
Zabbix 监控 Redis 和 Nightingale 生态监控 Redis,采集原理类似:连接 Redis 实例,执行 info 之类的命令,解析输出,再把结果写入监控系统。但两者的产品体验和数据模型差异很大。
本文分别说明 Zabbix 和 Nightingale/Categraf 的 Redis 监控方式,帮助大家做选型对比。
核心要点摘要
- Redis 监控的采集端逻辑并不复杂,通常是通过 TCP 连接 Redis,执行
info命令并解析 key-value 输出。 - Zabbix 老版本监控 Redis 主要依赖自定义脚本;Zabbix Agent 2 开始支持更多采集能力,包括 Redis 监控。
- 在 Zabbix 中,建议把 Redis 采集任务下发给 Redis 实例所在机器上的 agent,减少网络因素影响。
- Nightingale 本身不采集数据,通常由 Categraf 等采集器采集 Redis 指标,再推送给 Nightingale 或远端时序库。
- 少量 Redis 实例用 Zabbix 也能工作;大量实例、高频采集和复杂聚合场景,更适合 Prometheus 生态和专用时序库。
监控 Redis 的原理
监控 Redis 的原理比较简单:通过 TCP 连到 Redis 实例,执行 info 之类的命令获取输出,解析输出中的 key-value,再把解析出来的数据推给监控系统。
MySQL、MongoDB 等数据库或中间件监控,从采集端看也有类似思路:连接目标实例,执行查询或状态命令,解析输出,再转换为监控指标。
当然,采集逻辑简单,不代表理解指标含义简单。Redis 指标很多,不同指标背后的容量、性能和异常含义需要结合实际业务判断。本文只讨论采集和监控系统接入方式。
下面是我的环境里通过 info 命令拿到的部分输出:
$ redis-cli
127.0.0.1:6379> info
# Server
redis_version:6.2.16
redis_git_sha1:00000000
redis_git_dirty:0
...
# Memory
used_memory:963376
used_memory_human:940.80K
used_memory_rss:8712192
used_memory_rss_human:8.31M
used_memory_peak:1021480
上面的内容只截取了一部分,但已经能说明问题。info 命令的输出按 section 分组,每个 section 里有很多 key-value 对,这些 key-value 对就是监控系统要解析和上报的指标来源。
Zabbix 如何监控 Redis
Zabbix 老版本监控 Redis 主要靠用户自行编写采集脚本。这种方式可行,但比较麻烦。
从 Zabbix Agent 2 开始,agent 使用 Go 重写,支持了更多新的采集能力,其中就包括 Redis 监控数据采集。
Zabbix 的采集流程可以理解为:
- 选择一个 agent 所在机器作为探针。
- 在 Zabbix 中给这个探针下发采集任务。
- Agent 执行采集任务,连接 Redis 并获取数据。
- Agent 把采集到的数据发送给 Zabbix Server。
- Zabbix Server 存储数据,并根据用户配置的告警规则触发告警。
一般来讲,为了稳定可靠地采集,建议直接把采集任务下发给 Redis 实例所在机器上的 agent。这样 agent 可以通过 127.0.0.1:6379 连接本地 Redis 实例,采集过程受网络影响更小。
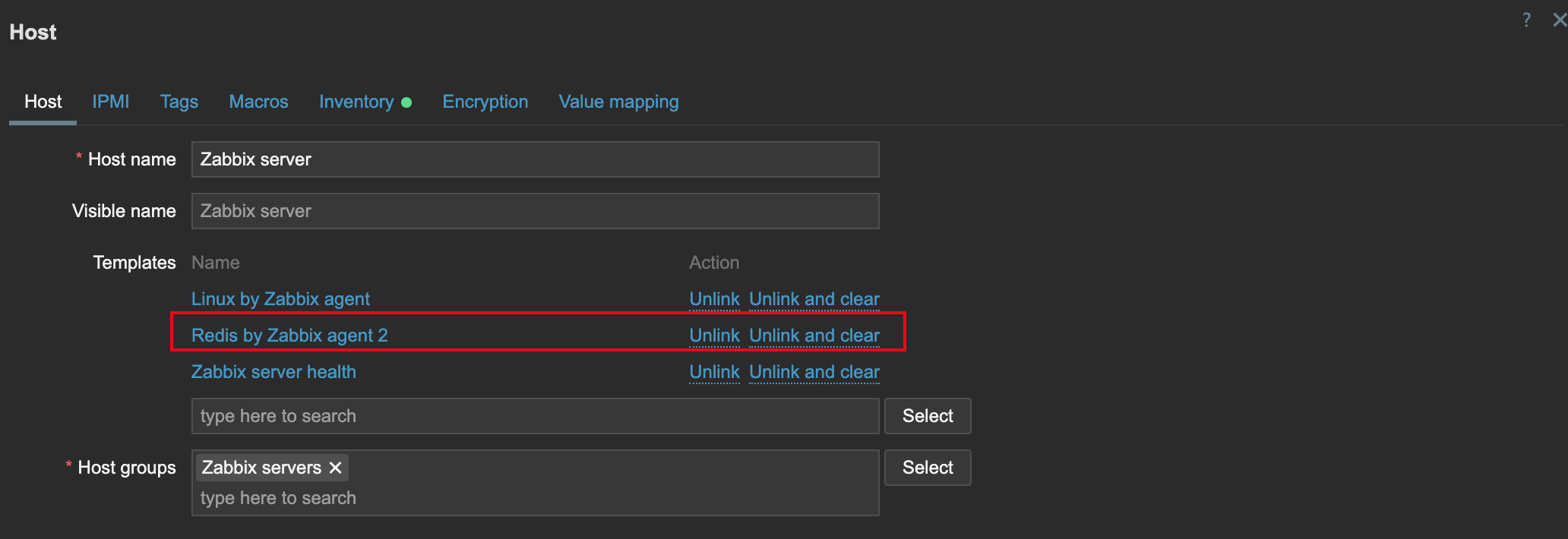
上例中,我给这台机器绑定了 Redis by Zabbix agent 2 模板。这个模板默认连接的是:
tcp://localhost:6379
绑定模板后,就可以采集到 Redis 指标。比如 redis.clients.connected 这个 Key 表示当前连接到 Redis 的客户端数量。
Nightingale/Categraf 如何监控 Redis
Nightingale 本身无法采集数据,可以使用 Categraf 作为采集器。当然,也可以使用其他习惯的采集器。
下面是 Categraf 采集 Redis 的相关配置:
[[instances]]
address = "localhost:6379"
labels = { instance="n9e-10.2.3.4:6379" }
这个配置的核心是 address,也就是 Redis 实例地址。如果 Redis 设置了密码,还需要配置 password。
示例中还给采集数据附加了一个 instance 标签。后续就可以根据 instance 标签区分不同 Redis 实例。
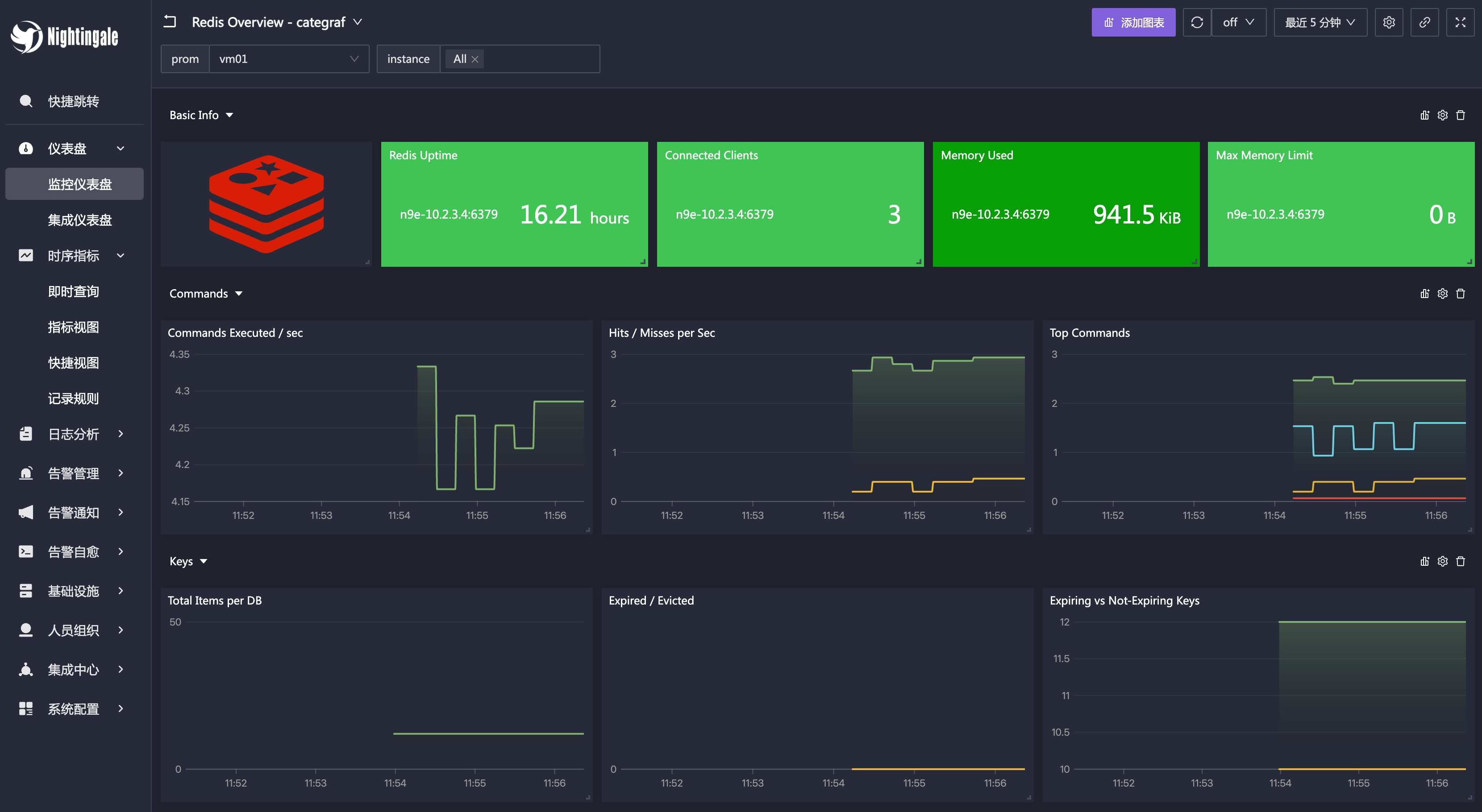
上图是使用 Categraf 采集数据并推给夜莺后,在夜莺中导入 Redis 内置仪表盘看到的效果。

Zabbix 和 Nightingale 的关键差异
表面上看,Zabbix 和 Nightingale/Categraf 都是在采 Redis 指标,差别好像不大。实际上差异主要在数据模型、存储和生态。
| 对比项 | Zabbix | Nightingale/Categraf |
|---|---|---|
| 采集方式 | Zabbix Agent 2 通过模板和 Key 采集 Redis。 | Categraf Redis 插件采集后推送到 Nightingale 或时序库。 |
| 数据模型 | 使用 Key 表示监控指标。 | 使用 Prometheus/OpenTSDB 生态的指标名 + 标签。 |
| 实例区分 | 依赖 Host、Key 和模板配置。 | 通过 instance 等标签区分不同 Redis 实例。 |
| 存储方式 | 依赖 Zabbix 底层数据库和历史数据模型。 | 通常接入 Prometheus 生态或专用时序库。 |
| 聚合计算 | Key 模型在多维聚合上不够灵活。 | 标签模型更适合按实例、服务、环境等维度聚合。 |
数据结构差异
Zabbix 使用 Key 表示监控指标。Nightingale 复用 OpenTSDB、Prometheus 生态的标签 + 指标方式,更灵活,尤其是在聚合计算时更明显。
Redis 这种中间件,经常需要按实例、集群、业务、环境等维度查看和聚合。如果数据从一开始就带有结构化标签,后续查询和告警规则会更容易维护。
存储容量差异
如果只有少量 Redis 实例要监控,差异感受不深。但如果有大量 Redis 实例,并且需要高频率采集,就会明显感受到 RDBMS 存储时序数据的瓶颈。Zabbix 在这个点上比较吃力。
Redis 实例的指标数量整体还好。如果换成 Elasticsearch 这类组件,要想完整采集,一个实例就可能有非常多指标。这类大规模时序数据更适合使用专门的时序库。
选型建议
如果你使用的是第一代 Zabbix Agent,笔者不建议用 Zabbix 监控 Redis 以及各类数据库、中间件。后续 Zabbix Agent 2 会更好一些,可以用,但因为 Zabbix 的历史包袱,笔者仍然不建议把它作为中间件监控首选。
笔者的判断是:
- Zabbix 更适合监控网络设备和传统基础设施。
- 数据库、中间件、Kubernetes、微服务这些监控需求,更适合交给 Prometheus 生态。
- Redis 实例少、已有 Zabbix 环境且只需要基础监控时,可以继续用 Zabbix Agent 2。
- Redis 实例多、需要高频采集、多维聚合和统一告警时,建议使用 Categraf、Telegraf、Prometheus Exporter 等采集器接入 Prometheus 生态。
Prometheus 生态的采集器很多,除了本文介绍的 Categraf,还可以使用 Telegraf、Prometheus Exporter 等。这些采集器都是开源的,可以根据团队习惯选择。
Nightingale 在 Prometheus 生态里扮演的是高可用、UI 易用的告警引擎。它可以同时对接多套 Prometheus,用一套告警规则生效到多套 Prometheus,并提供权限管控,适合给全公司多个团队使用。后面 Nightingale 会开放 Elasticsearch、ClickHouse 的告警引擎能力,届时会更加强大。
FAQ
Zabbix 能监控 Redis 吗?
可以。Zabbix Agent 2 已支持 Redis 监控能力,可以通过绑定 Redis 模板采集指标。老版本 Zabbix 通常需要自定义脚本。
Nightingale 为什么还需要 Categraf?
因为 Nightingale 本身主要承担告警引擎和平台入口角色,不直接负责采集。Redis 指标需要由 Categraf、Telegraf 或 Exporter 等采集器获取并上报。
少量 Redis 实例是否必须迁到 Prometheus 生态?
不一定。如果实例数量少、采集频率不高、团队已有 Zabbix 体系,用 Zabbix Agent 2 也可以满足基础需求。Prometheus 生态的优势主要体现在大量实例、多维标签和复杂聚合场景。
总结
Zabbix 和 Nightingale/Categraf 监控 Redis 的采集原理类似,都是连接 Redis、执行命令、解析输出并上报指标。真正的差异在于数据模型、存储能力和生态扩展方式。
Zabbix 适合已有 Zabbix 环境中的基础 Redis 监控,尤其是实例数量不多、监控要求不复杂的场景。Nightingale/Categraf 更适合 Prometheus 生态,适合实例更多、标签维度更多、聚合和告警治理要求更高的场景。


