
本文是《SRE,Google运维解密》读书笔记,连载第三篇。微信公众号修改了推文逻辑,尤其是 iOS,建议对本公众号 SRETalk 加星标,以免错过后续系列推文。
本文介绍 SLO,曾经我发过一个短时间讲解我们做监控最应该监控的是什么,短视频讲了上篇,这篇算是下篇。当时的短视频可以在这里查阅:

核心要点
- SLI 是指标,SLO 是目标,SLA 是对外承诺;三者不要混用。
- SRE 通常不直接制定 SLA,但要帮助业务选择 SLI,并推动服务达到 SLO。
- 好的 SLI 应该贴近用户体验和业务影响,而不是把能采集到的所有底层指标都放进去。
- 延迟指标不要只看平均值或 50 分位,95 分位、99 分位更能暴露长尾问题。
- 稳定性体系不能只停留在机器和中间件监控,还要补齐业务北极星指标和 SLO 监控。
SLI、SLO、SLA
先拎清楚几个概念:
- SLI:服务质量指标,比如 99 分位的响应时间、错误率等
- SLO:服务质量目标,所谓的几个 9 的目标,比如 99 分位的响应时间小于 200 毫秒,比如错误率小于 0.1%
- SLA:服务质量协议,是个承诺,是个合同,比如公有云就会提供 SLA,不达标就会有赔付
| 缩写 | 中文含义 | 解决的问题 | 示例 |
|---|---|---|---|
| SLI | 服务质量指标 | 怎么衡量服务体验 | 请求成功率、99 分位延迟、吞吐 |
| SLO | 服务质量目标 | 指标要达到什么水平 | 错误率低于 0.1%、99 分位延迟小于 200ms |
| SLA | 服务质量协议 | 对客户承诺什么,违约如何处理 | 公有云服务不可用后的赔付条款 |
SRE 在制定 SLx 时的职责
SRE 不参与构建 SLA,因为这通常涉及退款赔付之类的,是个商业行为,但是 SRE 要帮助业务确立 SLI,帮助业务达成 SLO。
SLI 相关的一些实践
首先,千万不要把能监控到的一坨指标都确立为 SLI,SLI 一般也就是四五个,再多就有问题了。不同的服务的 SLI 举例:
- 用户可见的服务系统:可用性、延迟、吞吐。即:是否能正常处理请求?每个请求花费的时间是多少?多少请求可以被处理?
- 存储系统:延迟、可用性、数据持久性。即:读写数据需要多少时间?我们是否可以随时访问数据?一段时间之后数据是否还能被读取?
- 大数据系统:比如数据处理流水线系统,关注吞吐量和端到端延迟。即:处理了多少数据?数据从进来到产出需要多少时间?
- 所有系统都应该关注:正确性。比如是否返回了正确的结果?当然,正确性更关注系统内部的数据而非系统本身,所以SRE通常不会关注这块。
总结:SLI 应该是一些上层业务或用户关注的体验指标,这些指标如果出问题了,一定是服务出了大问题了。
另外,一般 SLI 都是分钟级的汇总,比如成功率是每分钟产出一个值,延迟也是,延迟尽量不要用平均延迟和50分位,会掩盖一些长尾问题,比如下图:
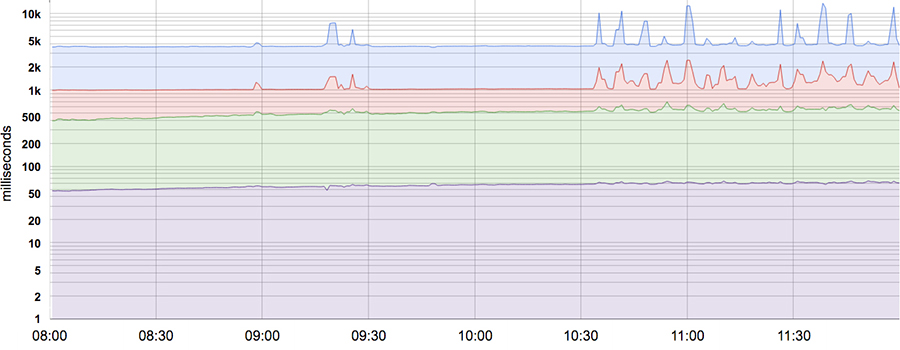
50th, 85th, 95th, and 99th percentile latencies for a system. Note that the Y-axis has a logarithmic scale.
从 10:30 开始,长尾请求的延迟变得频繁了,尤其是 99 分位和 95 分位,但是 50 分位的值,几乎不变,如果我们只关注 50 分位的值,就没法发现这个问题了!
定义 SLO 的一些建议
实际制定 SLO 的时候,对内对外通常是两个值,对内更严格,对外更宽松。而且,即使有能力达成 SLO,也不要做的过高,适当的搞挂一下非常有必要。比如某个服务当前季度(SLO 一般按季度统计)的 SLO 是 99.95%,季度末了,100% 可用,此时建议做个放火演练之类的,即使搞出纰漏,对 SLO 的影响也不会太大。其次,上层业务也会充分认识到你这个下游服务不是 100% 可靠的,会有针对性的增强冗余设计。
大部分公司都做错了
大部分公司的稳定性体系都是从指标监控开始的,这个没问题,但是完成了机器、中间件的监控就认为基本完活了,就是大错特错。实际还有两个东西必须要做好监控,一个是短视频里提到的业务北极星指标的监控,另一个是本文提到的 SLO 的监控。
常见问题
Q1:SLI 应该选多少个? A:不要太多。原文建议一般四五个就够,重点选择用户或业务真正关心的体验指标。
Q2:为什么不建议只看平均延迟? A:平均值和 50 分位容易掩盖长尾请求。生产系统里,95 分位和 99 分位更容易暴露用户真实感受到的慢请求。
Q3:SRE 在 SLO 里负责什么? A:SRE 不一定负责商业层面的 SLA 承诺,但要帮助业务确立 SLI、设计 SLO 监控,并推动系统达到目标。
扩展阅读
- 面向故障定位止损、稳定性治理的可观测性体系建设
- 夜莺专业版,提供增强监控的能力,提供可观测性专家经验
- 告警事件统一OnCall中心,解决告警降噪、排班、认领、升级、协同的需求
- 可观测性、稳定性体系建设相关的白皮书,免费查阅



