
核心要点
- 日志 ETL 的核心任务,是把原始文本日志抽取、解析、类型转换并写入 Elasticsearch 等后端,让日志具备可查询、可聚合和可分析的结构。
- Logstash 功能成熟,但 pipeline 配置对使用者要求较高;fc-stash 的重点是把数据源、规则配置、预览测试和规则管理平台化。
- 在本文给出的压测环境中,fc-stash 与 Logstash 的消费和写入峰值接近,但 fc-stash 的单机内存占用更低。
- 选型时不应只看吞吐,还要看团队是否需要 UI 自服务、权限隔离、规则预览、Kafka 积压查看以及与查询、告警、大盘的一体化体验。
前言
什么是ETL?ETL 是指 Extract、Transform、Load 的缩写,是一种常见的数据处理模式,用于将数据从一个数据源抽取(Extract)出来,经过转换(Transform)后加载(Load)到目标数据仓库或数据库中。如果数据源是日志文件,那么最通用的技术栈是ELK。
相信很多研发人员对这三个字母并不陌生,ELK是Elasticsearch、Logstash、Kibana的首字母,是一个非常流行的开源工具组合,在日志的收集、转换、搜索和分析中得到非常广泛的应用。ELK 架构的简单示例如下图所示:

- Beats:通常指filebeat,用于收集日志文件数据的工具,具有轻量级和低资源消耗的特点
- Kafka:用于实现日志数据的传输、缓冲和分发
- Logstash:用于收集、抽取、转换和发送日志和事件数据的工具,日志经过处理后发送到Elasticsearch
- Elasticsearch:用于存储、索引和分析日志和事件数据的分布式搜索和分析引擎,具有强大的搜索和聚合功能
- Kibana:用于可视化和分析 Elasticsearch 中存储的数据的开源数据可视化工具
虽然ELK已经成为一种标准化的日志解决方案,但是在某些背景(比如成本压力)和细分场景下,也存在无法解决的问题,因此越来越多的“替代方案”开始涌现出来,本文重点介绍一款替代Logstash的方案:fc-stash(flashcat的日志提取模块),并与 logstash 做基本的对比。
日志提取主要做什么
首先以NGINX access_log为例,说明一下日志提取需要解决什么问题。
| 阶段 | 要解决的问题 | 本文示例 |
|---|---|---|
| Extract | 从 Kafka 等来源读取原始日志消息 | categraf 采集 NGINX access_log 后写入 Kafka |
| Transform | 解析文本、转换时间和数值类型、删除无效字段 | 用 log_format 或 grok 提取 status、request_time、upstream_addr 等字段 |
| Load | 写入可查询分析的目标系统 | 将结构化结果写入 Elasticsearch 索引 |
如下文所示,这是一条典型的access_log和对应的log_format定义:
10.99.1.103 - - [16/Apr/2024:13:11:45 +0800] "GET /api/n9e/board/2/pure HTTP/1.1" 200 196 2.948 "http://10.99.1.106:8766/dashboards/2?datasource=95&ident=dev-backup-01" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36" "-" "10.99.1.107:17001"
$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent $request_time "$http_referer" "$http_user_agent" "$http_x_forwarded_for" "$upstream_addr"
经过采集程序上报到KAFKA后,KAFKA中的消息文本格式如下,本文使用的采集程序是categraf:
{
"agent_hostname": "categraf-local",
"fcservice": "stash_benchmark",
"fcsource": "",
"fctags": "filename:INFO.log,dirname:/opt/logs/cpay_api,monitoring=test,k=v",
"message": "10.99.1.103 - - [16/Apr/2024:13:11:45 +0800] \"GET /api/n9e/board/2/pure HTTP/1.1\" 200 196 2.948 \"http://10.99.1.106:8766/dashboards/2?datasource=95&ident=dev-backup-01\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36\" \"-\" \"10.99.1.107:17001\"",
"status": "info",
"timestamp": 1713248023079
}
经过日志提取后,应该转化为以下结构化数据,转换后的数据将写入到Elasticsearch中,并用于上层查询分析:
{
"remote_addr": "10.99.1.103",
"remote_user": "-",
"time_local": "2024-04-16T13:11:45+08:00",
"method": "GET",
"request": "/api/n9e/board/2/pure",
"status": "200",
"body_bytes_sent": "196",
"request_time": 2.948,
"http_referer": "http://10.99.1.106:8766/dashboards/2?datasource=95&ident=dev-backup-01",
"http_user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"http_x_forwarded_for": "-",
"upstream_addr": "10.99.1.107:17001"
}
功能对比
logstash的配置
本文使用的logstash版本统一是 7.17.20
如果要实现本文所要求的提取效果,通过部署一个logstash实例、然后编写logstash的pipeline配置来实现。那么请各位停下来想一想,在不借助网络的帮助时,你能否写出对应的配置呢?反正笔者是写不出来,经过与GPT长达50多次问答、并通过输出到stdout的方式测试,终于写出了如下的配置文件:
input {
kafka {
bootstrap_servers => "your_broker_ip:9092"
topics => ["fc_stash_benchmark"]
group_id => "logstash_group01"
codec => json
}
}
filter {
mutate {
remove_field => ["status", "fcsource", "fctags"]
convert => { "timestamp" => "integer" }
}
grok {
match => { "message" => '%{IPORHOST:remote_addr} - %{DATA:remote_user} \[%{HTTPDATE:time_local}\] "%{WORD:method} %{URIPATH:request}(?:%{URIPARAM:params})? %{DATA:protocol}" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{NUMBER:request_time} "%{DATA:http_referer}" "%{DATA:http_user_agent}" "%{DATA:http_x_forwarded_for}" "%{DATA:upstream_addr}"' }
remove_field => ["message"]
}
date {
match => [ "time_local", "dd/MMM/yyyy:HH:mm:ss Z" ]
target => "time_local"
}
date {
match => [ "timestamp", "UNIX_MS" ]
target => "@timestamp"
}
mutate {
remove_field => ["timestamp", "@version", "protocol", "params"]
convert => { "request_time" => "float" }
}
}
output {
# stdout { codec => rubydebug }
elasticsearch {
hosts => ["your_ndoe_ip:9200"]
index => "logstash_benchmark_test-%{+YYYY.MM.dd}"
user => "your_user"
password => "your_password"
}
}
fc-stash的配置
对于 IaC 践行的比较好的企业,修改配置文件是挺好的方式。不过很多企业,还是希望能够提供 UI,提供权限隔离,让各个团队能够自服务,同时在整个配置过程中可以随时进行“测试”,fc-stash 应运而生,其配置过程如下。
- 第一步,管理KAFKA和Elasticsearch数据源,通过平台快速录入KAFKA和Elasticsearch集群信息
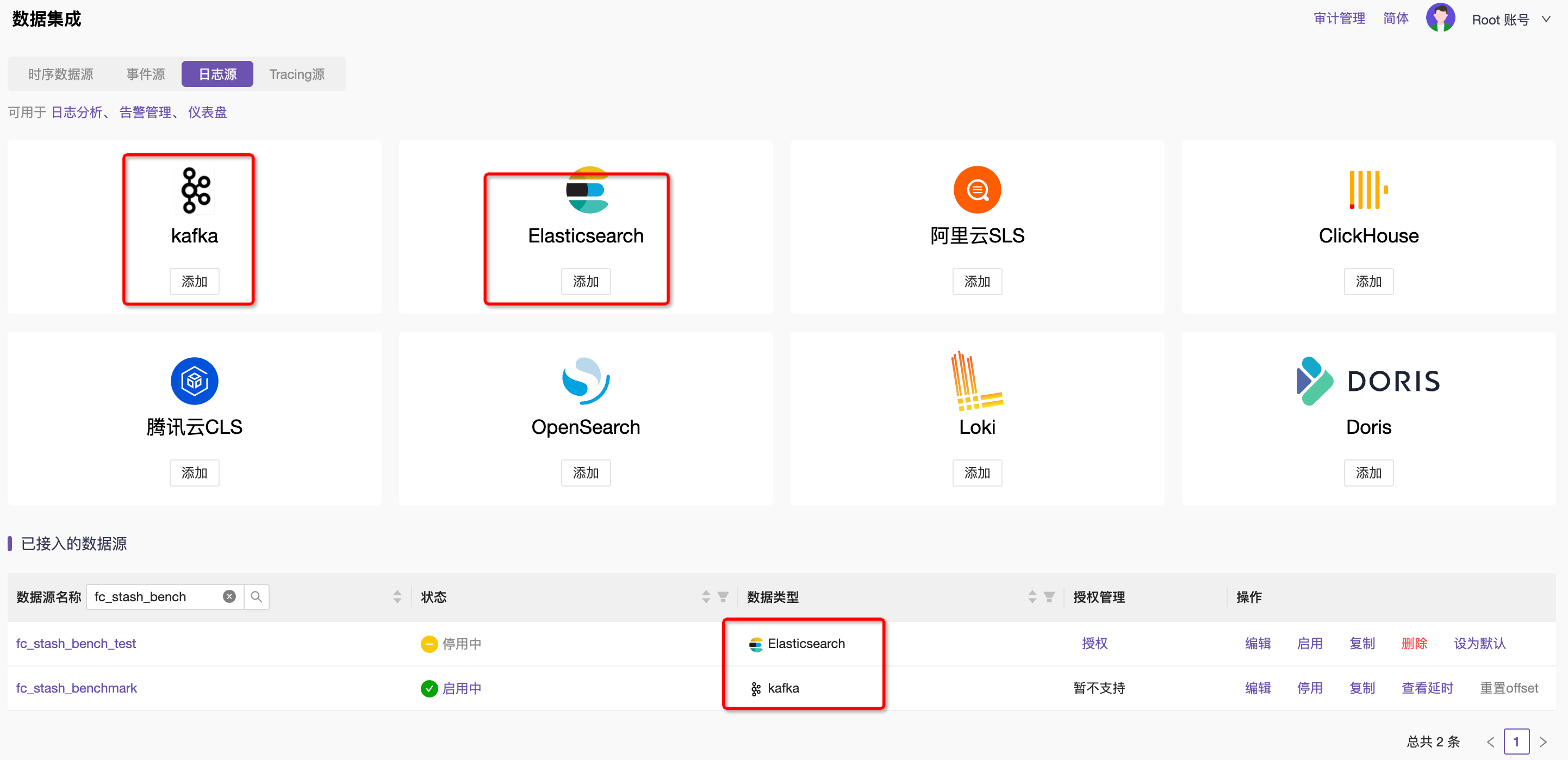
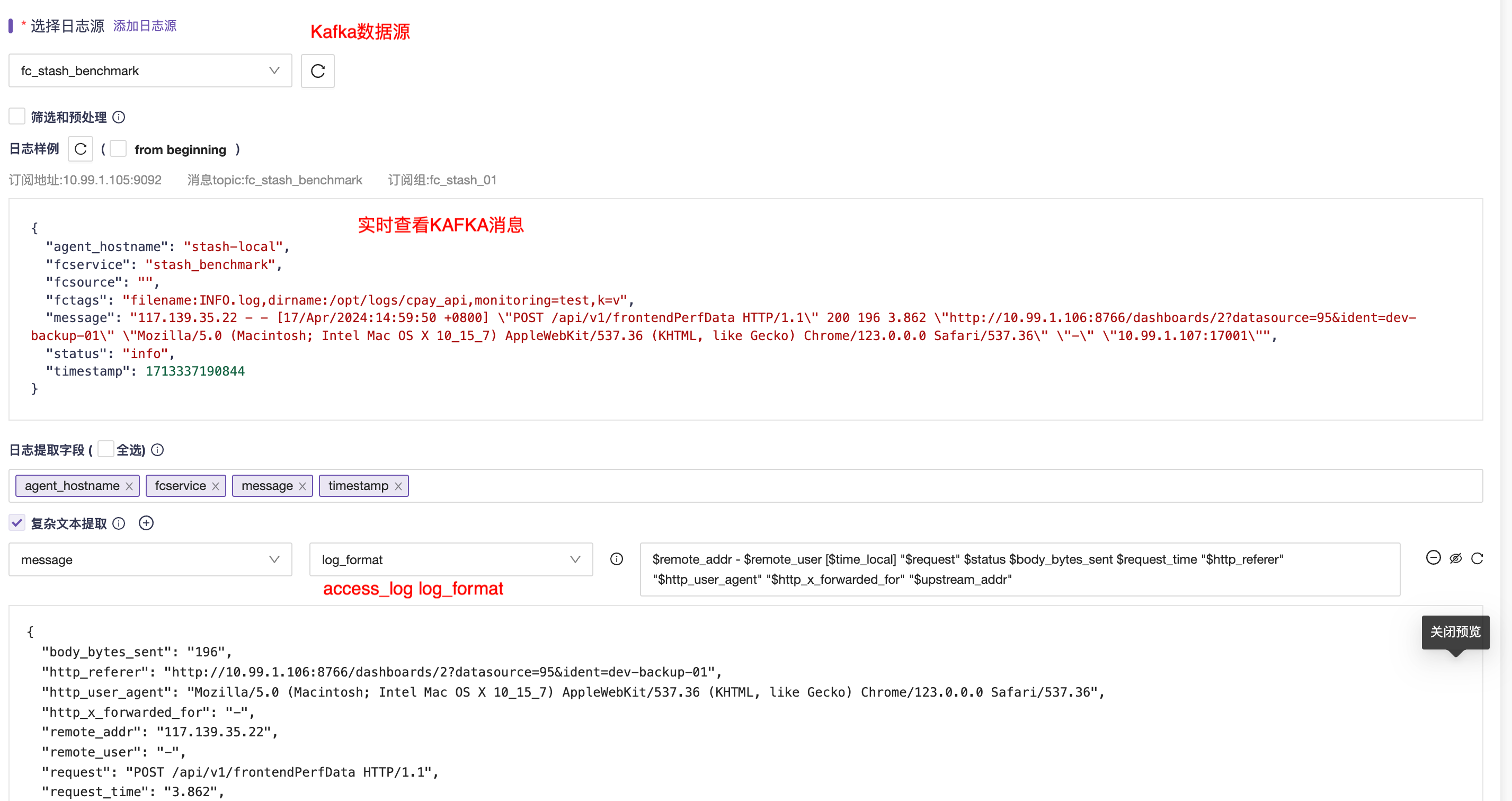
- 第二步,进入添加日志提取规则的页面,选择Kafka数据源,并实时读取一条消息作为配置样本数据
- 第三步:通过内置的方法对复杂文本进行处理,本文用到的是log_format模式,填写log_format配置项,并预览效果
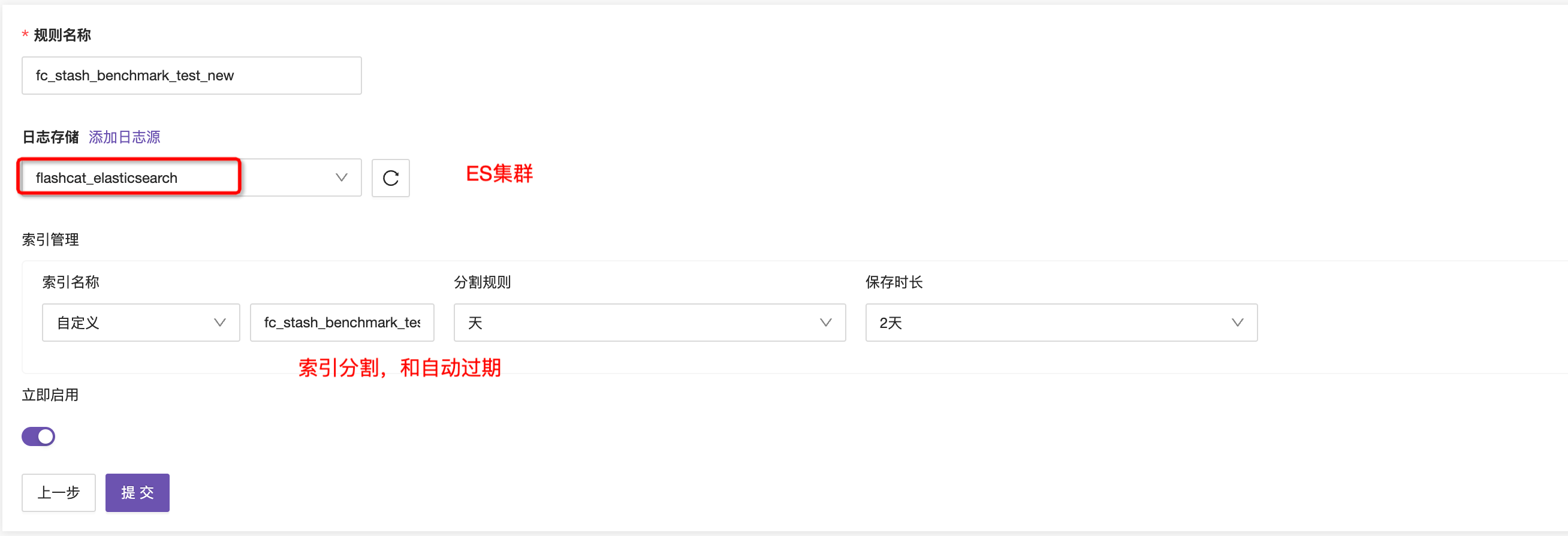
- 第四步,对提取后字段做处理,包括类型转换、无效字段移除、重命名等等,并预览最终结果

- 第五步,配置Elasticsearch写入信息,包括集群、索引名称、分割规则等,提交即可
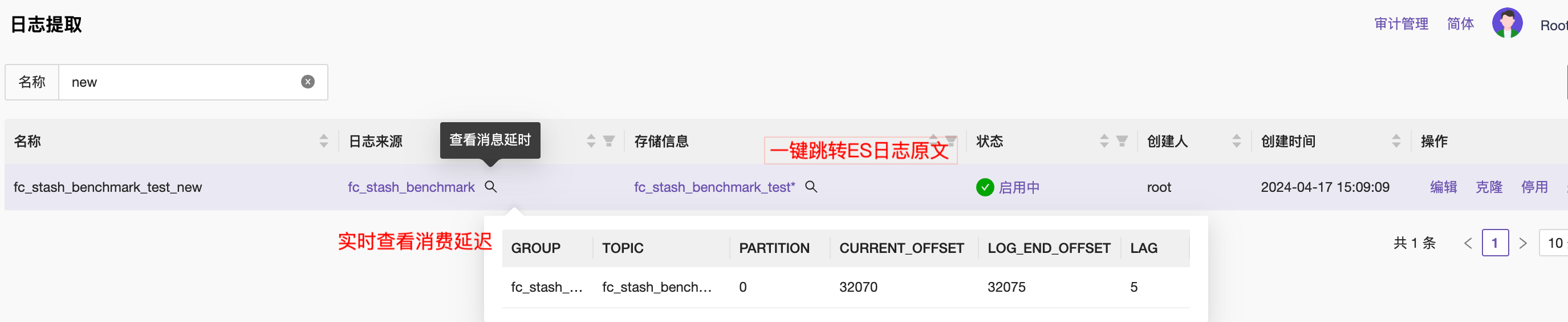
- 最后,在日志提取规则列表页,进行规则管理,包括启用、禁用、查看KAFKA积压、快速跳转Elasticsearch日志查询页面等
两种方案的使用差异
| 维度 | Logstash | fc-stash |
|---|---|---|
| 配置方式 | 编写 pipeline 配置文件 | 通过平台页面配置规则 |
| 解析验证 | 通常需要本地或 stdout 反复调试 | 配置过程中可读取样本并预览效果 |
| 团队协作 | 更适合熟悉配置文件和 IaC 的团队 | 更适合希望多团队自服务和权限隔离的场景 |
| 管理能力 | 依赖外部配置管理和运行维护流程 | 平台内管理 Kafka、Elasticsearch 和提取规则 |
| 上层联动 | 需要自行串接查询、告警和大盘 | 与 Flashcat 的查询、大盘、报警能力统一使用 |
性能对比
基于日志提取模块的功能属性,其性能瓶颈一般包括两部分:
- 自身的资源限制
- 下游Elasticsearch的写入性能,上游KAFKA通常不会成为瓶颈。
本文的压测环境配置为:
Kafka:单点,4核8G
topic的配置 6个partition,写入4k条/s
stash机器:单实例,4核8G
logstash的jvm参数4G
Elasticsearch:3节点,4核8G,100G磁盘,IOPS 5W
索引的配置 6个shard,1主1从副本
压测步骤是 首先提前写入KAFKA消息造成积压现场,这样在启动消费后可以快速达到峰值,积压的消息消费完后,进入平稳消费阶段(即此阶段的日志量是4k条/s),持续10分钟,结束。以下是现场数据记录:
| KAFKA消费峰值 | 单机CPU利用率 | 单机内存利用率 | ES写入峰值 | |
|---|---|---|---|---|
| logstash | 27.4k条/s | 峰值 87%,平峰 12% | 峰值 1.6G,平峰 1.6G | 52K/s |
| fc-stash | 29k条/s | 峰值 82%,平峰 12% | 峰值 800M,平峰 800M | 58K/s |
显然,fc-stash与logstash相比,在内存占用上存在较大的优势,其他指标基本一致。
这组数据的适用边界也要说清楚:它来自本文描述的 Kafka、stash 单实例和 Elasticsearch 三节点环境,日志格式、解析复杂度、索引配置、磁盘性能和下游写入能力都会影响最终表现。因此选型时应在自己的日志样本和目标写入后端上做一次小规模验证。
结语
与logstash相比,fc-stash的优势主要集中在:
- Go语言编写,低内存需求
- 提取规则配置实时预览,所见即所得的体验
- 平台化管理,KAFKA、Elasticsearch配置、提取规则配置均保存在平台,同时Flashcat平台提供。Elasticsearch日志查询、大盘、报警等丰富的功能,使用体验更统一
如果团队已经有成熟的 Logstash 配置体系、自动化发布流程和专人维护,继续使用 Logstash 是合理选择。如果团队更重视低门槛配置、规则预览、多团队自服务和与日志查询告警的一体化体验,fc-stash 更值得评估。
FAQ
Q1:日志 ETL 和日志采集是一回事吗?
不是。采集负责把日志从文件、容器或消息队列送出来;ETL 更关注解析、字段转换、清洗和写入目标后端。两者可以在一个组件里完成,也可以由不同组件分工。
Q2:为什么日志提取后要做字段类型转换?
如果响应时间、状态码、时间戳等字段仍是普通字符串,后续聚合、排序、分位值计算和时间窗口查询都会受影响。结构化字段必须同时保证字段名和字段类型稳定。
Q3:性能选型只看消费条数够吗?
不够。吞吐、CPU、内存、下游写入峰值、规则维护成本、故障恢复、积压观察和团队使用体验都要一起看。



