
本文介绍 Jaeger 的基本概念、特性和架构。原文转载自 MakeOptim,正文保留原文中的 Jaeger、OpenTracing、Uber 和相关组件说明。

核心要点
- Jaeger 是受 Dapper 和 OpenZipkin 启发、由 Uber Technologies 开源的分布式追踪系统。
- 在微服务场景中,Jaeger 主要解决上下文传播、链路监控、根因分析、服务依赖分析和延迟优化问题。
- 一个 Trace 可以理解为一次请求经过系统的执行路径,由多个 Span 组成;Span 是 Jaeger 中描述单个工作单元的基本对象。
- Jaeger 后端既可以使用 all-in-one 方式部署,也可以拆分为 Agent、Collector、Query、Ingester 和存储后端等组件。
- 采样策略会直接影响追踪数据量、性能开销和问题定位精度,生产环境需要结合流量规模和排障目标配置。
Jaeger 是什么
Jaeger 是一个面向分布式系统的链路追踪系统,用于观察请求在多个服务之间的传播路径。它可以帮助研发和运维团队回答几个常见问题:
- 一次请求经过了哪些服务?
- 每个服务或端点分别耗时多久?
- 请求在哪个依赖或调用环节变慢?
- 服务之间的依赖关系是什么?
- 某次异常请求是否可以还原为一条完整调用链?
简单理解,Jaeger 是兼容 OpenTracing 的一个实现。它为微服务系统提供 Trace、Span、上下文传播、采样、存储和查询能力,让调用关系不再只停留在日志或监控指标的局部视角里。
Uber 曾发布博客文章 Evolving Distributed Tracing at Uber,解释 Jaeger 在架构选择方面的历史和原因。Jaeger 的创建者 Yuri Shkuro 还出版了 Mastering Distributed Tracing,系统介绍 Jaeger 设计、运维以及分布式追踪方法。
Jaeger 适合解决哪些问题
| 场景 | Jaeger 的作用 |
|---|---|
| 分布式上下文传播 | 在服务调用之间传递 trace id、span id 和 baggage 等上下文信息 |
| 分布式传输监控 | 观察一次请求在多个服务、接口和依赖之间的执行路径 |
| 根因分析 | 从慢调用或错误 Trace 中定位异常发生的服务、端点或依赖 |
| 服务依赖分析 | 生成服务拓扑,帮助理解调用关系和依赖方向 |
| 性能和延迟优化 | 通过 Span 耗时拆解请求链路,识别主要耗时环节 |
主要特性
Jaeger 的常见特性包括:
- 兼容 OpenTracing 的数据模型和工具库,覆盖 Go、Java、Node、Python、C++、C# 等语言。
- 支持按服务和端点进行概率采样。
- 支持 Cassandra、Elasticsearch、内存等多种存储后端。
- 支持系统拓扑图,便于查看服务之间的依赖关系。
- 支持自适应采样和收集后数据处理管道等能力规划。
更多详细信息可参考 Jaeger 的特性页面。
Jaeger 的核心概念
理解 Jaeger 架构前,需要先弄清楚 Span 和 Trace 两个概念。
Span
Span 表示 Jaeger 中的一个逻辑工作单元。一个 Span 通常包含操作名称、开始时间和持续时间,也可以携带 tag、log 等信息。多个 Span 可以嵌套并排序,用来表达一次请求中的因果关系。

例如,一次用户请求进入 API 网关后,继续调用订单服务、库存服务和数据库,每个关键调用都可以被表示为一个 Span。
Trace
Trace 表示一次请求通过系统时形成的数据路径或执行路径。它可以被看成由一组 Span 组成的有向无环图(DAG)。当 Trace 展示出来后,排障人员可以看到请求在每个服务上的耗时、调用顺序和上下游关系。
Jaeger 的部署架构
Jaeger 可以使用 all-in-one 二进制部署,即所有后端组件运行在同一个进程中;也可以作为可扩展的分布式系统部署。常见部署方式有两类:
- Collector 直接写入存储后端。
- Collector 先写入 Kafka 作为中间缓冲,再由 Ingester 写入最终存储。
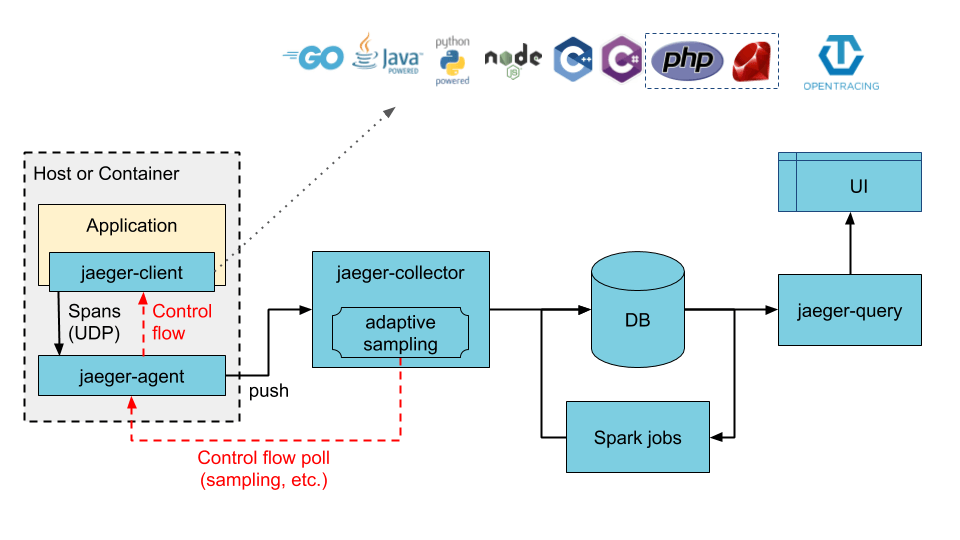
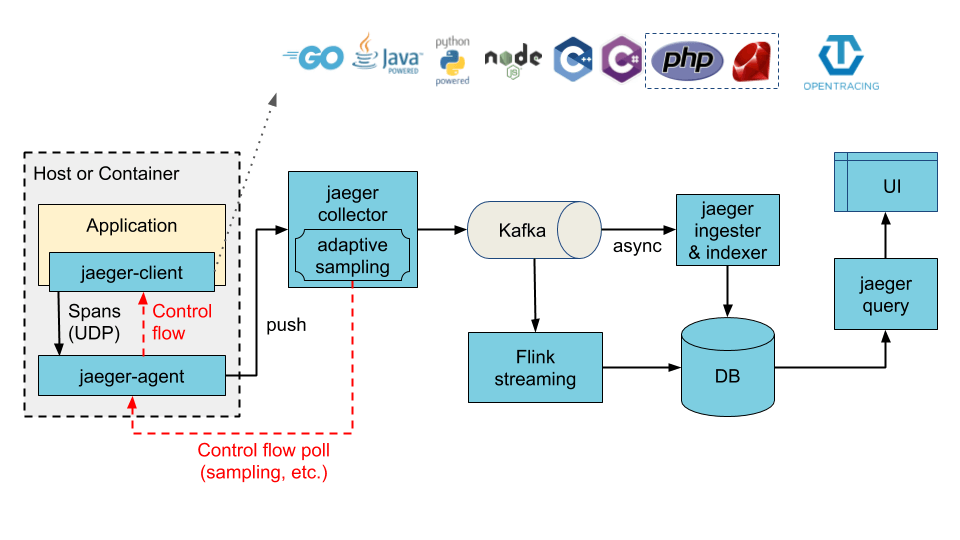
第一种方式链路更短,适合规模较小或架构相对简单的环境。第二种方式在 Collector 与存储之间加入 Kafka,通常用于缓冲写入压力、提升后端处理弹性。
Jaeger 组件说明
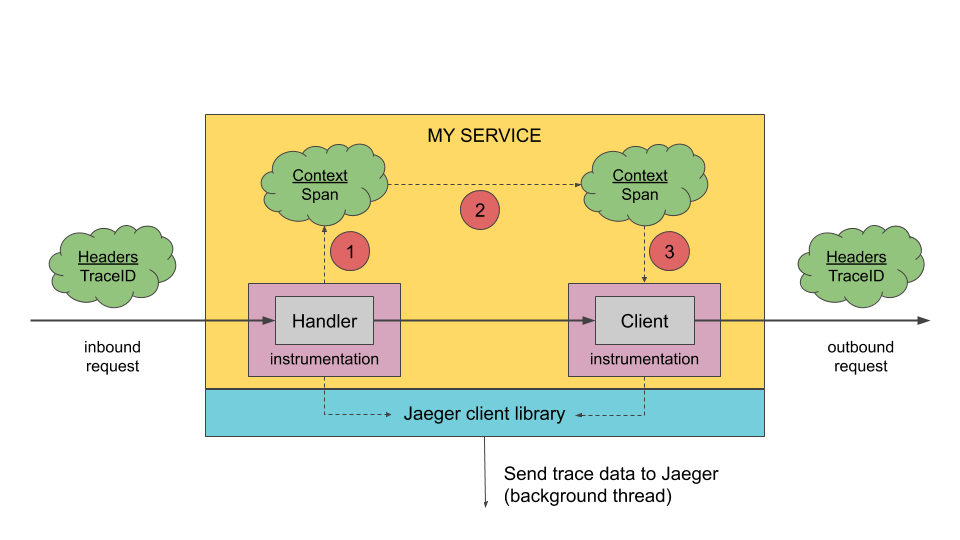
客户端库(Client Libraries)
Jaeger 客户端是 OpenTracing API 的特定语言实现。应用可以通过手动埋点,或者借助已经集成 OpenTracing 的开源框架进行链路追踪,例如 Flask、Dropwizard、gRPC 等。
被检测的服务在接收新请求时创建 Span,并把 trace id、span id 和 baggage 等上下文信息附加到传出请求。只有 id 和 baggage 会随请求传播;操作名称、时间、tag、log 等分析数据不会继续传播,而是在后台异步传输到 Jaeger 后端。
为了降低运行开销,Jaeger 客户端使用采样策略。被采样的 Trace 会采集 Span 数据并发送到 Jaeger 后端;未被采样的 Trace 不会收集性能分析数据,对 OpenTracing API 的调用也会被短路,以减少额外开销。默认情况下,Jaeger 客户端对 0.1% 的 traces 进行采样,即每 1000 条中采样 1 条,并且可以从 Jaeger 后端检索采样策略。更多信息可参考采样文档。
代理(Agent)
Jaeger Agent 是一个网络守护进程,监听通过 UDP 发送的 Span,再将它们批量发送给 Collector。Agent 通常部署在每台主机上,为客户端屏蔽 Collector 的路由和发现细节。
收集器(Collector)
Jaeger Collector 从 Agent 接收 Trace,并通过处理管道完成验证、索引、转换和存储。Collector 是写入链路上的核心组件,需要根据写入量和存储后端能力规划容量。
存储后端
Jaeger 的存储是可插拔组件,原文提到的后端包括 Cassandra、Elasticsearch 和 Kafka。不同存储后端的容量、查询性能和运维复杂度不同,生产环境需要结合 Trace 写入量、保留周期和查询需求选择。
查询(Query)
Query 服务负责从存储中检索 Trace,并托管用于展示 Trace 的 UI。排障人员通常通过 Query UI 搜索 Trace、查看调用链详情和分析服务依赖。
Ingester
Ingester 从 Kafka topic 读取 Trace 数据,并写入 Cassandra、Elasticsearch 等存储后端。它通常出现在“Collector -> Kafka -> Ingester -> Storage”的部署模式中。
使用 Jaeger 时需要关注什么
部署 Jaeger 不是只把组件跑起来,还需要关注几个影响效果的关键点:
- 采样策略:采样率过低可能漏掉关键问题,采样率过高会增加网络、存储和查询压力。
- 上下文传播:跨服务调用必须正确传递 trace id 和 span id,否则 Trace 会被切断。
- 存储容量:Trace 数据量与请求量、采样率和 Span 数量相关,需要规划保留周期。
- 埋点质量:Span 命名、tag 和 log 的一致性会影响后续检索和根因分析。
- 组件拓扑:小规模环境可用 all-in-one,生产大流量环境通常需要拆分 Collector、存储和查询组件。
FAQ
Jaeger 和普通监控指标有什么区别?
监控指标更擅长回答“系统整体是否异常”,例如错误率、延迟、吞吐量是否变化;Jaeger 更擅长回答“一次请求具体慢在哪里、经过了哪些服务”。两者并不替代,通常需要结合使用。
Span 和 Trace 的关系是什么?
Span 是单个工作单元,Trace 是一组有因果关系的 Span。一个 Trace 里通常包含多个 Span,用来还原一次请求在分布式系统中的完整路径。
为什么 Jaeger 需要采样?
微服务系统的请求量通常很大,如果所有 Trace 都完整采集,会带来较高的网络、CPU 和存储开销。采样用于在成本和可观测性之间做平衡。
小结
Jaeger 是微服务监控和可观测性体系中的分布式链路追踪工具。它通过 Trace、Span、上下文传播、采样和查询能力,把一次请求在多个服务之间的执行路径串联起来。理解 Jaeger 的组件分工、部署模式和采样机制,是后续部署、使用和排障的基础。
下一篇可继续围绕如何部署和使用 Jaeger 进行分布式追踪展开。



