
Zabbix 监控进程和 Nightingale 生态监控进程,底层原理差不多,都是识别目标进程并采集数量、CPU、内存、句柄等信息。但产品体验差异很大:Zabbix 更多通过 Web 页面管理,Nightingale 更多复用 Prometheus 生态的方式,由 Categraf 这类 agent 通过配置文件驱动采集。
本文分别演示两个产品的配置方式,帮助大家理解它们在进程监控上的设计差异。
核心要点摘要
- Linux 进程监控通常依赖
/proc文件系统,通过进程名、命令行、用户和状态等条件匹配目标进程。 - Zabbix 使用
proc.num[...]这类 Key 表示进程数量监控项,适合在 Web 页面上快速配置和测试。 - Zabbix 的 Key 模型简单直观,但参数没有结构化标签,在复杂聚合计算时不如 Prometheus 标签模型灵活。
- Nightingale 本身不是采集器,进程数据通常由 Categraf、Telegraf、Exporter 或 Datadog Agent 等采集器提供。
- Categraf 的
procstat插件可以采集进程数量、线程、fd、IO、CPU、内存、uptime 和 limit 等指标,再推送给 Nightingale 或远端时序库。
监控进程的原理
所谓进程监控,通常是指监控进程数量以及进程占用的 CPU、内存等资源。
比如监控 Nginx 进程,平时 Nginx 进程数是 8。如果进程数不是 8,就不符合预期。同时,我们也希望知道 Nginx 进程占用了多少 CPU、内存,甚至想知道进程句柄限制等信息。
在 Linux 系统中,进程信息可以通过 /proc 文件系统获取:
/proc/1是 PID 为 1 的进程信息目录。/proc/1/status是 PID 为 1 的进程状态信息。/proc/1/cmdline是 PID 为 1 的启动命令。
所以,进程监控的本质是读取 /proc 文件系统中的信息,再根据进程名、命令行、用户、状态等条件匹配目标进程,最后计算出需要的监控数据。
下面是一个样例:
root@ubuntu-linux-22-04-desktop:~/works# ps aux|grep zabbix_agent
zabbix 116675 0.0 0.0 21688 4140 ? S Nov02 0:00 /usr/sbin/zabbix_agentd -c /etc/zabbix/zabbix_agentd.conf
zabbix 116678 0.0 0.0 21688 2588 ? S Nov02 4:00 /usr/sbin/zabbix_agentd: collector [idle 1 sec]
zabbix 116679 0.0 0.0 23340 4740 ? S Nov02 2:03 /usr/sbin/zabbix_agentd: listener #1 [waiting for connection]
zabbix 116680 0.0 0.0 23344 4736 ? S Nov02 2:02 /usr/sbin/zabbix_agentd: listener #2 [waiting for connection]
zabbix 116681 0.0 0.0 23340 4736 ? S Nov02 2:06 /usr/sbin/zabbix_agentd: listener #3 [waiting for connection]
zabbix 116682 0.0 0.0 23340 4736 ? S Nov02 2:03 /usr/sbin/zabbix_agentd: listener #4 [waiting for connection]
zabbix 116683 0.0 0.0 23340 4740 ? S Nov02 2:04 /usr/sbin/zabbix_agentd: listener #5 [waiting for connection]
zabbix 116684 0.0 0.0 23344 4732 ? S Nov02 2:06 /usr/sbin/zabbix_agentd: listener #6 [waiting for connection]
zabbix 116685 0.0 0.0 23344 4732 ? S Nov02 2:06 /usr/sbin/zabbix_agentd: listener #7 [waiting for connection]
zabbix 116686 0.0 0.0 23344 4732 ? S Nov02 2:04 /usr/sbin/zabbix_agentd: listener #8 [waiting for connection]
zabbix 116687 0.0 0.0 23344 4732 ? S Nov02 2:05 /usr/sbin/zabbix_agentd: listener #9 [waiting for connection]
zabbix 116688 0.0 0.0 23340 4736 ? S Nov02 2:05 /usr/sbin/zabbix_agentd: listener #10 [waiting for connection]
zabbix 116689 0.0 0.0 22228 3808 ? S Nov02 3:27 /usr/sbin/zabbix_agentd: active checks #1 [idle 1 sec]
root 1789894 0.0 0.0 9016 1860 pts/1 S+ 11:43 0:00 grep --color=auto zabbix_agent
root@ubuntu-linux-22-04-desktop:~/works# head -n 3 /proc/116675/status
Name: zabbix_agentd
Umask: 0002
State: S (sleeping)
root@ubuntu-linux-22-04-desktop:~/works# cat /proc/116675/cmdline | tr '\0' ' '; echo
/usr/sbin/zabbix_agentd -c /etc/zabbix/zabbix_agentd.conf
上例中,先通过 ps aux|grep zabbix_agent 找到 zabbix_agentd 进程的 PID,然后通过 /proc/116675/status 查看进程状态,通过 /proc/116675/cmdline 查看启动命令。
其中 status 文件中的 Name 字段是进程名字。监控进程时,经常靠这个字段匹配进程。Name 字段有长度限制,一般是 15 个字符。
cmdline 文件中保存的是进程启动命令,但内容以 \0 分隔,所以示例里用 tr '\0' ' ' 把 \0 替换为空格,方便查看。\0 是不可见、不可打印字符,如果直接 cat /proc/116675/cmdline,会看到一长串没有明显分隔的字符串。
进程监控需要用户告诉监控系统:要监控的进程 Name 是什么,cmdline 有什么特征,是否要限定用户或状态。监控系统根据这些匹配条件找到进程,再输出数量和资源使用情况。
Zabbix 如何监控进程
这里在 Zabbix 中创建一个监控项,用来监控 zabbix_agentd 进程数量。
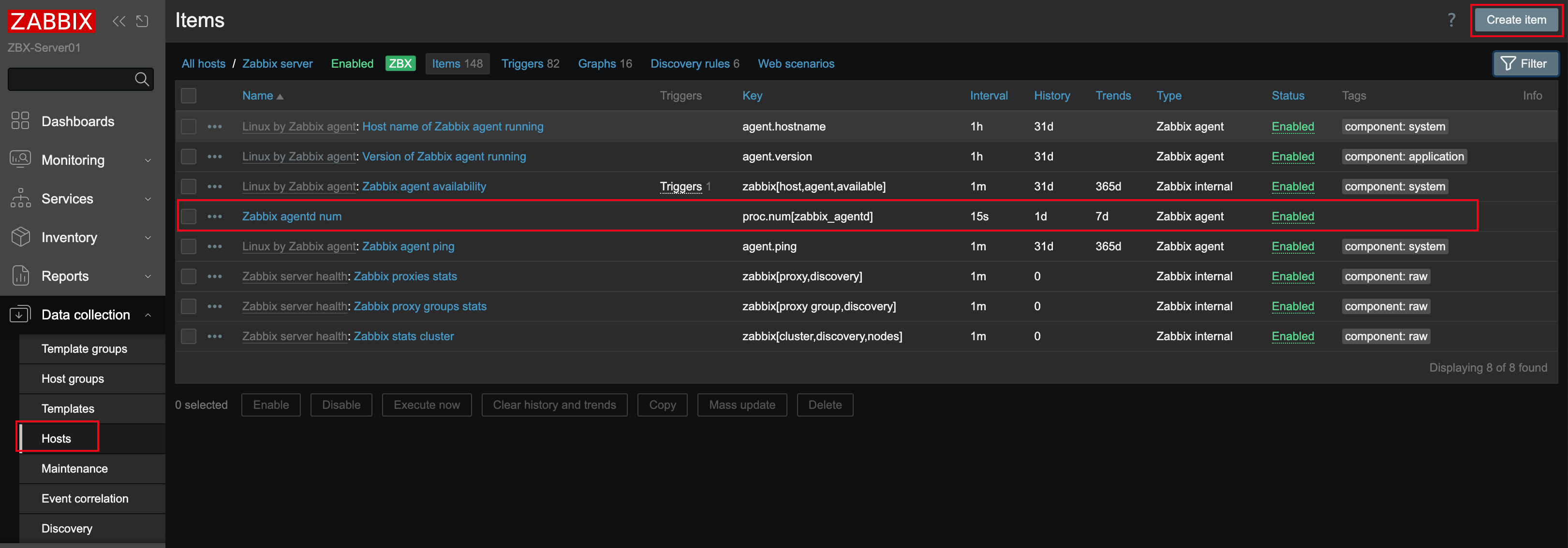
操作路径是:
- 进入 Hosts 菜单。
- 找到要监控的机器。
- 点击 Items 进入监控项列表。
- 点击 Create item 创建监控项。
创建时最核心的是填写 Key。示例中使用:
proc.num[zabbix_agentd]
这个 Key 的意思是监控 zabbix_agentd 进程数量。它是 Zabbix 自带的 Key,不需要用户自己写采集脚本,只需要填写参数即可。
填写完成后点击 Test,可以发起测试请求,检查监控项是否正常。
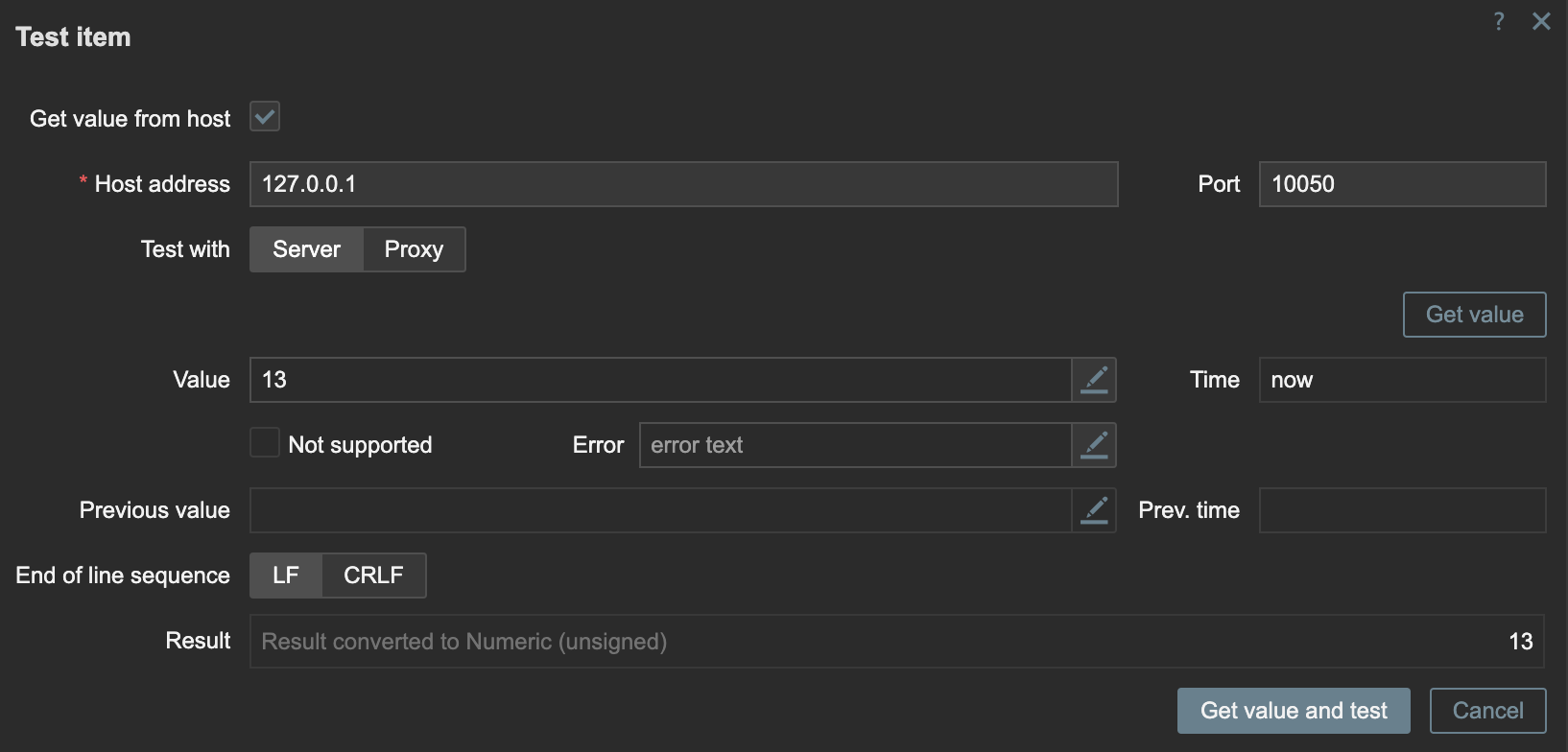
如果监控项正常,就可以创建告警规则。Zabbix 中的告警规则称为 Trigger。
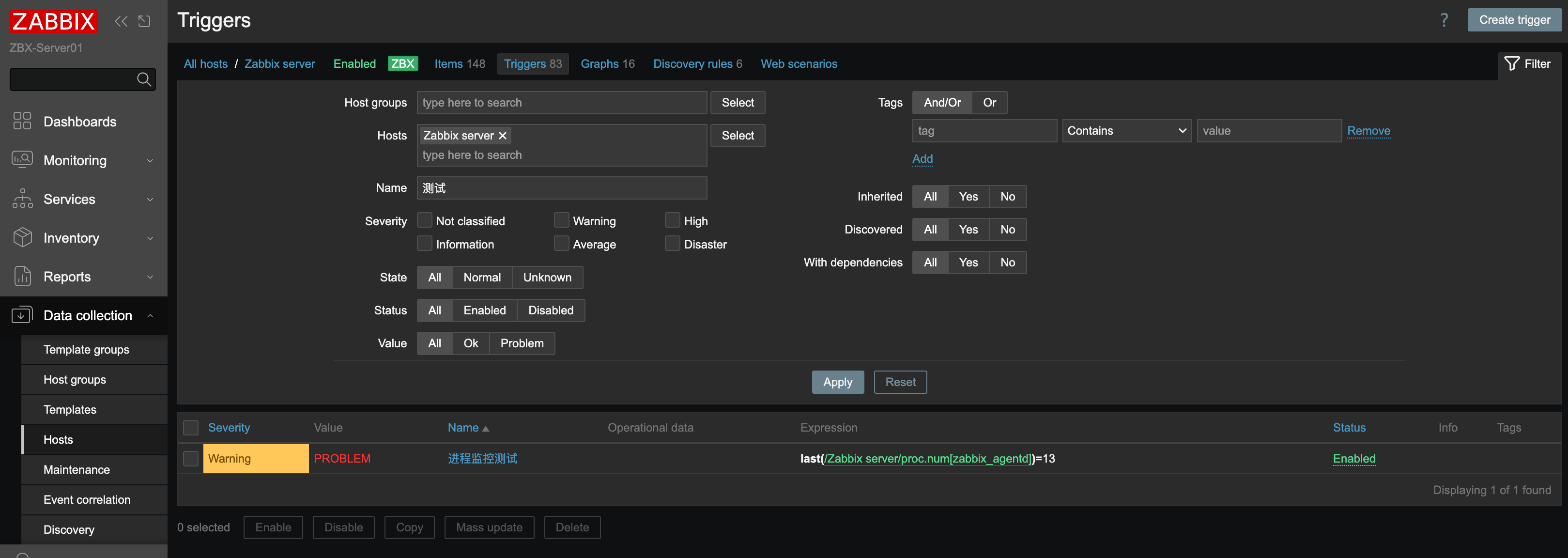
这里我故意把阈值设置为等于 13 就告警,让它立刻产生告警,因为我的环境里这个值就是 13。上图中 Value 是 PROBLEM,表示这个监控项已经触发告警。
Zabbix 的 Key 设计如何理解
对于 Zabbix 内置指标,整体体验比较丝滑,不需要改配置文件,在页面上就可以完成。当然,Zabbix Agent 无法采集所有数据,有些数据仍然需要用户自己写脚本采集,这时就需要改配置文件。
Zabbix Agent 采集的任何数据都有一个 Key 作为标识。Key 对应的监控数据会因为参数不同而结果不同,例如:
proc.num[zabbix_agentd]:监控zabbix_agentd进程数量。proc.num[nginx]:监控nginx进程数量。
可以简单理解为:Zabbix Agent 提供了一个接口,远端 Zabbix Server 通过这个接口获取监控数据。要获取哪些监控数据,就通过 Key 以及 Key 参数传给 Zabbix Agent。
proc.num 还有其他参数,例如:
proc.num[,,run]
这个参数表示监控所有 run 状态进程的数量。
proc.num 的完整调用格式是:
proc.num[<name>,<user>,<state>,<cmdline>,<zone>]
各参数含义如下:
| 参数 | 含义 |
|---|---|
name |
进程名,默认匹配所有进程。 |
user |
用户名,默认匹配所有用户。 |
state |
进程状态,可取 all、disk、run、sleep、trace、zomb 等。 |
cmdline |
按命令行过滤,支持正则表达式。 |
zone |
目标 zone,默认 current,也可以是 all。该参数仅 Solaris 支持。 |
这种 Key 的设计今天来看不太适合复杂聚合计算,因为参数和 Key 没有结构化区分。比如要计算某个服务所有接口的平均响应时间,就需要很多 Key 再做聚合,灵活性不够。OpenTSDB、Prometheus 等采用 metric name + 多维度标签的方式,更适合这类需求。

Nightingale 生态如何监控进程
严格说,Nightingale 本身并不采集监控数据。它更多是一个告警引擎和监控平台入口。监控数据的采集通常由 Prometheus Exporter、Telegraf、Categraf、Datadog Agent 等采集器完成。
这里以 Categraf 为例。Categraf 是一个 Go 语言编写的监控数据采集器,支持很多插件。监控进程的插件叫 procstat。
下面是 procstat 配置示例:
[[instances]]
# # executable name (ie, pgrep <search_exec_substring>)
search_exec_substring = "zabbix_agentd"
# # pattern as argument for pgrep (ie, pgrep -f <search_cmdline_substring>)
# search_cmdline_substring = "n9e server"
# # windows service name
# search_win_service = ""
# # search_exec_regexp: Use a regular expression to match the executable path
# # executable name filter to regexp (like "ps -e | grep -E <search_exec_regexp>" but using re2 regexp )
# search_exec_regexp = ""
# # search_cmdline_regexp: Use a regular expression to match the command line
# # executable name filter to regexp (like "ps -ef | grep -E <search_cmdline_regexp>" but using re2 regexp )
# search_cmdline_regexp = ""
# # [option] search process with specific user
# search_user = ""
# # mode to use when calculating CPU usage. can be one of 'solaris' or 'irix'
# mode = "irix"
# sum of threads/fd/io/cpu/mem, min of uptime/limit
gather_total = true
# will append pid as tag
gather_per_pid = true
gather_more_metrics = [
"threads",
"fd",
"io",
"uptime",
"cpu",
"mem",
"limit"
]
上例同样采集 zabbix_agentd 进程数据。它不只可以采集进程数量,也可以采集 threads、fd、IO、CPU、内存、uptime、limit 等指标。
如果要采集多个进程,复制多个 [[instances]] 配置块即可。
Zabbix 要采集什么数据基本都需要在 Web 上配置;Prometheus 生态要采集什么数据,大多通过配置采集器完成。数据采集、数据处理和转换,也更多在采集器中完成。
配置完成 procstat.toml 后,可以执行下面的命令查看采集到了哪些指标:
./categraf --test --inputs procstat
如果一切正常,就可以使用 systemd 之类的进程管理器启动 Categraf,让 Categraf 把采集到的数据通过 remote write 协议推给远端 Nightingale,或者直接推给远端时序库。
数据采集之后,就可以在 Nightingale 中配置告警规则。一般公司会监控很多进程,没必要为每个进程分别配置一条告警规则。在 Prometheus 生态里,可以用类似下面的 PromQL 判断 Categraf 是否匹配到了目标进程:
procstat_lookup_count != 0
如果要做“进程不存在就告警”的规则,可以围绕这个指标反向配置告警条件。
Zabbix 和 Nightingale/Categraf 的差异
| 对比项 | Zabbix | Nightingale/Categraf |
|---|---|---|
| 采集入口 | Web 页面配置 Item。 | Categraf 配置文件配置插件。 |
| 进程匹配 | 使用 proc.num[...] 等 Key 参数。 |
使用 procstat 的进程名、命令行、用户等配置项。 |
| 数据模型 | Host + Key。 | metric name + labels。 |
| 告警配置 | Zabbix Trigger。 | Nightingale 告警规则和 PromQL。 |
| 适合场景 | 固定主机、页面化配置、Zabbix 存量环境。 | 多维标签、统一时序库、Prometheus 生态。 |
FAQ
Zabbix 监控进程一定要写脚本吗?
不一定。像 proc.num 这类内置 Key 可以直接监控进程数量,不需要写脚本。只有内置能力覆盖不了的数据,才需要通过脚本扩展。
Nightingale 可以直接采集进程数据吗?
Nightingale 本身不直接采集数据。它通常接收 Categraf、Exporter、Telegraf 等采集器上报的数据,再做查询、告警和展示。
进程监控应该匹配 Name 还是 cmdline?
要看场景。Name 简单,但长度有限;cmdline 信息更完整,可以区分同名进程的不同启动参数。实际配置中经常需要结合使用。
总结
本文围绕进程监控,演示了 Zabbix 和 Nightingale/Categraf 两种配置方式。两者底层都依赖操作系统进程信息,但产品设计不同。
Zabbix 的优势是 Web 配置直观,内置 Key 上手快,适合固定主机和存量 Zabbix 环境。Nightingale/Categraf 的优势是更贴近 Prometheus 生态,采集配置、标签模型和聚合告警更灵活。
对于刚接触监控的朋友来说,能监控进程存活只是第一步。真正决定后续可维护性的,是数据模型、采集方式、标签组织和告警规则的设计。


