
核心要点
- 夜莺 v8 大版本已经启动开发,正式版预计在 2025 年 7、8 月发布。
- v8.0.0-beta.1 引入 sqlite 和 miniredis,测试环境可以不依赖 MySQL、Redis,一键拉起夜莺。
- 告警规则支持变量,并可以结合机器名和业务组筛选机器,解决特殊机器阈值和混部机器告警问题。
- Webhook 支持代理,适合夜莺机器不能直接访问钉钉、企微等外部地址的网络环境。
- beta.1 还支持通过 Cron 表达式配置告警规则执行周期。
夜莺 v8 大版本已经启动开发,预计 2025 年 7、8 月发布正式版。相比 v7,v8 大概会做四五个大功能;每个功能做完、做稳定之后,都会提前放出来供大家体验。虽然以 beta 命名,实际是稳定的,大家可以放心升级。
夜莺 v5、v6、v7 三个大版本算是一脉相承,一直在打基础,最后一个稳定版是 v7.7.2,可以看作这个系列的终极版。这个系列中有些功能早就想改进,但由于兼容性、迁移成本和人力考虑,一直没有动作。现在基础打好了,从 v8 开始,我们计划做一些更有意思的功能。
当然,v8 不会完全不兼容 v7。v7 用户仍然可以直接升级,只是夜莺会通过 feature flag 等方式,在某些功能上引入新的做法。
v8 计划重点
| 方向 | 计划能力 | 目标 |
|---|---|---|
| 部署方式 | 减少依赖,没有 MySQL、Redis 也可以一键拉起 | 降低功能测试门槛 |
| 机器告警 | 机器告警规则不只通过 PromQL 定义,还可以和业务组打通 | 解决不同业务组、特殊机器阈值差异 |
| 通知链路 | 大幅重构告警通知逻辑 | 支持灵活分派策略、自定义媒介和多模板 |
| 数据源告警 | 支持 ElasticSearch、ClickHouse 等更多数据源告警 | 打造统一告警引擎 |
| 仪表盘 | 提供新的、更直观的仪表盘功能 | 把现有可视化能力做稳定、好用 |
除了这些大方向,还会有很多其他小改动。下面介绍 v8.0.0-beta.1 已经完成的几个重点能力。
部署方式改造:测试环境一键拉起
v8.0.0-beta.1 引入了 sqlite 和 miniredis,不再强依赖 MySQL、Redis,因此可以用一个二进制一键拉起。这个方式适合个人功能测试,但不适合生产环境。生产环境仍然需要 MySQL、Redis。
到如下地址下载 v8.0.0-beta.1 发布包:https://flashcat.cloud/download/nightingale/
我本地有一个 arm64 的 Linux 虚机做测试,所以下载了 arm64 版本发布包 n9e-v8.0.0-beta.1-linux-arm64.tar.gz。解包后直接运行夜莺二进制即可:
wget https://download.flashcat.cloud/n9e-v8.0.0-beta.1-linux-arm64.tar.gz
mkdir n9e-v8.0.0-beta.1-linux-arm64
tar zxvf n9e-v8.0.0-beta.1-linux-arm64.tar.gz -C n9e-v8.0.0-beta.1-linux-arm64
cd n9e-v8.0.0-beta.1-linux-arm64
./n9e
启动后,可以在夜莺页面上接入数据源,类似 Grafana,然后对数据源做告警、查询分析等。
如果你想采集监控数据,有两种常见方式:
- 复用以前 Prometheus 摘取 Exporter 的模式。只要数据进入 Prometheus,就可以在夜莺里配置告警规则、看图查询。
- 使用 Categraf 采集监控数据,尤其是机器层面的监控数据。此时 Categraf 的 writer 地址和 heartbeat 地址都配置为 n9e 地址;n9e 配置文件中配置时序库地址。Categraf 通过 heartbeat 请求把本机元信息上报给 n9e,n9e 存入 MySQL 和 Redis;Categraf 通过 writer 请求把监控数据上报给 n9e,n9e 再存入时序库。相关配置在
config.toml中的 Pushgw 配置项。
告警规则支持通过业务组筛选机器
这是一个重大改造,目标是解决特殊机器的阈值配置问题。
假设 DBA 团队有 100 台机器。默认情况下,希望 cpu_usage_idle < 20 时告警;但有几台机器比较特殊,CPU 核数较多,希望 cpu_usage_idle < 15 才告警。原本在 Prometheus 生态中,一切皆标签,可以给这几台机器打上 hardware=high 标签,普通机器打上 hardware=normal 标签,然后配置两条告警规则:
cpu_usage_idle{hardware="normal"} < 20
cpu_usage_idle{hardware="high"} < 15
这个方案看起来能解决问题,但实际会带来几个问题:
- 新增标签会让原本的 TimeSeries 断掉,影响其他告警逻辑。比如原本活跃的告警可能会报恢复,因为原来的数据断了查不到,告警引擎以为恢复了。
- 新增机器都要打上
hardware标签。特殊机器较少时,手工打上hardware=high还可以接受;普通机器较多时,每次新机器启用都要打上hardware=normal,很麻烦。 - 标签通常用于定义维度信息,把硬件特性也放进标签里会显得混乱。后续如果某台 normal 机器升配了,还要改标签;一旦改标签,TimeSeries 又会断掉。
再举一个混部场景:一部分机器同时部署了 redis 和 etcd 服务。etcd 对硬盘 IO 比较敏感,希望 IO 使用率超过 80% 就告警,可能会写:
diskio_util{service="etcd"} > 80
其他服务所在机器大于 90% 才告警,于是写:
diskio_util{service!="etcd"} > 90
对于同时部署 etcd 和 redis 的机器,我们希望同时打上 service="etcd" 和 service="redis" 标签。但 Prometheus 生态里不允许出现同 Key 不同 Value 的做法,这就很棘手。
夜莺 v8 的解法:变量 + 业务组
夜莺从 v7.4.1 开始支持把机器挂载到多个业务组,相当于可以用业务组描述现实中的混部场景。对于硬件规格不同的场景,也可以用业务组描述,因为业务组很灵活。
但仅仅把机器挂到不同业务组,只是方便分类查看,还没有和告警规则联动。告警规则强依赖 PromQL,而 PromQL 仍然需要使用标签过滤。从 v8.0.0-beta.1 开始,夜莺提供了新的手段:在告警规则的 PromQL 中支持配置变量,变量类型可以设置为机器;告警规则也支持配置机器筛选方式,包括通过机器名或业务组筛选。
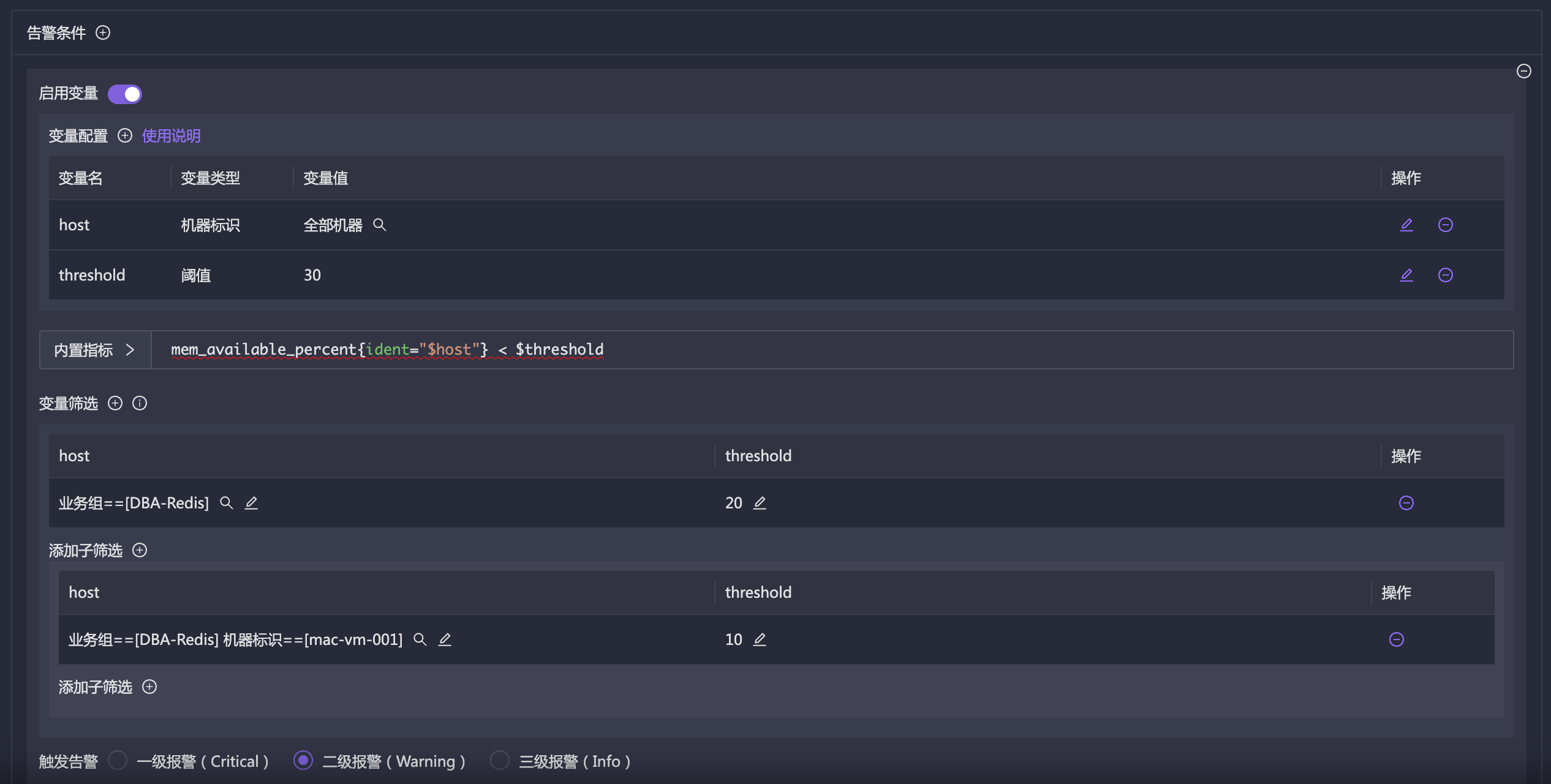
告警规则中增加了一个 switch 开关:启用变量。如果启用变量,就会出现一组更复杂的配置。
在上例中,我定义了两个变量:
host:类型是机器标识,默认值是所有机器。threshold:类型是阈值,默认值是 30。
然后在 PromQL 中引用这两个变量。如果没有变量筛选部分,只有变量配置和 PromQL,告警引擎会拿到 host 变量的所有值,即全部机器。假设是 100 台机器,就会循环 100 次,每次把 PromQL 中的 $host 和 $threshold 替换掉,执行检测;如果最终 PromQL 查到数据并满足持续时长配置,就产生告警。
上例还配置了变量筛选以及一个子筛选,最终效果是:
- DBA-redis 业务组的机器,并且机器标识是 mac-vm-001,则以阈值 10 代入 PromQL 判断。
- 除了 mac-vm-001 之外的 DBA-redis 业务组其他机器,则以阈值 20 代入 PromQL 判断。
- 除了 DBA-redis 业务组机器之外,公司的其他全部机器,则以阈值 30 代入 PromQL 判断。
PromQL 中的下划波浪线先不用关心,并非是 PromQL 写错了,而是编辑器自身的问题。
使用建议
如果可以用普通 PromQL 解决告警场景,建议继续使用老方式。如果老方式实在不好解决,可以尝试启用变量的告警规则。这个方式和业务组联动,性能会稍差,但灵活性更好。
另外,业务组是夜莺特有的概念。一旦用这种方式配置,就会和夜莺深度绑定,将来如果想迁移到其他告警引擎会麻烦一些,这点也请注意。
关于告警规则启用变量的更多信息,可以参考 文档。
Webhook 支持代理
有些公司的网络环境比较复杂,可能需要代理。夜莺的 webhook 之前不支持代理,如果夜莺所在机器不能访问外网,发送钉钉、企微等通知就会比较麻烦;虽然可以走自定义通知脚本,但成本更高。
实际上从 v7.7.2 开始,夜莺就支持代理模式,只是一直没有宣传。借 v8.0.0-beta.1 发布,做一次说明。
比如希望通过代理调用钉钉和企微,可以配置三个环境变量:HTTP_PROXY、HTTPS_PROXY、N9E_PROXY_URL。前两个环境变量指定代理地址,N9E_PROXY_URL 指定要被代理的 URL,例如:
N9E_PROXY_URL=qyapi.weixin.qq.com,oapi.dingtalk.com
多个 URL 用逗号分隔。每个 URL 不用写全,只写一部分即可,只要能匹配到就行。上面只写了域名,没有写完整回调地址。
其他改动
v8.0.0-beta.1 还有其他改动,例如告警规则支持 Cron 表达式配置执行周期,可灵活设置定时执行策略。更多改动请参考 Changelog。
结语
一个新的大版本启程了,兄弟们跟上脚步,一起打造最好用的国产开源监控系统。如果你有什么建议,欢迎在 https://github.com/ccfos/nightingale 上提 issue。如果能来个 star 就更好了,让更多人知道并参与;即便现在还有瑕疵,开源社区也会推动它越来越好。
FAQ
Q1:v8.0.0-beta.1 可以用于生产环境吗? A:文章说明 beta 版本实际是稳定的,可以放心升级;但 sqlite/miniredis 的一键拉起方式仅适合个人功能测试,生产环境仍然需要 MySQL、Redis。
Q2:什么时候应该使用告警规则变量? A:当普通 PromQL 很难表达特殊机器阈值、混部机器或业务组差异时,可以考虑启用变量。能用普通 PromQL 解决的场景,仍建议继续用老方式。
Q3:Webhook 代理需要配置什么?
A:需要配置 HTTP_PROXY、HTTPS_PROXY 和 N9E_PROXY_URL。其中 N9E_PROXY_URL 用来指定哪些 URL 走代理。


