
SLICK: Facebook基于SLO的可靠性保障实践
定义服务的SLI和SLO,通过全局系统呈现、处理所有服务的SLI/SLO,从而帮助SRE实践在系统中的落地。本文介绍了Facebook(Meta)在这方面的实践。原文:SLICK: Adopting SLOs for improved reliability
我们需要与使用我们的应用程序和产品的人们和社区不断保持联系,从而为他们提供足够的支持。我们希望将可靠性方面的经验提供出来,与我们支持的更大的社区建立信任关系。在像Meta(Facebook的新名字)这样大规模、快速发展的环境中,有成千上万的工程师在频繁部署代码、创建特性原型,并对更改进行迭代,因此保障可靠性的工作尤其具有挑战性。我们需要对每个产品、功能和服务有明确的期望,从而可以更好的为使用我们服务的用户提供可视化的体验,并分析系统之间的任何瓶颈或复杂的交互。
我们开始研究服务水平指标(SLIs,service-level indicators)和服务水平目标(SLOs,service-level objectives),将其作为期望的设置,并根据这些期望度量服务的性能。为了提供工具支持,我们构建了SLICK,这可以看作是一个专门的SLO商店。有了SLICK,我们能够集中SLI和SLO定义,从而轻松找到和理解另一个服务的可靠性。SLICK可以利用高留存率,以及其他工具无法找到的关键服务指标的完整粒度数据,为服务开发团队提供洞见,并将SLO与公司的其他各种工作流集成起来,以确保SLO成为日常工作的一部分。
在SLICK出现之前,SLO和其他性能指标存储在定制的仪表板、文档或其他工具中。如果想要定位团队的SLO,可能需要花费一个小时的时间来搜索或要求人们找到相关的数据。此外,之前的系统并没有以完整的粒度长时间(超过几周)保留这些指标,这使得对SLO进行更长时间的分析几乎是不可能的。有了SLICK,我们现在能够:
- 以一致的方式为服务定义SLO
- 精度高达分钟级别的度量数据,最多可保留两年
- 对SLI/SLO指标有标准的可视化和洞见
- 定期向内部小组发送可靠性报告,允许团队基于这些报告进行可靠性检查
可发现性(Discoverability)
SLICK定义了一个标准的模型,帮助公司里的每个人用同样的术语讨论可靠性。这使得新的服务开发团队能够无缝遵循公司范围的标准,在服务的早期设计阶段就考虑到服务需要达到的可靠性期望。
只要知道服务名,SLICK就可以帮助我们定位特定服务的可靠性指标和性能数据。SLICK通过构建内置的服务索引来实现这一点,该索引链接到带有标准可视化的仪表板,以分析和评估服务的可靠性。因此,只需单击一下,就可以知道服务当前是否满足用户的期望,如果有任何问题,就可以马上开始寻找答案。
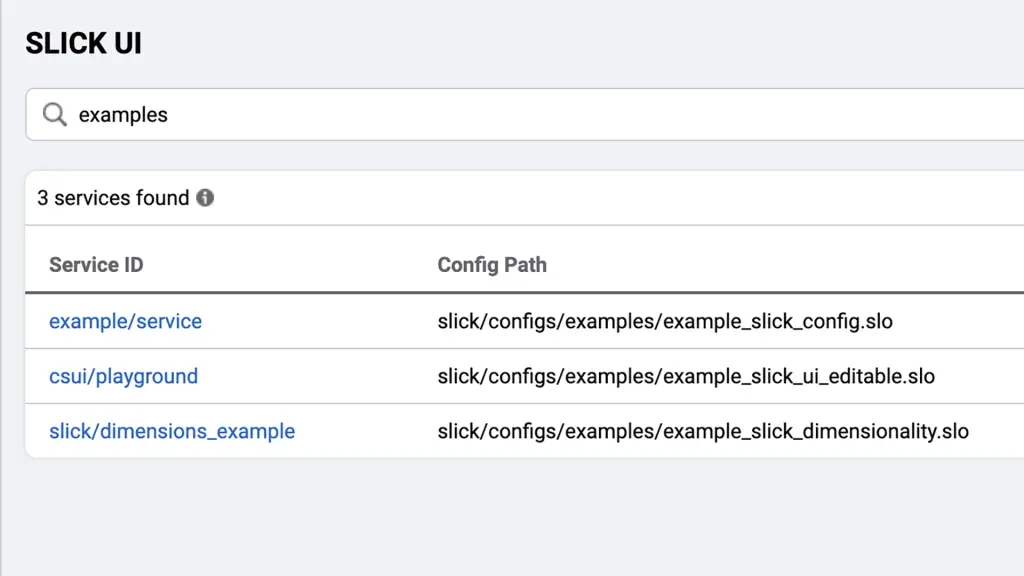
上图是SLICK的SLO索引搜索示例
长期洞察(Long-term insights)
服务可靠性的问题非常复杂。在某些情况下,单个错误的部署或某一段代码的变更可能就会导致服务突然退化。而在其他情况下,有可能随着服务的发展,不断累积微小的不可靠因素。
SLICK允许服务所有者使用最长可达两年的完整粒度的度量和性能数据。SLICK中的存储过程每小时运行一次数据管道,捕获所有SLI时间序列数据,并将它们存储在分片的MySQL数据库中。然后分析这些内容,形成可消费的洞见。这使得每个人——从工程师到TPM到领导——都能够了解随着时间的推移,可能会出现的服务可靠性的退化,而这些信息在之前很有可能会被忽视。
工作流(Workflows)
为了放大价值并帮助我们使用新的长期洞见来推动决策,SLI和SLO需要使用一种人人都能理解和使用的语言来规划和评估影响。为了实现这一点,我们将SLO集成到公共工作流中。
当大规模事件发生时,通过查看实时工具中的SLO,服务开发团队可以评估其对整体用户体验的影响。另一方面,当发生重大事件时,也可以基于SLO来驱动处理流程。我们首先使用SLO作为公司内部事件的标准,其他系统可以使用这些标准来获得用户看到的问题的警报。
从本质上说,将SLI和SLO集成到其他工具中,可以方便的将尚未引入的服务引入到SLICK中,从而以易于访问和易于使用的方式获得有效的见解。
SLICK引入(SLICK onboarding)
服务开发团队通过UI或者编写一个简单的配置文件来支持SLICK,该文件遵循带有服务名称等信息的DSL,可以查询SLI时间序列以及相应的SLO。
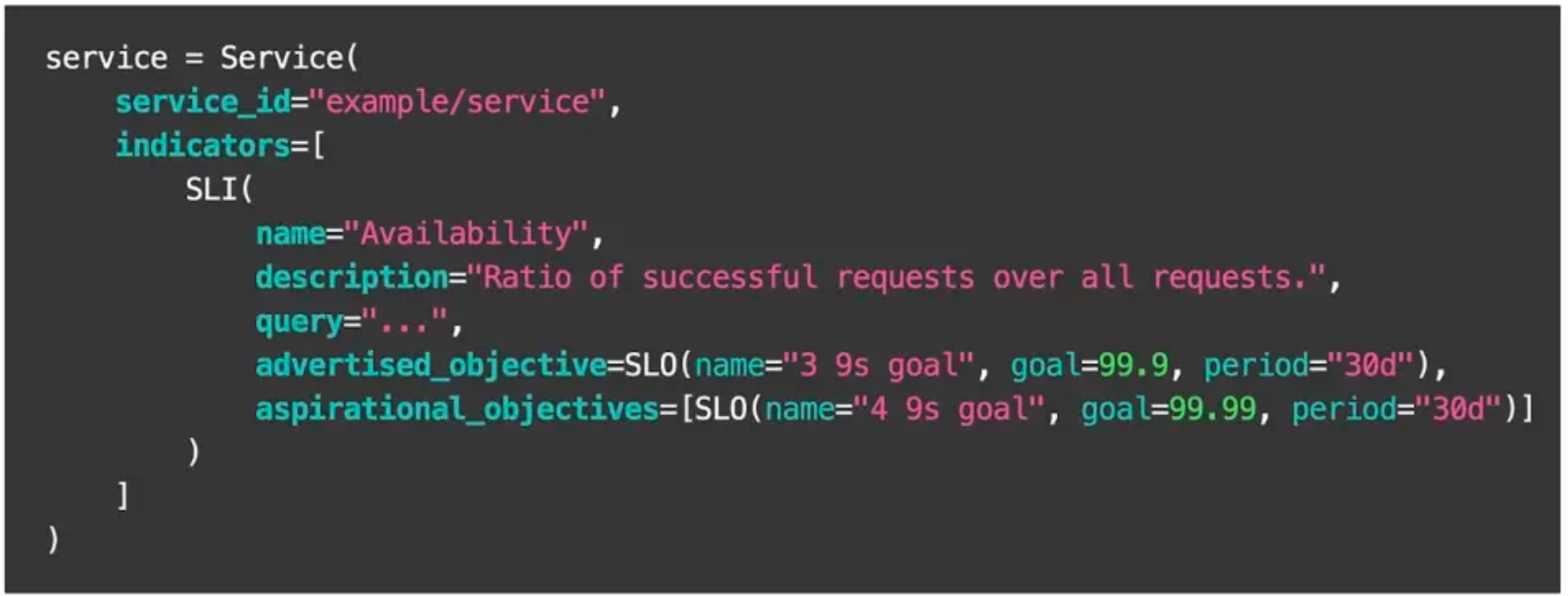
在用户测试并提交配置之后,SLICK会自动将服务添加到索引中,然后生成特定于服务的指示板,并开始收集数据以进行长期观测。除了这个配置文件,其他所有集成都是开箱即用的。
使用SLICK
1)仪表板
SLICK仪表板为服务开发团队提供了监控实时SLI数据以及基于高留存率、长期数据的历史趋势的能力。
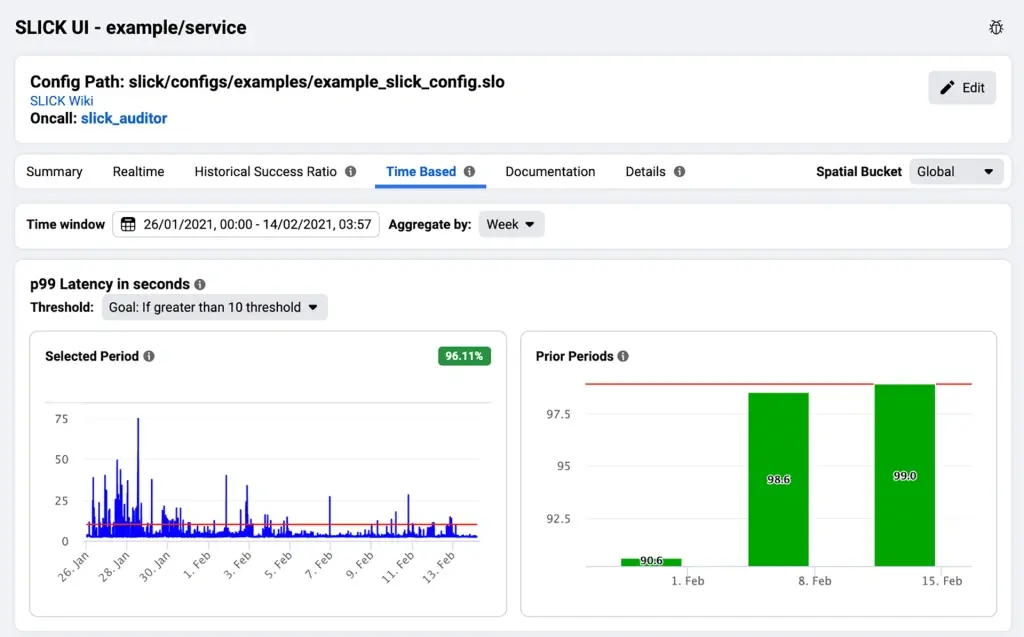
上图:左边以完整的粒度说明了SLI时间序列。右侧显示基于时间的SLI值的每周聚合和SLO的相对差距。
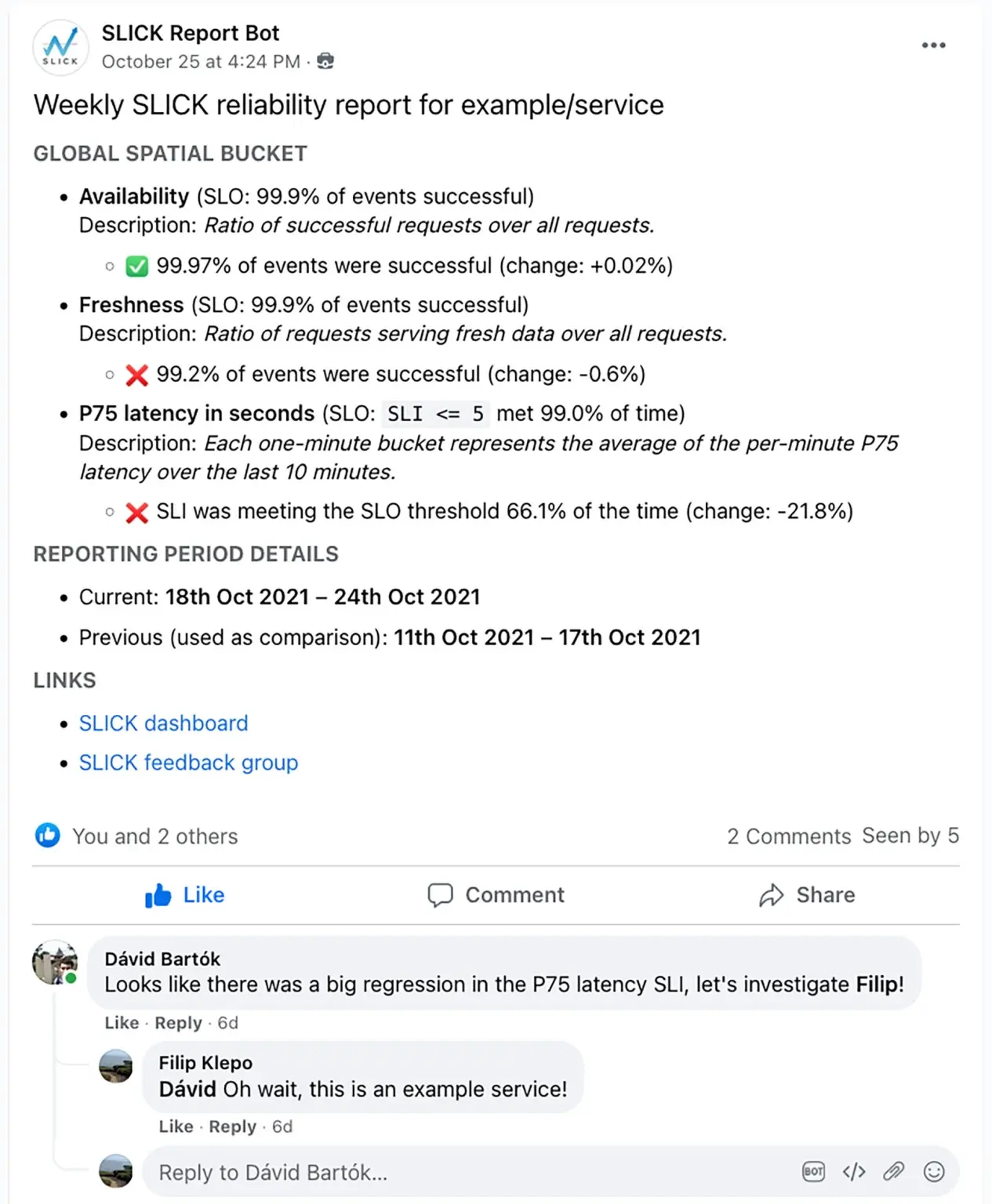
2)周期性报告
SLICK为工程师提供了SLO性能总结报告的能力,这些报告会定期发布给内部团队。报告为服务开发团队提供了一种简单的方法来关注回归并进行回顾,我们经常看到服务开发团队在这些帖子的评论中讨论可靠性问题。
3)CLI
SLICK提供了命令行接口,使服务所有者能够执行某些操作,比如回填数据、根据需要生成报告,或者测试对SLICK配置的更改的效果。
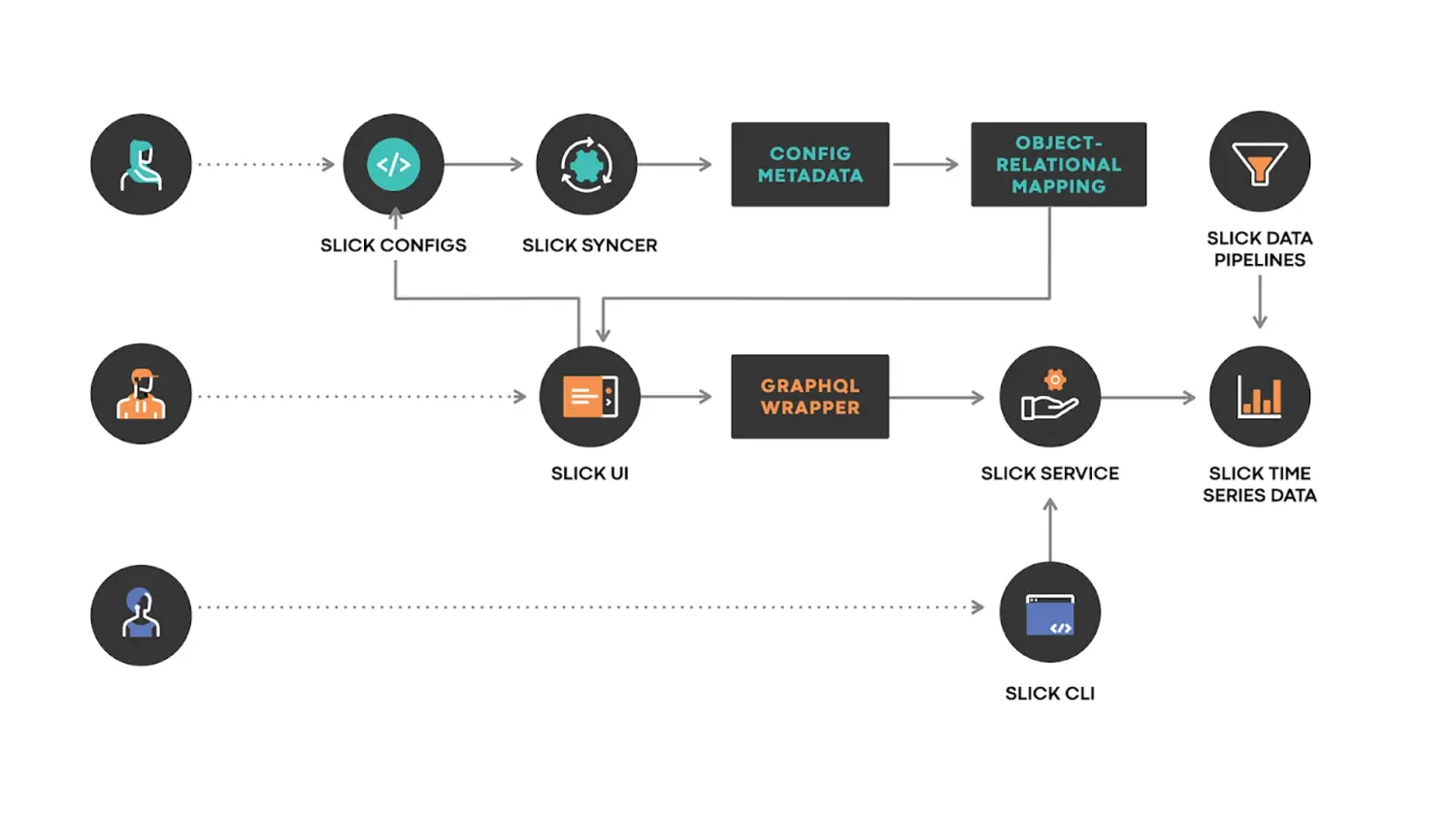
SLICK架构
总体架构
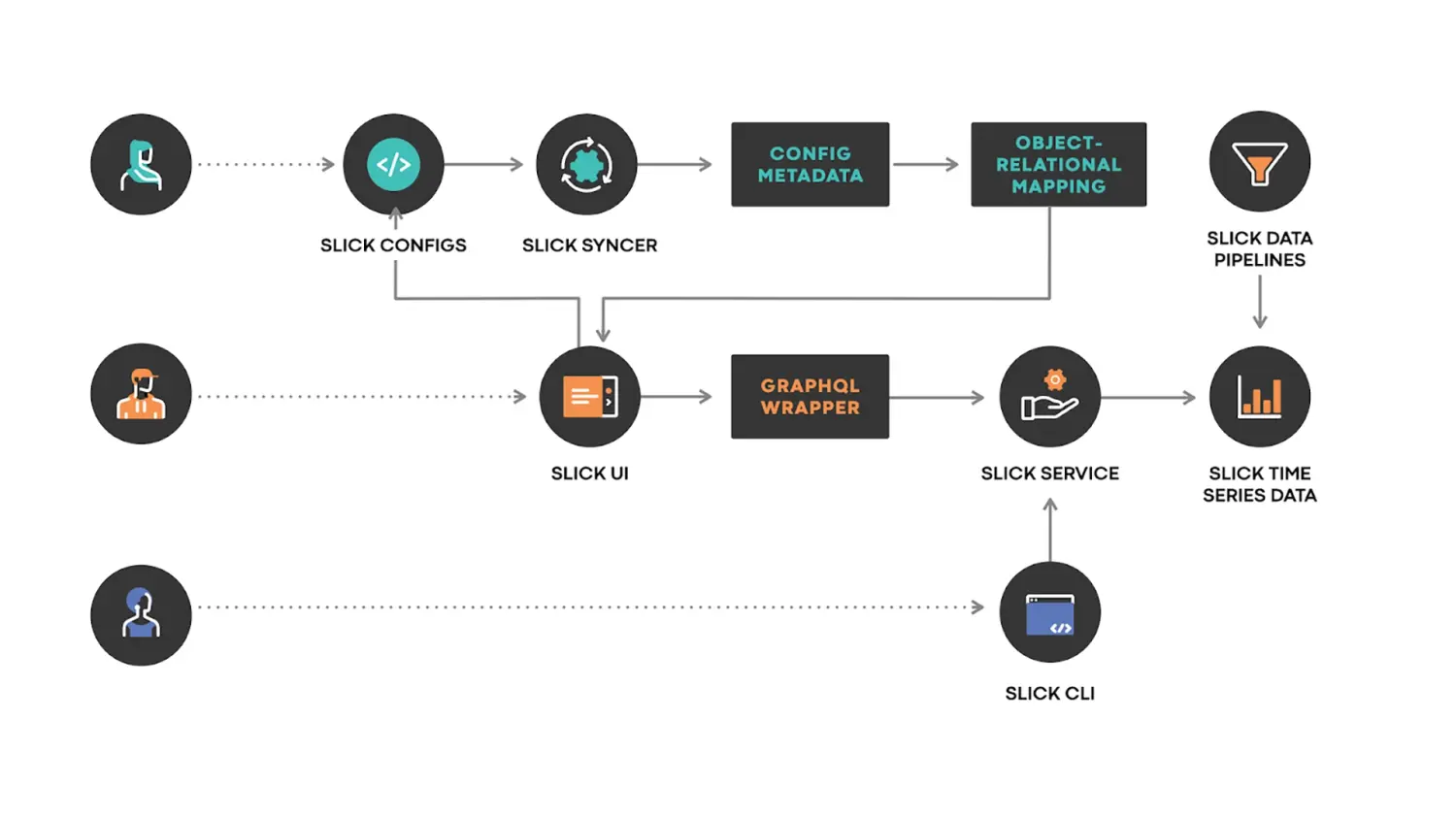
- SLICK配置(SLICK CONFIGS):使用SLICK的DSL编写的配置文件,由用户提交到SLICK配置存储区。
- SLICK同步器(SLICK SYNCER):将对SLICK配置所做的更改同步到SLICK配置元数据存储的服务。
- SLICK UI:为每个服务生成的SLICK仪表板,SLICK UI还提供了前面提到的索引。
- SLICK服务(SLICK SERVICE):提供API的服务器,能够回答诸如“如何为特定的可视化计算SLO?”这样的问题。服务器允许我们抽象出关于数据存储和分片的所有细节,使调用者能够轻松找到所需数据。
- SLICK数据流水线(SLICK DATA PIPELINES):周期性运行的流水线,以便长期获取SLI数据。
数据获取详细设计(Zooming in on the data ingestion)
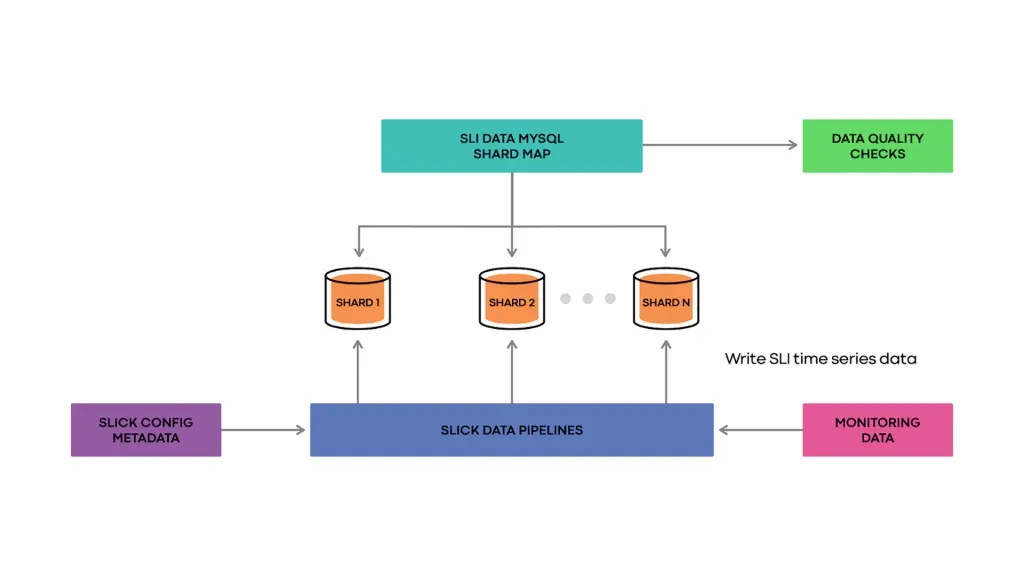
SLICK每小时运行一次数据流水线,这些流水线通过查询SLICK的配置元数据来查找所有SLI。流水线对被监控的数据集执行所有需要的查询,以获得以分钟为粒度的当前时刻每个SLI的原始时间序列数据。
然后,流水线参考SLICK分片映射确定每个SLI的数据应该存储在哪里,然后将数据批量插入到适当的分片中。
此外,可以执行数据质量检查,从而使我们对数据流水线的操作方式充满信心,并快速捕获真正的错误。数据质量检查针对一组确定性测试时间序列运行,用处理真实SLI序列同样的方式处理这些确定性时间序列,也就是说,对它们执行流水线,将它们插入到分片数据库中,最后,将数据库中的行与预期的时间序列进行比较,以验证系统的行为。
Meta应用SLICK的SLO的当前状态
在2019年创建了SLICK后,我们发现到2021年,全公司已经有超过1000个服务接入了SLICK。我们还看到其他许多公司在可靠性方面的成功案例,下面会分享其中的一部分。请注意,出于保密原因,下面图表使用了模拟数据,我们删除了日期并略微修改了数值,但图表的整体形状保持不变。
LogDevice:回归检测和修复示例
LogDevice是我们的分布式日志存储系统。服务开发团队可以通过SLICK对读可用性进行回归检查,并且可以基于这些数据修复回归发现的问题,并通过SLICK确认修复恢复了读取可用性的服务级别。
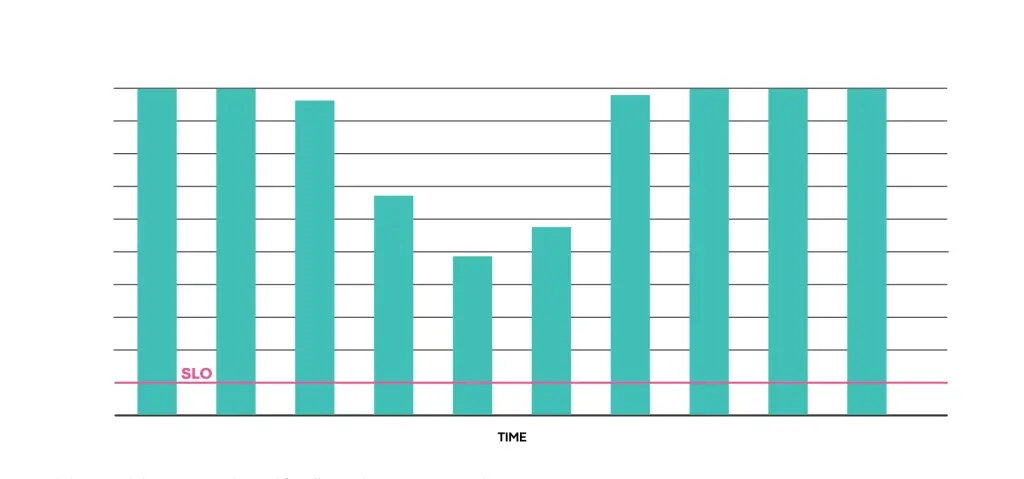
上图:LogDevice可靠性(读可用性)。此图不按比例绘制,仅供讨论之用。

后端ML服务可靠性示例
2020年,Meta公司一个关键后端ML系统开始出现显著的可靠性退化,而这是一个影响到我们终端应用用户的ML服务。
SLICK数据显示,该服务始终没有达到SLO要求,服务开发团队能够识别这种回归,并帮助启动了可靠性评估,从而帮助他们调查、发现和修复可靠性问题的根本原因。团队解决了根本原因,服务回到了满足SLO的状态。

上图:后端ML服务可靠性(可用性)。此图不按比例绘制,仅供讨论之用。
我们的收获
在推进SLO的过程中,我们走过了很长的一段路,并从中吸取了一些经验教训:
- 长期跟踪能力非常有价值,能够帮助我们了解趋势,从而使我们可以计划一段更长时间的可靠性工作。
- SLO必须处于工程文化的中心,无论是在战略可靠性规划还是日常沟通中。
- 引入SLO有助加强我们服务的整体可靠性。
SLICK团队将继续致力于平台的发展以提供更多的价值。我们特别希望在以下领域进行投资:
- 使服务的SLO与其依赖项的SLO保持一致。这将允许团队理解他们的依赖关系如何影响他们的性能,还能帮助我们揭示调用栈中服务之间不匹配的期望值,而这些不匹配因素有可能触发级联失败。
- 为服务开发团队提供如何提高服务可靠性的反馈和建议。我们希望利用在提高可靠性方面的经验,为服务开发团队提供可操作的见解,以帮助他们提高可靠性并满足SLO。
- 进一步发展SLICK的覆盖范围。我们希望在SLICK上搭载更多的团队和服务,为了做到这一点,SLICK需要保持可靠性和可扩展性(满足我们自己的SLO)。
References: [1] SLICK: Adopting SLOs for improved reliability: https://engineering.fb.com/2021/12/13/production-engineering/slick/ [2] LogDevice: https://engineering.fb.com/2017/08/31/core-data/logdevice-a-distributed-data-store-for-logs/


