

简介
最近我有一个任务,需要跟踪、搞定 series 基数问题,并显著减少 Prometheus 的资源使用。为了做到这一点,我首先需要分析系统。在本文中,我将解释如何使用 mimirtool 来识别平台上使用哪些指标以及哪些没有被使用。
核心要点
- Prometheus 指标瘦身的第一步不是直接删除指标,而是先知道哪些指标被 Dashboard、告警规则和记录规则使用。
- mimirtool 可以分析 Grafana、规则文件和 Prometheus 实例,输出已使用和未使用的指标列表。
- 未使用指标不等于一定可以删除,还要确认是否被 HPA、自定义脚本、外部查询、临时排障或其他系统使用。
- 找到未使用指标后,可以考虑在 Exporter 侧禁用,或通过 Prometheus relabeling 规则丢弃。
- 本文示例基于 Kubernetes 和 kube-prometheus-stack,其他部署方式需要调整命令路径、端口转发和规则文件位置。
分析流程总览
| 步骤 | 输入 | 输出 |
|---|---|---|
| 分析 Grafana Dashboard | Grafana API Token | metrics-in-grafana.json |
| 分析 Prometheus 规则 | Prometheus 规则文件 | metrics-in-ruler.json |
| 分析 Prometheus 实例 | Prometheus HTTP API | prometheus-metrics.json |
| 导出文本列表 | prometheus-metrics.json |
used_metrics.txt、unused_metrics.txt |
| 后续治理 | 未使用指标列表 | Exporter 配置、relabeling 或采集策略调整 |
先决条件
本文中描述的所有内容都是在 Kubernetes 环境中使用 kube-prometheus-stack 完成的。如果您的 Prometheus 部署方式与我不同,您可能需要进行调整,但如果您同时拥有 Prometheus 和 Grafana 的至少一个实例,那么您应该可以继续使用。
根据 Grafana 的官网:
Mimirtool 是一个 CLI 工具,可用于涉及 Grafana Mimir 或 Grafana Cloud Metrics 的 Prometheus 兼容任务的各种操作。
要重现示例,您需要:
# Archlinux
pacman -Sy kubectl mimir jq
# MacOS
brew install kubectl mimirtool jq
如果您的 Prometheus 和 Grafana 实例也在 Kubernetes 上运行,如果您希望能够复制和粘贴示例,则可以在下面的变量中复制它们的 pod 名称:
# kubectl get pod -n monitoring | grep -E 'prometheus|grafana'
my_grafana_pod="kube-prometheus-stack-grafana-6b7fc54bd9-q2fdj"
my_prometheus_pod="prometheus-kube-prometheus-stack-prometheus-0"
分析你的 Prometheus 的 metrics 使用情况
我们需要做的第一件事是确定我们使用的指标和我们拥有的指标。我过去曾使用 grep 手动完成此操作,但 mimirtool 使它变得非常简单!
这里的“使用”主要指被 Grafana Dashboard 或 Prometheus 规则引用。它不能自动覆盖所有可能的消费方,因此后面看到未使用指标时,需要再结合实际环境确认。
Grafana 仪表板中的指标
在我们提取 Grafana 实例中使用的指标列表之前,我们首先需要创建一个具有管理员角色的 Grafana API 密钥。如果你有一个暴露的 Grafana 实例,只需打开它并转到 https://grafana.your.domain/org/apikeys 。如果没有,您可能需要先公开它:
# Run this is a separate terminal
kubectl port-forward ${my_grafana_pod} -n monitoring 3000:3000
然后你应该能够打开:http://localhost:3000/org/apikeys
从那里,单击 New API key 按钮,为密钥命名、管理员角色和可选的 TTL,如下所示:
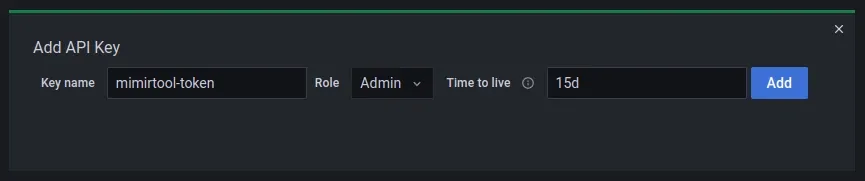
Screenshot: Creation of a Grafana API Key.
单击添加并将 Token 保存到终端中的变量:
GRAFANA_API_TOKEN="copy your token here"
我们现在可以使用 mimirtool 来提取我们的 Grafana 实例中使用的指标列表:
mimirtool analyze grafana --address=http://localhost:3000 --key="${GRAFANA_API_TOKEN}"
完成后,您应该在当前目录中有一个 metrics-in-grafana.json 文件,其中包含 Grafana 中使用的 JSON 格式的指标列表。
Prometheus 规则中的指标
我们将对我们在 Prometheus 规则中使用的指标做同样的事情。 因为我使用 Prometheus Operator,所以我的规则来自不同的地方和格式,主要是 ServiceMonitors 但不仅如此。最后,它们都加载到 Prometheus 实例本身,这就是为什么我们需要直接在 Prometheus pod 上提取指标列表。
所有规则都位于我的 Prometheus pod 中的 /etc/prometheus/rules/ 中,检查你的规则并在需要时进行调整:
# Print your Prometheus rules files
kubectl exec -it ${my_prometheus_pod} -n monitoring \
-- sh -c 'for i in `find /etc/prometheus/rules/ -type f` ; do cat $i ; done'
如果您在输出中看到您的 Prometheus 规则,请将它们导出到本地文件:
# Export your Prometheus rules files to a local file
kubectl exec -it ${my_prometheus_pod} -n monitoring \
-- sh -c 'for i in `find /etc/prometheus/rules/ -type f` ; do cat $i ; done' > my-prom-rules.yaml
如果您有多个规则文件,您可能需要在继续之前修复 YAML 结构:
# Fix the combined rules YAML schema for mimirtool
sed -i -e 's/groups://g' -e '1s/^/groups:/' my-prom-rules.yaml
您也可以在一个命令中执行此操作:
# One-liner
kubectl exec -it ${my_prometheus_pod} -n monitoring \
-- sh -c 'for i in `find /etc/prometheus/rules/ -type f` ; do cat $i ; done' \
| sed -e 's/groups://g' -e '1s/^/groups:/' > my-prom-rules.yaml
现在我们在 my-prom-rules.yaml 中有了导出的规则,我们现在可以使用 mimirtool 来提取指标列表:
mimirtool analyze rule-file my-prom-rules.yaml
与我们为 Grafana 所做的类似,您现在应该在当前目录中有一个 metrics-in-ruler.json 文件,其中包含 Prometheus 规则中使用的指标列表。
其他地方的指标
根据您的环境,您可能会在其他地方使用 Prometheus 指标,例如,如果您有任何基于自定义指标的 HorizontalPodAutoscaler。如果是这种情况,您将需要找到一种方法在进一步操作之前将指标列表导入其中一个文件中。
除了 HPA,还要检查自研运维脚本、外部 BI 查询、临时排障面板、第三方告警系统和远端存储查询。否则,单纯根据 Dashboard 和规则判断“未使用”,可能会误删仍有价值的指标。
与 Prometheus 对比
一旦我们同时拥有 metrics-in-grafana.json 和 metrics-in-ruler.json,其中包含我们当前使用的指标列表,我们就可以将它们与我们在 Prometheus 中拥有的所有指标进行比较。这使我们能够获得 Prometheus 中已使用和未使用的指标列表。
为此,我们需要公开我们的 Prometheus 实例:
# run this is a separate terminal
kubectl port-forward ${my_prometheus_pod} -n monitoring 9090:9090
再一次,我们将使用 mimirtool 自动加载我们之前创建的文件并将它们与存储在我们的 Prometheus 实例中的指标进行比较:
mimirtool analyze prometheus --address=http://localhost:9090
样例输出:
$ mimirtool analyze prometheus --address=http://localhost:9090
INFO[0000] Found 1377 metric names
INFO[0000] 22451 active series are being used in dashboards
INFO[0000] 28440 active series are NOT being used in dashboards
INFO[0000] 270 in use active series metric count
INFO[0000] 1105 not in use active series metric count
最终会得到 prometheus-metrics.json 文件,其中包括了已使用和未使用的 metrics 列表。
要以原始文本格式保存已用指标列表:
jq -r ".in_use_metric_counts[].metric" prometheus-metrics.json | sort > used_metrics.txt
要以原始文本格式保存未使用的指标列表:
jq -r ".additional_metric_counts[].metric" prometheus-metrics.json | sort > unused_metrics.txt
在此示例中,这是一个默认的 Kubernetes 部署,只有几个正在运行的应用程序,我们看到只使用了 270/1377 个指标,这意味着 80% 的抓取指标从未使用过!您拥有的应用程序和指标越多,这个数字就越大。
未使用的列表可能是最有趣的一个。有了它,我们可以甄别那些或许可以在我们的仪表板和警报中利用的指标,但也可以甄别出或许需要在 Exporter 侧禁用的无用指标,或者使用 relabeling 规则 删除它们。
删除指标前的检查清单
- 确认指标没有被 Grafana Dashboard 使用。
- 确认指标没有被告警规则、记录规则或聚合规则使用。
- 确认指标没有被 HPA、自研脚本、外部系统或临时查询依赖。
- 评估指标是否只是“目前没用”,但未来排障可能需要。
- 优先在测试环境或小范围实例上验证禁用策略。
- 对高基数标签优先治理标签,而不是粗暴删除整类指标。
- 变更后观察 Prometheus 资源、active series、查询结果和告警行为。
结语
在本文中,我们能够从我们的 Prometheus 实例中提取已使用和未使用的指标列表。虽然这有助于理解我们的监控系统,但请记住,禁用和删除未使用的指标可能对 Prometheus 性能的影响有限。在另一篇文章中,我将解释我是如何处理基数问题并显着减少 Prometheus 资源使用的。
换句话说,mimirtool 的价值是帮助你看清指标使用情况,而不是承诺一键降本。真正的 Prometheus 瘦身,还需要结合指标基数、标签设计、采集频率、保留周期、远端存储和查询模式一起治理。
FAQ
Q1:mimirtool 找到的 unused metrics 可以直接删除吗? A:不建议直接删除。unused 只代表没有在当前分析到的 Dashboard 和规则中使用,还要检查 HPA、自研脚本、外部系统和临时排障查询。
Q2:为什么删除未使用指标后,Prometheus 资源下降不明显? A:资源消耗更受 active series 数量、高基数标签、采集频率、查询复杂度和存储策略影响。删除少量低基数指标,效果可能有限。
Q3:指标瘦身应该优先删指标还是治理标签?
A:如果问题来自高基数标签,优先治理标签更有效。例如某个指标本身有价值,但带了 user_id、request_id 这类高基数字段,就应优先评估标签处理策略。
Q4:这套流程只适用于 Grafana Mimir 吗? A:不是。本文示例用 mimirtool 分析 Prometheus 兼容任务,只要你有 Grafana、Prometheus 规则和 Prometheus HTTP API,就可以按环境调整命令使用。
本文作者的一些联系方式:
- GitHub : https://github.com/dotdc
- Mastodon : https://hachyderm.io/@0xDC
- Twitter : https://twitter.com/0xDC_
- LinkedIn : https://www.linkedin.com/in/0xDC
👋



