
OpenTelemetry Collector 应该怎么部署?核心判断标准不是“哪种模式更先进”,而是遥测数据在哪里产生、在哪里需要预处理、中心端是否需要采样和路由,以及团队能否承受配置复杂度。
本文介绍三种常见部署方式:sidecar 模式、DaemonSet 模式和中心集群模式。它们不是互斥关系,生产环境里经常组合使用:DaemonSet 负责节点级采集,中心 Collector 负责聚合、采样和导出,少数特殊业务才使用 sidecar 做前置处理。
核心要点
- Sidecar 模式适合对单个业务进程做特殊预处理,例如日志脱敏、局部聚合或按服务定制采样。
- DaemonSet 模式适合节点级数据采集,例如主机指标、容器日志和本地 OTLP 数据汇聚。
- 中心集群模式适合统一接收、处理、采样、路由和导出遥测数据,是大多数生产体系的核心层。
- 尾部采样要求同一条 Trace 的 Span 尽量进入同一个 Collector 实例,因此需要按 TraceID 做负载均衡。
- 部署方式要围绕数据路径和运维成本设计,不要把所有复杂逻辑都堆在同一层。
OpenTelemetry
OpenTelemetry 合并了 OpenTracing 和 OpenCensus 项目,提供了一组 API 和库来标准化遥测数据的采集和传输。OpenTelemetry 提供了一个安全、厂商中立的工具,这样就可以按照需要将数据发往不同的后端。
OpenTelemetry项目由如下组件构成:
- 推动在所有项目中使用一致的规范
- 基于规范的、包含接口和实现的 APIs
- 不同语言的 SDK(APIs 的实现),如 Java、Python、Go、Erlang 等
- Exporters:可以将数据发往一个选择的后端
- Collectors:厂商中立的实现,用于处理和导出遥测数据
OpenTelemetry Collector 部署方式
OpenTelemetry Collector 是一个用于收集、处理和转发遥测数据(如指标、日志和链路追踪)的组件。这个组件内部可以构建指标、日志、链路数据的 Pipeline:
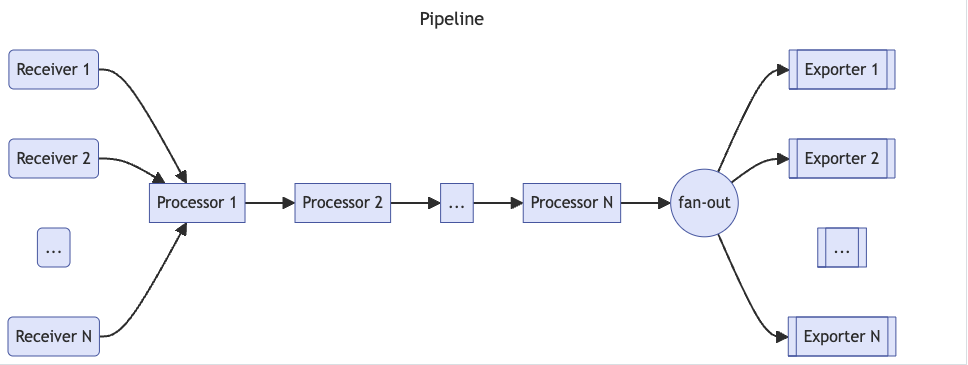
OpenTelemetry Collector 提供了多种部署模式,以适应不同的需求和场景。主要部署模式如下所示,我们来做简单介绍,并讲解适用场景。
| 部署模式 | Collector 位置 | 主要价值 | 主要代价 | 适合场景 |
|---|---|---|---|---|
| Sidecar | 与业务容器在同一个 Pod 内 | 离业务最近,便于按服务定制处理 | 每个工作负载都要管理额外容器和配置 | 特殊脱敏、局部采样、服务级隔离 |
| DaemonSet | 每个节点一个 Collector | 适合节点日志、主机指标和本地汇聚 | 节点资源有限,不适合重处理 | Kubernetes 节点级采集 |
| 中心集群 | 独立 Collector 集群 | 统一处理、采样、路由和导出 | 多一次网络跳转,需要高可用设计 | 企业级统一遥测入口 |
sidecar 模式
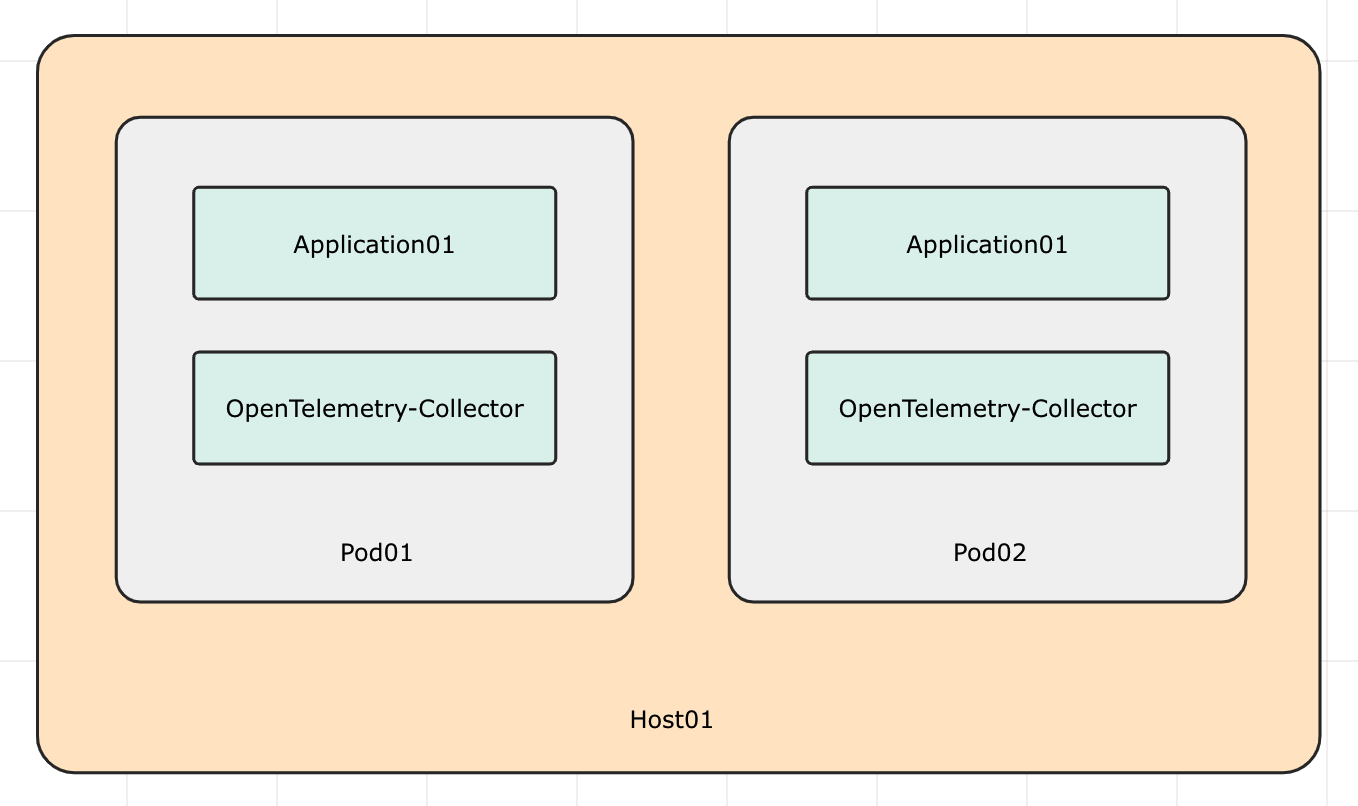
即和业务进程放到一个 Pod 内,作为一个 sidecar 容器运行。这种部署模式通常用于业务进程的遥测数据需要特殊处理的场景,例如需要对日志进行脱敏、需要对指标进行聚合、需要对链路追踪数据进行采样等。相当于一个前置处理逻辑。
业务进程的遥测数据直接发到中心化的 Collector 也不是不行,只是所有的特殊逻辑都要放到中心化的 Collector 中,这样会使得 Collector 的配置变得复杂,不易维护。
Sidecar 模式的边界也要明确:如果只是把 OTLP 数据转发到中心端,通常没有必要为每个业务 Pod 增加 sidecar。它更适合“这个服务确实需要和其他服务不同的前置处理”的情况。
daemonset 模式
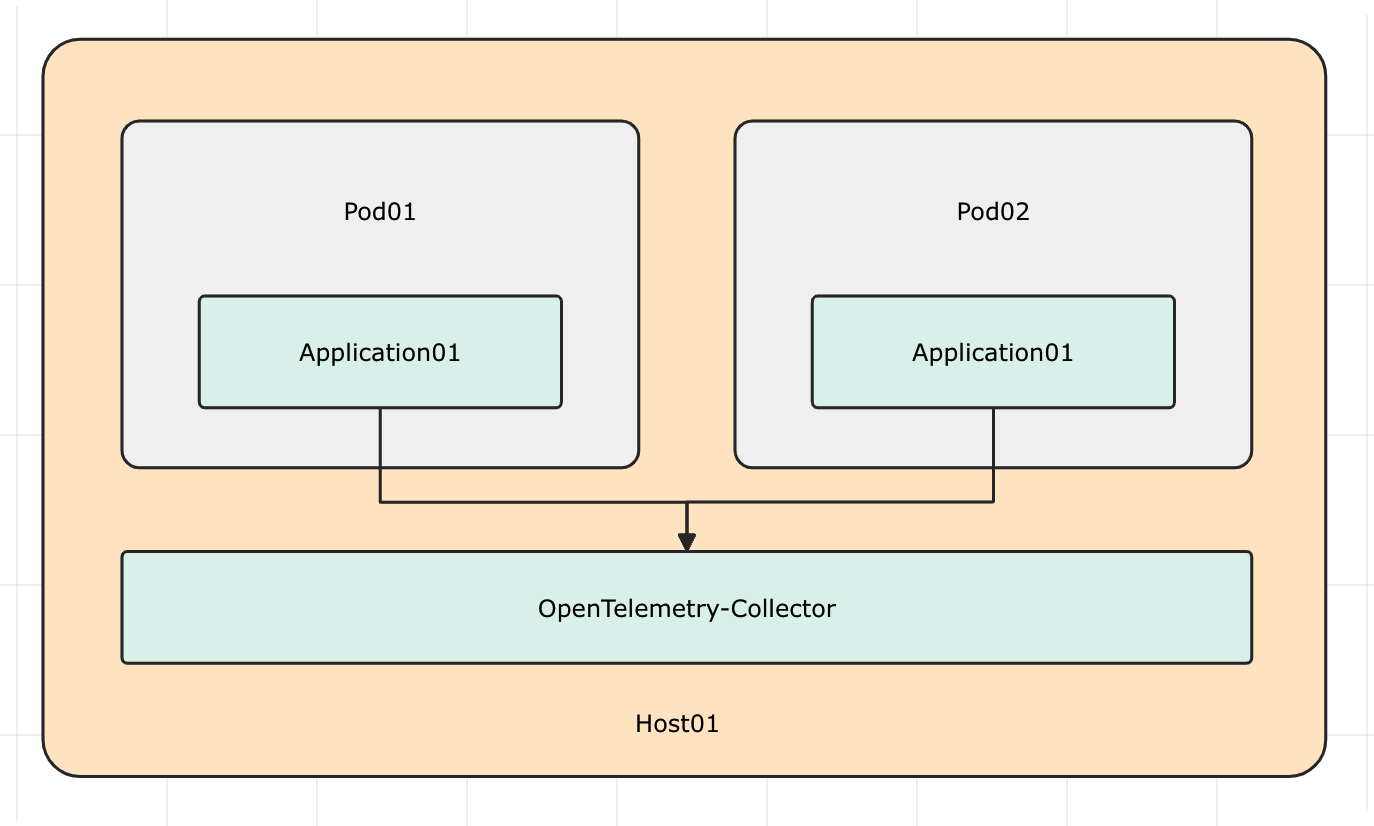
Daemonset 模式是把 OpenTelemetry Collector 部署到集群中的每个节点上,以 Daemonset 的形式运行。这种部署模式通常用于需要在每个节点上收集遥测数据的场景,例如需要收集每个节点上的系统指标、需要收集每个节点上的容器日志等。
Pod 里的业务进程发出的 Traces 数据,可以直接发给本地的 Collector,Collector 再把数据发给中心化的 Collector。这样可以减少网络开销,提高性能。
Pod 里的业务进程也可以直接发给中心化的 Collector,只是这样一来,中心化的 Collector 需要承担非常多的网络连接,攒批动作放到了 Pod 内的进程里,不如把攒批动作放到 Daemonset 内的 Collector 里效果好。
如果你需要采集机器上的系统日志、系统指标,那么 Daemonset 模式是必须的,因为这些数据是在机器上产生的,只有在机器上收集才能收集到。
DaemonSet 里的 Collector 应尽量保持轻量:接收、批量处理、补少量资源属性、转发即可。复杂的尾部采样、重度转换、多后端路由,更适合放到中心 Collector 集群。
中心集群模式
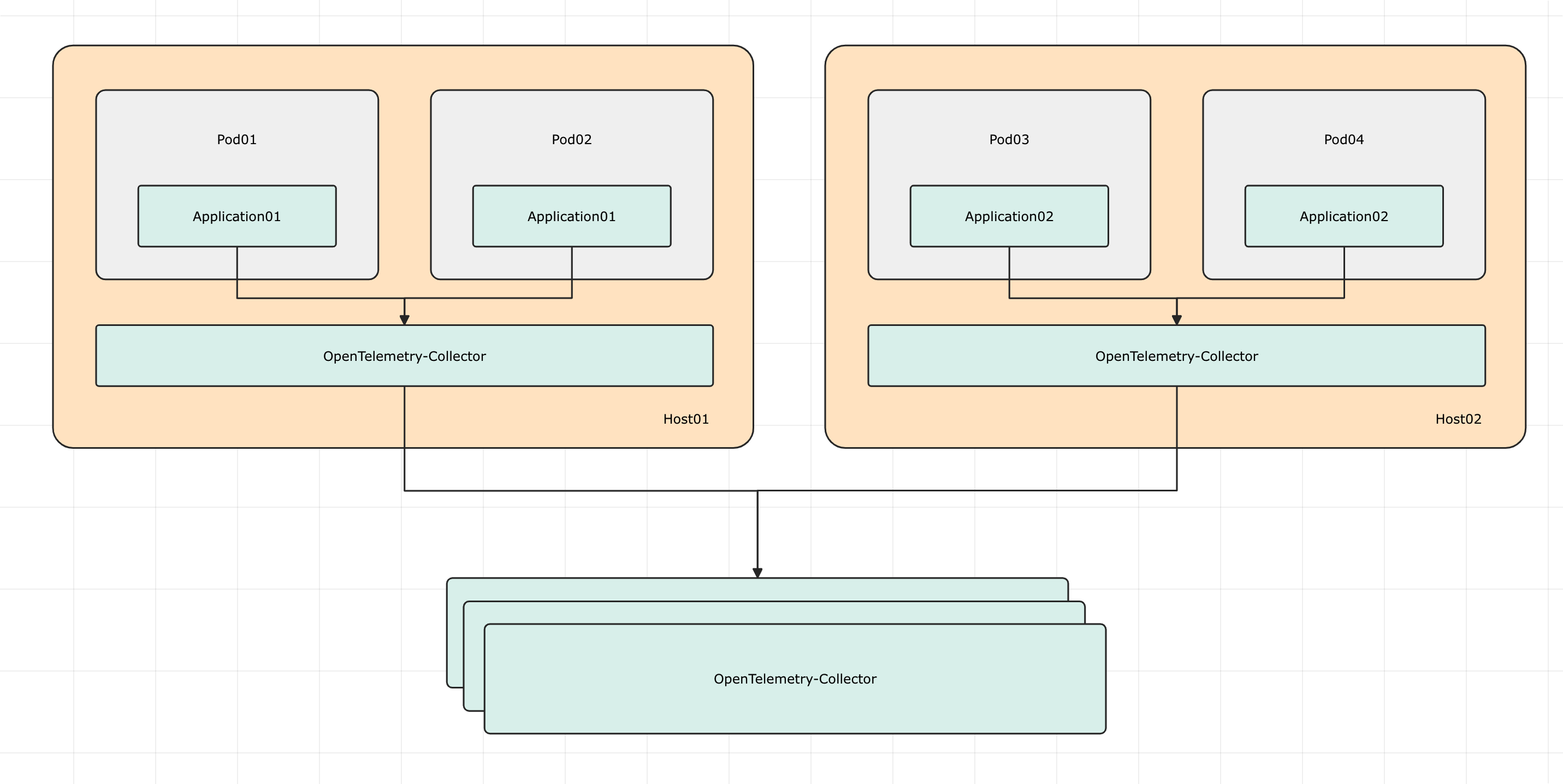
其实无论如何,一般都有一个中心化的 Collector,用于接收所有的遥测数据,然后再把数据发给后端存储、展示、告警等系统。
中心化的 Collector 通常会有多个实例,用于高可用和负载均衡。中心化的 Collector 通常要承担尾部采样的职能,尾部采样要求同一个 Trace 的多个 Span 都应该发到同一个 Collector 实例上,这样才能保证同一个 Trace 的多个 Span 被聚合在一起一同实施采样逻辑。所以前面的 Collector 在发数据给中心的 Collector 的时候,需要根据 TraceID 做负载均衡,确保相同 TraceID 的 Span 被发到同一个 Collector 实例上。怎么做负载均衡?让前面的 Collector 使用 loadbalancing 的 exporter 来导出数据即可。一个简单的配置样例如下:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
exporters:
loadbalancing:
routing_key: "traceID" # 默认不写这个配置就是 traceID
protocol:
otlp:
timeout: 5s
sending_queue: # 发送队列
enabled: true
num_consumers: 50 # 消费者数量
queue_size: 5000000 # 队列长度
retry_on_failure:
enabled: false # 是否重试
tls:
insecure: true
resolver:
k8s: # k8s service 方式获取pod 的IP 进行负载均衡
service: otel-collector.observable
# # static resolver example
# resolver:
# static:
# hostnames:
# - endpoint: "otel-collector-1:4317"
# - endpoint: "otel-collector-2:4317"
service:
pipelines:
traces:
receivers: [otlp]
exporters: [loadbalancing]
如何选择部署方式
可以按以下顺序做判断:
- 是否需要采集节点上的系统指标、容器日志或本地文件?如果需要,优先使用 DaemonSet。
- 是否有全局采样、统一脱敏、多后端路由、数据扇出或统一队列需求?如果有,需要中心 Collector 集群。
- 是否只有某个业务服务有特殊处理逻辑,并且该逻辑不适合放到中心层?如果有,再考虑 sidecar。
- 是否需要尾部采样?如果需要,中心 Collector 前面要确保相同 TraceID 的 Span 能路由到同一个实例。
- 是否能监控 Collector 自身资源、队列、导出失败和拒绝数据?如果不能,先补齐 Collector 可观测性,再扩大接入范围。
常见问题
生产环境只部署一个中心 Collector 可以吗?
小规模测试可以,生产环境通常不建议。中心 Collector 是遥测数据的关键路径,需要考虑多副本、高可用、负载均衡、队列、重试和自身监控。否则 Collector 出问题时,可观测性数据本身会先丢失。
Sidecar、DaemonSet 和中心 Collector 能同时使用吗?
可以,而且很多生产架构就是组合模式。常见做法是应用把 OTLP 数据发给本节点 DaemonSet,DaemonSet 转发到中心 Collector,中心 Collector 再做采样、过滤、路由和导出。只有少数有特殊处理需求的服务才额外使用 sidecar。
尾部采样为什么要关注负载均衡?
尾部采样需要等一条 Trace 的多个 Span 到齐后再判断是否保留。如果同一条 Trace 被随机打散到多个 Collector 实例,每个实例都看不到完整上下文,采样决策就可能失真。因此需要按 TraceID 做路由。
总结
本文介绍了 OpenTelemetry Collector 的三类部署方式:sidecar 模式、DaemonSet 模式和中心集群模式。选择时不要只看部署形态,而要看数据来源、处理位置、采样要求和运维成本。
一个稳妥的默认架构是:DaemonSet 负责节点级采集和轻量转发,中心 Collector 集群负责统一处理、采样、路由和导出;只有当某个服务确实需要独立前置处理时,再引入 sidecar。



