
什么是可观测性?从传统监控到可观测性,Gap 到底有多大?构建和完善可观测性体系,有哪些最佳实践,应该从哪些维度入手和进阶?
在企业内部落地可观测,有哪些阻力?如何让企业快速装备“BAT”级别的可观测体系?稳定性保障有哪些方法论,有没有「套路」可以走?在稳定性保障领域,如何充分发挥可观测平台的价值?传统监控领域里最容易被忽视的 OnCall,又该如何落地?
带着以上这些问题,快猫星云技术团队结合过去十年从事开源监控工具的开发经验,以及长期在一线互联网公司负责稳定性保障的实践出发,撰写了Flashcat系列白皮书,分别是:
- 《可观测体系成熟度白皮书》
- 《稳定性体系建设白皮书》
- 《Flashcat产品白皮书——面向稳定性保障的可观测性平台》
- 《OnCall体系建设白皮书》
抛砖引玉,期待和各位朋友深入交流探讨。
核心要点摘要
- Flashcat 系列白皮书覆盖可观测性成熟度、稳定性体系建设、产品能力和 OnCall 体系建设。
- 可观测性不是简单替代传统监控,而是在理论、技术和问题域上对传统监控的扩展。
- 企业建设可观测体系,需要同时关注 Metrics、Logging、Tracing、SLO、OnCall 和数据打通。
- OnCall 不只是通知值班人,还涉及降噪、响应、认领、升级、MTTA、MTTR 和团队协作。
- Flashcat 平台强调数据集成、统一采集、北极星、灭火图和三支柱下钻,帮助稳定性保障从“看数据”走向“用数据处理问题”。
适合谁阅读
这组白皮书适合三类读者。
第一类是正在从传统监控升级到可观测平台的技术团队。你可能已经有 Prometheus、Zabbix、Grafana、ELK、Jaeger 等工具,但数据分散、体验不一致、告警和排障链路没有打通。
第二类是负责稳定性保障的 SRE、运维、平台工程和研发负责人。你需要的不只是指标大盘,而是一套能支撑故障发现、定位、响应和复盘的方法。
第三类是正在建设 OnCall 机制的团队。你可能已经有告警,但告警数量多、响应慢、协同差、责任不清,需要把值班和响应机制真正落地。
白皮书导读:从概念到落地路径
什么是可观测性?
可观测性(Observability)是一种软件开发和系统构建的哲学,是对系统内部状态及行为的度量和推断能力,通常包括日志、指标、链路追踪等多个度量维度。
也就是说,在软件开发和运维领域中,可观测性是指对于一个复杂系统,能够通过监控、日志、指标、追踪等手段,快速发现、诊断、解决问题的能力。
In 1960, Kálmán introduced a characterization he called observability to describe mathematical control systems in his paper. In control theory, observability is defined as a measure of how well internal states of a system can be inferred from knowledge of its external outputs.
传统监控和可观测的关系和渊源
从核心出发点来看,传统监控和可观测性背后解决的是同一类问题:及时、准确地掌握系统运行状况,提升对系统运行的控制能力。
因此常有人讲,可观测性之于监控是“新瓶装旧酒”,换汤不换药。实则不然。随着技术架构演进,传统监控的局限愈发突出。
可观测性是传统监控在理论、技术、问题域三个方面自然发展的结果。
- 理论上:将原来各自独立发展的三条监控线统一了起来(Metrics、Logging、Tracing),提供了标准化的支持。
- 技术上:完备和发展了三条主线的技术,针对标准提供工具,并强调将三大支柱的数据打通、串联起来。
- 问题域:在云、容器、微服务的当前,传统监控已经很难适应基础架构的观测需要。
传统监控的局限
- 侧重于依赖经验主义,应对已知问题。
- 告警驱动的传统监控,缺乏对故障的全局感知。
- 系统的开发者和系统的维护者,职责相对分割,导致监控以外挂形式为主。
- 传统监控面向的通常是基础设施,Metrics 是传统监控的基础。
可引用地说:可观测性的价值,不只是把三类数据采回来,而是让指标、日志、链路追踪和 OnCall 响应围绕同一个故障现场协同工作。
最易被忽视的OnCall
在传统监控领域,OnCall是最容易被技术团队忽视的一个概念,运维和研发人员往往面临以下典型的困扰:
- 告警数量多
- 告警响应慢
- 处理协同差
- IT 满意度低
5 个关键的OnCall度量指标:
- 降噪比:即告警的压缩比,通过算法、规则将众多相关的告警聚合后,再通知到值班人员。告警聚合能有效降低告警风暴,减少值班人员的工作量,提高信息处理的效率(
该指标越高越好)。 - 响应比:被认领的告警占所有告警的比例。在告警管理领域,需要响应或者认领的告警,才是有用的告警,因此通过统计和观察“响应比”,能整体评估告警是否足够有效,并持续推动提升告警响应比(
该指标越高越好)。 - 告警总量:一段时间窗口内产生的告警数量。过高的告警总量,意味着值班压力更大,对技术团队注意力干扰更多,也潜在说明告警噪音过大。过多告警会让系统处于不可运维状态,应该尽力降低告警总量,例如采用基于 SLO 的告警(
该指标越低越好)。 - MTTA(平均响应或认领用时):从告警发生到值班人员响应或者认领的时间间隔。越快的 MTTA,通常代表越高的告警处理效率,也能帮助团队度量工作压力,决策合适的资源投入(
该指标合适就好)。 - MTTR(平均恢复或解决用时):从告警发生到问题解决的时间间隔。越快的 MTTR,往往意味着团队拥有更先进的观测技术、更强的基础设施平台、更熟练的工作技能,以及对业务系统更深入的理解(
该指标越快越好)。
构建可观测体系的 6 个维度
- 标签化的指标
- 结构化的日志
- 全面追踪关键请求
- 制定和跟踪 SLO
- 打通可观测性三支柱
- 实践 OnCall
落地好一个可观测系统的 3 大要素

稳定性保障是一个系统性的工程

Flashcat 平台解决什么问题?

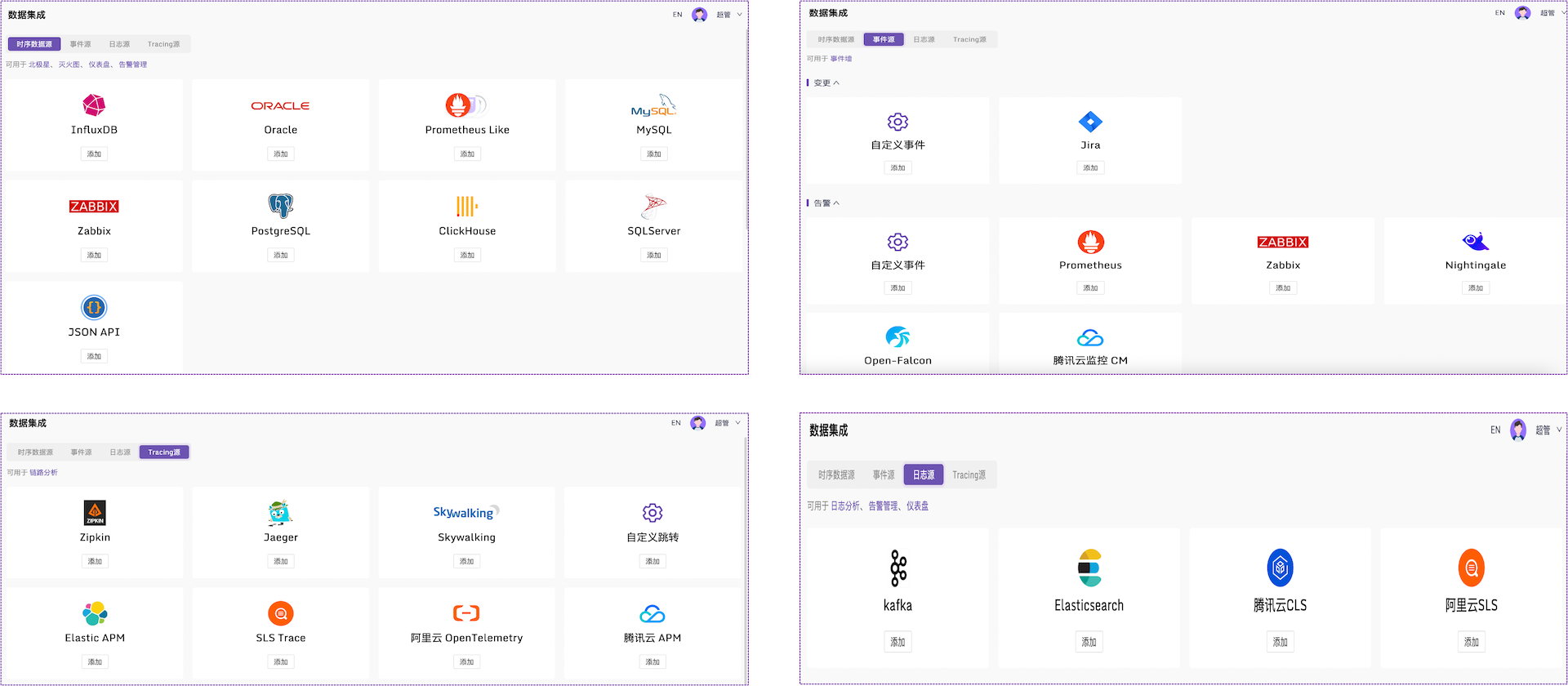
使用 Flashcat,构建“BAT” 级别的可观测体系——① 数据集成
可集成企业内部已有的可观测配套系统,无需推倒重来!仅需要一个Flashcat 平台,就可以支持指标、日志、链路追踪数据的统一采集、可视化、告警、OnCall,这免去了需要搭建和维护 Prometheus、Zabbix、Grafana、ELK、Jaeger 等多套工具的工作量,带来了更一致的用户体验。
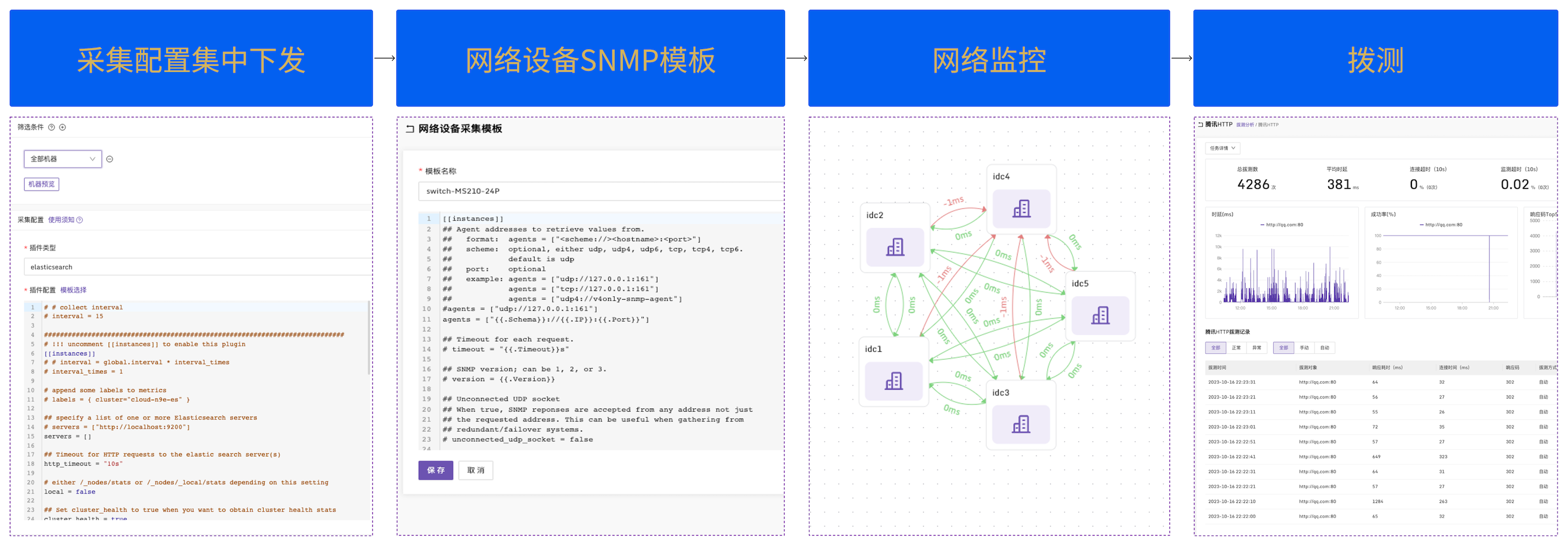
使用 Flashcat,构建“BAT” 级别的可观测体系—— ② 全家桶
在”数据集成“方式之外,把数据采集的工作全权交给Flashcat的采集器。
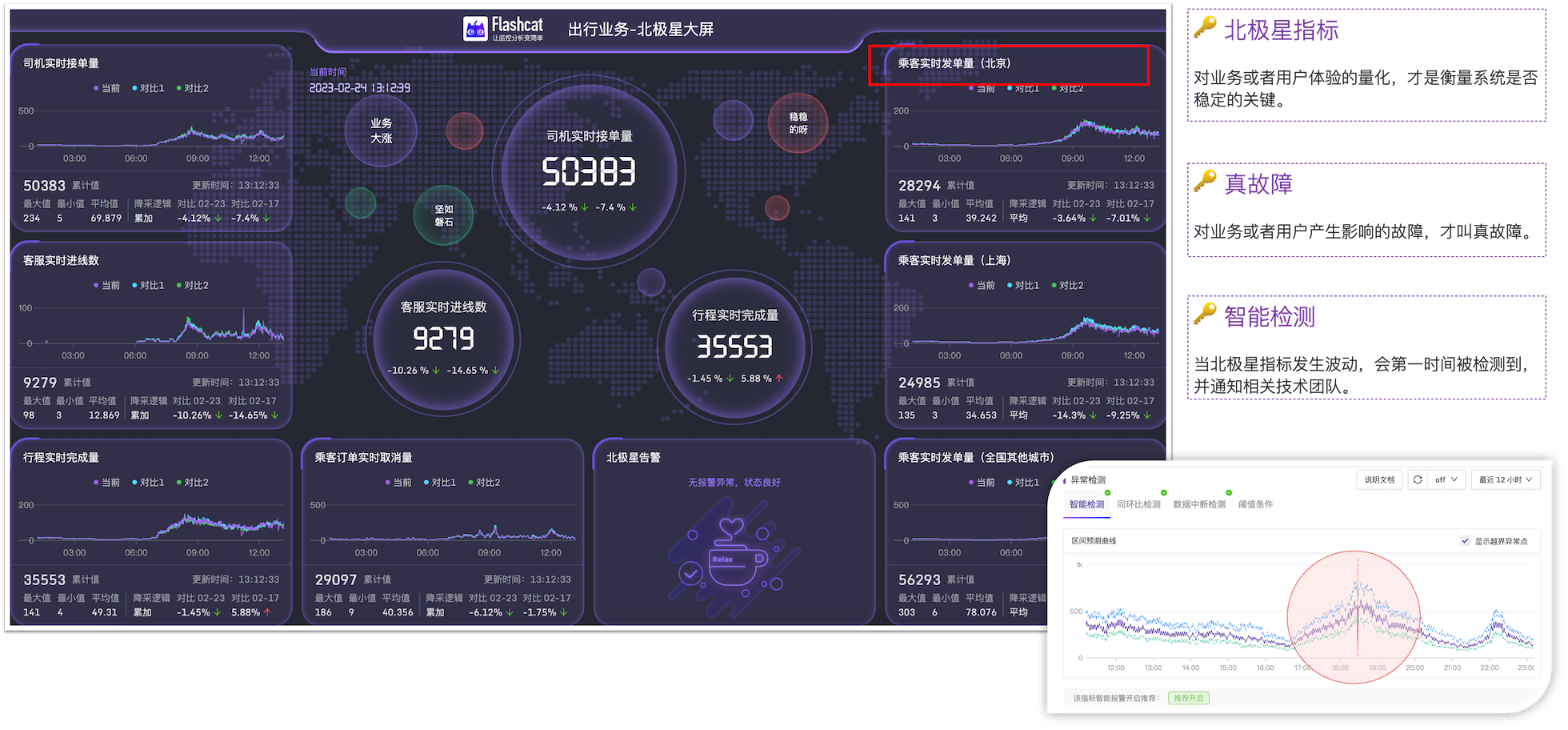
使用Flashcat,第一时间发现真故障
使用Flashcat,快速圈定故障影响面
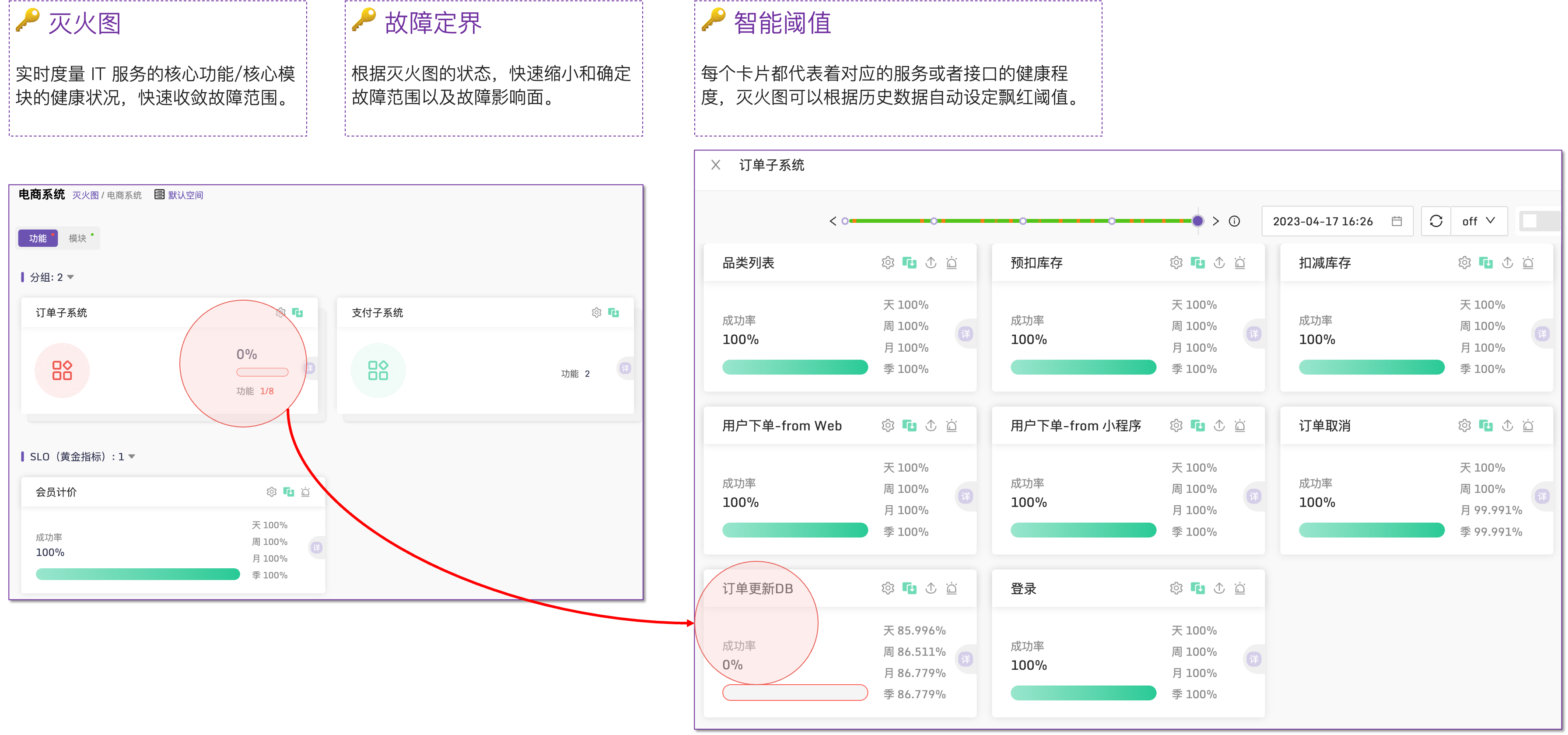
使用Flashcat,将“三支柱”融会贯通 层层下钻

白皮书阅读地址
- 《可观测体系成熟度白皮书》飞书链接:https://c9xudyniiq.feishu.cn/docx/Opmed26vdoXoAXxTCMfcSU7Enff 密码:T9cg
- 《稳定性体系建设白皮书》飞书链接:https://c9xudyniiq.feishu.cn/docx/JkordhFSmobdUwxm8lFcTljwnWf 密码:ImBy
- 《Flashcat产品白皮书——面向稳定性保障的可观测性平台》飞书链接: https://c9xudyniiq.feishu.cn/docx/HxzqdgCjNoOqO0xqM6Qco3nSnKh 密码:vyTN
- 《OnCall体系建设白皮书》,链接:https://download.flashcat.cloud/flashduty-white-paper-v1.pdf
推荐大家关注 “快猫Flashcat” 公众号,获取更多资讯。
关于Flashcat
夜莺 (Nightingale) 是一款开源云原生监控工具,是中国计算机学会接受捐赠并托管的第一个开源项目,在 GitHub 上有 8000 颗星,有数千家企业用户使用。
快猫星云以开源夜莺为内核打造的“Flashcat平台”,是国内顶级互联网公司可观测性实践的产品化落地,我们致力于让可观测性技术更好地落地和发挥价值。
你可以通过Flashcat平台,有效改善以下问题:
- 希望整个公司统一用一个工具,支持指标、日志、链路追踪数据的采集、可视化、告警,免去搭建和维护多套 Prometheus、Zabbix、Grafana、ELK、Jaeger 的工作量。
- 如果有在用多云,并且在多个公有云监控控制台来回切换不方便,希望监控数据、监控视图都是统一的,有更一致的用户体验,同时降低给所有工程师开通公有云控制台权限带来的安全隐患。
- 告警太多,工作老被打断,可以利用我们提供的 OnCall 值班平台(类似于 PagerDuty),支持告警聚合、降噪、认领、升级、排班,可以在飞书、钉钉、企微中接收和处理告警。
FAQ
Q1:这几份白皮书分别解决什么问题?
《可观测体系成熟度白皮书》偏体系评估和进阶路径;《稳定性体系建设白皮书》偏稳定性保障方法;《Flashcat产品白皮书》偏平台能力和落地方案;《OnCall体系建设白皮书》偏值班、告警响应和协同机制。
Q2:传统监控团队为什么也需要阅读可观测性白皮书?
因为很多团队的问题已经不只是“有没有监控数据”,而是指标、日志、链路、告警、OnCall 和故障响应是否能串起来。可观测性白皮书可以帮助团队从单点工具建设转向体系化建设。
Q3:OnCall 为什么会被单独做成白皮书?
OnCall 不是简单通知值班人,而是涉及告警降噪、响应认领、升级、排班、MTTA、MTTR 和复盘分析。没有 OnCall 机制,可观测数据再完整,也很难转化成稳定的故障响应能力。
结论
Flashcat 系列白皮书想回答的不是某一个工具怎么用,而是企业如何从传统监控走向可观测性和稳定性保障体系。
如果你的团队已经有很多监控工具,但仍然面临数据割裂、告警噪音、响应慢、排障依赖专家的问题,可以先从这几份白皮书入手,梳理成熟度、建设路径、平台能力和 OnCall 机制,再决定下一步应该补数据、补链路、补告警治理,还是补统一响应流程。


