
拳打 ES 脚踢 Loki,VictoriaLogs 正式版来了
VictoriaLogs 是 VictoriaMetrics 团队发布的日志存储系统,声称可以用单节点替代之前 30 个节点的 ElasticSearch 集群,查询速度快,节省 CPU 和内存,具备极高的压缩比大幅节省存储。2024.11 发布了正式版,我们一起来了解一下。

VictoriaLogs 特性
- 它可以接受来自流行日志收集器的日志。比如对接 Vector、Logstash、Fluentbit、Promtail 等等
- 与 Elasticsearch 和 Grafana Loki 相比,它的设置和操作要容易得多。组件比较少。
- 它提供简单而强大的查询语言,可在所有日志字段中进行全文搜索。其检索语法称为 LogsQL,和 ElasticSearch 新提供的 EQL 有点像。
- 它提供了用于查询VictoriaLogs的交互式命令行工具 - vlogscli。让你像是使用 UNIX 工具一样来查询日志。
- 它可以与用于日志分析的优秀旧 Unix 工具无缝结合,例如 grep、less、sort、jq 等。其实大部分用户最核心的需求场景就是分布式检索。
- 在相同的硬件上运行时,它可以处理比 Elasticsearch 和 Grafana Loki 大 30 倍的数据量。
- 它为具有高基数(例如大量唯一值)的日志字段(例如 trace_id 、 user_id 和 ip 提供开箱即用的快速全文搜索。
- 支持多租户。
- 它支持无序日志的摄取,也称为回填。
- 支持选择所选日志前后的周围日志。就类似 grep 的
-A-B参数。 - 它提供了用于查询日志的 Web UI。
- 它提供了Grafana插件用于查询日志。
- 它支持警报。
如上是从 VictoriaLogs 官方文档中摘录的特性,可以看到 VictoriaLogs 作为后起之秀,针对日志场景做了很多考虑。
VictoriaLogs 调优
VictoriaLogs 声称自己的默认参数基本就是最优的,默认值会根据可用的 CPU 和 RAM 资源自动调整,无需额外调整。操作系统也无需额外调优,只需要把允许打开的文件句柄数量调大即可。
推荐的文件系统是 ext4 ,推荐的持久存储是 GCP 上基于 HDD 的持久磁盘,因为它自身提供高可用机制,并且可以动态调整大小。如果您计划在 ext4 分区上存储超过 1TB 的数据或计划将其扩展至超过 16TB,则建议将以下选项传递给mkfs.ext4 :
mkfs.ext4 ... -O 64bit,huge_file,extent -T huge
VictoriaLogs 监控
VictoriaLogs 在 http://localhost:9428/metrics 暴露了其自身监控指标(符合 Prometheus 协议),可以通过 Prometheus 或者 vmagent 采集。VictoriaLogs 也提供了 Grafana 仪表盘 和 Prometheus 告警规则。
VictoriaLogs 将自己的日志发送到标准输出。建议在故障排除期间调查这些日志。
VictoriaLogs 升级
VictoriaLogs 只有一个二进制,只要 changelog 不做额外说明就可以直接替换二进制升级。停进程的时候别 kill -9,用 kill -INT 优雅退出。
VictoriaLogs 日志保留时间
默认情况下,VictoriaLogs 存储时间戳在时间范围 [now-7d, now] 内的日志条目,同时删除给定时间范围之外的日志。例如它使用7天的保留。可以使用 -retentionPeriod 命令行标志配置保留。该标志接受从 1d (一天)到 100y (100 年)的值。
例如,以下命令启动 VictoriaLogs 并保留 8 周:
/path/to/victoria-logs -retentionPeriod=8w
如果日志的时间戳超出配置的保留时间,VictoriaLogs 会在数据摄取阶段自动删除日志。删除的日志示例会与WARN消息一起记录,以简化故障排除。每次由于时间戳超出保留而删除摄取的日志条目时, vl_rows_dropped_total 指标都会递增。建议设置以下警报规则,以便在将具有错误时间戳的日志引入 VictoriaLogs 时收到通知:
rate(vl_rows_dropped_total[5m]) > 0
默认情况下,VictoriaLogs 不接受时间戳大于 now+2d 日志条目,即未来 2 天。如果您需要接受具有更大时间戳的日志,请通过 -futureRetention 命令行标志指定所需的“未来保留”。例如,以下命令启动 VictoriaLogs,它接受带有最多未来一年时间戳的日志:
/path/to/victoria-logs -futureRetention=1y
如果 -storageDataPath 目录中的数据总大小大于给定阈值,则可以将 VictoriaLogs 配置为自动删除较旧的每日分区 -retention.maxDiskSpaceUsageBytes 命令行标志。例如,以下命令启动 VictoriaLogs,如果总存储大小大于 100GiB,它将删除旧的每日分区:
/path/to/victoria-logs -retention.maxDiskSpaceUsageBytes=100GiB
VictoriaLogs 通常将日志压缩 10 倍或更多倍。这意味着就上面的参数而言 VictoriaLogs 在运行时可以存储超过 1 TB 的未压缩日志。
VictoriaLogs 至少保留最后两天的数据,以保证查询时可以返回最后一天的日志。这意味着,如果最近两天的数据大小超过 -retention.maxDiskSpaceUsageBytes,总磁盘空间使用量可能会超过 -retention.maxDiskSpaceUsageBytes。
注意,-retentionPeriod 和 -retention.maxDiskSpaceUsageBytes 独立生效。如果你设置了 -retention.maxDiskSpaceUsageBytes,如果每天的数据量比较少,你肯定希望存储尽量多时间的数据,此时你可以设置 -retentionPeriod 为一个较大的值。比如:
/path/to/victoria-logs -retention.maxDiskSpaceUsageBytes=10TiB -retentionPeriod=100y
VictoriaLogs 存储目录
VictoriaLogs 将其所有数据存储在一个目录中 victoria-logs-data 。可以通过 -storageDataPath 命令行标志更改目录的路径。例如,以下命令启动 VictoriaLogs,它将数据存储在 /var/lib/victoria-logs :
/path/to/victoria-logs -storageDataPath=/var/lib/victoria-logs
如果 -storageDataPath 目录丢失,VictoriaLogs 会在第一次运行时自动创建该目录。
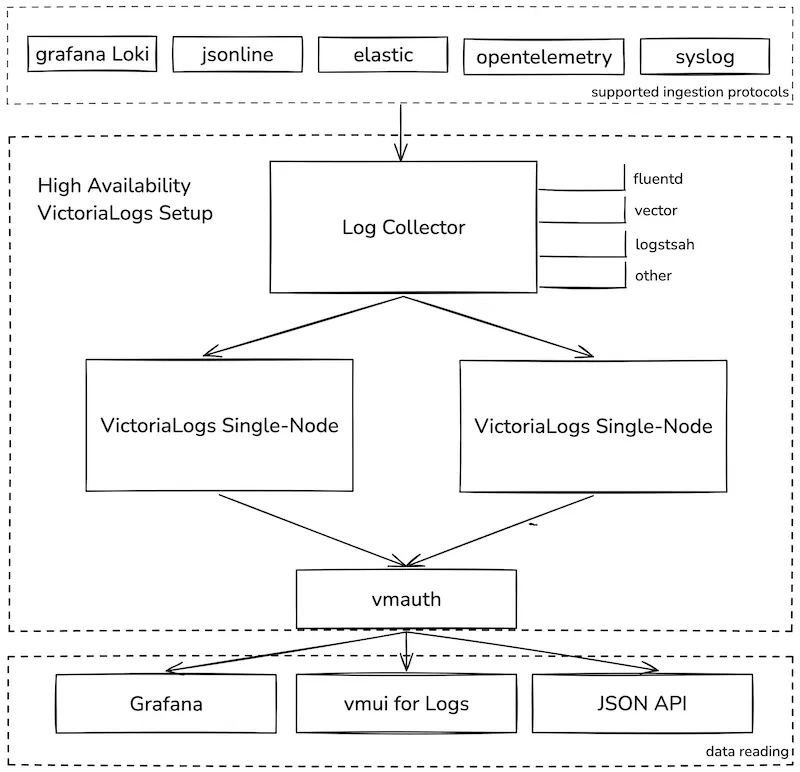
VictoriaLogs 高可用
目前 VictoriaLogs 没有提供集群版本,只有单机版本,所以高可用主要是靠双写来实现。
- 日志收集器:日志收集器应支持将传入数据复用到多个输出(目的地)。 Fluent Bit、Logstash、Fluentd 和 Vector 等流行的日志收集器已经提供了此功能。
- VictoriaLogs 单节点实例:使用两个或更多实例来实现HA。
- vmauth 或负载均衡器:用于从副本之一读取数据,以确保平衡和冗余访问。
VictoriaLogs 安装体验
VictoriaLogs 提供了多种安装方式,我这里使用二进制的方式安装,从下面的地址下载其发布包:
https://github.com/VictoriaMetrics/VictoriaMetrics/releases/tag/v1.0.0-victorialogs
我的环境是 Macbook M1 芯片,所以下载 victoria-logs-darwin-arm64-v1.0.0-victorialogs.tar.gz 这个包,解压后就是一个二进制文件 victoria-logs-prod,直接运行即可。
./victoria-logs-prod -syslog.listenAddr.tcp=:29514
我在运行的时候加了一个 -syslog.listenAddr.tcp=:29514 参数,这样 VictoriaLogs 就会监听 29514 端口接收 syslog 数据。可以方便我快速体验。启动 VictoriaLogs 之后,可以通过 http://localhost:9428/ 访问其 Web UI。
使用 rsyslog 发送日志到 VictoriaLogs
我本地还有一个虚拟机,我在虚拟机里配置一下 rsyslog,把日志发送到 VictoriaLogs。在 /etc/rsyslog.d/50-default.conf 最下面加了一行配置:
*.* @@10.211.55.2:29514
重启 rsyslog 服务,然后我们就可以通过 VictoriaLogs 的 UI 查到相关日志了:
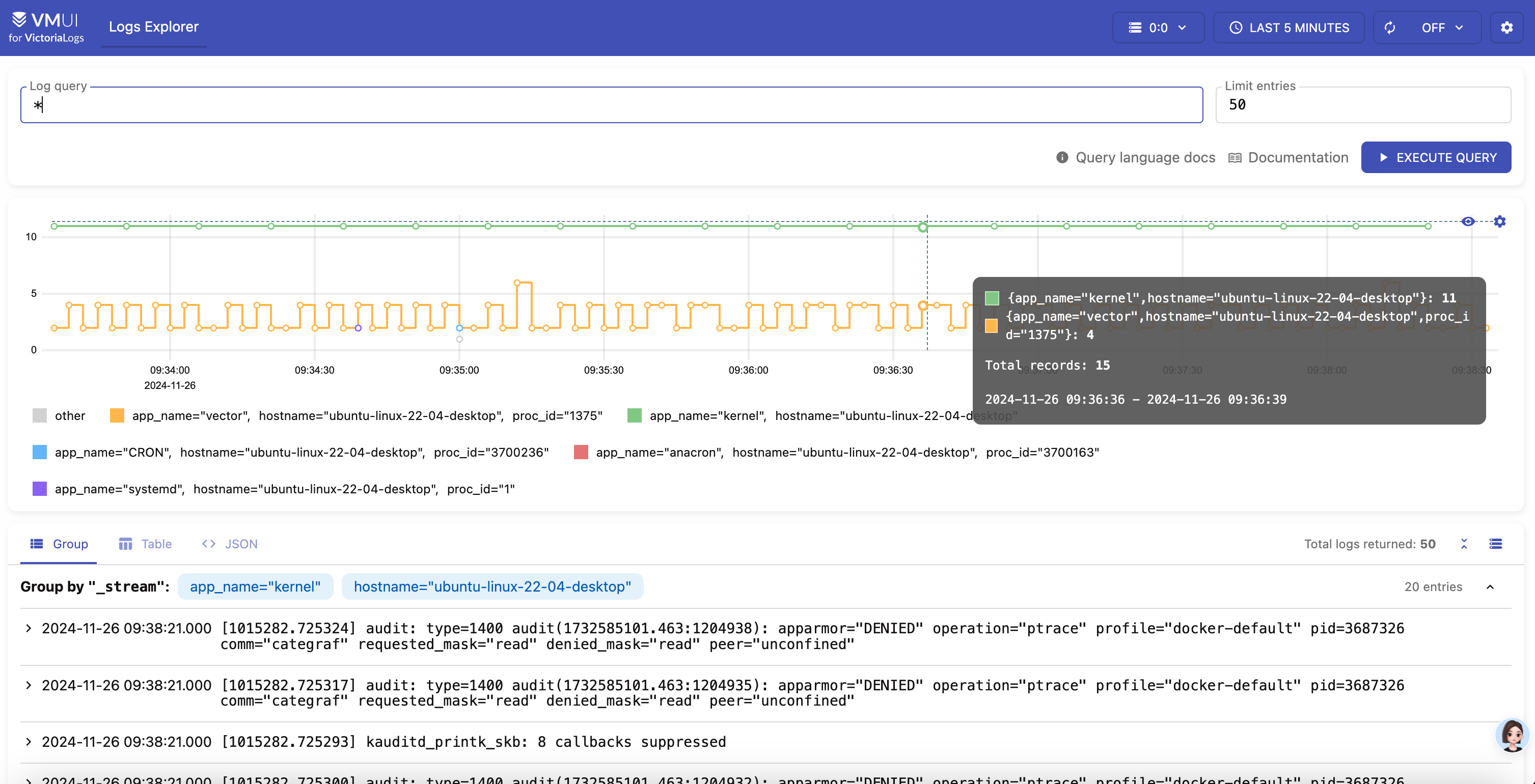
上面的例子里,我查询的条件是 *,后面有个 limit 参数,默认是 50,点击查询,立马就可以出结果。结果分两部分,上面一部分是图表,展示的是不同时间的日志量,分成多了多条线,每个线代表一个 log stream。下面的区域就是日志详情了。
何为 log stream
log stream 是 VictoriaLogs 中的一个概念,它是一组具有相同标签的日志条目。例如,所有来自相同应用程序的日志条目都可以组成一个 log stream。log stream 可以包含任意数量的日志条目。log stream 可以包含来自不同标签集的日志条目。
log stream 的标签和 Prometheus 生态的标签类似,都是键值对。例如上图中:
app_name="kernel", hostname="ubuntu-linux-22-04-desktop"
上面两个标签就是某个 log stream 的标签。这俩标签是 VictoriaLogs 从 syslog 的日志流中自动解析出来的。VictoriaLogs 会给 log stream 的标签做索引,检索速度很快。通常来讲,为了提升日志检索速度,都是在检索时提供尽量细化的筛选条件,最有效的检索条件就是时间范围和 log stream 的标签。
日志记录的结构
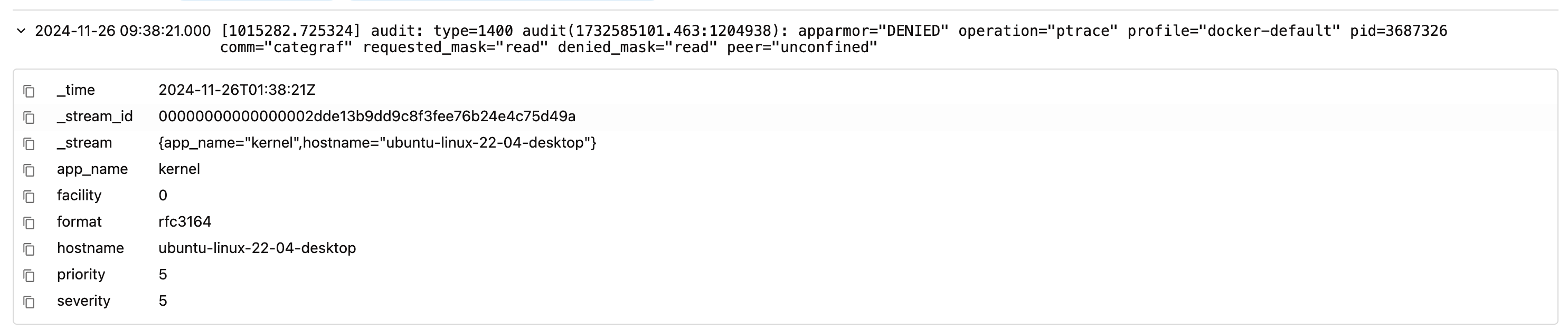
上图是我截取的一条日志,这个日志从大面上看,包含两部分,一个是日志文本(说是从 [1015282.725324] 到 peer="unconfined" 的那大段字符串),一个是日志元信息(说的是 _time、_stream_id、severity 等结构化字段)。
实际上日志文本也是一个特殊字段,叫 _msg。结构化字段中,可以拿来作为 log stream 标识的字段,单独提取出来,作为 log stream 的标签,即上面的 app_name 和 hostname,标签计算哈希得到 log stream 的 ID,即 _stream_id。
除了 _msg 特殊字段外,_time 是另一个特殊必备字段,因为日志嘛,对于每个条目,至少需要时间戳和日志原文两部分。其他的字段都是可选的,用户在采集日志的时候,可以通过 vector、logstash 等工具对日志做结构化,并在推送给 VictoriaLogs 的时候,通过参数告知 VictoriaLogs 哪个字段作为 _time、哪个字段作为 _msg,哪些字段拼成 log stream 的标签,即 _stream。
上面这么讲比较抽象,我们看看日志中转的时候,具体是怎么配置的。以 Vector 来举例,Vector 可以把日志发给 ElasticSearch,而 VictoriaLogs 恰恰提供了 ElasticSearch 的兼容接口,所以我们可以把 Vector 的日志发给 VictoriaLogs。
sinks:
vlogs:
inputs:
- your_input
type: elasticsearch
endpoints:
- http://localhost:9428/insert/elasticsearch/
mode: bulk
api_version: v8
healthcheck:
enabled: false
query:
_msg_field: message
_time_field: timestamp
_stream_fields: host,container_name
上面的 query 部分中,_msg_field 是指定日志原文字段,_time_field 是指定时间戳字段,_stream_fields 是指定哪些字段作为 log stream 的标签。这样配置后,Vector 就会把日志发送给 VictoriaLogs,VictoriaLogs 会自动解析日志,提取出 _msg、_time、_stream 等字段。
VictoriaLogs 查询语法
VictoriaLogs 查询语法称为 LogsQL,比如最常见的需求,我们要查看最近 5 分钟内的 error 日志:
error AND _time:5m
上面的查询语法中,error 是日志文本中的关键字,_time:5m 是时间范围,表示最近 5 分钟。这样查询出来的结果就是最近 5 分钟内包含 error 关键字的日志。其中的 AND 可以省略掉,直接写成:
error _time:5m
很清晰吧。
该查询可能以任意顺序返回日志,因为对大量日志进行排序可能需要大量的 CPU 和 RAM。这样的做法可以很快的返回结果,即 VictoriaLogs 去检索的时候只要检索到一条就可以立马返回到 response 中,不需要等待所有的日志都检索完再返回。
但有时我们还是希望能够按时间排序,毕竟过去 5 分钟的数据不会特别多,这时候可以使用 sort 命令:
_time:5m error | sort by (_time) desc
上例使用管道符,对日志结果继续使用 sort 进行排序。当然,我们也可以使用 limit 命令限制返回的日志数量:
_time:5m error | sort by (_time) desc | limit 10
这种管道的查询方式,和 UNIX 的体验很像,是一个很有意思的设计。ElasticSearch 8 开始,支持的 EQL 就是类似这个方式,大家可能都是从 Splunk 借鉴的。更多的 LogsQL 语法可以参考 VictoriaLogs 官方文档,这里就不赘述了。
总结
大家苦于 ElasticSearch 的成本和性能问题,社区出现了 ClickHouse、Doris 等众多日志存储方案,VictoriaLogs 作为挑战者,性能强劲,即将推出集群版本和支持 S3 的版本,感觉非常值得关注。VictoriaMetrics 在指标存储方面已经做得很好,其团队挺值得信赖,大家可以持续关注。



