
运维监控工具怎么选?先不要从工具清单开始,而要先分清监控对象:主机和网络设备、Kubernetes 和微服务、日志检索、可视化大盘、告警处理,分别对应不同能力。
本文围绕 Zabbix、Prometheus、Nightingale、Grafana、ELK 这几类常见工具,回答三个问题:
- 运维监控为什么是稳定性保障的基础?
- 指标监控和日志监控有什么区别?
- 不同工具适合什么场景,选型时应该看哪些维度?
运维监控的重要性
运维监控是运维工作的重中之重,因为做好监控是稳定性保障的前提,如果监控都没做好,更何谈故障及时发现、故障快速定位呢。运维监控工具可以收集生产环境的各类信息,而这些信息是我们开展运维工作的基础。
- 确保系统稳定运行:运维监控工具可以实时监控服务器、网络、应用程序等IT基础设施的运行状态,及时发现并解决潜在问题,保障系统的稳定运行。
- 提升系统性能:运维监控工具可以收集和分析性能指标数据,帮助运维人员了解系统瓶颈和性能瓶颈,从而采取相应的优化措施,提高系统性能和稳定性。
- 容量规划:运维监控工具可以通过分析历史数据和趋势,预测未来系统负载和资源需求,为容量规划提供科学依据。
运维监控工具有哪些
运维监控工具可以大体分成两部分:一类针对指标场景,另一类针对日志场景。指标用于观察服务器、网络、应用程序等 IT 设施的运行状态和性能情况;日志用于记录运行过程中的事件和上下文,帮助运维和研发人员定位问题原因。
指标通常是一个随时间变化的数值,比如某个机器的 CPU 利用率,某个接口的 QPS、某个数据库实例的连接数。一些大型互联网公司,每秒采集几千万指标数据点,为了区分这么多的指标,指标需要有唯一标识,另外我们希望对各类指标做过滤和聚合计算,比如公司有上万机器,某个时刻我只想查看部署了 Oracle 数据库的那些机器,并且想对这些数据做聚合计算,比如计算这些机器的平均 CPU 利用率。为了解决这些场景的需求,现代的监控系统通常把指标定义为名字+标签的形式,名字和标签组合在一起就是一个唯一的指标,比如 cpu_usage{host="host1",service="mysql"}。一个标签就是一个维度信息,可以基于标签做过滤和聚合计算。
日志相比指标,量更大,数据不够结构化,通常表现为一个字符串,如果想要从日志数据中提取有价值的信息,通常就要对日志数据做清洗,做ETL,最终存储在 Elasticsearch、ClickHouse 等存储中,然后通过 Kibana、Grafana 等工具进行展示。当然,实际的情况是,大部分公司的研发人员只是用日志定位问题,能够对日志做快速查询就挺好了,所以日志的存储系统通常是 Elasticsearch,ClickHouse 则用的较少,因为 Elasticsearch 支持全文检索更适合研发排查问题,而 ClickHouse 更适合做 OLAP 分析,如果数据是结构化的,Schema 固定的,ClickHouse 更适合。
从能力边界看,可以先这样分类:
| 场景 | 常见工具 | 主要价值 |
|---|---|---|
| 主机、网络设备、传统数据库监控 | Zabbix | 资产管理式监控、模板和传统基础设施覆盖 |
| Kubernetes、微服务、云原生指标 | Prometheus | 多维标签模型、PromQL、云原生生态 |
| 公司级告警和统一监控入口 | Nightingale | 告警规则、权限、UI、统一数据源接入 |
| 仪表盘和可视化 | Grafana | 多数据源展示、仪表盘生态 |
| 日志检索和分析 | ELK / EFK | 日志采集、清洗、检索和展示 |
运维监控工具之 Zabbix 的优缺点

Zabbix 出现的时间较早,Zabbix 擅长服务器、网络设备的监控,其资产管理式的设计,甚至可以当做 CMDB 来使用。Zabbix 数据存储使用 RDBMS,不是专门为时序数据设计的,容量有限。Zabbix 的资产管理式的设计,也给他带来一些缺点,难以应对 Kubernetes 这类动态环境的监控。Zabbix 的数据结构相对简单,缺少维度的概念,缺少灵活的 Query Language,不适合大规模微服务监控场景。
但是,如果你就只是想用 Zabbix 监控服务器和网络设备,则 Zabbix 是一个不错的选择,Zabbix 的创始人最开始是做银行的运维工作的,所以 Zabbix 的设计更偏向于传统的监控场景,比如监控服务器、网络设备、数据库等。Zabbix 发展了这么多年,其功能是非常完善的,而且 Zabbix 的社区也很活跃,在网上可以找到很多资料。
运维监控工具之 Prometheus 的优缺点

Prometheus 是一款开源的监控系统和时间序列数据库,由 SoundCloud 开发并开源。Prometheus 以多维数据模型和强大的查询语言 PromQL 而著称,可以灵活地处理多种类型的监控数据。
Prometheus 奠定了云原生监控的生态基础,如果你使用 Kubernetes,大概率你也会使用 Prometheus,虽然 Prometheus 自带的的存储是单点,自带的告警引擎是单点,也没有太多权限控制的设计,难以把 Prometheus 直接作为公司级统一的监控系统来使用。但是,如果你们公司不同的团队各自使用自己的 Prometheus,那 Prometheus 就是很好的选择。
Prometheus 相比 Zabbix 更为丰富,社区里有很多 Prometheus 的插件,如果你的动手能力很好,希望有很高的灵活性,Prometheus 是一个不错的选择。
运维监控工具之 Nightingale 的优缺点

Nightingale 核心就是解决刚才提到的 Prometheus 在告警层面的问题,单点、权限控制等问题。Nightingale 是一个开源的监控系统,隶属于中国计算机学会开源发展委员会,Nightingale 的设计目标是希望支持不同的时序库、日志库,然后做上层的告警功能。同时提供权限控制、良好的 UI,以期成为公司级统一的监控系统。
Nightingale 内置了很多组件的告警规则,力求开箱即用,同时也提供监控数据采集器、提供数据可视化的能力,所以完全可以把 Nightingale 看成是一套完整的监控系统。
不过,由于 Nightingale 相对年轻,其可视化能力相比 Grafana 之类的还有差距,但是 Nightingale 的团队在不断完善,相信未来会有更好的发展。
运维监控工具之 Grafana 的优缺点
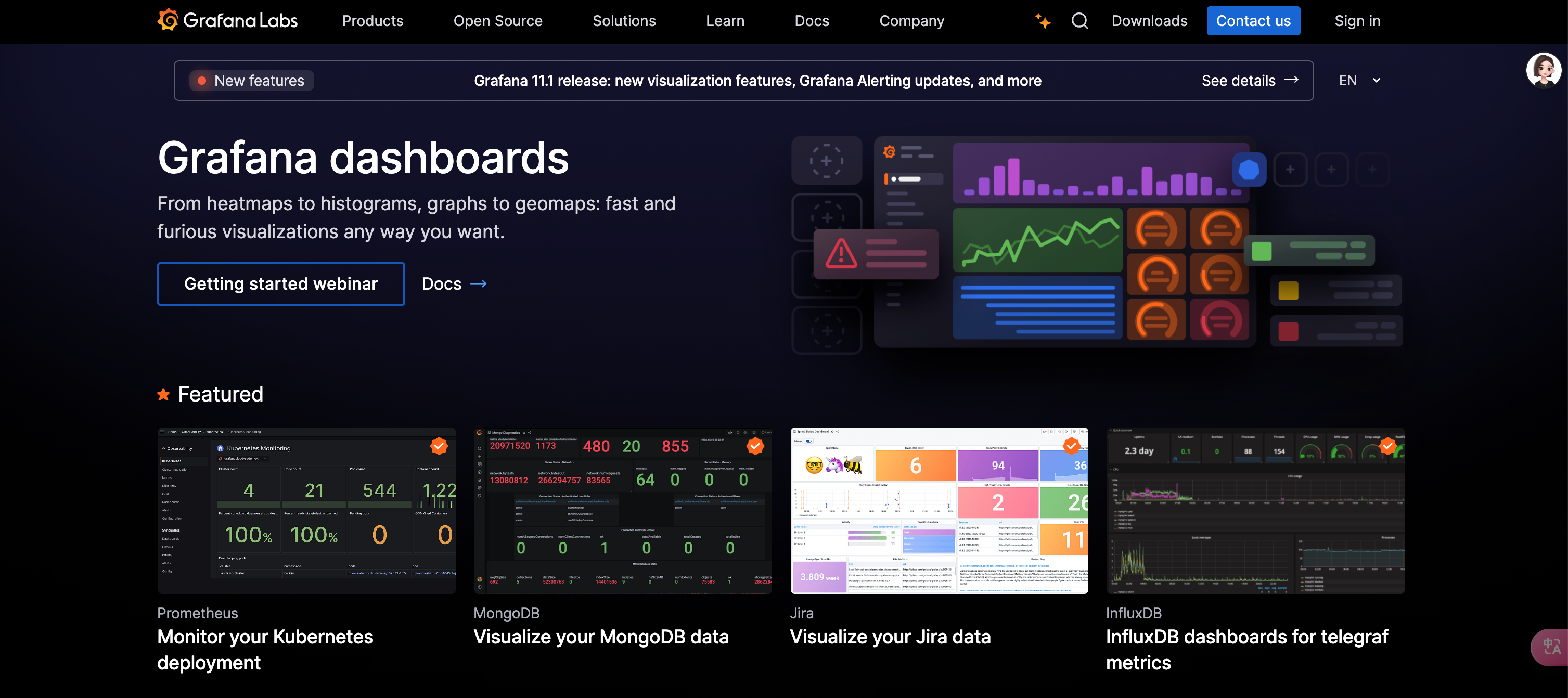
Grafana 几乎成为了开源监控领域的可视化标配工具,非常擅长制作各类可视化的仪表盘。Grafana 支持多种数据源,比如 Prometheus、InfluxDB、Elasticsearch、MySQL 等,支持多种图表类型,比如折线图、柱状图、饼图等,支持多种展示方式,比如仪表盘、地图、日历等。
Grafana 不采集数据、只是做数据展示,所以,通常需要把 Grafana 配合其他监控系统一起使用,比如 Prometheus、InfluxDB 等。
运维监控工具之 ELK 的优缺点
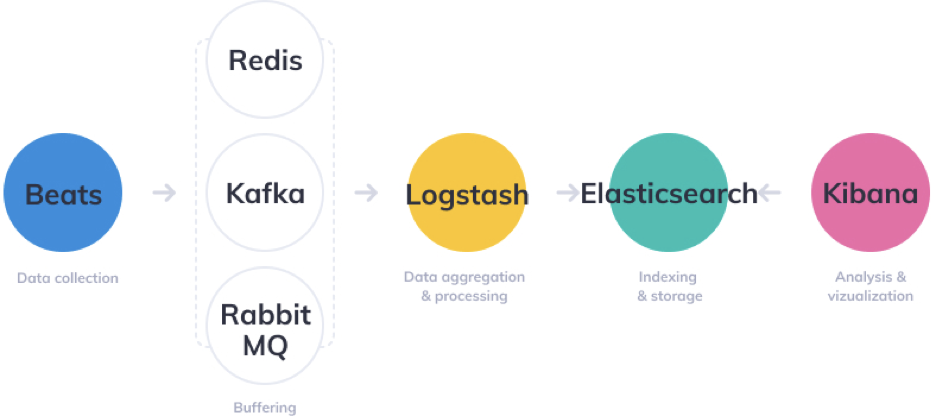
指标监控通过 Zabbix、Prometheus、Nightingale 等项目已经可以解决的很好了,但是日志监控需要专门的方案。ELK 是一个开源的日志管理解决方案,由 Elasticsearch、Logstash、Kibana 三个开源项目组成。当然了,由于 Logstash 的性能问题,现在很多公司都用 Fluentd 替代 Logstash,所以 ELK 也就变成了 EFK。
Elasticsearch 在日志领域的应用非常广泛,因为 Elasticsearch 支持全文检索,所以检索效率很高,尤其是日志没有很好的结构化的情况下,Elasticsearch 的全文检索能力就显得尤为重要。但是,全文检索带来了高成本的问题,所以很多公司在尝试使用 ClickHouse、Doris 等存储日志。但是,ClickHouse、Doris 等在日志领域算是新秀,相比 Elasticsearch 还有很多生态上的不足。
运维监控工具的选型考虑
选型时可以按下面几个维度逐项判断:
- 业务场景:监控服务器、网络设备、数据库等传统对象,可以重点看 Zabbix;监控 Kubernetes、微服务等云原生对象,可以重点看 Prometheus;监控日志,可以重点看 ELK / EFK。
- 功能需求:是否需要告警、数据可视化、权限控制、租户隔离、模板管理、通知升级和告警降噪。
- 数据规模:指标量、日志量、保留周期、查询并发和高可用要求,会直接影响存储和架构选择。
- 社区支持:活跃社区意味着更多模板、插件、案例和问题解决路径。
- 成本考虑:除了软件许可,也要考虑存储、计算、通知、运维人力和二次开发成本。
- 技术栈:工具要能接入现有云平台、数据库、Kubernetes、消息队列、日志系统和告警响应流程。
- 未来发展:如果团队正在从传统主机走向云原生,工具要能覆盖动态环境、多维标签和统一告警治理。
一个实用判断是:如果团队从零建设,优先选择能快速覆盖核心监控链路的 all-in-one 方案;如果团队已经有多套系统,优先考虑统一告警、统一视图和统一治理,而不是强行替换所有底层采集系统。
运维监控工具的未来发展趋势
目前有两个明显的趋势,一个是 all-in-one 的方向,一个是整合的方向。
- all-in-one:即一个系统既包含指标的监控,又包含日志的监控,甚至包含 APM 的监控,这样可以减少系统的复杂度,提高运维效率。
- 整合:即不同的数据存储在不同的系统,比如服务器、网络设备的监控使用 Zabbix,微服务、Kubernetes 的监控使用 Prometheus,日志的监控使用 ELK,这样可以根据不同的业务场景选择不同的监控工具,提高监控的灵活性。同时在这些系统的上层构建统一的数据串联、告警、可视化系统,比如使用 Flashcat(当然,Flashcat 也可以提供 all-in-one 的能力)。
如果你要从零开始做一整套体系,那可以选择 all-in-one 的方案,如果你已经或多或少的建设了一些监控系统了,想整合这些系统的数据,那可以选择整合的方案。
FAQ:运维监控工具常见问题
Q1:Zabbix 和 Prometheus 应该二选一吗?
不一定。Zabbix 更适合传统主机、网络设备和资产管理式监控,Prometheus 更适合 Kubernetes、微服务和多维指标查询。很多企业会同时使用,再在上层做统一告警和可视化。
Q2:Grafana 能不能单独作为监控系统?
Grafana 主要负责可视化展示,不负责采集和存储全部监控数据。实际落地时通常要和 Prometheus、InfluxDB、Elasticsearch、MySQL 等数据源配合。
Q3:日志一定要用 Elasticsearch 吗?
不一定。Elasticsearch 的全文检索能力适合排障查询;ClickHouse、Doris 等更适合结构化日志和 OLAP 分析。选择取决于日志结构化程度、查询模式和成本要求。
总结
运维监控工具是稳定性保障的基础。Zabbix、Prometheus、Nightingale、Grafana、ELK 解决的问题并不完全相同:有的偏采集和模型,有的偏告警治理,有的偏可视化,有的偏日志检索。选型时不要只看工具名气,要回到业务场景、数据规模、团队技术栈和故障响应流程。未来监控体系会继续沿着 all-in-one 和整合两个方向发展,关键是让监控数据真正服务于发现问题、定位问题和持续治理。



