
最佳实践:可观测性三支柱?远不止此!
日志,指标和分布式链路追踪这三个可观测性的传统支柱,已经是过时的,过于关注数据采集和底层数据格式,而不去关注结果(我们建设可观测性的初心和目标),这个做法实在是滑天下之大稽。by Martin Mao
Gartner 把“可观测性”定义为“监控”的巨大革新,可观测性提供了数字化业务应用、创新速度、客户体验提升方面的洞察能力。如今,DevOps 运动和云原生架构使得企业数字化业务变得更具竞争力,这需要更牛逼的可观测性体系的支持。
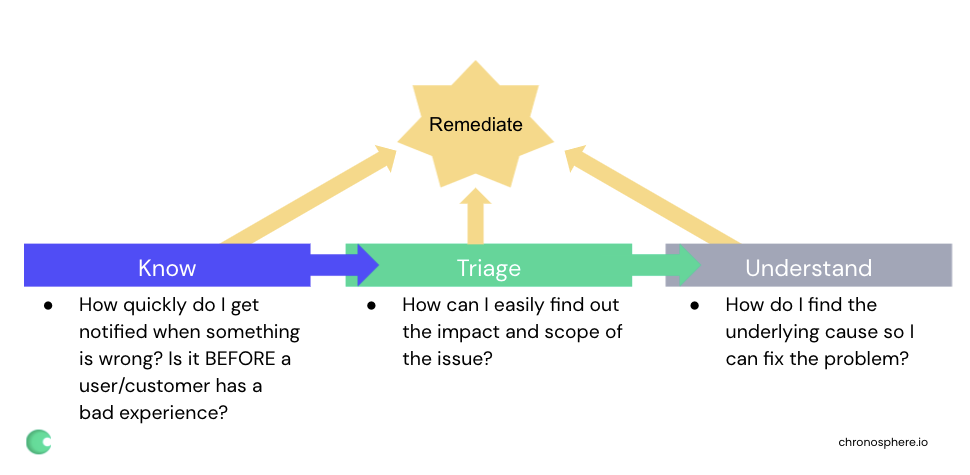
在 DevOps 出现之前,研发工程师很少需要考虑如何运维他们构建的系统。现在,研发工程师需要考虑构建更易于观测的系统。为了更好的理解可观测性对结果的影响,工程师应该考虑以下三个关键问题:
- 1.当系统出故障时,如何才能让我尽快收到通知?是在用户/客户体验受损之前吗?
- 2.如何才能简单、快速地揪出故障点,圈定影响范围?
- 3.如何才能找到直接原因并快速止损?
无论使用什么采集方法和工具,可观测性体系最应该着重建设的,就是回答以上三个问题的能力。
可观测性不是什么
如今,有很多人将可观测性定义为一组数据类型的集合——即三个支柱:日志、指标和分布式链路追踪。对于落地可观测性而言,这种孤立的方法过于关注数据采集和底层数据格式,反而忽略了最终结果(我们建设可观测性的初心和目标)。
简单的采集系统中这三种数据并不能保证有更好的结果。反而,很多公司发现:可观测性数据量和这些数据衍生的价值之间关联甚微,并非可观测性数据量越大产生的价值就越大。
可观测性的3个阶段
我们不是第一个对三支柱提出异议的人。像Charity Majors(可观测性具备多方面定义) 和Ben Sigelman(揭穿“可观测性的三支柱”神话) 所提出的大部分批判我们也是认同的。我们开发了一种落地可观测性的新方法,注重结果而非注重输入,替代可观测性的三支柱,我们称之为“三阶段”方法。“三阶段”重点关注如何实现积极的可观测性结果,以及如何让团队一步一步达成可观测性目标。
日志,指标和分布式链路追踪这三个可观测性的传统支柱,已经是过时的,过于关注数据采集和底层数据格式,而不去关注结果(我们建设可观测性的初心和目标)。
每个阶段的重点都是为了尽快地降低对客户的影响或修复故障(即:止损)。止损是拯救客户体验和恢复服务 Service Level 的动作。在每个阶段,工程师都在寻找足够的信息来止损,即使他们尚未定位到根因。
译者注:做过 SRE 的兄弟肯定清楚,大部分情况下,『止损』只需要知道直接原因就够了,不需要知道根因,根因可以在复盘阶段再去梳理。举个例子,某个故障是变更引起的,变更本身就是直接原因,止损手段就是回滚,根本原因可能是这次变更引入的代码Bug,但具体是什么Bug在止损阶段不需要知道。
第一阶段:定故障
知道故障正在发生,有时就可以止损了(不需要更多信息)。比如,你升级了某个服务,然后,这个服务告警了,想都不用想,回滚这个变更就是最快的止损手段,不需要先去确认故障影响面、故障根因。变更是万恶之源,生产事故有一大半都是变更引起的,当你在做变更的时候,时刻掌握服务的健康状况就异常关键。
成功的关键:
- 快速报警:缩短问题发生和发出通知之间的时间。
- 将通知范围限定在需要采取行动的团队内:从一开始就限定问题的范围,并将其指派给相关的团队。
- 提高降噪比:确保每一个警报都有对应的操作预案。
- 自动化告警配置:自动化或模板化的告警配置可以帮助工程师无需投入巨大精力来完成复杂配置就可以收到警报。
工具和数据:
- 告警
- 指标(原生指标以及从日志和链路追踪生成的指标)
第二阶段:定边界
了解故障范围有助于止损。例如,如果你确认只有一个实验组的客户影响,则关闭该实验特性可能就会解决问题。
为了帮助工程师做故障定界,需要把告警快速置于上下文环境中来分析,了解有多少客户受影响、有多少系统受影响,以及影响程度如何。好的可观测性系统,以数据驱动工程师的排查过程,将焦点放在场景化数据上以诊断故障。
成功的关键:
- 上下文信息仪表盘:告警直接链到仪表盘,显示告警相关的原始数据,以及相关的上下文数据(译者注:只链到仪表盘其实不够,还应该链到相关的日志、trace、事件等)。
- 多维度的数据分析:允许工程师根据不同的维度对数据进行分析,以进一步缩小问题范围。
- 充分利用现有埋点数据:假设每次都有完美的数据埋点是不可能的,所以充分利用既有的数据非常关键,但需要尽可能按照场景化的方式来串联数据。
工具和数据:
- 仪表盘
- 指标
- 日志
第三阶段:定原因
想要分析问题的原因,就需要找到相关服务的 owner 一起配合,但是服务的依赖关系错综复杂,想要找到服务依赖链路上的所有 owner 并不容易。
好的可观测性实践,可以给工程师一个更直观的视角,揪出那些引起指标异常的罪魁祸首。另外,它也提供了修复底层问题的洞见,以避免事故再次发生。
成功的关键:
- 易于理解服务依赖拓扑关系:对于当前正在故障的服务,快速圈定其上下游依赖。
- 在不同的工具和数据之间串联跳转的能力:对于复杂的故障,您需要在日志、链路、指标之间反复跳转,理想的情况是在一个单一的工具中完成。
- 确定根因的时间:有时候无法避免在故障期间做根因分析,而在这些情况下,通过在告警通知或仪表板上显示出可能的故障原因,可以减少确定根因的时间。
工具和数据:
- 链路追踪
- 日志
- 指标
- 仪表盘
结论
优秀的可观测性可以带来竞争优势、世界一流的客户体验、更快的创新和研发人员的幸福感。但是,仅仅关注于输入和数据(三支柱),组织是无法做到优秀的可观测性的。通过专注于本文提到的『三阶段』以及面向结果的方式,团队就有望落地优秀的可观测性实践!
本文翻译自:https://thenewstack.io/beyond-the-3-pillars-of-observability/,国内来看,Martin Mao 的这个理念和快猫的理念如出一辙,如果您也需要这类面向结果的新式可观测性系统,可以了解一下快猫的产品。



