
前言
对于数据库、中间件的监控,目前社区里最为完善的就是 Prometheus 生态的各个 Exporter,不过这些 Exporter 比较分散,不好管理,如果有很多目标实例需要监控,就要部署很多个 Exporter,要是能有一个大一统的 Exporter,具备所有这些 Exporter 的能力就好了。还真有,而且还不止一个,一个是 Grafana-agent,一个是 Cprobe,Grafana-agent 整合这些 Exporter 相对比较生硬而且缺少了目标实例自动发现机制,好处是 Grafana-agent 不止是整合了常见的 Exporter,还整合了 Promtail 和 OTEL Collector,也可以用于日志和链路数据的采集转发,Cprobe 整合 Exporter 的方式相对更为丝滑且一致性更好,支持目标实例的自动发现机制,专注在指标采集方向,不提供日志采集和链路数据转发能力,两个项目都是开源的,大家根据自己的需求选择。
本专栏专注如何构建生产级监控系统,侧重指标监控领域,选择 Cprobe 作为采集器。下面我们对 Cprobe 的通用配置做简要说明。
本文要接入哪些中间件
本文是专栏第二篇,重点不是展开每个中间件的指标含义,而是演示如何快速接入常见数据库和中间件监控,并把指标送到前一篇搭建好的时序库、仪表盘和告警链路里。
| 对象 | Cprobe 插件目录 | 主要配置关注点 | 验证方式 |
|---|---|---|---|
| MySQL | conf.d/mysql |
多实例、认证信息、rule toml 拆分 | ./cprobe --no-writer --no-httpd --plugins mysql |
| Redis | conf.d/redis |
Redis target 和采集规则 | ./cprobe --no-writer --no-httpd --plugins redis |
| MongoDB | conf.d/mongodb |
target 和可选认证信息 | ./cprobe --no-writer --no-httpd --plugins mongodb |
| Oracle | conf.d/oracledb |
target 需要 IP、端口和 service | ./cprobe --no-writer --no-httpd --plugins oracledb |
| Postgres | conf.d/postgres |
Postgres target 和 rule 配置 | ./cprobe --no-writer --no-httpd --plugins postgres |
| Tomcat | conf.d/tomcat |
tomcat-users.xml 和 manager 访问限制 |
./cprobe --no-writer --no-httpd --plugins tomcat |
| Kafka | conf.d/kafka |
broker target 写法和 consumergroup lag | ./cprobe --no-writer --no-httpd --plugins kafka |
| ElasticSearch | conf.d/elasticsearch |
ElasticSearch target 和 rule 配置 | ./cprobe --no-writer --no-httpd --plugins elasticsearch |
整体流程是一致的:配置 main.yaml,按需配置认证或采集规则,先用 --no-writer --no-httpd 本地验证指标输出,再检查 writer.yaml 的 remote write 地址,最后重启 Cprobe 并在时序库、Grafana 和 Flashduty 中验证。
Cprobe 简介
Cprobe 的 README 中已经放置了相关文档链接,不多总共三四篇,请各位自行阅读,这里就不再赘述了。安装的话,可以采用二进制方式、容器方式、Kubernetes 方式,安装文档在这里:https://github.com/cprobe/cprobe/issues/5,每种安装方式基本就是一条命令的事,简单的很。
Cprobe 的配置文件在 conf.d 目录下,writer.yaml 配置时序库的 remote write 地址,Cprobe 采集了数据之后通过 remote write 协议发送指标数据给时序库。conf.d 下面有不少目录,每个目录对应一个采集插件,每个采集插件的目录下通常都会有一个 main.yaml 的入口配置,main.yaml 中配置要采集的监控目标的地址,当然,也可以不写死目标实例的地址,而是通过 HTTP SD 或 File SD 的方式动态发现监控目标。其次,main.yaml 中一般会有 scrape_rule_files 配置项,配置各个 job 的采集规则,这是个数组,程序处理时会把数组里的每个规则文件拼接成一个整体来使用,即:通过这种方式可以实现配置文件拆分管理。举例:
global:
scrape_interval: 15s
external_labels:
cplugin: 'mysql'
scrape_configs:
- job_name: 'mysql_static'
static_configs:
- targets:
- '127.0.0.1:3306'
scrape_rule_files:
- 'rule_head.toml'
- 'rule_coll.toml'
- job_name: 'mysql_http_sd'
http_sd_configs:
- url: http://localhost:8080/get-targets
scrape_rule_files:
- 'rule_head.toml'
- 'rule_coll.toml'
- job_name: 'mysql_file_sd'
file_sd_configs:
- files:
- 'inst.yaml'
scrape_rule_files:
- 'rule_head.toml'
- 'rule_coll.toml'
- 'rule_cust.toml'
另外,每个插件目录下通常有个 doc/README.md 文件,里面会有该插件的详细说明,并且会有插件对应的仪表盘和告警规则的模板。OK,下面我们就来看看如何配置 Cprobe 来监控常见的数据库、中间件。
生产环境里,不建议每个实例都手工维护一份静态配置。目标实例较多时,优先考虑 HTTP SD 或 File SD,把实例发现、认证信息、标签和规则拆分管理,避免配置文件失控。
MySQL
MySQL 的监控插件配置在 conf.d/mysql 目录下,我给大家演示一下监控 3 个 MySQL 实例的配置,首先是 main.yaml:
global:
scrape_interval: 15s
external_labels:
cplugin: 'mysql'
scrape_configs:
- job_name: 'mysql_dept1'
static_configs:
- targets:
- '10.99.1.107:3306'
- '10.99.1.108:3306'
scrape_rule_files:
- 'rule_head1.toml'
- 'rule_coll.toml'
- job_name: 'mysql_dept2'
static_configs:
- targets:
- '10.99.1.109:3306'
scrape_rule_files:
- 'rule_head2.toml'
- 'rule_coll.toml'
上面的配置文件可以看出,总共监控了 3 个实例,分成两个 job,之所以分成两个 job 是因为这两组数据库实例的认证信息不同,所以需要分开配置,mysql_dept1 这个 job 引用了 rule_head1.toml,而 mysql_dept2 这个 job 引用的是 rule_head2.toml,这俩 rule toml 文件中配置的是认证信息,比如 rule_head1.toml 的内容是:
[global]
user = 'cprobe'
password = 'cProbePa55'
上面只是为了演示,所以这么划分 job 和 认证信息,实际上,用于监控的账号,最好是全局统一的只读账号,方便管理,而 job 的划分依据,主要是 SD 的方式,不同的 SD 不同的 job。
通过 ./cprobe --no-writer --no-httpd --plugins mysql 可以测试一下采集是否成功,正常来讲,会输出一堆 mysql 指标,然后我们检查 writer.yaml 中的 remote write 地址是否正确,然后重启 Cprobe,就可以在时序库中看到 MySQL 的指标了。另外你可以从下面地址获取 MySQL 仪表盘:
https://github.com/cprobe/cprobe/blob/main/conf.d/mysql/doc/dash/grafana_mysql_01.json
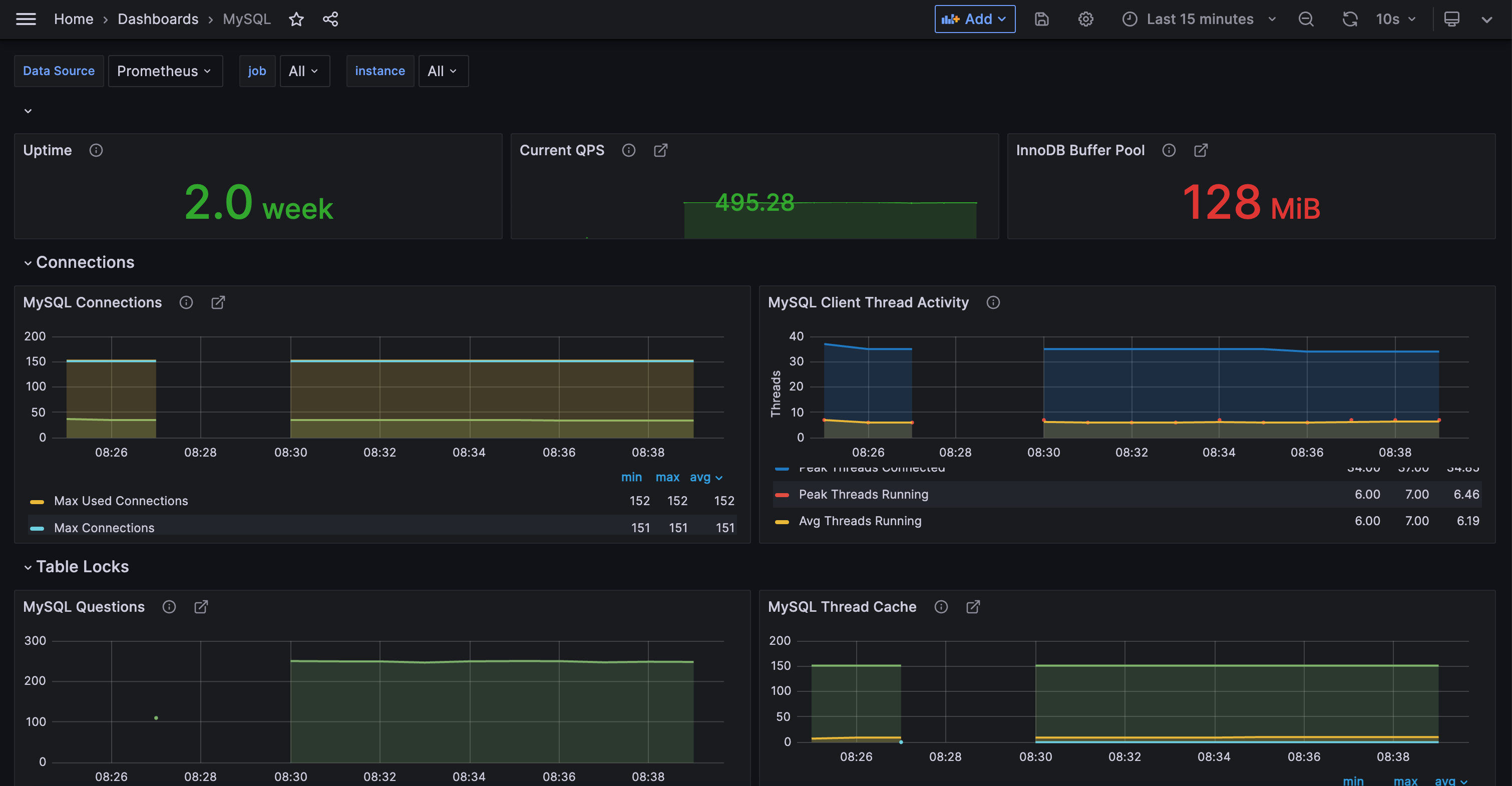
对于常用的数据库、中间件,Flashduty 已经提供了一些常用的告警规则,导入即可使用:

Flashduty 在专栏第一篇已经介绍过,主要是一个事件 OnCall 中心,可以接入各种监控系统,把告警事件收集到一个地方统一管理,提供告警多渠道分发、收敛降噪、排班、认领升级、协同等能力,新版本还内置了告警引擎,可以对时序库中的数据做告警判定,内置各类常用的告警规则模板,总之,告警这个事,交给 Flashduty 就好了。我们只需要做好数据采集(Cprobe等各类采集器)、存储(VictoriaMetrics等时序库)、展示(Grafana等可视化工具)这些事情就行了。
Redis
Redis 的监控插件配置在 conf.d/redis 目录下,main.yaml 举例如下:
global:
scrape_interval: 15s
external_labels:
cplugin: 'redis'
scrape_configs:
- job_name: 'redis'
static_configs:
- targets:
- '10.99.1.107:6379'
scrape_rule_files:
- 'rule.toml'
通过 ./cprobe --no-writer --no-httpd --plugins redis 可以测试一下采集是否成功,正常来讲,会输出一堆 Redis 指标,Redis 的仪表盘可以从这里获取(或者自行从 Grafana 官网搜索别人分享的仪表盘):
https://github.com/cprobe/cprobe/blob/main/conf.d/redis/doc/dash/grafana_redis_01.json
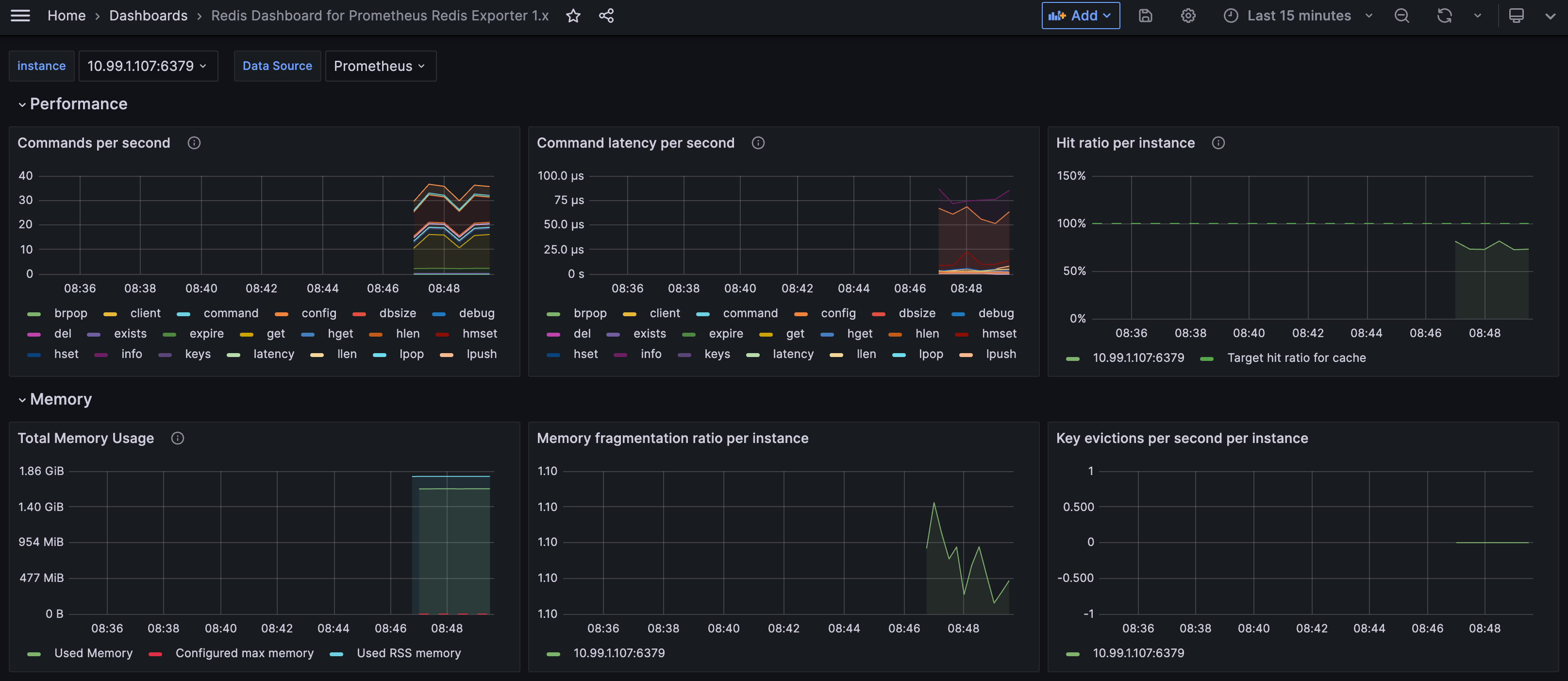
Redis 的告警规则,Flashduty 也已经内置了,使用 Flashduty 做告警和事件分发即可,这里不再赘述。
MongoDB
MongoDB 的监控插件配置在 conf.d/mongodb 目录下,main.yaml 举例如下:
global:
scrape_interval: 15s
external_labels:
cplugin: 'mongodb'
scrape_configs:
- job_name: 'standalone'
static_configs:
- targets:
- 10.99.1.110:27017
scrape_rule_files:
- 'rule.toml'
如果有认证信息,可以在 conf.d/mongodb/rule.toml 中配置,通过 ./cprobe --no-writer --no-httpd --plugins mongodb 可以测试一下采集是否成功,正常来讲,会输出一堆 MongoDB 指标,之后重启 Cprobe 即可。MongoDB 的仪表盘可以从这里获取(或者自行从 Grafana 官网搜索别人分享的仪表盘):
https://github.com/cprobe/cprobe/blob/main/conf.d/mongodb/doc/dash/grafana_mongodb_01.json
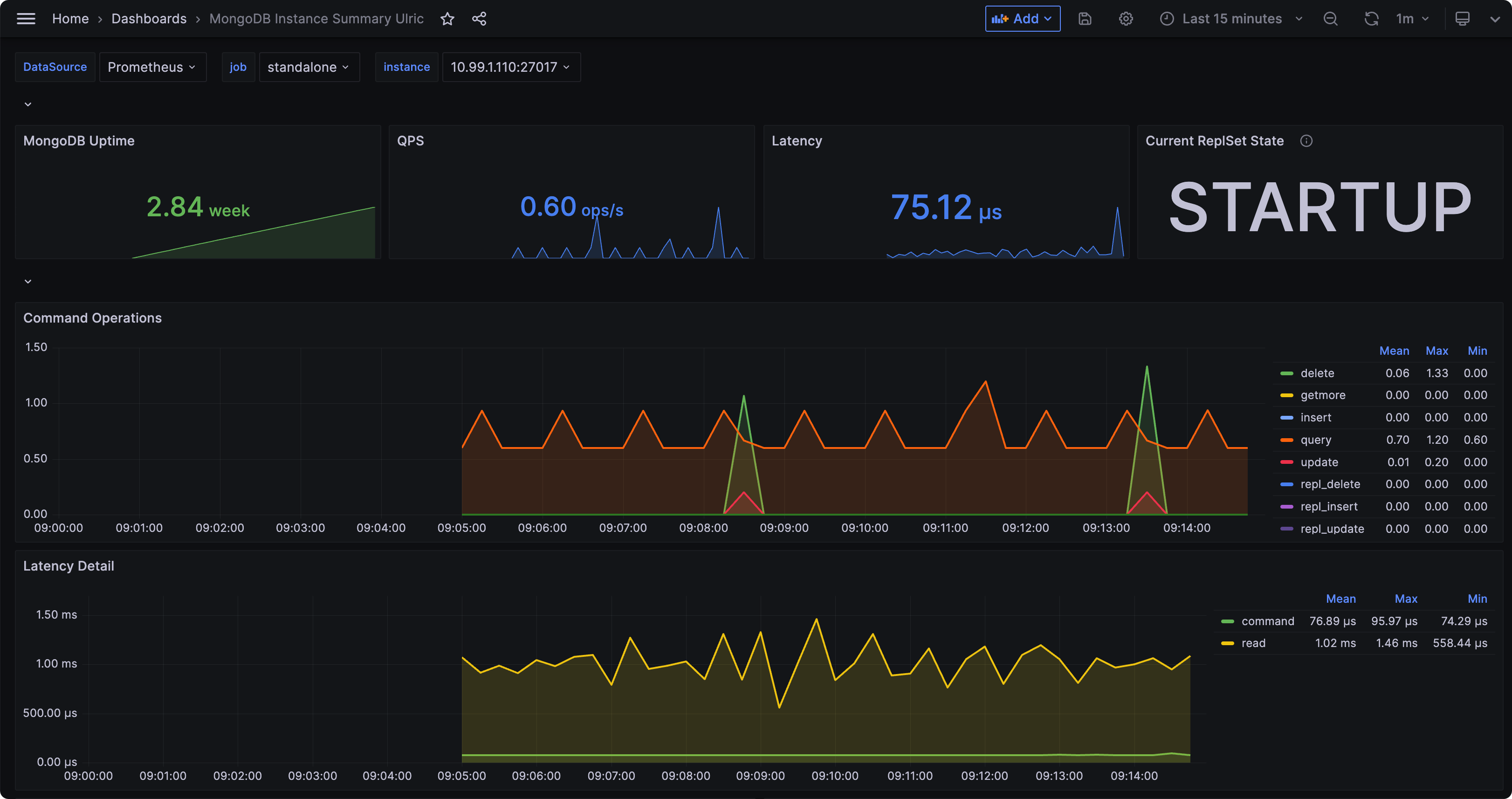
MongoDB 的告警规则,Flashduty 也已经内置了,使用 Flashduty 做告警和事件分发即可,这里不再赘述。
Oracle
Oracle 的监控插件配置在 conf.d/oracledb 目录下,main.yaml 举例如下:
global:
scrape_interval: 15s
external_labels:
cplugin: 'oracle'
scrape_configs:
- job_name: 'oracle'
static_configs:
- targets:
- 10.99.1.107:1521/xe # ip:port/service
scrape_rule_files:
- 'link.toml'
- 'comm.toml'
一般监控目标,即 target 的配置都是 IP + 端口,Oracle 的略有不同,需要配置成 IP + 端口 + service,通过 ./cprobe --no-writer --no-httpd --plugins oracledb 可以测试一下采集是否成功,正常来讲,会输出一堆 Oracle 指标,之后重启 Cprobe 即可。Oracle 的仪表盘可以从这里获取(或者自行从 Grafana 官网搜索别人分享的仪表盘):
https://github.com/cprobe/cprobe/blob/main/conf.d/oracledb/doc/dash/grafana_oracledb_01.json
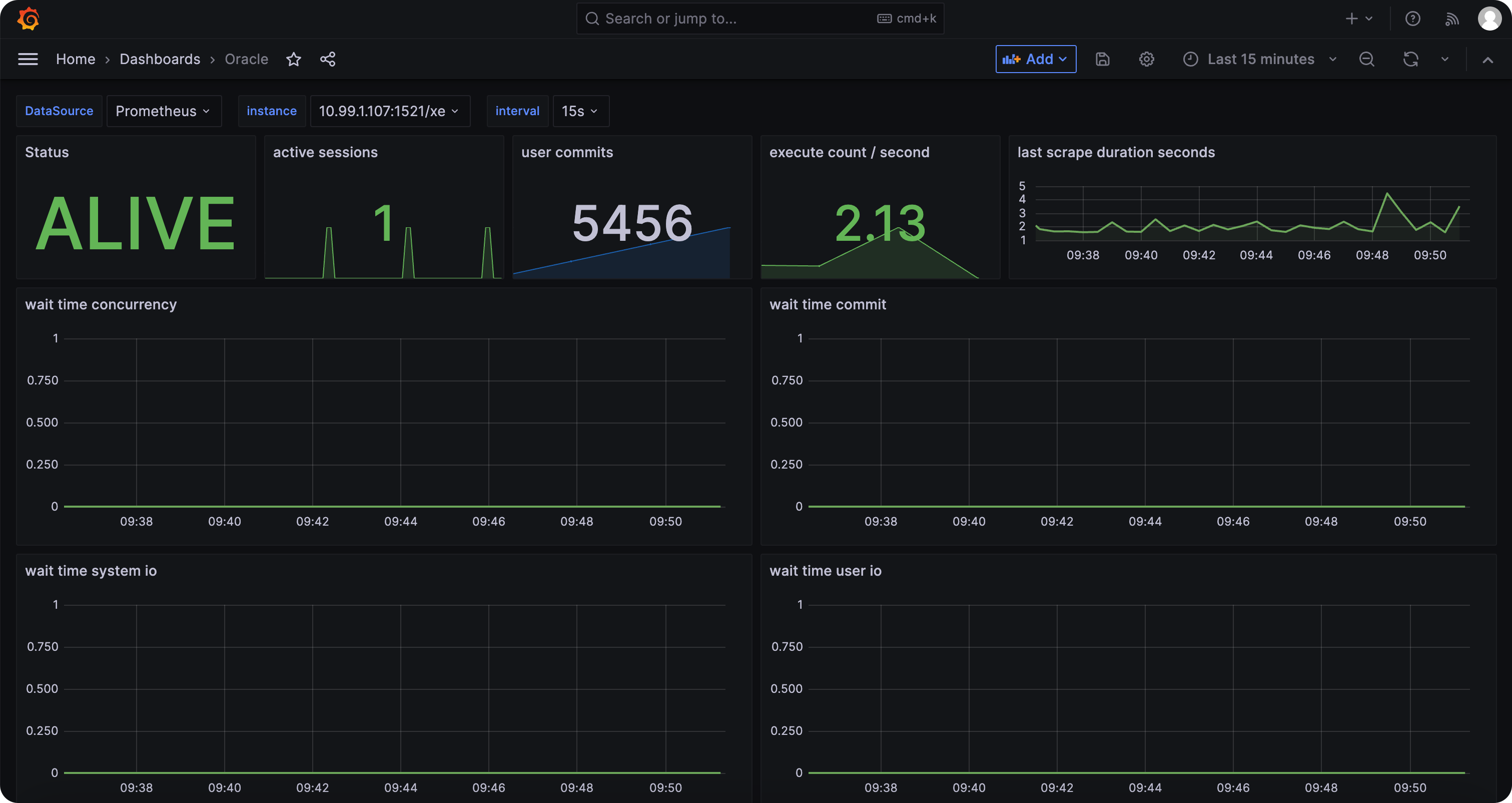
Oracle 的告警规则,Flashduty 也已经内置了,使用 Flashduty 做告警和事件分发即可,这里不再赘述。
Postgres
Postgres 的监控插件配置在 conf.d/postgres 目录下,main.yaml 举例如下:
global:
scrape_interval: 15s
external_labels:
cplugin: 'postgres'
scrape_configs:
- job_name: 'postgres'
static_configs:
- targets:
- '10.99.1.107:15432'
scrape_rule_files:
- 'rule.toml'
通过 ./cprobe --no-writer --no-httpd --plugins postgres 可以测试一下采集是否成功,正常来讲,会输出一堆 Postgres 指标,之后重启 Cprobe 即可。Postgres 的仪表盘可以从这里获取(或者自行从 Grafana 官网搜索别人分享的仪表盘):
https://github.com/cprobe/cprobe/blob/main/conf.d/postgres/doc/dash/grafana_postgres_01.json
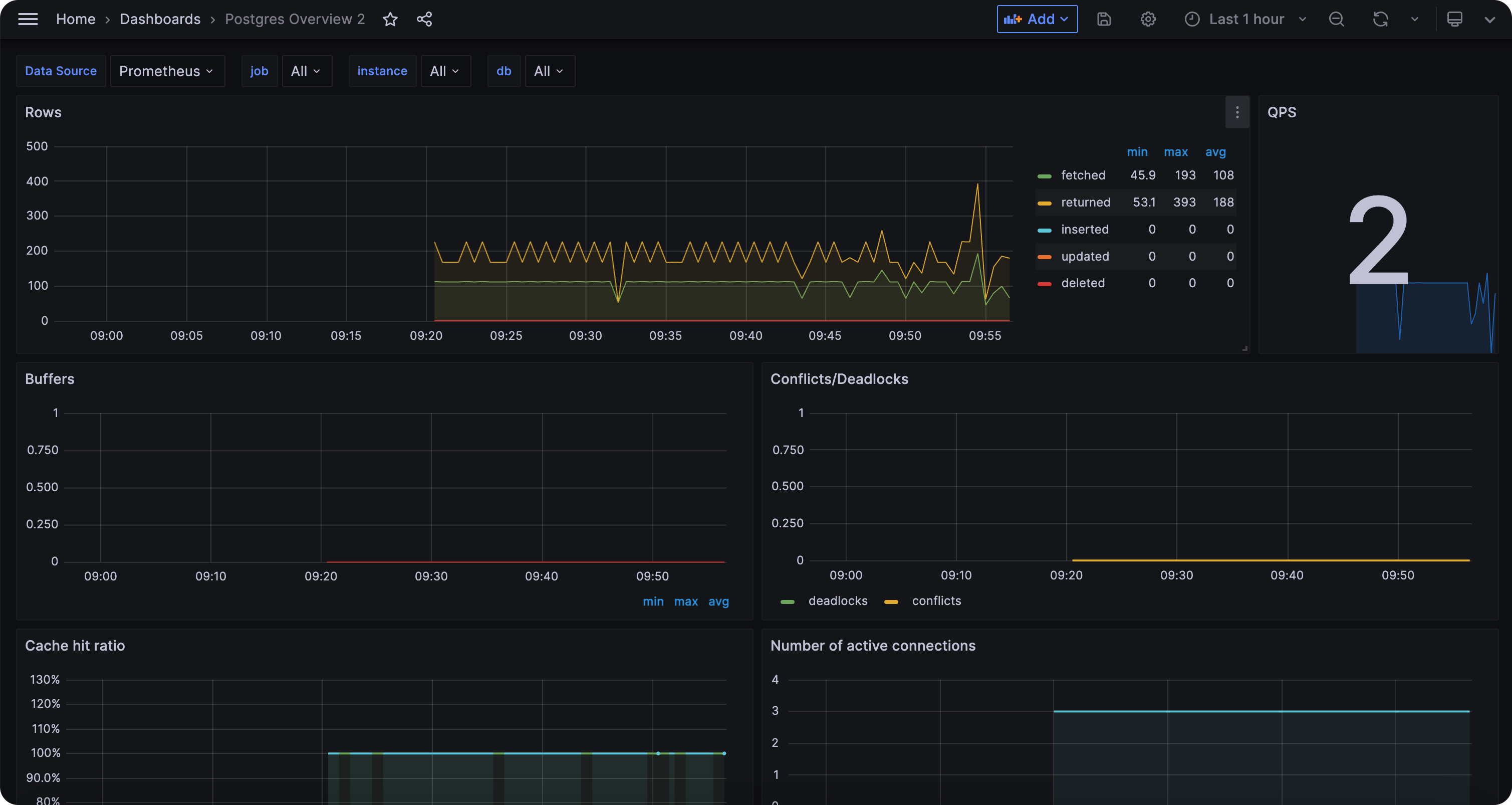
Postgres 的告警规则,Flashduty 也已经内置了,使用 Flashduty 做告警和事件分发即可,这里不再赘述。
Tomcat
Tomcat 的监控插件配置在 conf.d/tomcat 目录下,main.yaml 举例如下:
global:
scrape_interval: 15s
external_labels:
cplugin: 'tomcat'
scrape_configs:
- job_name: 'tomcat'
static_configs:
- targets:
- '10.211.55.3:8080'
scrape_rule_files:
- 'rule.toml'
注意,Tomcat 监控需要修改 conf/tomcat-users.xml 配置,增加 role 和 user,比如:
<tomcat-users xmlns="http://tomcat.apache.org/xml"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://tomcat.apache.org/xml tomcat-users.xsd"
version="1.0">
<role rolename="manager-gui"/>
<user username="tomcat" password="s3cret" roles="manager-gui"/>
</tomcat-users>
其次,通常 cprobe 和 tomcat 部署在不同的机器上,需要修改 webapps/manager/META-INF/context.xml 配置,把下面的部分注释掉:
<Valve className="org.apache.catalina.valves.RemoteAddrValve"
allow="127\.\d+\.\d+\.\d+|::1|0:0:0:0:0:0:0:1" />
xml 的注释使用 <!-- -->,所以,最终注释之后变成:
<!--
<Valve className="org.apache.catalina.valves.RemoteAddrValve"
allow="127\.\d+\.\d+\.\d+|::1|0:0:0:0:0:0:0:1" />
-->
然后修改 tomcat 的 rule.toml,写上认证信息,即可测试:./cprobe --no-writer --no-httpd --plugins tomcat。Tomcat 的仪表盘暂未整理,欢迎大家贡献 PR 呀。Tomcat 的告警规则,Flashduty 也已经内置了,使用 Flashduty 做告警和事件分发即可,这里不再赘述。
Kafka
Kafka 的众多指标是通过 jmx 的方式暴露的,所以,在 Kafka 启动的 shell 里通过 -javaagent 埋入 prometheus_jmx_agent.jar,就可以暴露 Prometheus 协议的监控数据了,使用 Cprobe 的 Prometheus 插件来抓即可。但是 Cprobe 还是提供了一个专门的 Kafka 插件,用于抓取 consumergroup 的 lag 信息,配置文件在 conf.d/kafka 目录下,main.yaml 内容举例:
global:
scrape_interval: 15s
external_labels:
cplugin: 'kafka'
scrape_configs:
- job_name: 'kafka'
static_configs:
- targets:
- '10.99.1.105:9092'
scrape_rule_files:
- 'rule.toml'
如果是监控集群,想要写多个实例,Kafka 的 target 写法跟其他的 plugin 会有不同,举例:
global:
scrape_interval: 15s
external_labels:
cplugin: 'kafka'
scrape_configs:
- job_name: 'kafka'
static_configs:
- targets:
- '172.21.0.162:9092,172.21.0.163:9092,172.21.0.164:9092'
scrape_rule_files:
- 'rule.toml'
和 mysql 插件对比一下,应该可以看出差别吧?你知道为啥会有这样的不同设计么?欢迎在评论区留言探讨 :-)
通过 ./cprobe --no-writer --no-httpd --plugins kafka 可以测试一下采集是否成功,正常来讲,会输出一堆 Kafka 指标,之后重启 Cprobe 即可。Kafka 的仪表盘可以从这里获取(或者自行从 Grafana 官网搜索别人分享的仪表盘):
https://github.com/cprobe/cprobe/blob/main/conf.d/kafka/doc/dash/grafana_kafka_01.json
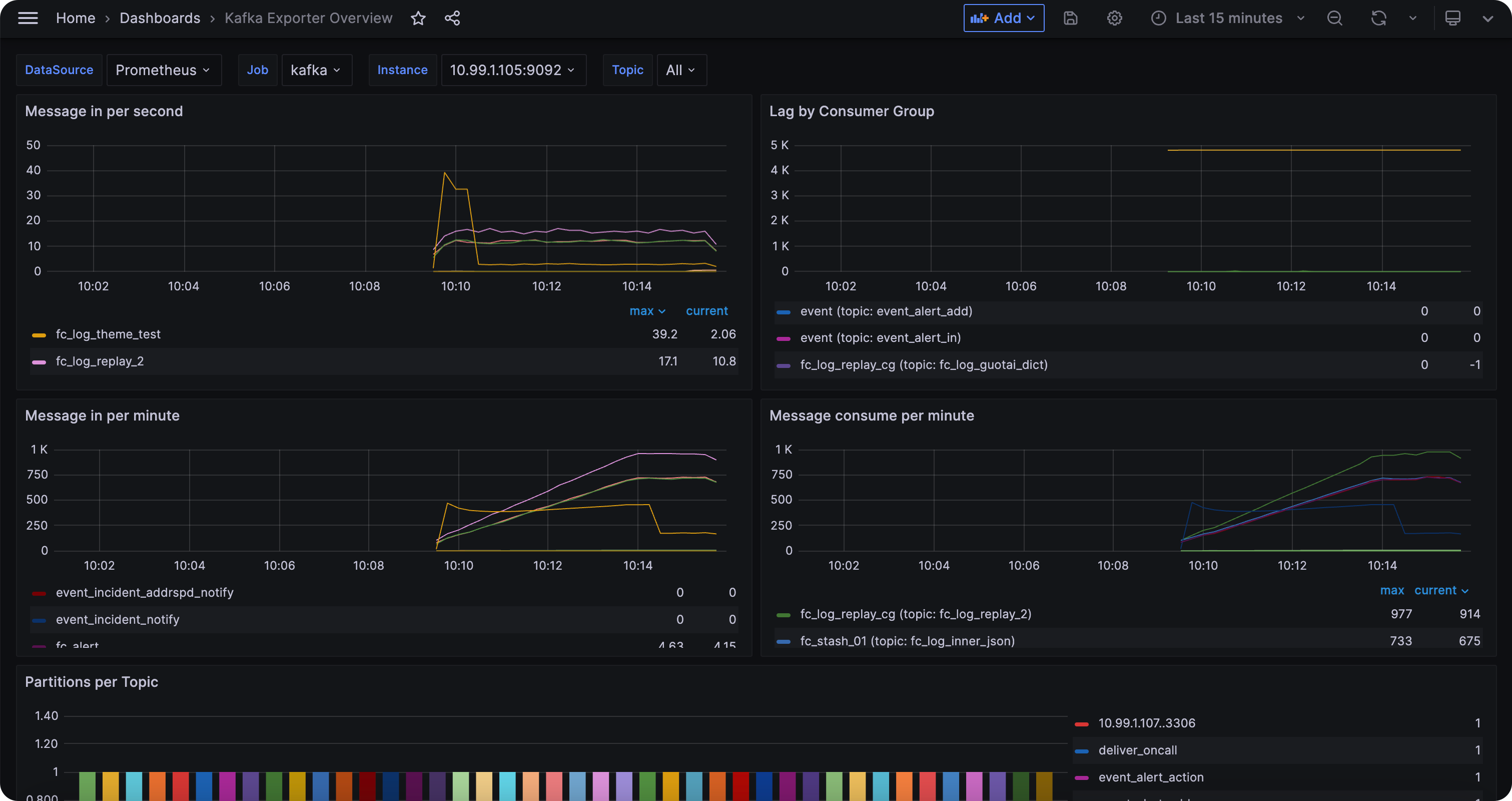
Kafka 的告警规则,Flashduty 也已经内置了,使用 Flashduty 做告警和事件分发即可,这里不再赘述。
ElasticSearch
ElasticSearch 的监控插件配置在 conf.d/elasticsearch 目录下,main.yaml 举例如下:
global:
scrape_interval: 15s
external_labels:
cplugin: 'elasticsearch'
scrape_configs:
- job_name: 'elasticsearch'
static_configs:
- targets:
- 10.99.1.105:9200
scrape_rule_files:
- 'rule.toml'
通过 ./cprobe --no-writer --no-httpd --plugins elasticsearch 可以测试一下采集是否成功,正常来讲,会输出一堆 ElasticSearch 指标,之后重启 Cprobe 即可。ElasticSearch 的仪表盘可以从这里获取(或者自行从 Grafana 官网搜索别人分享的仪表盘):
https://github.com/cprobe/cprobe/blob/main/conf.d/elasticsearch/doc/dash/grafana_elasticsearch_01.json
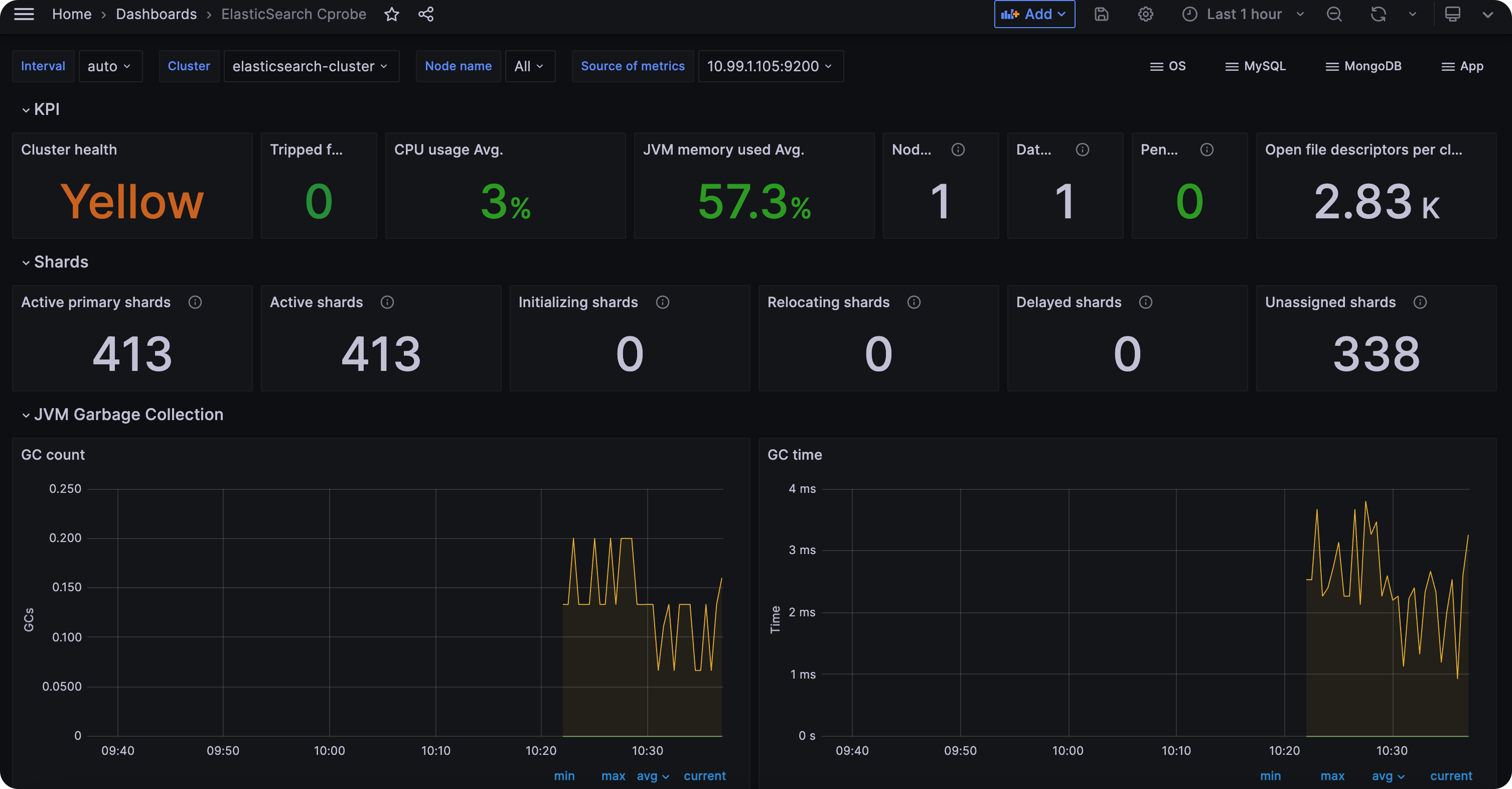
ElasticSearch 的告警规则,Flashduty 也已经内置了,使用 Flashduty 做告警和事件分发即可,这里不再赘述。
小结
作为专栏第二篇文章,本文大体介绍了常用中间件的采集方式。它们的共同点是:先找到对应插件目录,配置 target 和 rule,使用 --no-writer --no-httpd 验证采集,再通过 remote write 写入时序库,最后在 Grafana 和 Flashduty 中完成展示与告警。
FAQ
Cprobe 和单独部署各类 Exporter 有什么差别?
单独部署 Exporter 的生态更分散,目标实例多时管理成本较高。Cprobe 的价值在于把常见 Exporter 能力整合到统一采集器里,并提供更一致的配置方式和目标实例发现机制。
为什么示例里 MySQL 要拆成多个 job?
示例中的 MySQL 实例认证信息不同,所以拆成 mysql_dept1 和 mysql_dept2 两个 job,并分别引用不同的 rule_head 文件。实际生产里,监控账号最好尽量统一为只读账号,job 划分更多由服务发现方式决定。
每个中间件都必须配置 Grafana 仪表盘吗?
仪表盘不是采集成功的前置条件,但它是验证和排障的重要入口。本文给出的插件目录通常带有仪表盘模板,可以先导入模板,再按业务需要调整。
告警规则应该在哪里管理?
文中口径是 Flashduty 已经内置了常见数据库和中间件的告警规则,可以导入使用,并把告警事件统一交给 Flashduty 做分发、降噪、排班、认领和升级。
Cprobe 是一个挺有意思的工具,大家可以一起贡献 PR。我们下一讲再见。



