
PromQL教程(五)PromQL 函数

在 2024 年的当下,Prometheus 生态基本已成为监控领域事实上的标准,学习 Prometheus 是每个运维人员的必修课,也是每个关注服务稳定性的研发人员的必修课。PromQL 是 Prometheus 的查询语言,全称是 Prometheus Query Language,想要学习 Prometheus,PromQL 是必学知识。本文是 PromQL 系列教程的第五讲,讲解 PromQL 中的常用函数。本系列其他文章:
总体来看,PromQL 中的函数分两类,一是聚合函数,二是变换函数。聚合函数用于对多个时间序列进行聚合操作,变换函数则用于对单个时间序列进行变换操作。Prometheus 函数非常多,具体文档参考:https://prometheus.io/docs/prometheus/latest/querying/functions/ 这一节我们举例说明一些常用的函数。
聚合函数
针对单个指标的多个 series,比如100台机器的 mem_available_percent,可能会有一些聚合需求,比如想查看这100台机器的平均内存可用率,或者排个序,取数值最小的10台。这种需求使用promql内置的聚合函数来做。
- sum (calculate sum over dimensions)
- min (select minimum over dimensions)
- max (select maximum over dimensions)
- avg (calculate the average over dimensions)
- group (all values in the resulting vector are 1)
- stddev (calculate population standard deviation over dimensions)
- stdvar (calculate population standard variance over dimensions)
- count (count number of elements in the vector)
- count_values (count number of elements with the same value)
- bottomk (smallest k elements by sample value)
- topk (largest k elements by sample value)
- quantile (calculate φ-quantile (0 ≤ φ ≤ 1) over dimensions)
比如取平均值和取最小的2个可用率数据,其对应的 promql 如下:
avg(mem_available_percent{app="clickhouse"})
bottomk(2, mem_available_percent{app="clickhouse"})
另外,我们有时会有分组统计的需求,比如我想分别统计 clickhouse 和 canal 的机器的内存可用率,可以使用 by 关键字指定分组统计的维度(与 by 相反的是 without):
avg(mem_available_percent{app=~"clickhouse|canal"}) by (app)
很多朋友可能都用过 by 的方式做聚合,但经常忽略 without,其实在很多场景下,用 without 都比 by 合适,因为 without 会把指定的标签过滤掉,大部分标签都会被保留,而 by 则是只保留指定的标签,大部分标签都被抹掉了。比如使用 node_exporter 采集机器的基础指标,如果要求取 CPU 的利用率,此时我们可以这么写:

avg without (mode,cpu) ( 1 - irate(node_cpu_seconds_total{mode="idle"}[2m]) ) * 100
这里我们使用 without (mode,cpu) 过滤掉了 mode 和 cpu 两个标签,剩下的标签都被保留了,相当于大部分元信息都被保留了。
这里使用的 irate 函数,使用 rate 也是可以的,后文会介绍二者的差别。
变换函数
变换函数是对过滤到的时间序列进行变换操作,比如最常用的是求取斜率的 rate、irate 函数,求取增量的 increase 函数,这些函数是对每个时间序列分别进行操作的。我们挑选几个比较常用的函数来说明。
increase 函数
这个函数很常用,但是其计算结果可能会出乎意料,这一节详细讲解,打消各位的疑问。字面意思上,表示求取一个增量,接收一个 range-vector,range-vector 显然是会返回多个 value+timestamp 的组合,我们直观理解就是,直接把时间范围内最后一个值减去第一个值,不就可以得到增量了吗?非也!如下图:
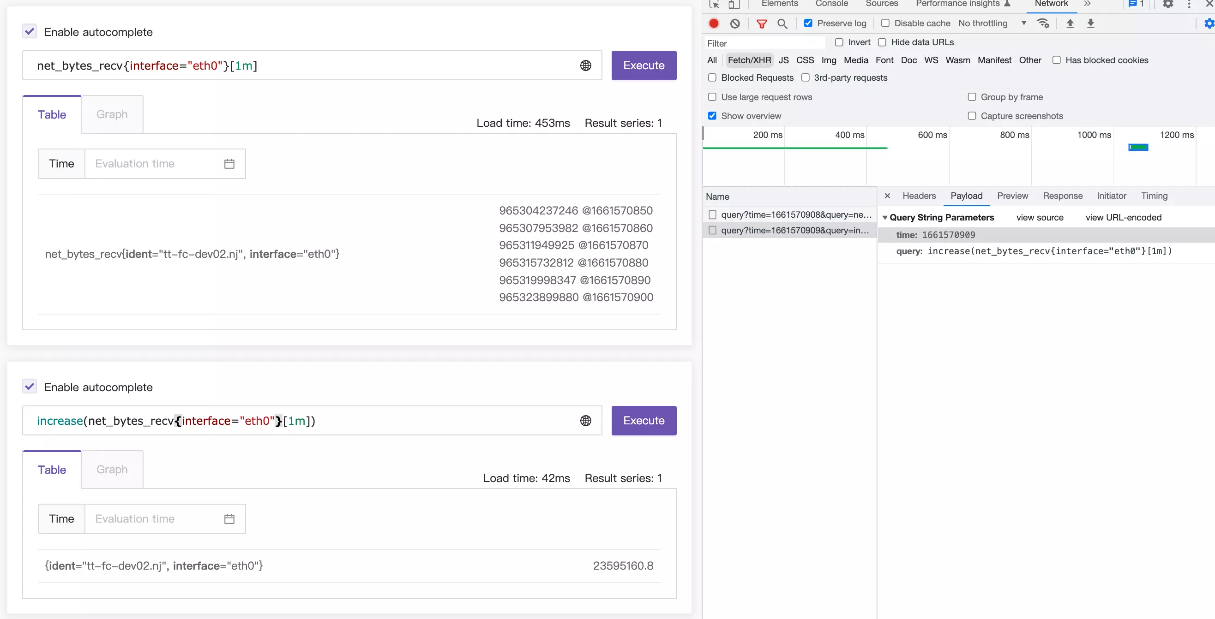
这个图上的一些关键信息,我们摘录出文本,具体如下:
promql: net_bytes_recv{interface="eth0"}[1m] @ 1661570908
965304237246 @1661570850
965307953982 @1661570860
965311949925 @1661570870
965315732812 @1661570880
965319998347 @1661570890
965323899880 @1661570900
promql: increase(net_bytes_recv{interface="eth0"}[1m]) @1661570909
23595160.8
监控数据是10秒上报一次,所以虽然两次 promql 查询时间不同,一次是 1661570908,一次是 1661570909,但是所查询的原始数据内容是一样的,就是 1661570850~1661570900 这几个时间点对应的数据。
直观上理解,在这几个时间点对应的数据上求取 increase,无非就是最后一个值减去第一个值,即965323899880-965304237246=19662634,很遗憾,实际结果是23595160.8,差别有点大,显然这个直观理解的算法是错的。
实际上,increase 这个 promql 发起请求的时间是1661570909,时间范围是[1m],相当于告诉Prometheus,我要查询1661570849(1661570909-60)~1661570909之间的 increase 数值。但是原始监控数据并没有 1661570849、1661570909 这两个时刻的数值,怎么办呢?Prometheus只能基于现有的数据做外推,即使用最后一个点的数值减去第一个点的数值,得到的结果除以时间差,再乘以60,即:
(965323899880.0-965304237246.0)/(1661570900.0-1661570850.0)*60=
23595160.8
📌 上例中,我的测试数据是没有缺失数据点的,如果有缺失数据点的情况,数据外推会更为复杂,具体可以参考这篇文章:https://mp.weixin.qq.com/s/9aiqrtLTnzysV9olMx-rzA
rate 函数
趁热打铁,说一下 rate 函数,increase 函数是求取的时间段内的增量,而且有数据外推,rate 函数则求取的每秒变化率,也有数据外推的逻辑,相当于 increase 的结果除以 range-vector 的时间段的大小,就是 rate 的值。我们用如下 promql 做验证:
rate(net_bytes_recv{interface="eth0"}[1m])
== bool
increase(net_bytes_recv{interface="eth0"}[1m])/60.0
这里 == 后面跟了一个 bool 修饰符,表示希望返回一个 bool 值,如果是 true 就会返回 1,如果是 false 就返回 0,我们观察结果会发现,这个表达式永远都会返回 1,即等号前后的两个 promql 语义上是相同的。
irate
rate 函数求取的变化率,相对平滑,因为是拿时间范围内的最后一个值和第一个值做数据外推,一些毛刺现象就会被平滑掉,如果想要得到更敏感的数据,可以使用 irate 函数。irate 是拿时间范围内的最后两个值来做计算,变化就会更剧烈,我们还是拿网卡入向流量这个指标来做个对比:
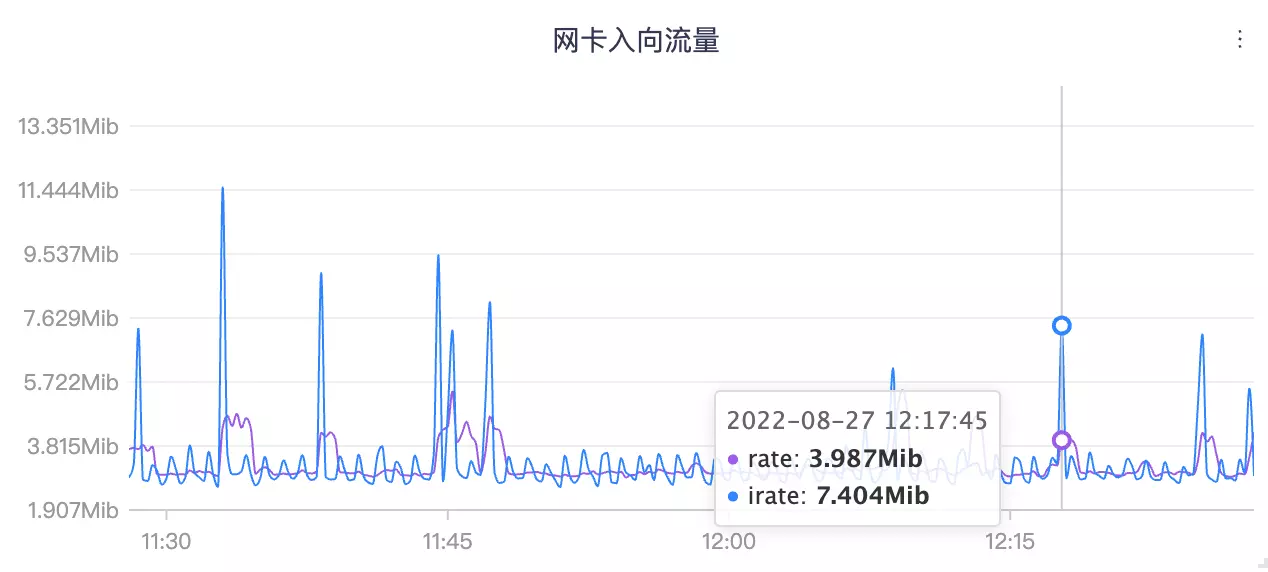
蓝色的更变化更剧烈的线是 irate 函数计算的,紫色的相对平滑的线是 rate 函数计算得到的。
histogram_quantile
要了解 histogram_quantile 函数的用法,首先得了解 Histogram 类型的数据。Histogram 翻译过来是柱状图,设计这个数据类型,是为了描述响应延时的情况。
比如接口:/api/v1/query,如何度量这个接口的健康状况?最核心有两个指标,一个是成功率,一个是延迟,成功率的计算代价比较小,只需要为每个请求指标打上 statuscode 的标签即可,然后可以求取非 5xx 非 4xx 的请求占比,即可得到成功的数量,除以总量就是成功率。
而对于延迟,如果只是求取平均延迟,代价也比较小,只要把请求总量做成一个 Counter 指标,把耗时总量做成一个 Counter 指标即可。但是,平均响应时间有时并不能很好的反应长尾问题,比如最近1分钟有1万个请求,大部分请求都是1秒内返回,有200个请求是10秒返回,平均响应时间是:1.18秒,看起来还不错,导致我们忽略了这200个长尾请求,而这200个长尾请求,可能恰好是暴露问题的200个请求。
所以在看延迟数据时,我们通常会用分位值,比如99分位,90分位,50分位,所谓的分位值,就是把一段时间内的所有延迟数据从小到大排序,99分位就是看第99%位置的那个值的大小。还是上面的例子,平均响应时间是1.18秒,但是99分位时间是10秒,相差巨大,更容易暴露问题。这里所谓的99分位延迟10秒,可以理解为,99%的请求都在10秒内返回。
从监控系统角度,如何来存储和计算出99分位值呢?如果每分钟有1亿个请求,难道真的要在监控系统中存储这1亿个请求,然后排序,然后求取分位值?那这个代价就太大了。监控数据是采样数据,对准确性要求没有那么的高,有没有什么办法可以降低这个代价呢?这就是 Prometheus Histogram 的设计初衷了。
Histogram 类型,是把延迟数据分到多个桶里,比如下面的例子,我们查询一个bucket指标看看效果,虽然这个指标的桶划分不是很合理,也可以说明问题:
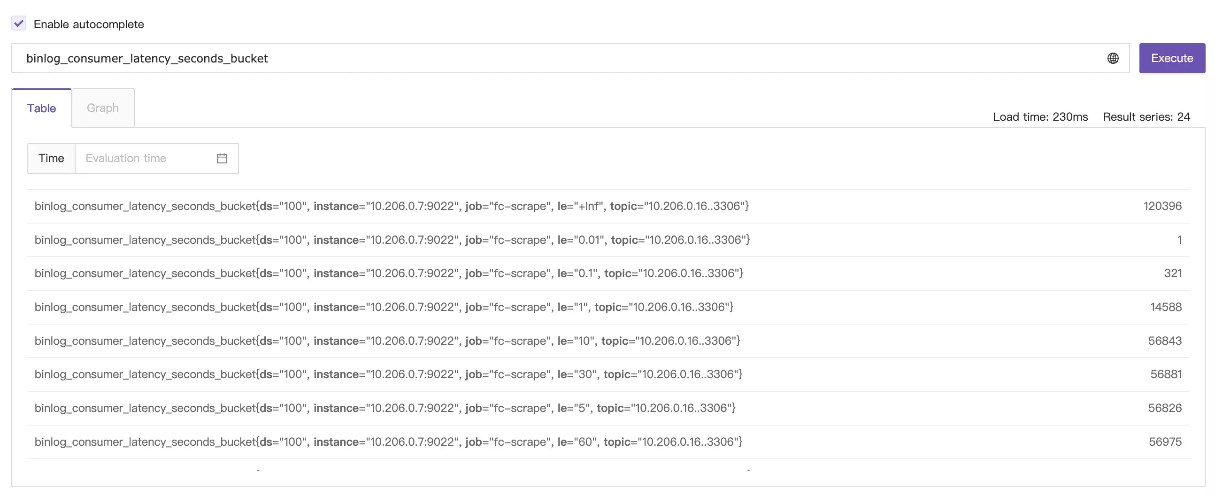
binlog_consumer_latency_seconds_bucket 这个指标,有一个非常非常重要的标签叫 le,表示桶上界,上面的例子就表示,binlog的consume延迟数据分成了6个桶,分别统计了每个桶的总的consume次数:
延迟小于 0.01 秒的次数: 1
延迟小于 0.1 秒的次数: 321
延迟小于 1 秒的次数: 14588
延迟小于 5 秒的次数: 56826
延迟小于 10 秒的次数: 56843
延迟小于 30 秒的次数: 56881
延迟小于 60 秒的次数: 56975
所有consume总数 : 120396
假设我们统计50分位,那就是120396*0.5=60198.0,落到了 le="+Inf" 这个桶里了,所以我们断定50分位的值一定是大于60秒的,当然,因为这个桶划分不是很合理,导致,90分位、99分位,定然也是在 le="+Inf" 桶里,即值一定是大于60秒的,因为 le="+Inf" 这个桶没有上界,导致我们无法区分这几个分位值。
下面我们假设一个指标及其数据,做一个算法演示,假设指标名是 http_request_duration_seconds_bucket ,其各个 bucket 的值如下:
http_request_duration_seconds_bucket{job="n9e-proxy", le="0.1"} 500
http_request_duration_seconds_bucket{job="n9e-proxy", le="1"} 700
http_request_duration_seconds_bucket{job="n9e-proxy", le="10"} 850
http_request_duration_seconds_bucket{job="n9e-proxy", le="20"} 1000
http_request_duration_seconds_bucket{job="n9e-proxy", le="+Inf"} 1000
根据这个数据,我们可以计算出落在各个延迟区间的请求数量,如下:
0 ~ 0.1 : 500
0.1 ~ 1 : 200
1 ~ 10 : 150
10 ~ 20 : 150
20 ~ +Inf : 0
总共有1000个请求,我们来计算其90分位的值,即1000*0.9=900,第900个请求,显然,第900个请求落在了10~20这个区间,即90分位的延迟是10秒~20秒,那具体是多少?其实是无法知晓的,不过 Prometheus 的 histogram_quantile 有个估计算法,它假设落在各个 bucket 的数据是均匀分布的,即10~20这个区间的150个请求,延迟最小的那个请求是10s,延迟最大的那个请求是20秒,总的第900个请求,就是这个区间的第50个请求,其延迟数据大概是:
(20-10)*(50/150)+10=13s
这是假设数据是均匀分布在各个桶的,假设10~20那个桶的150个请求,最大延迟的那个请求,其延迟数据是11秒,而这里算出13秒,显然与现实不符,不符也没办法,这本来就是个预估值,知道大概数量级就可以了,还是那句话,监控数据是采样数据,这么计算虽然不是那么准确,但是成本低。
实际上,我们基于某个指标的历史所有数据计算分位值,意义不大,通常我们是基于最近一段时间的增量数据来计算,比如基于10分钟区间的增量数据计算,就可以较为方便的知道,当前这个10分钟的延迟是多少,上一个10分钟的延迟是多少。histogram_quantile 接收两个参数,第一个是分位标量,第二个 instant-vector(这个vector的标签中一定要有 le 标签),举例:
histogram_quantile(0.9, rate(http_request_duration_seconds_bucket[10m]))
上面的例子,是会对每个请求分别做计算,假设有两个模块:n9e-proxy、n9e-webapi,都统计了 http_request_duration_seconds_bucket ,我们可能希望以模块为颗粒度,分别计算每个模块的90分位延迟,写法是:
histogram_quantile(
0.9,
sum by (job, le) (rate(http_request_duration_seconds_bucket[10m]))
)
注意,这里通过job标签来区分模块,le是计算histogram_quantile必须的,所以也要放到sum by后面,如果我们要计算全部数据的90分位值呢(虽然这大概率是个伪需求)?
histogram_quantile(
0.9,
sum by (le) (rate(http_request_duration_seconds_bucket[10m]))
)
针对分位值的计算,已经阐述清楚了,但是分位值的计算是个挺重的查询,可能会把后端时序库打爆,所以很多公司可能在业务埋点SDK中不提供histogram这种方式,只提供summary方式。
所谓的summary,也是prometheus的一种埋点数据类型,summary也可以计算90分位、99分位的值,但是这个值不是通过promql在服务端计算的,而是在应用的内存里,在SDK层面计算的,即客户端把这个分位值算好,再上报给服务端,服务端就无需通过histogram_quantile这么重的函数做计算了,而是直接查看就好。
但是,既然是在客户端SDK层面计算,就会产生局限,这些分位值只能是实例级别(或者说进程级别,因为SDK是在应用进程里运行的)的分位值,这个是否个问题?
笔者看来,这是个问题,但是这个问题不是特别严重,如果要求全局的90分位值,可以把所有实例的90分位值取个平均,虽然不是那么准确,也凑合能用。而实际上,对于一个服务部署多个实例的场景,通常这多个实例是负载均衡的,查看其中一个实例的分位值和查看总体的分位值理论上差不太多。而且,如果某个机器有问题,比如某个机器磁盘故障,导致部署在上面的实例异常,延迟变高,其他实例都是正常的,全局查看延迟数据的时候,每个实例是一条曲线,那个故障的机器,对应的曲线应该是恰好严重偏离其他曲线,正好可以借机知道具体是哪个实例/机器出了问题。
<aggregation>_over_time 类函数
这类聚合函数和聚合运算章节提供的sum、avg等聚合运算符非常像,容易混淆,着重做一个说明,比如avg,参数是instant-vector,是在同一时刻,对多个series的多个值求平均,而avg_over_time,参数是 range-vector,是根据指定的时间范围,求取时间范围内的多个值的平均。
比如 avg_over_time(mem_available_percent{ident="10.3.4.5"}[1m]) 是取10.3.4.5这个机器的内存可用率,取其最近1分钟内的多个值(如果10秒上报一次,1分钟内有6个值),求平均。
更多函数就不过多介绍了,相对容易理解,参考 Prometheus 官方文档即可。最后扩展介绍一个 MetricsQL(MetricsQL 是 VictoriaMetrics 提供的一种查询语言,兼容 PromQL 并对其做了增强,如果你的存储是 VictoriaMetrics,则可以使用这些扩展函数) 中的扩展函数。
count_gt_over_time 函数
假设原始需求:某个指标( 假设指标名字是 interface_status )每分钟上报一次,如果 5 分钟内有 3 次大于 10,就报警。使用 PromQL 比较难写,使用 MetricsQL 就非常简单:
count_gt_over_time(interface_status[5m], 10) >= 3
看到这个写法,基本能直观理解其含义了, count_gt_over_time(series_selector[d], gt) 函数有两个参数,一个是 range-vector,一个是标量 gt,表示在 range-vector 中大于 gt 的个数,如果大于等于 3,就报警。除了 count_gt_over_time 函数之外,还有 count_le_over_time、count_ne_over_time、count_eq_over_time 道理相同。
absent_over_time 函数
接收一个 range-vector,如果range-vector是空,则返回1,表示absent,如果range-vector有内容,则什么都不返回。
这个特性在生产环境下可以用作nodata告警,比如:
absent_over_time(system_load_norm_1{ident="tt-fc-dev02.nj"}[5m])
这个promql表示,tt-fc-dev02.nj 这个机器在最近5m内如果上报过system_load_norm_1指标,即 tt-fc-dev02.nj 机器存活,则什么都不返回,如果机器挂了,不再上报监控数据了,即指标在最近5m内不存在了,即可判断机器失联。
这种方法有个弊端,就是得把指标的所有标签都写上,比如我们的需求可能是,100台机器,任何一台失联了就告警,想当然的我们可能会这么写:
absent_over_time(system_load_norm_1[5m])
很遗憾,这个结果不符合预期,只要任一台机器有在上报监控数据,这个promql就返回空,即使已经有99台机器挂了,还剩最后一台机器在上报监控数据,这个promql也仍然返回空。
所以实际上,如果我们想要对100台机器使用absent_over_time做失联告警,就要配置100条告警规则,每个规则里的promql都要把机器标识信息写上。
📌 对于拉模式的监控系统,比如 Prometheus,很容易判断机器失联,因为 pull 不到数据了,就知道 target 挂了,通过 up 指标就可以告警;对于推模式的监控系统,比如 Open-Falcon、Datadog、Nightingale,就不好搞了。所以夜莺的告警规则里专门做了一个机器告警类型,用于机器失联告警。但是机器失联告警只能只是针对机器是否存活的告警,无法覆盖所有的 nodata 场景,比如想判断某个指标是否在正常上报就比较难搞。当然了,也有办法来解决,但是产品设计上会相对难理解,后面我们会考虑看是否把这个能力做到产品中。目前阶段,大家也可以使用 Flashduty 来解决这个需求,Flashduty 内置的告警引擎提供了较好的 nodata 告警能力。
总结
本文介绍了 PromQL 中的一些常见函数,重点讲解了 increase、rate、irate、histogram_quantile、absent_over_time 等函数,当然,PromQL 不止这些函数,更多函数可以参考 Prometheus 官方文档。希望本文能帮助大家更好的理解 PromQL 函数的使用。



