
PromQL教程(二)Prometheus 数据类型

在 2024 年的当下,Prometheus 生态基本已成为监控领域事实上的标准,学习 Prometheus 是每个运维人员的必修课,也是每个关注服务稳定性的研发人员的必修课。PromQL 是 Prometheus 的查询语言,全称是 Prometheus Query Language,想要学习 Prometheus,PromQL 是必学知识。本文是 PromQL 系列教程的第二讲,讲解 Prometheus 数据类型。本系列其他文章:
Prometheus 数据类型
在学习 PromQL 之前,我们先来了解一下 Prometheus 的数据类型,很多人连这个没搞懂就上生产了实属过于头铁。Prometheus 中有四种基本数据类型:Gauge、Counter、Histogram 和 Summary。为何要区分不同的类型,显然是为了对现实世界建模,更好地反映现实世界的不同指标特性。
Gauge
Gauge 类型的值表示当前的状态,可大可小、可负可正,比如某个虚机实例挂了,用 0 表示,如果实例存活,用 1 表示;再比如内存使用率,这个时刻采集是 33.7%,下个周期采集可能就变成了 25.8%;还有像机器最近 5 分钟的 load、正在运行的进程数量等等,都使用 Gauge 类型来表示。这种类型的值,我们非常关注当前值。
Counter
Counter 类型是单调递增的值,比如机器上某块网卡收到的数据包的总量,是从操作系统启动之后,就持续递增的,对于这种类型的值,我们通常关注的不是当前值是多少,而是关注增量和变化率。我们在机器上执行 ifconfig 命令:
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.206.0.16 netmask 255.255.240.0 broadcast 10.206.15.255
inet6 fe80::5054:ff:fed2:a180 prefixlen 64 scopeid 0x20<link>
ether 52:54:00:d2:a1:80 txqueuelen 1000 (Ethernet)
RX packets 457952401 bytes 125894899868 (117.2 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 518040495 bytes 276312546157 (257.3 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
RX packets 后面的值是 OS 启动以来收到的总的包量,TX packets 后面的值是 OS 启动以来发出去的总的包量,都是很大的值,我们通常不太关注这个值当前是多少,更关注的是最近 1 分钟收到/发出多少包,或者每秒收到/发出多少包。
而对于监控数据采集器而言,一般是周期性运行的,比如每 10 秒采集一次,每次采集网卡收到/发出的包这个数据的时候,都只能采集到当前的值,就像执行 ifconfig 命令,每 10 秒执行一次,每次都看到一个巨大的当前值,而且一次比一次大。如果采集器不做计算,把这个值原封不动上报给监控服务端,那计算增量、计算速率这个需求,就要放到服务端来实现了,所以服务端必须要能对这种类型的数据建模抽象,也就是所谓的 Counter 类型。
计算增量、速率这样的动作也可以放到客户端 agent 采集器里来做,但是灵活性就不好了,因为 agent 一旦得到增量、速率这样的计算结果,就会把原始数据丢弃,但是 agent 计算增量、速率一定要基于一个时间窗口大小,通常这个窗口大小要固化在 agent 配置中。如果想要按照不同的窗口大小来计算,那就要放到服务端更合适了,服务端保留原始数据,同时支持用户按照不同的窗口大小来动态计算增量、速率。
Histogram
Histogram 类型通常用于描述请求延迟、请求大小的分布情况。比如某个接口,最近一分钟收到 1000 个请求,多少请求是 10 毫秒内返回,多少请求是 100 毫秒内返回,多少请求是 1000 毫秒内返回,就是典型的一个需求场景。有了这个数据之后,就可以很方便的计算出 99 分位的延迟、95 分位的延迟这样的数据,相比平均延迟,分位延迟可以更好的描述一个服务的延迟情况。
Histogram 数据其实是由多个 Counter 指标组成,我查询一个例子给你看看:
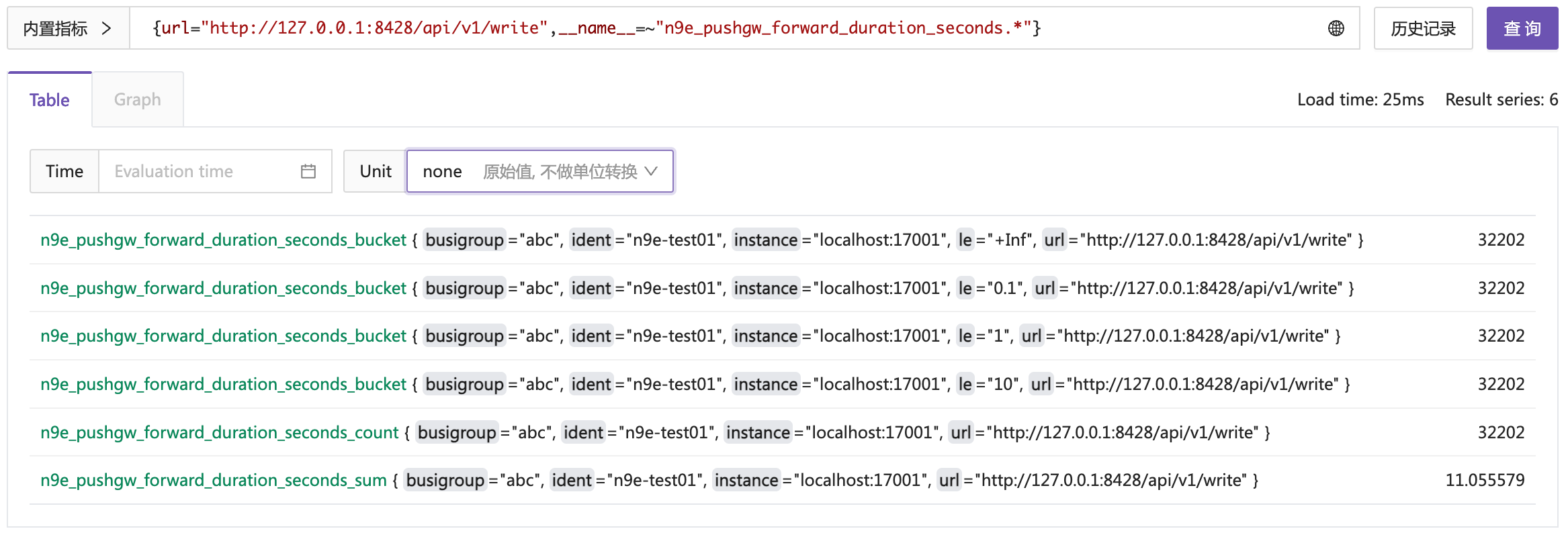
n9e_pushgw_forward_duration_seconds 作为前缀的指标有 6 个,分别是:
- 以
_count结尾的指标,表示总的请求量,上例中这个值是 32202,表示 n9e-pushgw 的 forward 动作共计执行了 32202 次 - 以
_sum结尾的指标,表示总的耗时,上例中是 11.055579,表示 n9e-pushgw 的 forward 动作总耗时是 11.055579 秒 - 以
_bucket结尾的指标,表示不同延迟区间的请求数量,上例中有 4 个 bucket,分别是 0.1、1、10、+Inf,表示 0.1 秒内的请求数量、1 秒内的请求数量、10 秒内的请求数量、+Inf 无穷大秒内的请求总数量,+Inf 这个 bucket 的值一定和_count是一样的
上例中各个 bucket 的值都是 32202,是因为 bucket 的划分不合理,划分的过大了,应该增加 less than 0.01 秒这样的区间才有意义。仅就上例而言,传递的信息是:所有的 forward 请求都很快,全部是在 0.1 秒内返回的。所以 le=0.1 的 bucket 的值是 32202,而因为 le=1 的 bucket 是 le=0.1 的超集,所以既然 le=0.1 的 bucket 的值是 32202,那么 le=1 的 bucket 的值也是 32202。le=10 的 bucket 也是一样,因为 le=10 是 le=1 的超集,所以 le=10 的 bucket 的值也是 32202。而 le=+Inf 的 bucket 的值也是 32202,因为 le=+Inf 是全集。
后文会介绍 histogram_quantile 函数,届时会对 Histogram 类型的数据有更详细的介绍。
Summary
Summary 和 Histogram 类似,主要用于描述请求总量、延迟总量、不同的分位数据等。Histogram 也可以计算分位值,Summary 也可以计算分位值,二者有何区别?最核心的点是:Histogram 可以在服务端计算某个服务的所有数据的分位值,Summary 只能在客户端计算某个特定实例颗粒度的分位值。
14 年左右的时候,当时在小米写 Open-Falcon,业务研发就搞了一个 SDK,专门计算各个接口的 Performance 数据,SDK 会内嵌在各个程序里,记录最近一段时间的请求数据,计算 50 分位、99 分位的延迟,回头来看,就相当于 Prometheus 的 Summary 数据。既然是在 SDK 里做的,那这个 Summary 的数据范围,就是实例颗粒度的,某个服务假设部署了 3 个实例,通过 Summary 数据是没法拿到整个服务全局的 99 分位延迟的,只能分别拿到各个实例各自的数据。
类型小结
虽然 Prometheus 有四种基本数据类型,但是在实际使用中,用的最多的是 Gauge 和 Counter 两种类型,作为初学者,即便现在你不理解 Histogram 和 Summary,也不要紧,后面见多了,听多了就懂了。
关于类型,你可能不知道的是
实际上,Prometheus 服务端时序库在存储指标的时候,是不区分类型的,比如我作为 client,可以通过 remote write 协议把监控数据推给 Prometheus 服务端,remote write 的数据结构如下:
func Send(WriteRequest)
message WriteRequest {
repeated TimeSeries timeseries = 1;
// Cortex uses this field to determine the source of the write request.
// We reserve it to avoid any compatibility issues.
reserved 2;
// Prometheus uses this field to send metadata, but this is
// omitted from v1 of the spec as it is experimental.
reserved 3;
}
message TimeSeries {
repeated Label labels = 1;
repeated Sample samples = 2;
}
message Label {
string name = 1;
string value = 2;
}
message Sample {
double value = 1;
int64 timestamp = 2;
}
这个 protobuf 数据结构中根本就没有数据类型相关的信息,惊不惊喜意不意外?那既然 Prometheus 服务端时序库不区分数据类型,那数据类型的区分是不是就没有价值了呢?也不是,数据类型会用在两个地方:
- 客户端埋点的时候,提升便利性。比如客户端指定某个指标是 Histogram 类型的话,虽然在调用 SDK 方法的时候,仅仅调用了一个 Observe 方法,实际 SDK 会在底层自动计算多个指标出来。如果指标类型是 Gauge,SDK 就不会额外计算那些指标了。
- 使用 PromQL 查询的时候,其实隐式的告诉查询引擎数据类型。比如在 PromQL 语句中,你用 rate 函数计算某个指标的速率,Prometheus 就会自动识别这是一个 Counter 类型的指标,然后计算速率,自动处理数据 reset 的情况。那如果你用 rate 函数计算一个 Gauge 类型的指标会如何?Prometheus 的 TSDB 中没有数据类型的概念,所以看到 rate 函数,还是会把你传入的指标当做 Counter 类型来对待,发现数据不是单调递增的,就会认为数据发生了重置,导致最终的计算结果是没有意义的。所以,你要保证 rate 函数计算的指标是 Counter 类型的。
演示 Gauge 和 Counter 类型
了解了 Prometheus 的数据类型,下面我们来查询一下 Gauge 和 Counter 类型的数据,看看它们的特点。这俩类型最重要,也是基础。我们之前的例子,使用的 cpu_usage_active 指标,表示 CPU 使用率,这个指标就是 Gauge 类型:
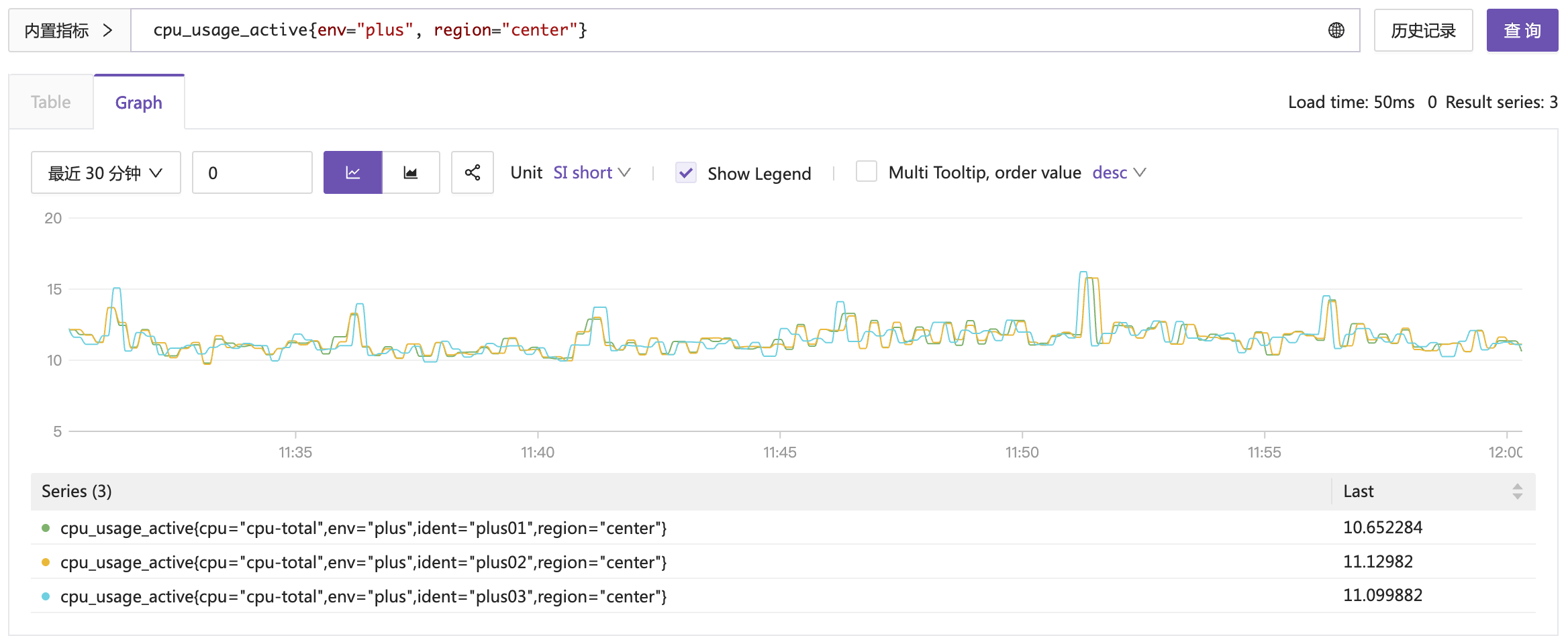
这个指标的特点是上下波动,可大可小。我们尤其关注其当前值,当然,也关注其历史变化趋势。下面我们再来看一个 Counter 类型的指标,比如 net_bits_recv,表示网卡收到的 bit 总量:
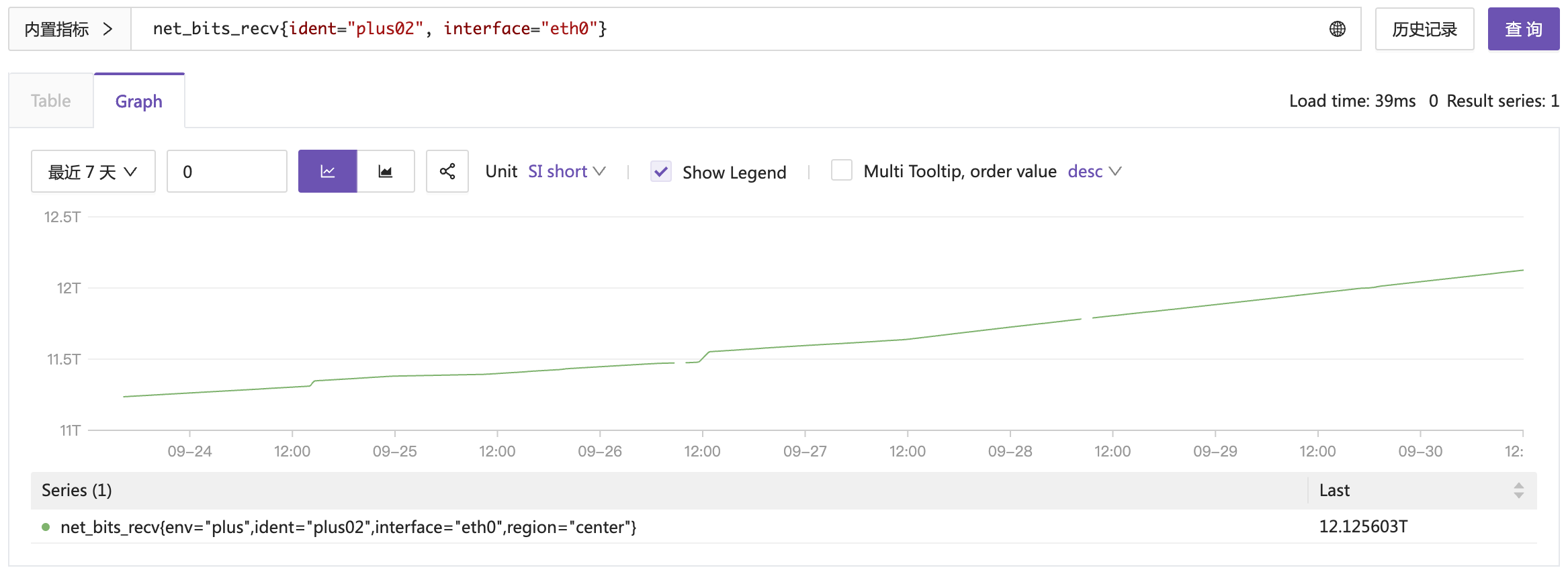
Counter 类型的数据,就是一直单调递增的,除非 OS 重启。一般 Counter 类型的数据,我们不关注当前这个巨大的值,没啥意义,而是关注变化率,即每秒收到多少 bit,这个才是我们关注的。使用 Counter 原始数据计算出变化率,就是我们常说的 rate 函数。
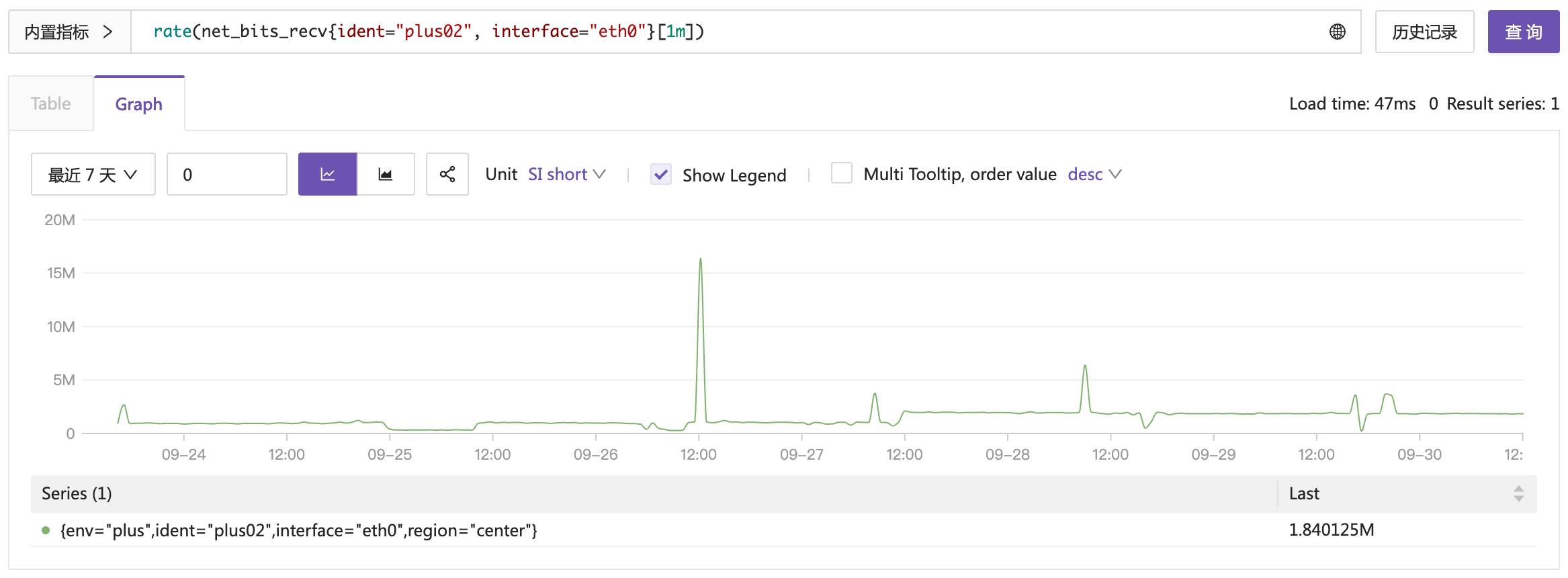
这就有波动,有价值了,从图上可以清晰看到,12:00 左右流量有个突增,其他时间流量都比较小。rate 函数接收 range-vector 类型的参数,什么叫 range-vector?可以参考上一篇PromQL教程(一)初识 PromQL。
小结
本文讲解了 Prometheus 的数据类型,主要有四种:Gauge、Counter、Histogram 和 Summary。这些知识是学习 PromQL 的必备知识,笔者尽量用浅显易懂的语言来讲解,希望对你有帮助。如果对 PromQL 教程系列的内容感兴趣,欢迎持续关注。



