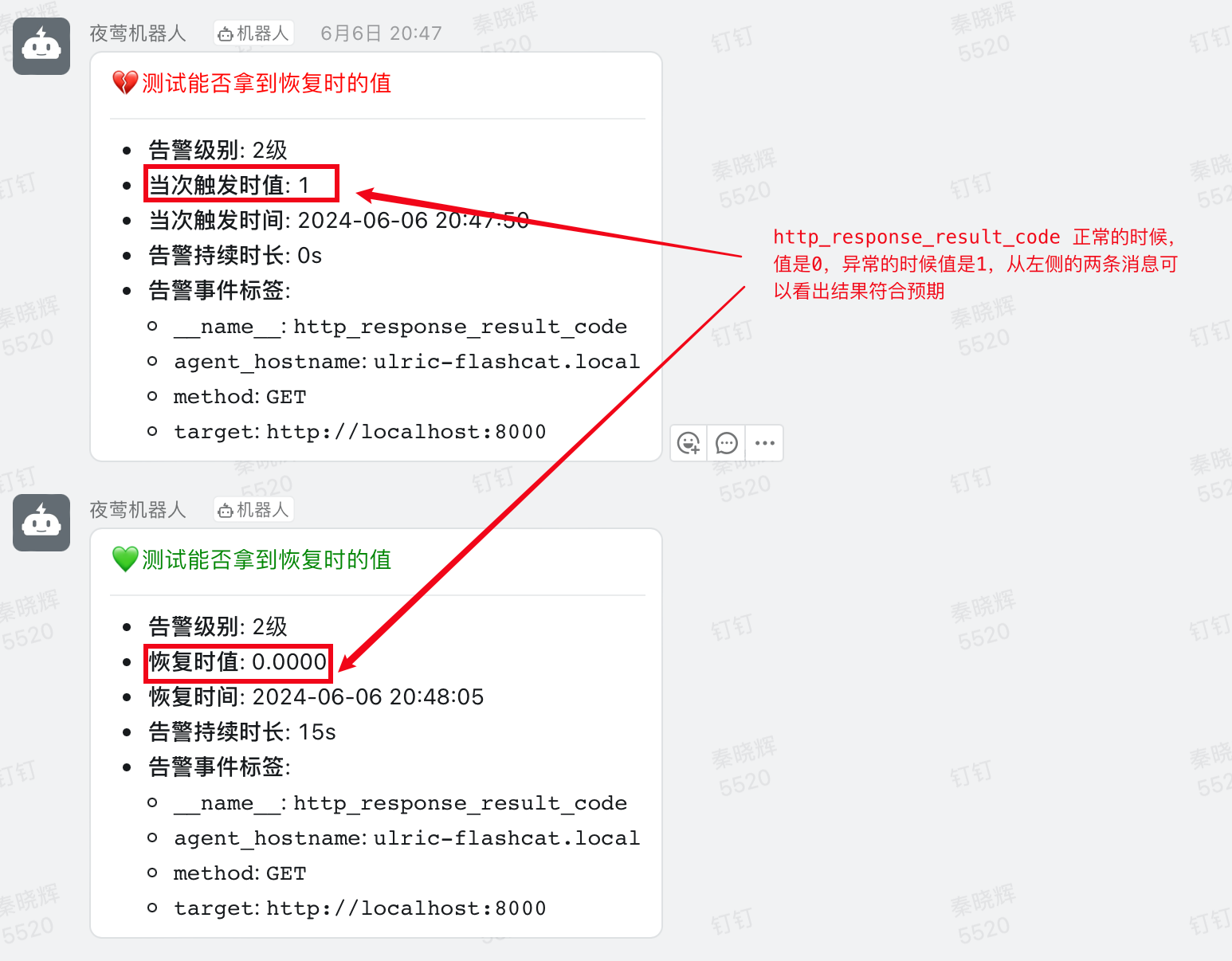
效果
后续计划
近期夜莺还计划做的事情如下:
- 仪表盘:支持内嵌 Grafana
- 告警规则:通知时支持配置过滤标签,避免告警事件中一堆不重要的标签
- 告警规则:支持配置恢复时的 Promql,告警恢复通知也可以带上恢复时的值了
- 机器管理:自定义标签拆分管理,agent 自动上报的标签和用户在页面自定义的标签分开管理,对于 agent 自动上报的标签,以 agent 为准,直接覆盖服务端 DB 中的数据
- 机器管理:机器支持角色字段,即无头标签,用于描述混部场景
- 机器管理:把业务组的 busigroup 标签迁移到机器的属性里,让机器支持挂到多个业务组
- 告警规则:增加 Host Metrics 类别,支持按照业务组、角色、标签等筛选机器,规则 promql 支持变量,支持在机器颗粒度配置变量值
- 告警通知:重构整个通知逻辑,引入事件处理的 pipeline,支持对告警事件做自定义处理和灵活分派
v7 正式版何时发版?
按每年惯例,v7 正式版会在 7 月底发版,每个大版本会持续支持 2 年。这也意味着,v5 版本将不再提供社区支持,建议 v5 版本的用户尽快升级到 v7 版本。升级方案可以查阅如下链接:
https://flashcat.cloud/docs/content/flashcat-monitor/nightingale-v7/install/upgrade/
常见问题
Q1:为什么恢复时默认拿不到恢复值?
A:因为阈值写在 PromQL 里时,恢复意味着异常查询不再返回数据;没有返回数据,就很难从原始查询结果里得到恢复时的值。
Q2:recovery_promql 配置时最容易出错的地方是什么?
A:最关键的是恢复查询要能准确匹配恢复对象。原文示例中依赖 target 标签区分 series,如果标签选错,可能查到不对应的值。
Q3:通知模板必须展示 recovery_value 吗?
A:如果希望恢复通知里显示恢复时值,就需要在模板中判断并展示 .AnnotationsJSON.recovery_value。



