
我们可以看到,在 CNCF landscape 中,在可观测性(Observability)这个大的领域中,近些年来涌现出了特别多的优秀项目,为什么会发生这样的变化?

这和过去十年,技术架构的演进变革有关。在过去的十年,微服务架构与云原生技术,相互促进发展,成为巨大的技术变革浪潮,而“可观测性”是云原生技术架构的关键能力之一。
本文的主线可以概括为三句话:
- 传统监控系统要解决的是容量、采集、存储、告警和可视化问题。
- 微服务和云原生让系统对象、数据维度、生命周期和依赖关系都变得更复杂。
- 现代可观测平台需要把 Metrics、Logs、Traces、告警、可视化、采集器和生态标准放在同一套产品与架构里考虑。
可观测性(Observability)是一种软件开发和系统构建的哲学,是对系统内部状态及行为的度量和推断能力,通常包括日志、指标、链路追踪等多个度量维度。也就是说,在软件开发和运维领域中,可观测性是指对于一个复杂的系统,能够通过监控、日志、指标、追踪等手段,快速地发现、诊断、解决问题的能力。
微服务和云原生,带来的好处,在我看来,最核心的有两点:
- 低耦合:使得我们具备了构建更大规模的系统的能力,并且通过极致的低耦合,从技术根本上,提升了协作的效率,从而带来了软件迭代效率的提升。
- 弹性:如果说云原生架构,只允许保留一个特性,你怎么选?我会毫不犹豫的选择保留“弹性”。过去很长一段时间,系统的可扩展性,是摆在架构师、运维等技术人员面前的头等问题,今天借助于云原生架构和微服务模型,我们可以快速地获取和释放资源,自动化地对我们系统规模进行扩缩容。同时我们把资源的供应单位,切割的粒度变得更小,进行自动化的编排调度。进而,带来了资源使用效率的革命性提升。
微服务和云原生,带来好处的同时却也有代价
微服务和云原生,给系统的可维护性,带来了巨大的挑战,系统的整体复杂度和系统之间的相互依赖程度更高,因而可观测性成为一个关键支撑因素。我所创建的开源项目 Open-Falcon 和夜莺监控,本质上也是在这样的大背景下,发展和成长起来的。
要回答 Open-Falcon 为什么会流行,那就得先回到 2013 年,从需求说起。当时我在小米工作,公司的互联网业务飞速发展,业务规模越来越大,监控系统的容量有限和业务的体量快速膨胀,成为核心矛盾。所以,Open-Falcon 在架构设计上,一个最关键的考量点就是“如何做到水平扩展”。
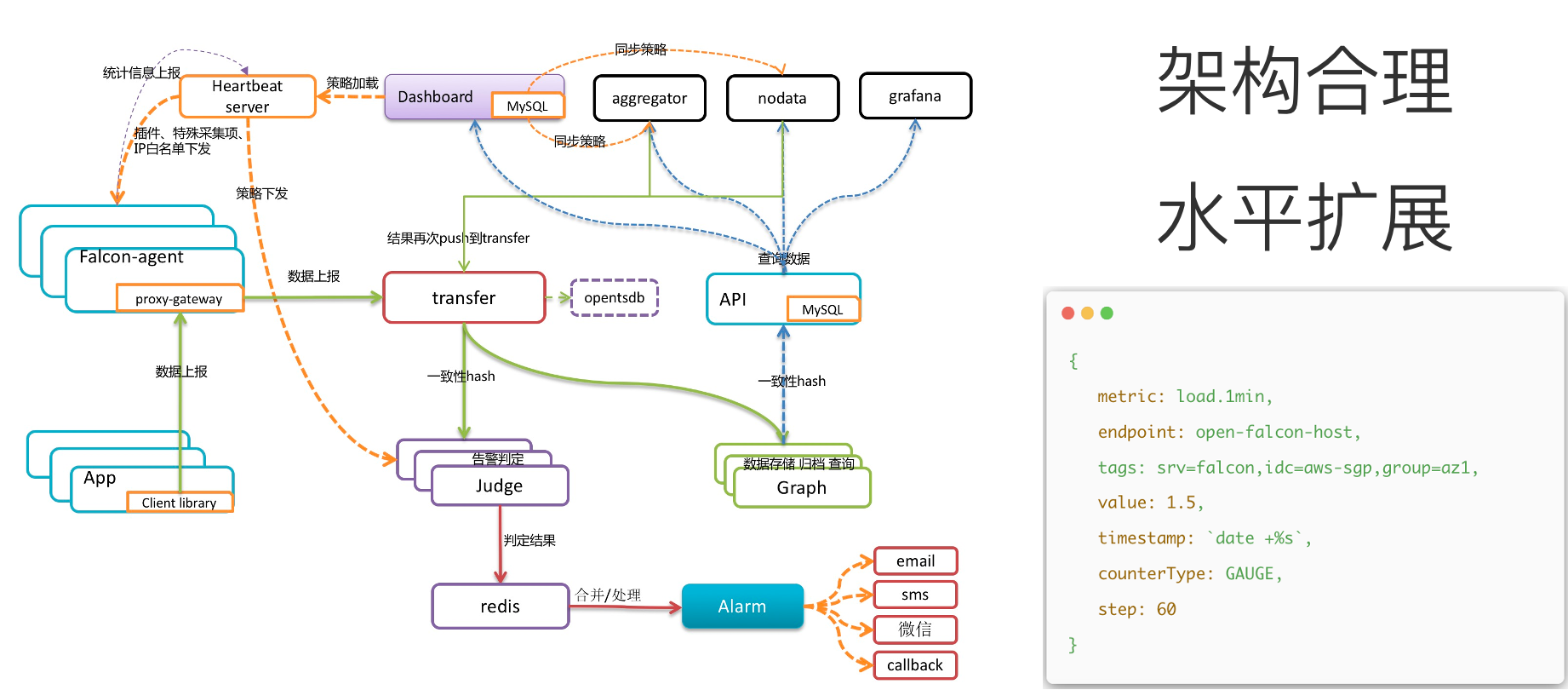
下面是 Open-Falcon 架构设计上的一些思考要点:
- 定义了可扩展的数据模型(label),引入了标签的概念,可以大大增强监控指标的表达能力;
- 从一开始就设计了专属的数据采集器 falcon-agent,数据采什么、怎么采、采了怎么用,都考虑到了,做到了开箱即用,知识沉淀。
- 数据采用“推”的方式;falcon-agent 采集到的数据,直接推送到 transfer 组件,当然用户也可以通过 transfer 的 api 来推送自定义数据;(保障了时效性、方便研发团队接入数据)。
- transfer 组件,是数据传输网关,可以水平扩展,同时 transfer 会根据一定的数据分片规则,将数据推送给存储模块 graph、以及告警判定模块 judge。
- 在整个 Open-Falcon 的架构中,核心思想是采用数据分片架构解决扩展性问题。比如 transfer 模块本身是无状态的,可以水平扩展;graph 组件是按照一致性 hash 算法对数据进行分片存储,judge 模块也是按照一致性 hash 算法来处理特定分片的数据和任务。
- 最后,Open-Falcon 不仅仅是一个工具,更多的是一个产品,将互联网公司的运维经验沉淀到产品中,同时具有较高的产品完成度,在数据采集、管理 portal、可视化、告警判定、告警通知等方面,都有不错的表现。
当然也有很多的局限和缺点:
- 在数据模型上,虽然很早(2013 年)就引入标签的维度,但是未能和 Prometheus 的数据模型看齐,导致后续在生态的融合上出现额外的障碍。
- 采用推的数据模型,在“控制”方面会比较弱(要做好流控、脏数据控制等能力),对于数据中断的监控无法感知(增加了“nodata”的额外逻辑,Prometheus 是在 scrape 数据的时候,提供了 target_up 指标)。
- 流式的规则判定模型,天然无法很好的解决多条件组合报警等复杂判定(aggregator 解决了一部分问题)。
- proxy 架构,没有很好的解决数据再平衡的问题(虽然提供了扩缩容时 migrate 数据的方案,但是运维操作比较复杂)。
- 基于 RRD 的数据格式,环状数据库,虽然磁盘的使用效率很高,但是磁盘 IO 负载很高(虽然做了优化,将小文件的随机写入,加了写的缓存,修改为批量写入等,但距离理想效果还有差距)。此外对于 ad-hoc 查询,支持比较弱。
Open-Falcon 的发展为什么遇到了瓶颈?
除去上面提到的设计上的一些缺陷,更重要的是,Open-Falcon 一直未能建立起开放、自治的社区。可以看到,有很多的公司都在基于 Open-Falcon 做二次开发,很多的公司在自己的 JD 中注明,需要熟悉 Open-Falcon 二次开发。但是 Open-Falcon 的贡献者数量停留在了 100 位之后就基本停滞了,未能持续的形成合力。

瓶颈二,原因在于,Open-Falcon 关注的更多是物理机架构的监控方案,未能很好的融入云原生生态。

那云原生时代的监控,有怎样的特点和变化趋势呢?
-
首先,数据量的大幅提升,尤其是 Application 层面监控数据比重快速增加
有别于物理机时代,更多在关注主机、系统层面的 metrics,在今天,Mesh、Pod、App、Business 层面,所产生的 metrics 占到了更大比重,以生产实践中的统计为例,占比达到了 80% 上下。这对数据采集和存储,都带来了新的挑战。
-
监控数据的采集原则发生了变化
数据的采集、存储、计算的成本在下降,数据的重要性在凸显,此消彼长,数据应收尽收,治理前置,成为了应用和系统开发人员的埋点原则。此外,eBPF 技术的发展和普及,使得数据捕获和应用层更解耦,在网卡、网络协议栈、内核等环节更高效的进行埋点和数据解析,并有望形成系统的、普适的解决方案。
-
监控数据模型的维度变得更丰富
以指标类型的监控数据为例,Label 作为云原生 Metrics 数据模型的灵魂,Open Metrics 成为事实上的云原生 metrics 标准。数据维度更多,对监控系统的架构设计、扩展性、产品交互体验,提出了挑战。
-
监控数据的生命周期变得更短、更不确定
比如,在微服务和云原生架构下,Pod 的生命周期不再是长期的,其状态变化的频率也更高,这使得对于监控数据的连续性追踪和关联分析变得更困难。
-
针对监控数据的 Ad Hoc 查询需求变大
在微服务和云原生架构下,单个 Pod 的状态监控重要性下降,用户更关心以 App 维度,或者其他 Label 维度的聚合查询,此类 Ad Hoc 查询的灵活度和性能,如何在产品设计和系统架构设计上取得折中,如何在保证灵活度的同时,控制好长尾请求的表现,变得非常关键。
-
Metrics 与 Logs、Traces 需要融会贯通,相互打通以及建立关联关系重要性凸显
由于微服务和云原生架构的复杂度和封装,使得系统管理员和研发人员,很难再去到具体的机器和案发现场,通过查询日志等方式来 debug。如何在监控系统层面,将 metrics、logs、traces 相关信息打通,对于研发、运维和运营人员,能提供更多的便利。
-
监控产品的使用对象发生了变化
云原生时代,监控系统的使用群体发生了变化,从面向规模较小的,具备专业能力的专职运维工程师群体,变成了更广大的研发、测试、运营人员群体,监控产品的体验好坏、入门门槛足够低、是否能够开箱即用,变得极为重要。此外,在数据应收尽收的背景下,数据多,如果缺乏有效的洞察手段和数据处理手段,那么数据多反而会变成一种干扰和负担。如何提供全局统一的数据视图,建立有效的信息系统,把知识沉淀、赋能,对于监控产品的用户可以发挥更大价值。
-
监控系统本身也要云原生
监控系统自身的部署架构是否支持容器化,以 binary、sidecar、daemonset 等多种方式运行,是否支持 opentelemetry / open metrics 相关标准,是否支持 service discovery,是否兼容 PromQL 等 Query Language,是否可以方便的通过 docker-compose、helm chart、k8s operator 等方式运行管理。这些都是作为一个云原生监控系统本身要先自我革新的方面。
这些变化可以放进一张表里理解:
| 变化 | 传统监控关注点 | 云原生可观测关注点 |
|---|---|---|
| 数据来源 | 主机和系统指标为主 | App、Pod、Mesh、Business 等更多层面 |
| 数据模型 | 指标维度相对固定 | Label 维度丰富,查询组合更多 |
| 生命周期 | 主机相对稳定 | Pod、实例和服务关系变化更频繁 |
| 查询方式 | 固定大盘和固定告警较多 | Ad Hoc 查询需求更强 |
| 数据类型 | Metrics 为主 | Metrics、Logs、Traces 需要关联 |
| 使用者 | 专职运维为主 | 研发、测试、运营和 SRE 共同使用 |
| 部署方式 | 传统二进制或集中部署 | 容器化、DaemonSet、Sidecar、Operator 等 |
基于之前我们做 Open-Falcon 的经验总结反思,结合云原生监控的发展特点和趋势,我们重新思考,一个现代化的观测平台,应该是什么样的?
- 数据统一生产、统一可视化、统一告警
- Metric/Log/Trace 融会贯通
- 兼容 OpenTelemetry 开源生态
夜莺监控既可以监控传统的物理机架构、可以监控微服务架构和 K8s,也可以监控公有云的资源和服务。不仅支持 Metrics,也支持 Log、Trce。提供统一的监控数据视图,提供集中化的可视化和管理界面。换句话说,你可以使用夜莺监控,来完成Zabbix + Prometheus + Grafana + ELK + Jaeger + 云监控的工作。
夜莺监控在架构设计上:
- 同时适合传统架构 & 云原生架构 & 混合云架构;
- 多数据源架构设计,适应灵活多变的部署环境和生态;
- 可扩展架构设计,水平灵活扩展;
- 支持联邦架构,兼顾中心化部署和边缘设备集群管理;
- Go 语言开发,安全,易维护,架构简洁;


夜莺配套的数据采集器 Categraf,有以下特点
- All-in-one:所有的采集工作使用一个 agent 来解决,包括 metrics、logs、 traces ,并从数据采集的源头建立起数据间的关联关系,保障好数据的质量。
- 开箱即用:覆盖支持上百种采集对象,包括 K8s、中间件、服务器、交换机等,针对常用的采集对象,在提供采集能力的同时,配套有默认的监控仪表盘模板和告警规则模板,用户可以直接导入并使用。
- 部署方式灵活:支持在 K8s 集群中以 Daemonset 或者 Sidecar 运行,支持公有云产品的数据采集,也支持独立运行在宿主机上。
- Go 语言开发:安全、易分发、易安装维护,插件化。

告警功能丰富、灵活
- 支持多数据源告警,Prometheus、Victoriametrics、M3DB、Thanos,ElasticSearch 等;
- 多种告警判定策略,多条件策略,生效周期,产品化配置和管理;
- 多通知渠道和自定义通知模版;
- 支持故障自愈和告警 Webhook;
- 支持告警聚合、收敛、排班、协同(需要对接 Flashcat SaaS 应用);
自研可视化引擎,对标 Grafana
俗话讲,一图胜千言,可视化是透传数据价值最直接的手段。夜莺监控的 Dashboard 不仅从功能、设计上可以对标 Grafana,同时也兼容 Grafana,要是你觉得 Grafana 某个 Dashboard 非常有用,甚至可以直接导入到夜莺监控中使用。
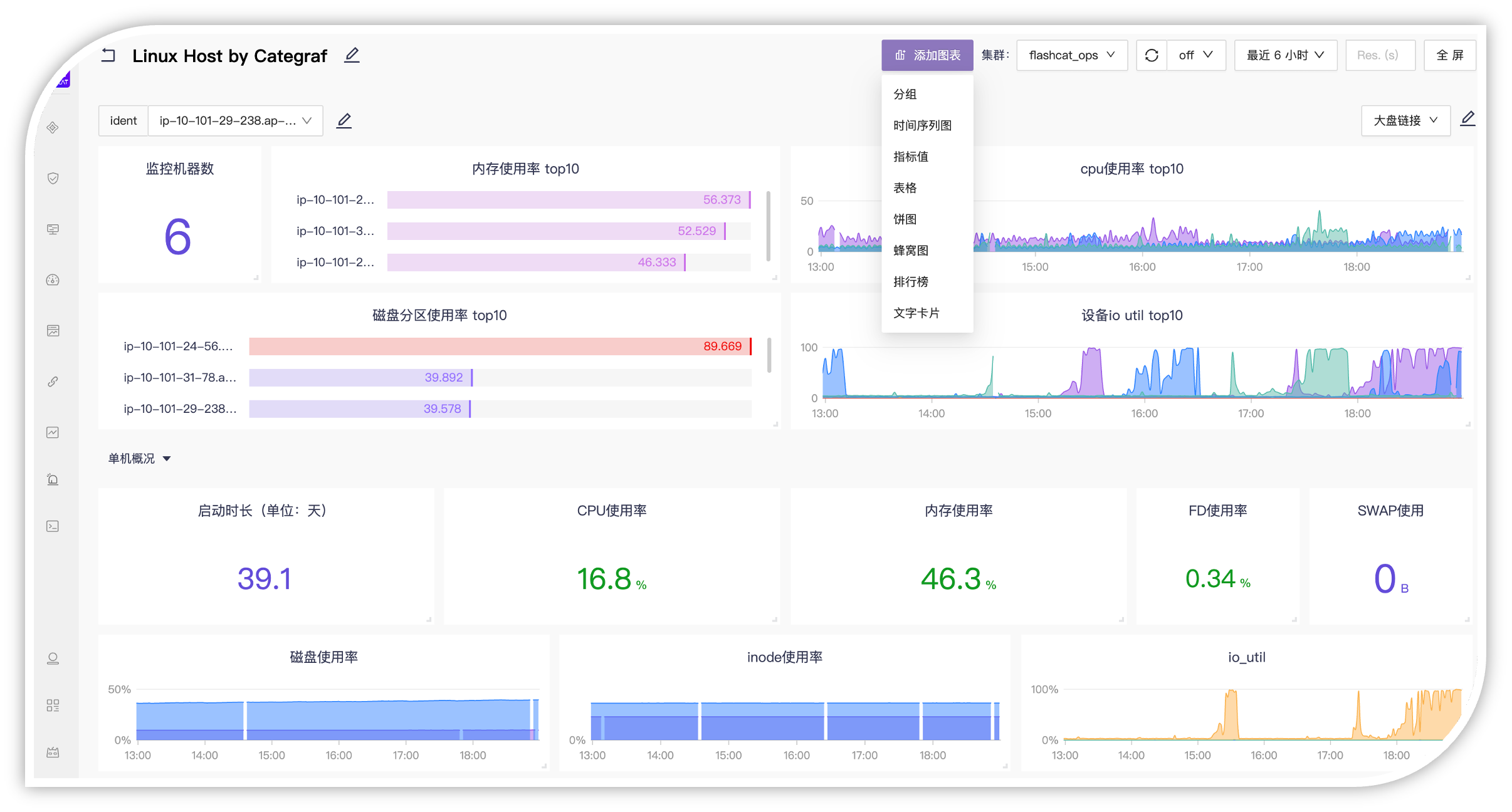
此外,夜莺监控的 Dashboard 支持多种数据源,比如时序数据库 Prometheus、Victoriametrics、M3DB、Thanos,又比如日志数据源 ElasticSearch,链路追踪数据源 Jager 等。
做开源监控,夜莺社区是认真的
夜莺监控,从 2020 年 3 月份开源,累计迭代发布了 100 个版本,获得了众多用户和企业的关注,获得超过 6200 颗 Star,1000 多次 fork,吸引了近百位外部代码贡献者。每 5 个 Star,产生 1 次 Fork;每 10 次 Fork,产生 1 位 Contributor。
更进一步,2022 年 5 月 11 日,夜莺监控正式捐赠给了中国计算机学会开源发展委员会,成为中国计算机学会开源发展委员会接受捐赠的一个开源项目。
夜莺开源社区,拥有了一个很好的起点。
开源项目要更有生命力,离不开开放的治理架构和源源不断的开发者共同参与,如果能从制度上,确立好中立、开放的机制,那么开源社区就有了坚实的地基。
夜莺监控项目加入 CCF 开源大家庭后,在 CCF 开源发展委员会的支持和带动下,进一步结合云原生、可观测、国产化等多个技术发展的需求,建立开放、中立的开源治理架构,致力于打造更专业、有活力的开发者社区。发布了夜莺监控开源社区治理架构草案,建立了用户、贡献者、committer、项目管委会的用户体系和管理制度,并公示了相关的任命和社区荣誉。
尊重、认可和记录每一位贡献者的工作,是夜莺开源社区的最高指导原则,在这里,我们强调每一位参与者的贡献,都应该被看见。结合我过去运营开源软件和社区的体会来看,“参与感”是超过物质激励,且更持久的一种激励方式。

最后,欢迎大家关注夜莺开源项目,支持夜莺开源社区的发展,我们一起打造“好看、好用、专业”的云原生监控工具,参与其中。
FAQ
Q1:监控系统和可观测平台的核心区别是什么?
A:监控系统更强调采集、存储、展示和告警;可观测平台还要关注多维数据模型、Metrics/Logs/Traces 关联、临时查询、对象上下文、用户体验和生态兼容。二者不是割裂关系,而是从传统监控能力向更复杂系统诊断能力的演进。
Q2:Open-Falcon 的经验对今天还有什么价值?
A:Open-Falcon 在水平扩展、标签模型、专属采集器、数据分片、产品化体验等方面提供了重要经验;它的局限也提醒我们,数据模型、社区治理和云原生生态融合会影响监控系统的长期生命力。
Q3:云原生监控为什么必须关注 Logs 和 Traces?
A:微服务和云原生架构让故障定位不再只依赖单机指标。Metrics 能发现趋势和异常,Logs 能提供错误细节,Traces 能展示请求路径和上下游依赖。三者打通后,排障才更容易从“发现异常”走向“定位原因”。
关于快猫星云
快猫星云是一家云原生智能运维科技公司,由开源监控工具“夜莺监控”的核心开发团队组成。
您只需要一个Flashcat 平台,就可以支持指标、日志、链路追踪数据的统一采集、统一可视化、统一告警,这免去了需要搭建和维护 Prometheus、Zabbix、Grafana、ELK、Jager/Skywalking 等多套工具的工作量,带来了更一致的用户体验。
Flashcat 平台提供的 On-Call 管理能力,支持告警聚合、降噪、认领、升级、排班,让告警的触达既高效,又确保告警处理不遗漏、做到件件有回响。
- Flashcat 平台 PPT: https://download.flashcat.cloud/flashcat.pdf
- 一分钟视频介绍:https://sourl.cn/JLStgU
- Flashcat 官网:https://flashcat.cloud


