
使用 eBPF 在云中实现网络可观测性
可观测性是一种了解和解释应用当前状态的能力,也是一种知道何时出现问题的方法。随着在 Kubernetes 和 OpenShift 上以微服务形式进行云部署的应用程序越来越多,可观察性受到了广泛关注。许多应用程序都有严格的承诺,比如在停机时间、延迟和吞吐量方面的 SLA,因此网络层面的可观测性是一项非常必要的功能。网络层面的可观测性由不同的编排器提供,有的是内置支持,有的是通过插件和 operator 提供。
最近,eBPF(扩展的伯克利数据包过滤器)因其性能和灵活性成为在终端主机内核实现可观察性的热门选择。通过这种方法,可以在网络数据路径的某些点(如套接字、TC 和 XDP)上挂接自定义程序。目前已发布了多个基于 eBPF 的开源插件和 operator,每个插件和 operator 都可插入终端主机节点,通过云上的编排器提供网络可观察性。
核心摘要
- 云原生网络可观测性的难点,是在尽量低侵入的前提下采集流量、延迟、连接和协议相关指标。
- eBPF 可以挂接在 socket、TC、XDP、kprobe、tracepoint 等位置,因此适合在主机侧观察网络数据路径。
- 不同 eBPF 工具的实现差异很大,但底层都绕不开数据结构选择:Ring Buffer、Hash Map、Per-CPU Hash、Array、Per-CPU Array。
- 原文实验的重点结论是:逐包 ringbuffer 简单但不易扩展;Hash Map 会受争用和容量影响;Per-CPU 结构和数组方案在短时突发场景下更有优势。
现有的可观测性工具
可观测性模块的核心部分是如何以非侵入方式收集必要数据。为此,使用代码埋点统计,我们研究了 eBPF 如何影响目标被观测模块的性能。测量方法和工具是开源的,你可以在我们的 Git仓库 中找到。在设计可扩展的高性能 eBPF 监控数据路径时,我们还能为您提供一些有用的见解。
以下是现有的开源工具,可用于在网络和主机的上下文中实现可观察性:
| 工具 | 主要场景 | 文中提到的 eBPF 使用方式 |
|---|---|---|
| Skydive | 网络拓扑和流量分析 | 通过 socket hook 捕获流量指标,使用 hash map 存储流量头和指标 |
| libebpfflow | TCP/UDP 流量状态和 RTT 分析 | 使用 kprobe、tracepoint、perf event buffer、LRU hash map |
| eBPF Exporter | 自定义指标导出 | 在 YAML 中附加 eBPF C 代码和 hook point |
| Pixie | Kubernetes 运行时观测 | 使用 bpftrace 跟踪系统调用并解析协议 |
| Inspektor | Kubernetes 集群调试 | DaemonSet 方式采集 syscall 等事件并写入 perf 环形缓冲区 |
| Falco | 云原生运行时安全 | 使用 eBPF 探测系统调用并基于规则告警 |
| Cilium / Hubble | 服务依赖、L4/L7 网络观测 | 在节点上运行 eBPF hook,构建通信关系和协议层信息 |
| Tetragon | 安全和可观测性策略 | 使用 eBPF ring buffer,并跨 VFS、namespace、syscall 等内核组件执行策略 |
Skydive
Skydive 是一款网络拓扑和流量分析器。它将探针下放到节点,以收集流量级信息。使用 PCAP、AF_Packet、Open vSwitch 等方式连接探针。Skydive 使用 eBPF 捕获流量指标,而不是捕获整个数据包。连接到套接字 Hook 点的 eBPF 实现使用哈希映射来存储流量头和指标(数据包、字节和方向)。
libebpfflow
Libebpfflow 是一个使用 eBPF 提供网络可见性的网络库。它 Hook 主机堆栈中的多个点,如 kernel probes(inet_csk_accept、tcp_retransmit_skb)和 tracepoints(net:netif_receive_skb、net:net_dev_queue),以分析 TCP/UDP 流量状态、RTT 等。此外,它还为所分析的流量提供进程和容器映射。其 eBPF 实现使用 perf event buffer 将 TCP 状态变化事件通知用户空间。对于 UDP,它连接到网络设备队列的跟踪点,并结合使用 LRU 哈希映射和 perf event buffer 来存储 UDP 流量指标。
eBPF Exporter
Cloudflare 的 eBPF Exporter 提供了用于插入自定义 eBPF 代码的 API,以记录感兴趣的自定义指标。它需要将整个 eBPF C 代码(以及挂钩点)附加到 YAML 文件中以进行部署。
Pixie
Pixie 使用 bpftrace 来跟踪系统调用。它使用 TCP/UDP 状态消息来收集必要的信息,然后将其发送到 Pixie Edge Module (PEM)。在PEM中,根据检测到的协议解析数据并存储以供查询。
Inspektor
Inspektor 是用于 Kubernetes 集群调试的工具集合。它有助于低级内核原语与 Kubernetes 资源的映射。它作为 daemonset 添加到集群的每个节点上,以使用 eBPF 收集syscall 等事件的跟踪。这些事件被写入 perf 环形缓冲区。最后,当发生故障时(例如,Pod 崩溃时),环形缓冲区会被追溯消耗。
L3AF
L3AF 提供了一组 eBPF 包,可使用 tail-calls 将其打包并串联起来。它提供了一个网络可观察性工具,可根据流标识将流量镜像到用户空间代理。此外,它还通过在 eBPF 数据路径中的hash map 上存储流量记录,提供了一个 IPFIX 流量导出器。
Host-INT
Host-INT 扩展了带内网络遥测支持,以支持主机网络堆栈的遥测。从根本上说,INT 将每个数据包产生的切换延迟嵌入到数据包的 INT 标头中。Host-INT 对两个主机之间的主机网络堆栈执行相同的操作。Host-INT 有两个数据路径组件:基于 eBPF 的源和接收器。源运行在发送方主机接口的 TC Hook 上,接收器运行在接收方主机接口的 XDP Hook 上。从源上来说,它使用 hash map 来存储流量统计信息。此外,它还添加了带有入口/出口端口、时间戳等的 INT 标头。在接收器处,它使用 perf array 在每个数据包到达时将统计信息发送到接收器用户空间程序,并将数据包发送到内核。
Falco
Falco 是一个云原生运行时安全项目。它使用 eBPF 探测器监控系统调用,并在运行时对其进行解析。Falco 可对使用特权容器进行特权访问、读写内核文件夹、添加用户、更改密码等活动配置警报。Falco 包括一个用户空间程序(作为 CLI 工具)和一个基于 libscap 和 libsinsp 库的 falco 驱动程序,前者用于指定警报和获取解析后的系统调用输出。对于系统调用探测,falco 使用 eBPF ring buffers。
Cilium
Cilium 的可观测性是通过 eBPF 实现的。Hubble 是一个在集群的每个节点上运行 eBPF 钩子的平台。它有助于深入了解相互通信的服务,从而构建服务依赖关系图。它还有助于第 7 层监控,例如分析 HTTP 调用和 Kafka 主题,以及通过 TCP 重传率进行第 4 层监控等。
Tetragon
Tetragon 是 Cilium 中用于安全和可观察性的可扩展框架。Tetragon 的底层驱动程序是 eBPF,使用环形缓冲区存储数据,但在监控 eBPF 的同时,还利用 eBPF 执行跨越虚拟文件系统(VFS)、命名空间、系统调用等各种内核组件的策略。
Aquasecurity Tracee
Tracee 是一款事件跟踪工具,用于调试通过 eBPF 构建的行为模式。Tracee 在 tc、kprobes 等处有多个挂钩点,用于监控和跟踪网络流量。在 tc 钩子点,它使用环形缓冲区(perf)向用户空间提交数据包级事件。
重新审视 Flow metric agent 的设计
虽然不同工具的动机和实现方式各不相同,但所有可观测性工具的共同核心部分是用于收集可观测性指标的数据结构。虽然不同的工具采用不同的数据结构来收集指标,但目前还没有进行性能测量,以了解用于收集和存储可观测性指标的数据结构的影响。为了弥补这一差距,我们使用不同的数据结构实施模板 eBPF 程序,从主机流量中收集相同的流量指标。我们使用 eBPF 中的以下数据结构(称为 “地图”)来收集和存储指标:
- Ring Buffer
- Hash
- Per-CPU Hash
- Array
- Per-CPU Array
这些结构的选择会直接影响两类成本:内核数据路径上的写入成本,以及用户空间消费数据的频率和复杂度。网络可观测代理如果选错数据结构,很容易在高吞吐场景下把观测本身变成新的性能瓶颈。

Ring Buffer
环形缓冲区是 eBPF 数据路径和用户空间之间的共享队列,其中 eBPF 数据路径是生产者,用户空间程序是消费者。它可用于向用户空间发送每个数据包的“明信片”,以汇总流量指标。虽然这种方法既简单又能提供准确的结果,但由于它按数据包发送“明信片”,用户空间程序一直处于繁忙的循环中,因此无法扩展。
Hash and Per-CPU Hash map
(每 CPU)Hash map 可用于 eBPF 数据路径,通过对流标识(例如 5 元组:IP、端口、协议)进行散列来聚合每个流的指标,并在流完成/未激活时将聚合信息驱逐到用户空间。虽然这种方法克服了环形缓冲区的缺点,每个流而不是每个数据包只发送一次明信片,但它也有一些缺点。
首先,多个流量有可能被散列到同一个条目中,从而导致流量指标汇总不准确。其次,对于内核 eBPF 数据路径来说,散列映射的内存必然有限,因此可能会被耗尽。因此,用户空间程序必须执行驱逐逻辑,以便在超时时不断驱逐流量。
Array-based map
(每 CPU)基于数组的映射也可用于在逐出用户空间之前临时存储每数据包明信片,尽管这不是一个明显的选择。使用数组有一个优势,即在数组中存储每个数据包的信息,直到数组已满,然后仅在数组已满时才刷新到用户空间。这样,与使用每个数据包的环形缓冲区相比,它可以改善用户空间的忙循环周期。另外,它不存在 Hash map 的哈希冲突问题。然而,实现起来很复杂,因为当主数组将其内容刷新到用户空间时,需要多个冗余数组来存储每个数据包的明信片。
Measurements
到目前为止,我们已经研究了可用于使用多种数据结构实现流度量收集的选项。现在是时候研究每种方式的性能了。为此,我们实施了代表性的 eBPF 程序来收集流量指标。为此,我们实施了具有代表性的 eBPF 程序来收集流量指标。我们使用的代码可在我们的 Git 仓库 中找到。此外,我们还在 PcapPlusPlus 的基础上定制了基于 UDP 的数据包生成器,通过发送流量进行测量。
该图描述了实验设置:
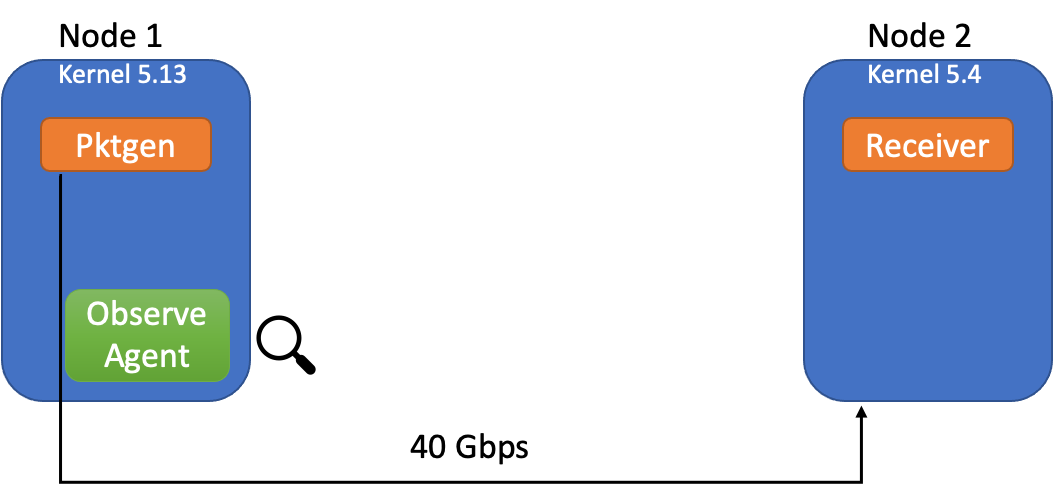
(Kannan/Naik/Lev-Ran, CC BY-SA 4.0)
观察代理是执行流度量收集的 eBPF 数据路径,挂接到发送方的 tc hook 点。我们使用两台通过 40G 链路连接的裸机服务器。数据包生成是使用 40 个独立的 core 完成的。为了正确看待这些测量结果,基于 libpcap 的 Tcpdump 可用于收集类似的流量信息。
Single Flow
我们最初使用单流 UDP 帧运行测试。单流测试可以向我们展示观察代理可以容忍的单流流量突发量。如下图所示,没有任何观察代理的本机性能约为 4.7 Mpps(每秒百万数据包),而运行 tcpdump 时,吞吐量降至约 2 Mpps。使用 eBPF,我们观察到性能从 1.6 Mpps 到 4.7 Mpps 不等,具体取决于用于存储流指标的数据结构。使用 HashMap 等共享数据结构,我们观察到单流性能下降最显着,因为每个数据包都会写入映射中的相同条目,而不管其源自哪个 CPU。
对于单个流突发,Ringbuffer 的性能比单个 HashMap 稍好。使用每 CPU 哈希映射,我们观察到吞吐量性能显着提高,因为来自多个 CPU 的数据包不再争用相同的映射条目。然而,在没有任何观察代理的情况下,性能仍然是本机性能的一半。 (请注意,此性能未处理哈希冲突和驱逐。)
使用(每个 CPU)阵列,我们看到单个流的吞吐量显着增加。我们可以将此归因于以下事实:数据包之间实际上不存在争用,因为每个数据包逐渐占用数组中的不同条目。然而,我们实现中的主要缺点是我们不处理数组满时的刷新,而它以循环方式执行写入。因此,它存储在任何时间点观察到的最后几个数据包记录。尽管如此,它为我们提供了通过在 eBPF 数据路径中适当应用数据结构来实现的一系列性能提升。
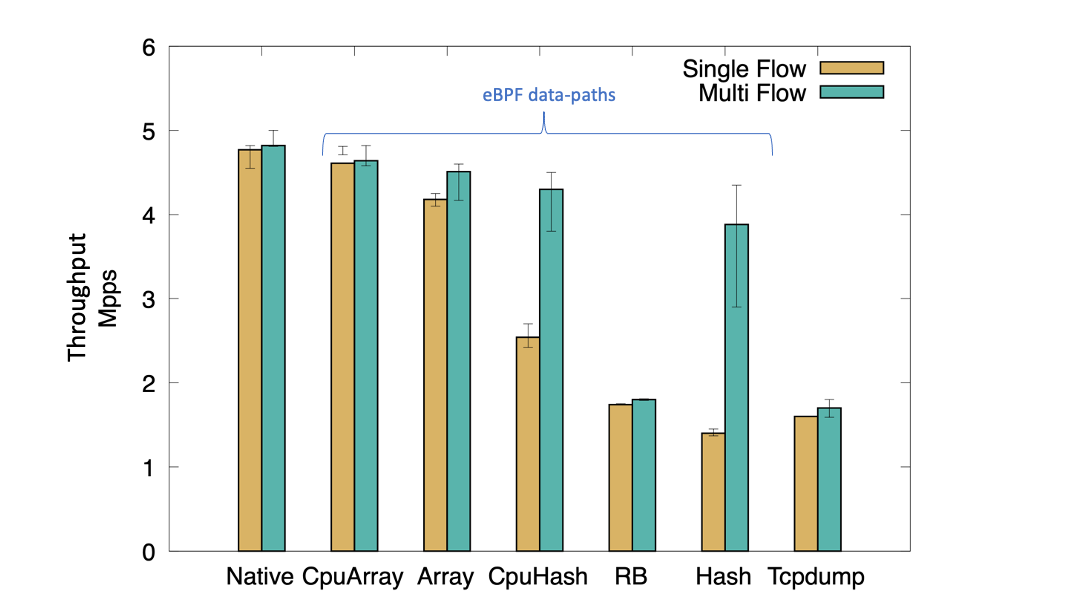
(Kannan/Naik/Lev-Ran, CC BY-SA 4.0)
Multi-Flow
我们现在测试具有多个流的 eBPF 观察代理的性能。我们通过检测数据包生成器生成了 40 个不同的 UDP 流(每个核心 1 个流)。有趣的是,对于多个流,我们观察到与单个流相比,每 CPU 哈希和哈希映射的性能存在明显差异。这可能归因于单个散列条目的争用减少。然而,我们没有看到 ringbuffer 有任何性能改进,因为无论流量如何,争用通道(即 ringbuffer )都是固定的。数组在多个流中的性能稍好一些。
学到了啥
根据我们的研究,我们得出以下结论:
- 基于 ringbuffer 的每个数据包的处理不可扩展,并且会影响性能。
- Hash map 限制了数据流的突发流量,即每秒处理的数据包数量。每个 CPU 的 hash map 性能表现稍好。
- 考虑到数组可以存储 10 个或 100 个数据包的记录,使用数组映射来存储每个数据包的明信片是处理数据流内数据包短时突发的一个不错选择。这将确保观察代理可以承受短时间的突发,而不会降低性能。
在我们的研究中,我们分析了云中多个主机之间的数据包级和流级信息的监控。我们首先假设可观察性的核心特征是如何以非侵入性方式收集数据。带着这种展望,我们调查了现有工具,并测试了从 eBPF 数据路径中观察到的数据包中以流量指标的形式收集可观测性数据的不同方法。我们研究了用于收集流指标的数据结构如何影响流的性能。
理想情况下,为了最大限度地降低主机流量因可观测代理的开销而导致的性能下降,我们的分析表明,可以混合使用每 CPU 数组和每 CPU 哈希数据结构。这两种数据结构可以一起使用,通过使用数组和每 CPU 哈希映射聚合来处理流量中的短时间突发。我们目前正在设计可观察性代理,并计划在未来发布一篇文章,介绍设计细节和与现有工具的性能分析。
FAQ
Q1:为什么 eBPF 适合做云网络可观测性? A:因为它可以在主机内核的数据路径上挂接程序,直接观察 socket、TC、XDP、tracepoint 等位置的事件,减少对业务应用的侵入。
Q2:Ring Buffer 为什么不适合所有流量采集场景? A:文中实验指出,逐包向用户空间发送记录虽然简单,但用户空间程序会频繁消费数据,在高吞吐场景下扩展性较差。
Q3:为什么 Per-CPU Hash 或 Array 结构有价值? A:Per-CPU 结构可以减少多个 CPU 争用同一个映射条目的情况;数组结构可以承接短时突发,降低逐包刷新到用户空间的频率。
翻译自:https://opensource.com/article/22/8/ebpf-network-observability-cloud
扩展阅读:


