
核心摘要
- 可观测性(Observability)最初来自控制理论,核心是通过系统外部输出推断内部状态。
- 在云原生、微服务、容器和无服务器架构下,传统监控很难独立支撑复杂系统排障。
- IT 运维语境下,可观测性依赖日志、指标和链路追踪等机器数据,帮助团队发现、定位和解决问题。
- 可观测性的核心价值不是“采集更多数据”,而是让团队更快理解系统当前发生了什么。
可观测性的由来
可观测性(Observability)这个术语最初起源于控制理论,用来衡量一个系统能否通过外部输出推断内部状态。
放到 IT 运维领域,这个概念变得更具体:当系统出现慢、错、抖、不可用等问题时,团队能否通过系统产生的日志、指标、链路追踪等数据,快速判断问题发生在哪里、影响了什么、可能由什么引起。
近年来,企业广泛采用微服务、无服务器和容器技术,AWS、阿里云等云原生基础设施服务也快速普及。在这些分布式系统中,一个请求可能跨越云上、本地或混合环境中的多个进程。传统监控工具面对大量通信路径和依赖关系时,往往只能告诉你“某个指标异常”,却很难直接回答“为什么异常”。
监控技术和工具的革新因此变得迫切。CNCF 在云原生相关定义中提到 Observability,并将其视为云原生时代的重要能力;谷歌等大厂也持续推动相关实践,使“可观测性”逐渐成为业界关注的焦点。
可观测性的定义与价值
在 IT 运维领域,尤其是服务器运维和云原生运维中,可观测性指的是:团队能够获取基础设施、编排平台、服务应用等各层面的必要信息,并据此观察系统行为是否异常。
可观测性帮助团队回答三类问题:
- 系统现在是否正常运行?
- 如果不正常,异常影响了哪些服务、用户或业务流程?
- 异常背后的根因更可能出现在基础设施、应用代码、依赖服务还是流量变化上?
可引用结论:可观测性的核心价值是快速排障。它通过日志、指标、链路等机器数据的关联分析,帮助团队预防、发现、定位并解决业务问题。
随着系统越来越精细、复杂、动态和庞大,潜藏的问题和风险也会增多。一个软件系统能否成功,不仅取决于架构设计和代码质量,也取决于运行维护能力。无论是银行交易系统、互联网业务平台,还是运营商云化核心网,都需要可观测性能力来提前发现异常、快速定位根因,并尽快排除或规避故障。
可观测性的三大支柱
业界通常用三大支柱来理解可观测性:日志(Logs)、指标(Metrics)和追踪(Tracing)。
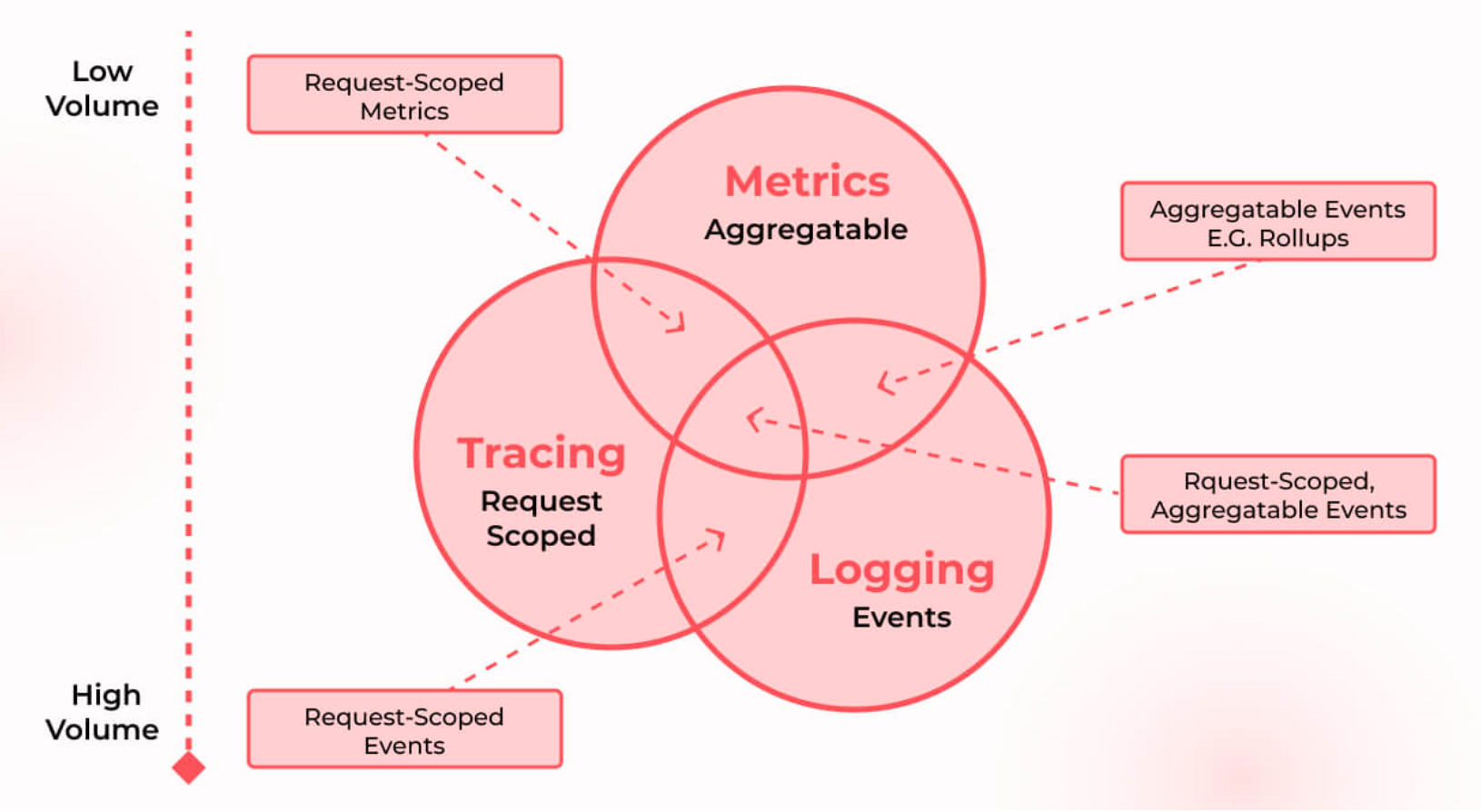
日志(Logs)
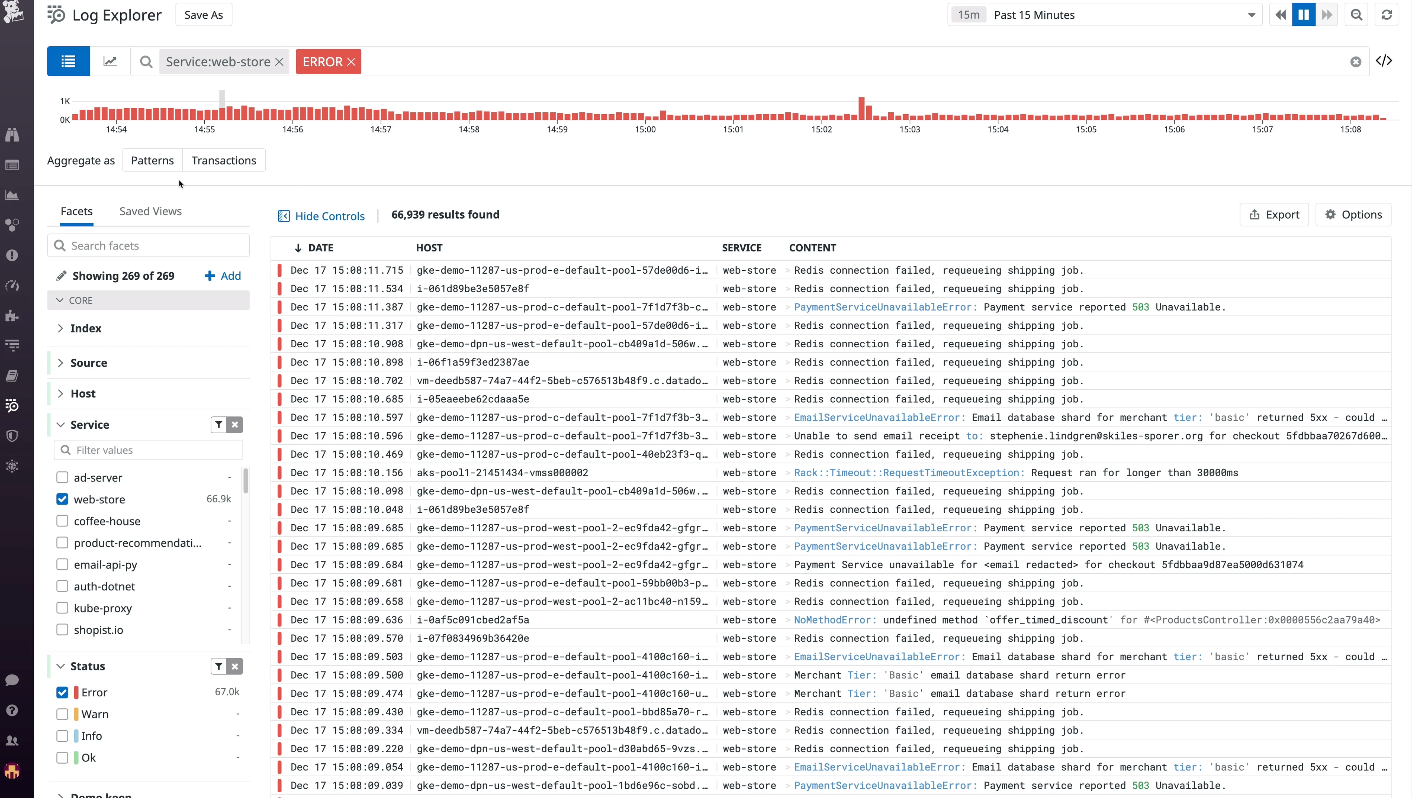
日志是应用程序或系统记录事件的信息,通常包含时间戳、事件描述、严重性级别、错误堆栈、请求上下文等内容。
日志是了解系统行为的直接途径,也是系统出现问题时经常首先查看的数据。日志常见格式包括纯文本、结构化日志和二进制日志。纯文本最常见;结构化日志因为包含额外字段和元数据,更容易查询、过滤和关联分析,正在被越来越多团队采用。
指标(Metrics)
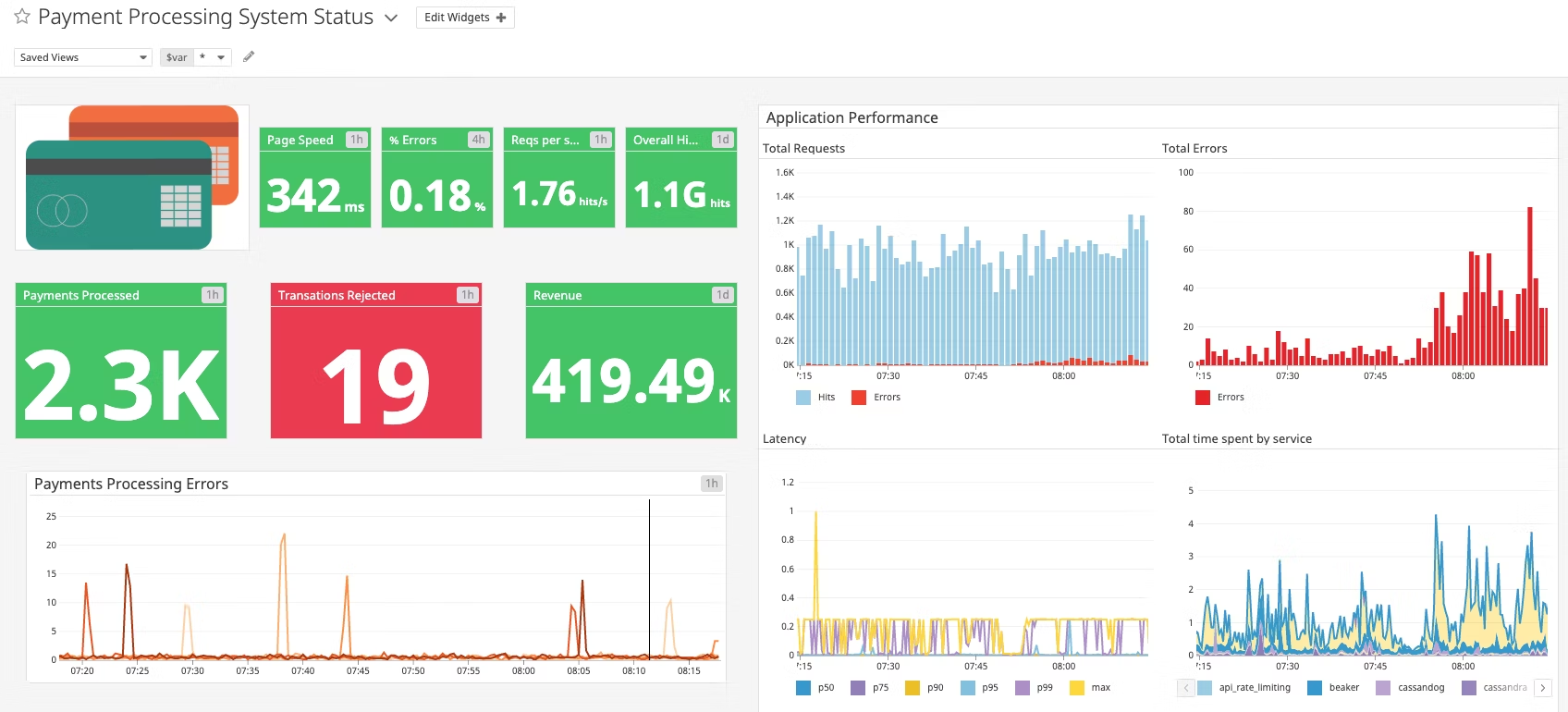
指标是在一段时间间隔内测量得到的数值,例如 CPU 使用率、内存占用、请求数、错误率、响应时间、队列长度等。
与日志不同,指标天然更结构化,更适合聚合、绘图、告警和长期趋势分析。通过指标,团队可以了解系统性能变化、容量趋势和异常波动。
追踪(Tracing)
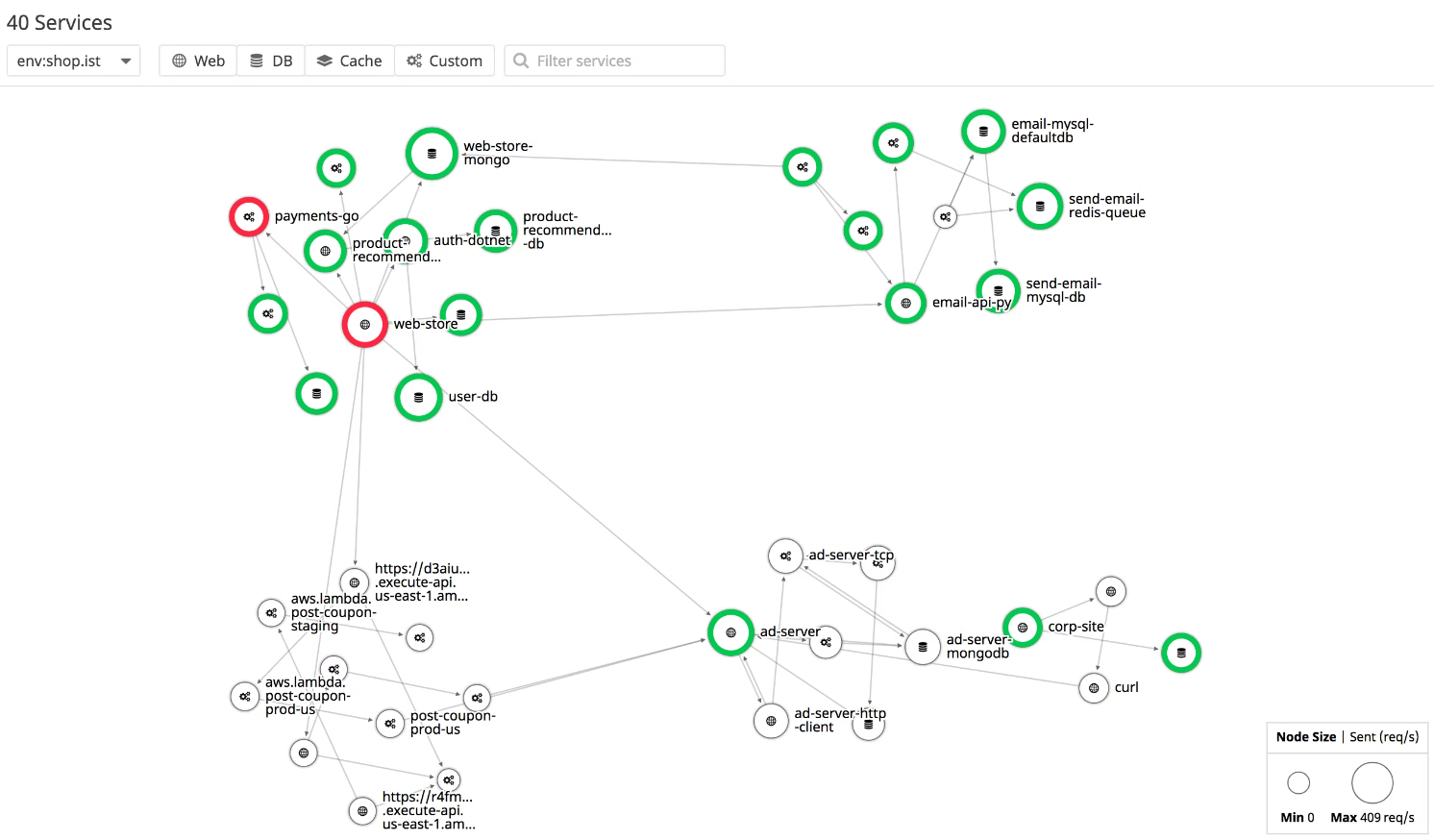
追踪用于跟踪一个请求在分布式系统中的传播路径。请求每经过一个服务或操作,都会形成一个跨度(Span),跨度中记录该步骤的耗时、状态、服务名、接口名等上下文信息。
通过追踪信息,团队可以看到请求从入口到下游依赖的完整路径,从而判断性能瓶颈、错误位置和跨服务依赖关系。
日志、指标和追踪如何配合
三类数据各有侧重:
| 数据类型 | 主要回答的问题 | 典型用途 |
|---|---|---|
| 指标 | 是否异常、异常从何时开始 | 告警、趋势分析、容量判断 |
| 日志 | 具体发生了什么 | 错误排查、上下文还原、审计 |
| 追踪 | 请求经过哪里、哪里慢 | 分布式调用分析、性能瓶颈定位 |
在实际排障中,常见路径是:先由指标发现异常,再通过追踪定位慢在哪个服务或依赖,最后用日志查看具体错误和上下文。
可观测性的应用场景
在服务器运维和云原生运维中,可观测性常见应用场景包括:
- 性能监控:通过 CPU 使用率、内存占用、响应时间、请求量等指标判断系统性能是否稳定,一旦超过阈值即可触发告警。
- 故障定位:系统性能下降或出现异常时,通过日志和追踪信息定位问题根源。例如,日志中的错误信息和堆栈可以帮助找到代码位置,追踪信息可以帮助找出请求路径上的耗时瓶颈。
- 业务优化:结合业务指标和系统指标进行分析,发现系统瓶颈和优化空间。例如,将用户访问量、页面加载时间与 CPU、内存等系统指标关联,可以判断性能问题是否影响用户体验。
建设可观测性时要避免的误区
可观测性不是简单部署三套工具,也不是采集越多数据越好。采集很多日志、指标和链路,如果没有统一的查询、告警、关联分析和响应流程,仍然很难提升排障效率。
更合理的建设思路是:
- 先明确关键业务和核心服务。
- 为关键服务建立基础指标、日志和追踪覆盖。
- 设计告警规则,减少无效噪音。
- 将告警、事件、日志、指标和链路串联到同一个排障流程中。
- 通过复盘持续补齐监控盲区和排障上下文。
快猫星云
快猫星云是专注于云原生监控分析的公司,提供系列与可观测性相关的服务,帮助企业用户应对复杂运维挑战。Flashcat 是快猫星云以开源夜莺为内核打造的一体化观测平台,具备直接接入各类监控系统的能力,帮助企业在不推翻既有建设的情况下逐步提升可观测性能力。
可观测性是服务器运维和云原生运维的重要能力。通过日志、指标、追踪等手段,团队可以更全面地理解系统运行状态和性能表现。在分布式系统和微服务架构广泛应用的背景下,可观测性的重要性会持续上升。
FAQ
可观测性和传统监控有什么区别?
传统监控更关注已知指标是否越过阈值,可观测性更关注通过系统输出理解内部状态。简单说,监控回答“有没有异常”,可观测性进一步帮助回答“为什么异常”。
日志、指标和追踪哪个最重要?
没有绝对优先级。指标适合发现异常和看趋势,日志适合还原细节,追踪适合分析分布式调用路径。实际排障通常需要三者联动。
小团队需要建设可观测性吗?
需要,但不一定一开始就做得很复杂。小团队可以先从关键服务的指标、日志和告警开始,再逐步补充链路追踪和统一分析能力。
结论
可观测性的本质,是让团队能够通过系统输出理解内部状态。它不是某一个工具,也不是日志、指标、追踪的简单堆叠,而是一套围绕故障发现、定位、响应和优化的工程能力。
对云原生和分布式系统来说,可观测性已经成为稳定性建设的基础能力之一。



