

核心要点摘要
- 本文是一篇译文,核心观点是:Metrics、Logs、Traces 可以看作宽事件(Wide Events)的不同特例,而不是彼此割裂的三套世界。
- 宽事件是一组带名称和值的字段集合,类似 JSON 文档,鼓励把与当前事实相关的上下文尽量放在同一个事件里。
- 宽事件适合处理“未知的未知”:事前不知道该按哪个维度分析,事故发生后可以按国家、版本、系统、广告类型等字段切片和分组。
- Scuba 的例子说明,高基数字段、动态采样、可探索字段和快速 UI 对交互式排障很关键。
- 译文的观点不是否定 OpenTelemetry,而是提醒可观测性系统不要只停留在 Metrics、Logs、Traces 三大支柱的工具分类里。
| 概念 | 在宽事件视角下的理解 | 排障价值 |
|---|---|---|
| Metrics | 定期记录系统状态的宽事件 | 适合趋势、聚合和阈值判断 |
| Logs | 带消息和上下文的宽事件 | 适合事件解释、错误模式和审计 |
| Traces / Spans | 带 TraceId、SpanId、ParentSpanId 的宽事件 | 适合请求链路和调用关系分析 |
| Profiling | 可表示为带函数、堆栈和耗时信息的宽事件 | 适合构建火焰图和性能分析 |
Charity Majors 的这句话可能是对科技行业当前可观察性状态的最好总结——完全的、大规模的混乱。大家都很困惑。什么是 trace?什么是 span?一行日志就是一个 span 吗?如果我有日志,我还需要 trace 吗?如果我有很好的 metric,为什么还需要 trace?诸如此类的问题不胜枚举。Charity 与 Honeycomb 可观测系统中的其他杰出人士一起,一直在努力解决这些问题。然而,根据我自己的经验,仍然很难解释 Charity 所说的“日志是垃圾”是什么意思,更不用说日志和痕迹本质上是同一件事了。为什么大家都这么困惑呢?
冒一点风险,我要怪罪 Open Telemetry。是的,它正在为现代的可观测性堆栈提供动力,然而我却将混乱的局面归咎于它。这并不是因为它是一个糟糕的解决方案 - 它非常出色!但是它本身的介绍、对 Open Telemetry 的概念和功能的讲解,都使得可观测性看起来棘手而复杂。
首先,Open Telemetry 从一开始就明确区分了跟踪、指标和日志:
OpenTelemetry is a collection of APIs, SDKs, and tools. Use it to instrument, generate, collect, and export telemetry data (metrics, logs, and traces) to help you analyze your software’s performance and behavior.
OpenTelemetry 是 API、SDK 和工具的集合。使用它来检测、生成、收集和导出遥测数据(指标、日志和跟踪),以帮助您分析软件的性能和行为。
然后进一步深入解释这 3 个问题中的每一个。
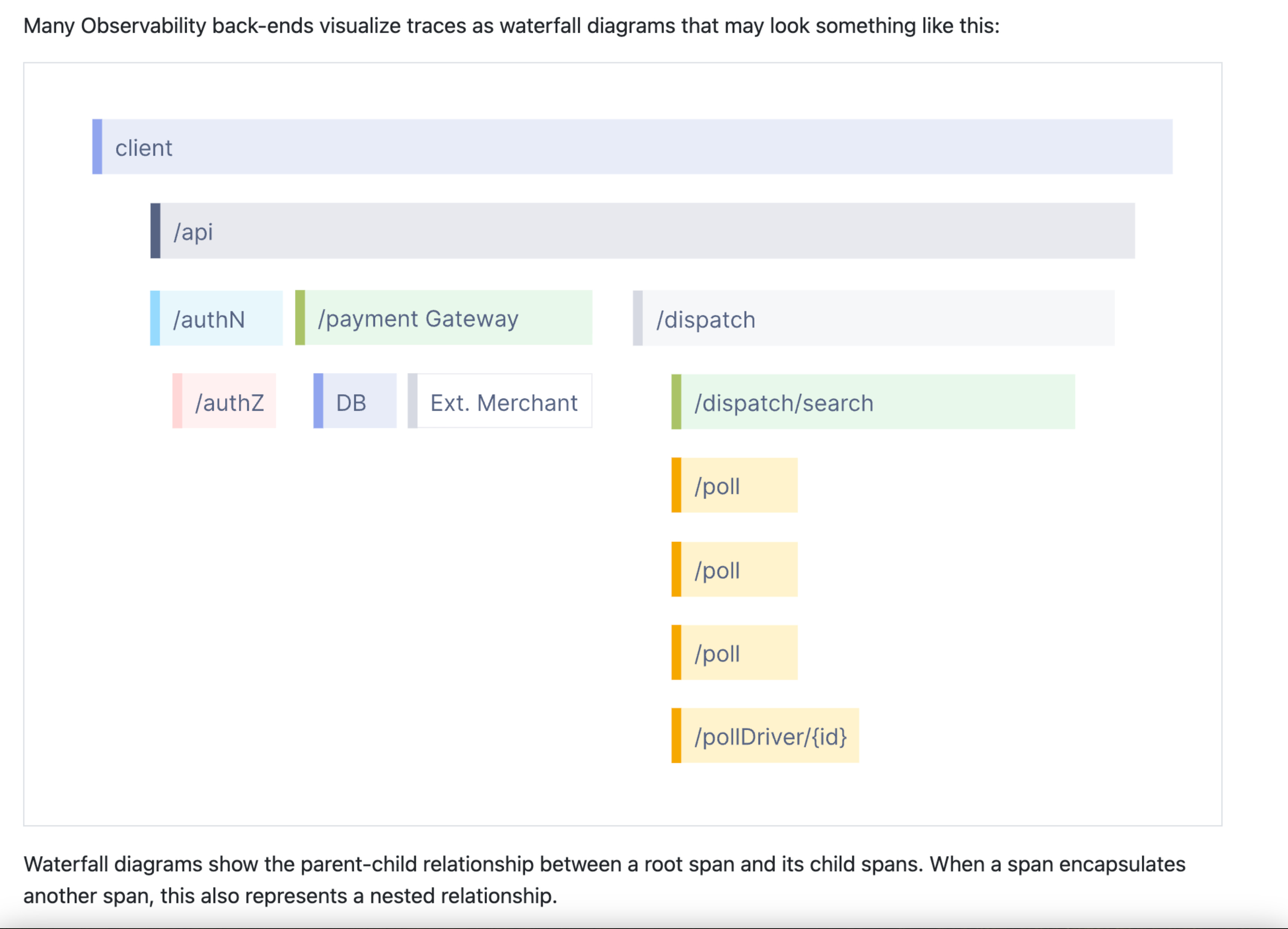
这是 OpenTelemetry 网站介绍 trace 的部分截图。根据我与 OpenTelemetry 工作人员交谈的经验,该演示文稿确实已成为与可观测性相关的主要图片之一。对于一些人来说,这就是可观测性。它还将 trace 与其他任何东西区分开来。这显然不是日志,对吧?这看起来也不像指标,对吧?这是一些特别的东西,可能有点牛逼,需要投入学习。根据我的经验,一旦人们了解了 trace,他们只会在这张图片的上下文中思考它们以及相关术语,如 span、根 span、嵌套 span 等。OpenTelemetry 网站有一个包含 60 多个术语的词汇表页面!这一切都极其复杂!
但更重要的是——这种对“日志、指标和链路追踪”的关注是否代表了可观察性的真正力量?确实,它确实涵盖了一些场景,但当涉及到大规模分布式系统时,更重要的是能够对数据进行深入挖掘 - 对其进行“切片和切块”,构建和分析各种视图,进行相关性分析,搜索异常情况… 而提供所有这些功能的系统确实存在。
Scuba: 可观测性天堂
当我在 Meta 公司工作时,我并没有意识到我有幸使用了有史以来最好的可观测性系统。这个系统称为 Scuba,它是离开 Meta 公司后人们最怀念的头等大事。
Scuba 的基本思想非常简单,不需要人们阅读术语页面就能理解。它使用广义事件(Wide Events)。广义事件只是一个带有名称和值的字段集合,就像一个JSON文档一样。如果你需要记录一些信息 - 无论是系统的当前状态还是由API调用、后台作业或其他事件引起的 - 你只需将一些广义事件写入Scuba。例如,如果一个系统提供广告服务,自然希望记录广告展示 - 即某个广告被用户看到的事实。相应的广义事件可能如下所示:
{
"Timestamp": "1707951423",
"AdId": "542508c92f6f47c2916691d6e8551279”,
"UserCountry": "US",
"Placement": "mobile_feed",
"CampaingType": "direct_ads",
"UserOS": "Android",
"OSVersion": "14",
"AppVersion": "798de3c28b074df9a24a479ce98302b6",
"...": ""
}
这样的事件被称为广义事件,因为鼓励将所有能想到的信息都存储在其中。在特定数据的上下文中可能相关的任何东西 - 只需将其放在那里,它可能在以后有用。这种方法为处理未知的未知情况奠定了基础 - 即现在无法想到的、在事故调查过程中可能会揭示的事情。
处理未知的未知情况可以通过一个例子更好地说明。Scuba拥有一个直观易用的界面,可以轻松探索和操作。它有一个部分可以选择要查看的指标,还有用于筛选和分组的部分 - Scuba会绘制一个漂亮的时间序列图表。对于广告展示数据集的首次查看将简单地绘制一个包含展示次数的图表:
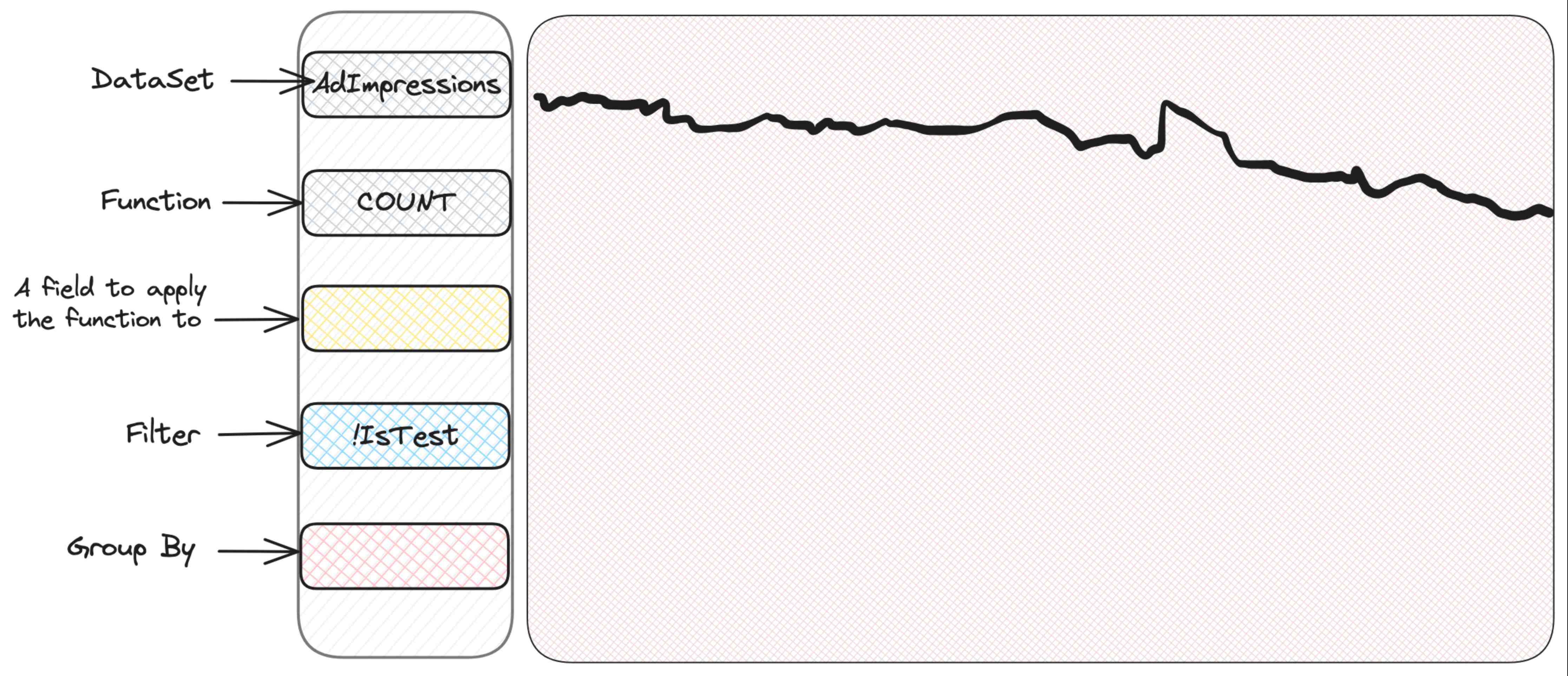
如果我们用 SQL 来表达这里到底选择了什么,那么这就像:
SELECT COUNT(*) FROM AdImpressions
WHERE IsTest = False
实际情况并非完全如此。Scuba 还具有原生采样的概念。当某个事件被写入 Scuba 时,还必须写入一个称为 samplingRate 的字段,表示此特定事件的采样率。Scuba 使用此信息来正确地“放大”图表上显示的结果,因此无需在头脑中进行这种放大操作。这是一个非常棒的概念,因为它允许动态采样 - 例如,某种类型的展示可能比另一种类型的展示更频繁地进行采样,同时保留 UI 中的“真实”值。因此,底层的实际查询是:
请注意,整个“放大”是由 UI 透明完成的,用户在查询期间无需考虑它。因此,假设发生了某个警报,并指示我们珍贵的广告展示图表看起来很奇怪:

每个使用 Scuba 进行调查的人的第一反应是进行“切片和切块”,即根据条件进行筛选或分组,以查看是否能够获取一些信息。我们不知道我们在寻找什么,但我们相信我们会找到。因此,我们会根据展示类型、用户国家或广告位置进行分组,直到找到可疑的地方。让我们假设是按照广告系列类型(CampaignType)进行分组:
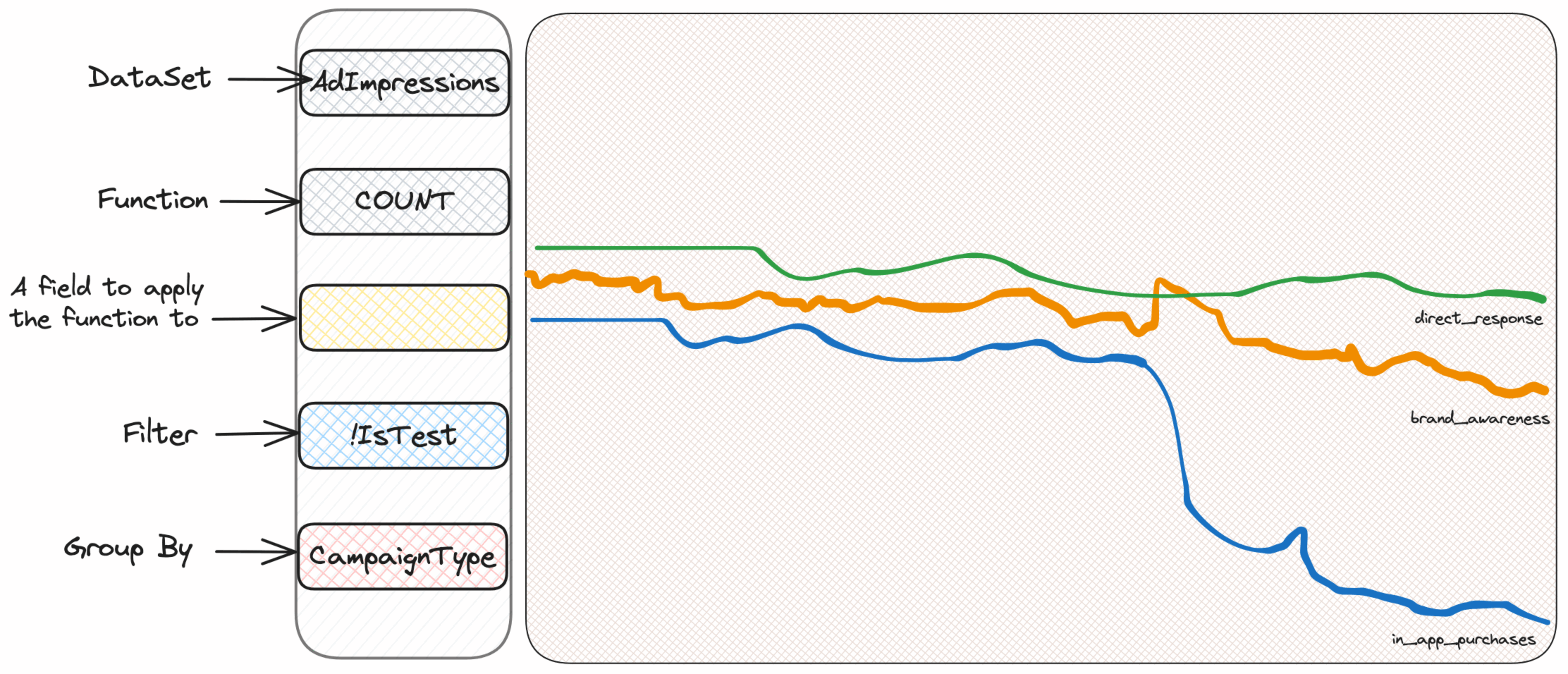
我们发现某个名为 in_app_purchases 的广告系列类型(请注意,此类型名称是我编造的)似乎与其他类型不同。我们真的不知道它意味着什么 - 我们也不需要知道! - 我们只需继续挖掘。好的,现在我们可以仅筛选这些广告系列,并继续根据其他我们能想到的条件进行分组。例如,用户操作系统是有意义的。
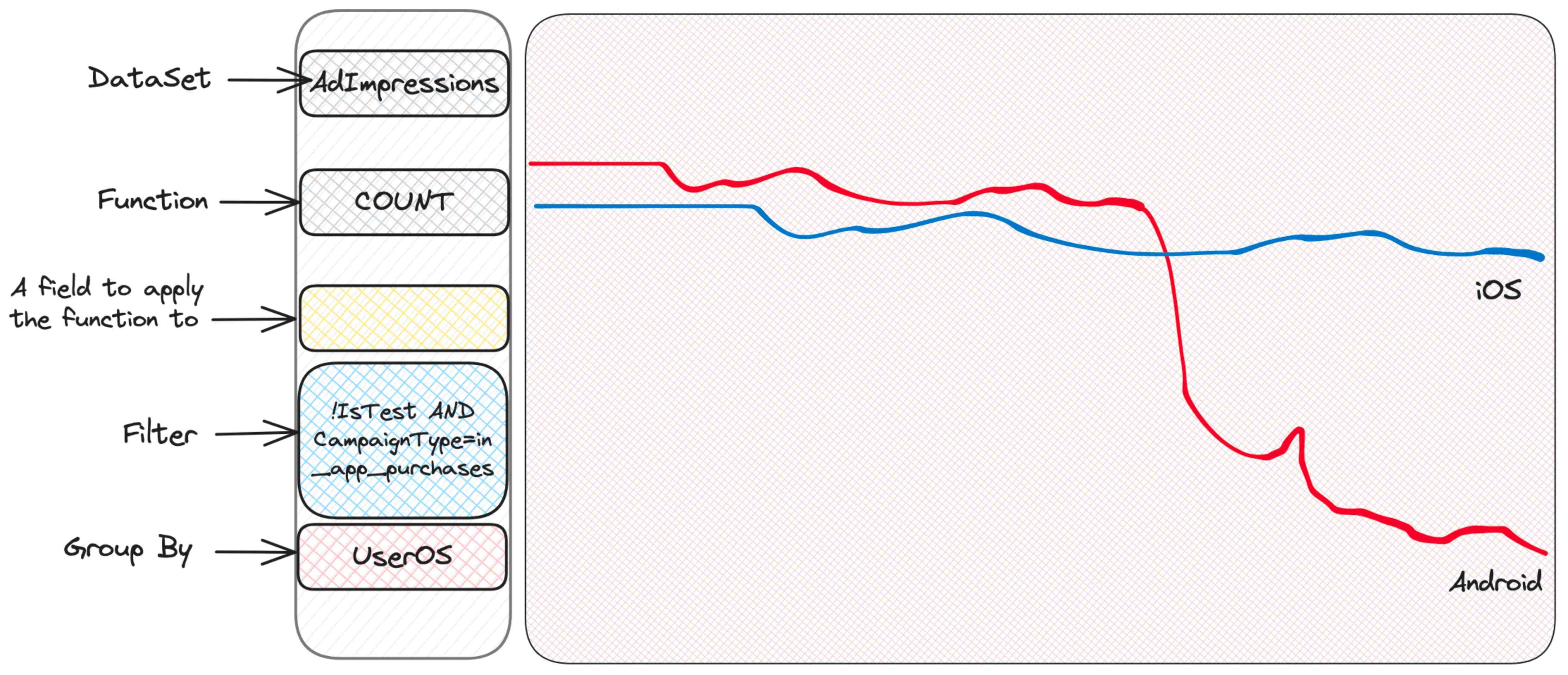
嗯,Android 似乎有问题。iOS 没问题,这表明问题可能出现在客户端 - 可能是一个有问题的应用版本?
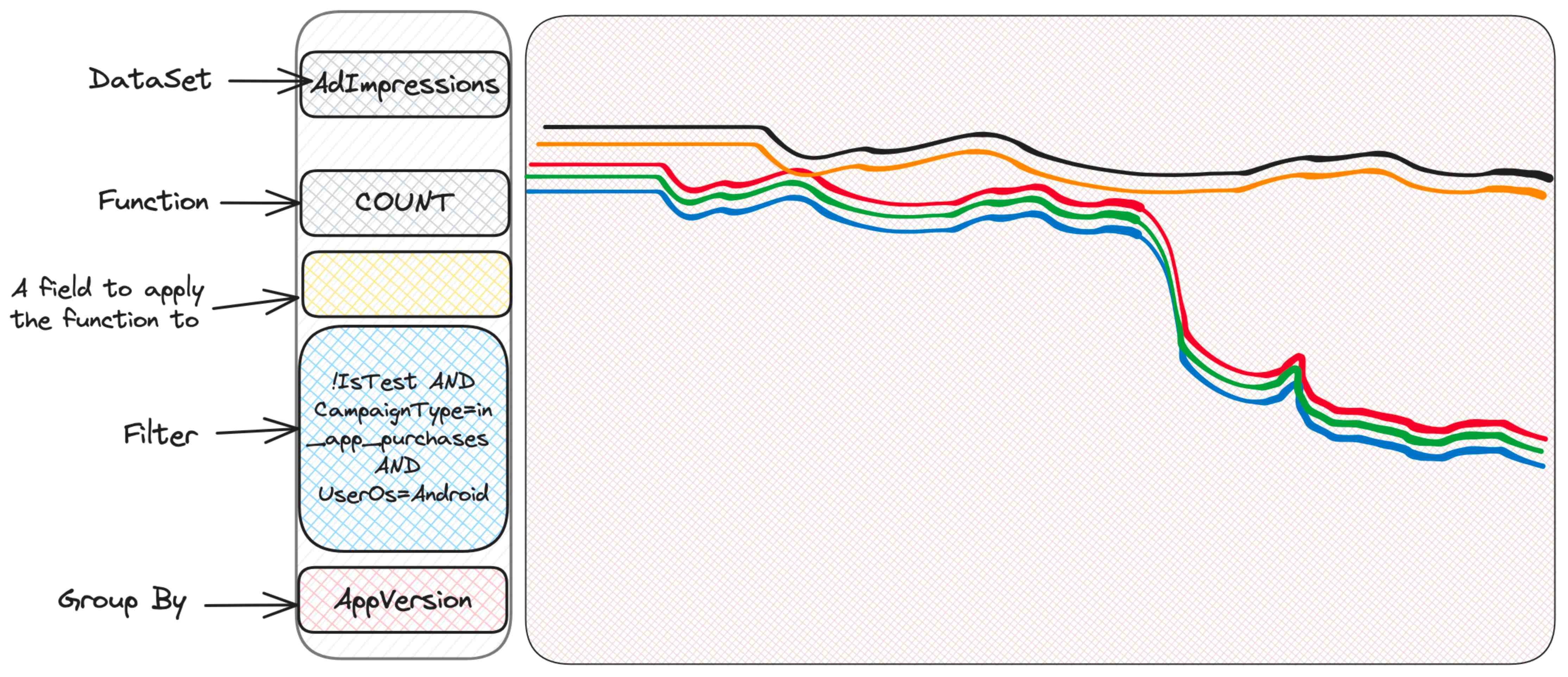
奇怪。有些人遇到了问题,而其他人没有。可能要检查操作系统版本?

哈!这是最新的操作系统版本,看起来某些应用版本在这个操作系统版本上对于这种类型的广告系列表现不佳。鉴于这些信息,专门的团队现在可以深入研究了。
发生了什么?在没有任何关于系统的知识的情况下,我们已经缩小了问题的范围,并确定了负责进一步调查的团队。我们能事先知道这种奇怪的操作系统、操作系统版本、广告系列类型和应用版本的组合可能会导致一些问题,并准备好相应的度量指标吗?当然不可能。这是处理未知的未知情况的一个例子。我们只是将所有相关的上下文信息存储在广义事件中,并在需要时使用它们。Scuba使得探索变得简单,因为它快速且具有非常漂亮易用的用户界面。还请注意,我们从未提及过基数的任何内容。因为这并不重要 - 任何字段都可以具有任何基数。Scuba使用原始事件进行操作,不进行预聚合,因此基数不是一个问题。
有时候界面/可视化方面没有得到足够的关注,监测系统提供了一些查询语言 - 可能是专有的(不好-不好-不好),或者是SQL(稍微好一些,但仍然不好)。这样的界面几乎不可能进行类似的调查。Scuba的一个重要方面是所有字段(函数、筛选、分组等)都是可探索的。也就是说,有一种简单的方法可以查看我们可以选择的值的类型。当某个字段的所有者不懒惰时,他们甚至会为给定字段提供详细的描述,包括相关链接等。这非常重要。我成功地进行了许多调查,而我对整个系统或该数据集中的可用数据并没有完全了解。而且在这些调查过程中,我通过与Scuba的互动简单地了解了很多关于系统的知识!这太神奇了。这就是可观测性的天堂。
离开 Meta 之后的痛苦
现在想象一下,当我离开 Meta 并了解到外部的可观测性系统的状况时,我有多么困惑和难以置信。

日志?追踪?指标?这到底是什么?有人知道广义事件吗?我可否不去学习那60个术语的术语表,只是…探索一下东西?
我花了相当长的时间将基于 Scuba 的心智模型映射到 Open Telemetry 的心智模型上。我意识到 Open Telemetry 的 Span 其实就是广义事件。实际上,我仍然不太确定我是否理解正确:

如果我们以广告展示为例,这个展示实际上并不是一项操作,它只是我们想要记录的一些事实… 公平地说,在 Open Telemetry 中确实存在事件(Event)的概念:

但如果我们按照链接深入挖掘,我们会再次发现事件实际上是跟踪、指标或日志之一 🤷

但无论如何,Span 是与广义事件最接近的概念。问题是 - 当已经习惯了 Open Telemetry 提出的心智模型时,很难为这种心智模型进行辩护。这真的很令人沮丧,因为追踪、指标和日志实际上都只是广义事件的特例:
- 追踪和跨度(Spans):它们只是具有 SpanId、TraceId 和 ParentSpanId 字段的广义事件而已。因此,我们可以使用给定的 TraceId 过滤所有跨度(Spans),根据 SpanId → ParentSpanId 的关系对它们进行拓扑排序,并绘制出每个人都喜欢的分布式跟踪视图。
- 日志:说实话,我对Open Telemetry所说的日志真的感到困惑。看起来它包含很多东西,其中之一是结构化日志,这基本上就是宽事件。太好了!然而,问题在于“日志”是一个相当明确的概念,通常人们指的是那些
logger.info(…)调用所产生的东西。不管怎样,无论是什么含义,日志当然可以很容易地映射到宽事件。在最简单的情况下,我们只需获取日志消息,将其放入“log_message”字段,添加一堆元数据,然后就可以满意了。在更复杂的情况下,我们可以尝试通过移除看起来像ID的令牌,从日志消息中自动提取一个模板,并获取这个模板的哈希值。这可以让我们快速获取最频繁的错误,例如,通过按这个哈希值进行分组。Meta有这样一个系统,它非常酷。 - 指标:指标也可以很容易地映射。我们只需要在某个间隔内发出一个包含系统状态(例如CPU系统指标、各种计数器等)的宽事件。顺便说一下,Prometheus正是通过抓取方法做到这一点的——偶尔对系统进行一次快照。然而,与Prometheus不同,使用宽事件方法我们不需要担心基数问题。
但是宽事件(Wide Events)可以提供比这些“三大支柱”(Traces, Logs, Metrics)多得多的东西。前面提到的调试会话已经是一个(至少不是自然地)由追踪(Traces)、日志(Logs)和指标(Metrics)所涵盖的案例。也可能有其他的用例——例如,continuous profiling 数据可以很容易地表示为一个宽事件(Wide Event),并被查询以构建火焰图(Flame Graph)。没有必要为此拥有一个单独的系统——一个单一的系统处理宽事件就可以做到这一切。想象一下,当所有东西都存储在一起、在一个地方时,交叉相关性(cross-correlation)和根本原因分析(root cause analysis)的可能性。特别是在人工智能工具兴起的时代,这些工具在发现数据中的关系方面非常出色。
所以,然后?
我不知道… 我只是想表达我的失望和挫败感,可观测性如此混乱让人困惑,而且还专注在什么“三大支柱”…
我只是希望可观测性(observability)供应商能站出来反对混乱,并提供一种简单自然的方式与系统互动。Honeycomb似乎正在这样做,还有一些其他系统,比如Axiom也在这样做。这很棒!希望其他供应商也能效仿。
FAQ
Wide Events 和结构化日志有什么关系?
结构化日志可以被看作宽事件的一种形式。区别在于,宽事件更强调把排障可能需要的上下文字段放到同一条事件里,并支持后续按任意字段探索、过滤、分组和关联。
宽事件是不是不需要指标、日志和链路追踪?
不是说工程实践里不需要这些入口,而是说它们可以共享同一种底层事件模型。指标、日志和链路追踪仍然有各自的展示方式和查询习惯,但不应因为工具分类而割裂上下文。
宽事件为什么适合未知问题排查?
未知问题的难点是事前不知道应该关注哪个维度。宽事件保留了国家、版本、系统、实例、接口、用户类型等上下文后,排障时可以不断切片和分组,逐步缩小影响范围。
高基数字段为什么在这篇文章里不是问题?
原文讨论的 Scuba 使用原始事件进行操作,不依赖预聚合,因此可以探索高基数字段。不同系统实现不同,是否支持高基数字段仍要看具体存储、查询和成本模型。
附
本文是译文,原文:https://isburmistrov.substack.com/p/all-you-need-is-wide-events-not-metrics
文末请允许我插播一个小广告。本人创业两年了,我们公司也是做可观测性,和本文思路有些相像之处。如果你有这方面的需求,欢迎联系我们做产品技术交流哈。
🎯 关于快猫星云
快猫星云是一家云原生智能运维科技公司,由知名开源项目“夜莺(Nightingale)”的核心开发团队组成,创始团队均来⾃阿⾥、百度、滴滴等互联⽹公司。夜莺是一款开源云原生监控工具,是中国计算机学会接受捐赠并托管的第一个开源项目,在GitHub上有超过8000颗星,迭代发布了超过100多个版本,上百位社区贡献者,是国内领先的开源可观测性解决方案。
快猫星云以开源夜莺为内核打造的“Flashcat平台”,是国内顶级互联⽹公司可观测性实践的产品化落地,致力于让可观测性技术更好的服务企业,保障服务稳定性。Flashcat 平台具有以下特点:
- 统一采集:采用插件化思路,内置集成上百种采集插件,服务器、网络设备、中间件、数据库、应用、业务,均可监控,开箱即用。
- 统一告警:支持几十种数据源对接,收集各类监控系统的告警事件,进行统一的告警收敛、降噪、排班、认领、升级、协同,大幅提升告警处理效率。
- 统一观测:将 Metrics、Logs、Traces、Events、Profiling 等多种可观测性数据融会贯通,并预置行业最佳实践,既提供全局业务视角、技术视角的驾驶舱,也提供层层下钻的故障定位能力,有效缩短故障发现和定位时间。



