
背景和概述
如果没有正确的解析,日志数据很难被有效解释和使用。常见后果包括排障时间变长、关键事件难以检索、告警规则无法利用结构化字段,以及日志进入后端后只能做全文搜索。
在 Fluent Bit 中,Parser 的作用是把非结构化或半结构化日志拆成可识别字段。拆出来的字段可以继续用于过滤、路由、告警、聚合分析和输出到不同系统。本文以 Linux messages 日志为例,演示如何用正则表达式解析日志,并把一整行日志拆成 time、host、ident、pid 和 message。
本文的核心步骤如下:
- 先确认原始日志行里有哪些字段值得提取。
- 用命名捕获组编写正则表达式。
- 在
custom_parsers.conf中定义 regex Parser。 - 在
tail输入插件里通过Parser引用这个解析器。 - 用 stdout 输出验证字段和时间戳是否符合预期。
解析数据时,正则表达式允许用户定义与日志数据的特定部分匹配的复杂模式,例如时间戳、错误消息或 IP 地址。这提供了一种强大而灵活的方法来从日志数据中提取和组织相关信息,使其更易于理解、分析和采取行动。
在本博客中,作为学习 Fluent Bit 的第二个练习,我们将使用正则表达式解析获得的日志数据。如果您想从头开始学习,可以参考第一篇博客《Fluentbit 入门教程(1):tail 插件》。
Fluentbit 实验环境
- 操作系统:CentOS8
- Fluent Bit 版本:v2.0.6
- 硬件规格:2CPU,2GB内存
目录结构和日志文件
就像我们的第一篇博客一样,我们将使用 Fluent Bit 中的“tail”插件从典型的 Linux 日志文件中获取数据。目录结构和日志文件也将保持不变。
本案例的目录结构如下:
/fluentbit : root directory
|--- conf
|--- custom_parsers.conf
|--- Lab01
|-- (Lab01 configuration files)
|-- sample
|-- (Sample log files for exercise)
|--- log
|--- buffer
这是我们将尝试解析的示例 Linux 日志:sample01_linux_messages.txt
Oct 27 16:14:31 fluent01 systemd[1]: Started dnf makecache.
Oct 27 16:20:29 fluent01 systemd[1]: Starting system activity accounting tool...
Oct 27 16:20:29 fluent01 systemd[1]: Started system activity accounting tool.
Oct 27 16:40:29 fluent01 kubelet[896]: W1027 16:40:29.280967 896 watcher.go:95] Error while processing event ("/sys/fs/cgroup/cpu,cpuacct/system.slice/sysstat-collect.service": 0x40000100 == IN_CREATE|IN_ISDIR): inotify_add_watch /sys/fs/cgroup/cpu,cpuacct/system.slice/sysstat-collect.service: no such file or directory
Oct 27 16:40:29 fluent01 kubelet[896]: W1027 16:40:29.281027 896 watcher.go:95] Error while processing event ("/sys/fs/cgroup/blkio/system.slice/sysstat-collect.service": 0x40000100 == IN_CREATE|IN_ISDIR): inotify_add_watch /sys/fs/cgroup/blkio/system.slice/sysstat-collect.service: no such file or directory
Oct 27 16:40:29 fluent01 kubelet[896]: W1027 16:40:29.281048 896 watcher.go:95] Error while processing event ("/sys/fs/cgroup/memory/system.slice/sysstat-collect.service": 0x40000100 == IN_CREATE|IN_ISDIR): inotify_add_watch /sys/fs/cgroup/memory/system.slice/sysstat-collect.service: no such file or directory
现在让我们继续练习解析这些数据!
Fluentbit 配置练习
在之前的练习中,Fluent Bit 只是从目标文件读取日志消息并将其输出到标准输出。默认情况下,整行消息会嵌套在 log 键下。但在实际日志分析中,我们通常希望把一行日志拆成多个字段。以下日志中包含这些信息:
Oct 27 16:14:31 fluent01 systemd[1]: Started dnf makecache.
- Timestamp : Oct 27 16:14:31
- Hostname : fluent01
- Ident : systemd
- Process ID : 1
- Message Body : Started dnf makecache
第 1 步:创建正则表达式
这一步的目标是使用正则表达式定义字段提取规则。下面的表达式通过命名捕获组把同一行日志拆成 time、host、ident、pid 和 message。
正则表达式:
/^(?<time>[^ ]* {1,2}[^ ]* [^ ]*) (?<host>[^ ]*) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?(?:[^\:]*\:)? *(?<message>.*)$/
输出:
{
"time" : "Oct 27 16:14:31",
"host" : "fluent01",
"ident" : "systemd",
"pid" : "1",
"message" : "Started dnf makecache."
}
Rubular 和 Regex101 对于调试正则表达式非常有用。建议在写入 Fluent Bit 配置前,先用样例日志验证每个命名字段是否能被正确捕获。
第 2 步:定义自定义解析器
一旦正则表达式准备就绪,下一步就是为 Fluent Bit 定义自定义解析器。通常做法是把 Parser 放在 custom_parsers.conf 中,并在 [SERVICE] 部分用 Parsers_File 指定该文件。
以下是 Linux 操作系统日志消息的自定义解析器定义示例。您可以在“正则表达式”选项中找到自定义正则表达式。
[PARSER]
Name syslog-messages
Format regex
Regex /^(?<time>[^ ]* {1,2}[^ ]* [^ ]*) (?<host>[^ ]*) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?(?:[^\:]*\:)? *(?<message>.*)$/
Time_Key time
Time_Format %b %d %H:%M:%S
Time_Keep On
正如第一篇博客中所述,如果不做时间解析,Fluent Bit 会使用读取日志文件时的时间作为事件时间戳,这可能与原始日志中的时间不一致。Time_Key、Time_Format 和 Time_Keep 用来解决这个问题。
Time_Key:指定提供时间信息的字段名称。Time_Format:指定时间字段的格式,以便 Fluent Bit 正确识别和解析。Time_Keep:默认情况下,解析时间键后,解析器可能删除原始时间字段。启用该选项后,Fluent Bit 会保留日志消息本身记录的时间字段。
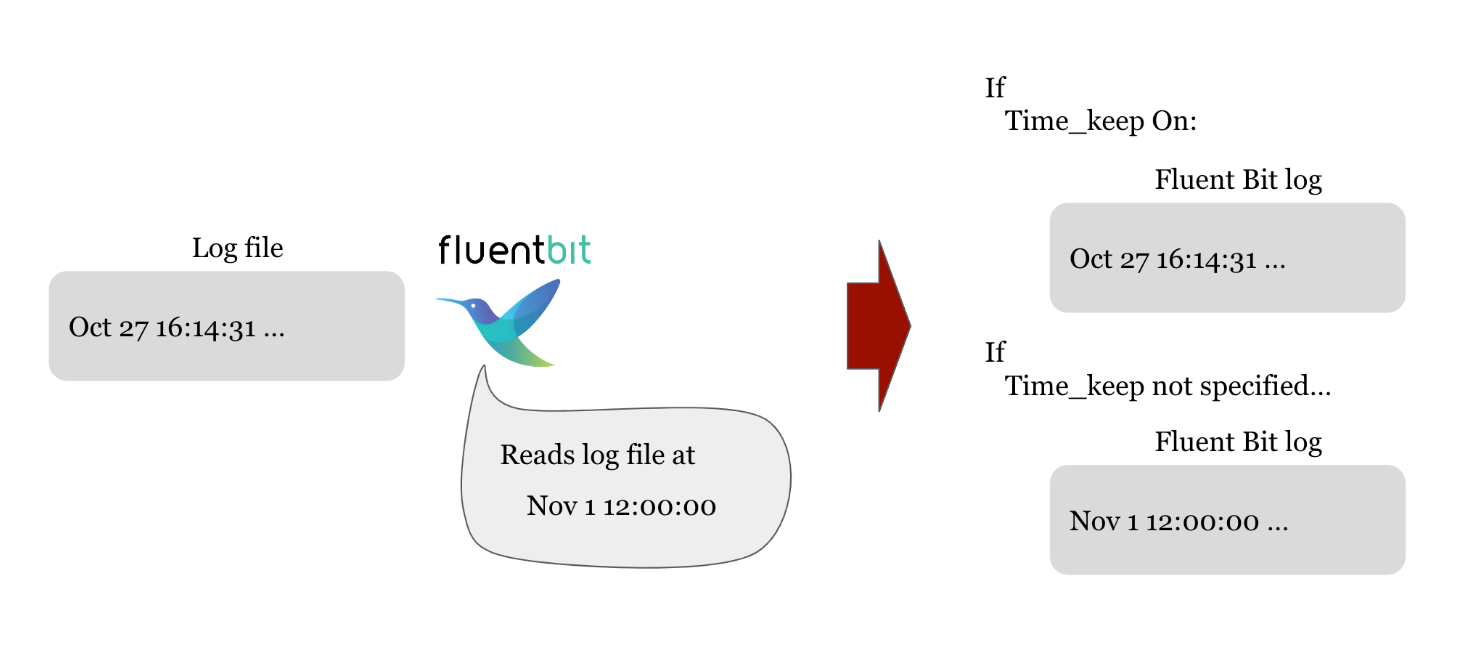
在示例解析器中,我们将时间戳捕获为“time”键,时间格式为“Oct 27 16:14:31”,可以标准化为“%b %d %H:%M:%S”。有关标准化时间格式的方法,请尝试查看此页面。
第 3 步:使用自定义解析器运行 Fluent Bit
让我们使用自定义解析器运行 Fluent Bit!自定义解析器配置到文件 custom_parsers.conf 中:
[PARSER]
Name syslog-messages
Format regex
Regex /^(?<time>[^ ]* {1,2}[^ ]* [^ ]*) (?<host>[^ ]*) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?(?:[^\:]*\:)? *(?<message>.*)$/
Time_Key time
Time_Format %b %d %H:%M:%S
Time_Keep On
之后,我们在 tail 这个 INPUT 插件里写上 Parser syslog-messages,同时注意把 Parsers_File 指向 custom_parsers.conf 的路径:
[SERVICE]
## General settings
Flush 5
Log_Level Info
Daemon off
Log_File /fluentbit/log/fluentbit.log
Parsers_File /fluentbit/conf/custom_parsers.conf
## Buffering and Storage
Storage.path /fluentbit/buffer/
Storage.sync normal
Storage.checksum Off
Storage.backlog.mem_limit 5M
Storage.metrics On
## Monitoring (if required)
HTTP_Server true
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 5
HC_Retry_Failure_Count 5
HC_Period 60
[INPUT]
Name tail
Tag linux.messages
Path /fluentbit/conf/Lab01/sample/sample01_linux_messages.txt
Storage.type filesystem
Read_from_head true
DB /fluentbit/tail_linux_messages.db
Parser syslog-messages
[OUTPUT]
Name stdout
Match linux.messages
让我们使用示例配置运行 Fluent Bit:
您可能需要删除“DB”文件 /fluentbit/tail_linux_messages.db 以使 Fluent Bit 从头开始读取该行。
$ fluent-bit -c sample02_flb_tail_custom_parser.conf
您可以在标准输出中看到解析后的消息。
[0] linux.messages: [1666887271.000000000, {"time"=>"Oct 27 16:14:31", "host"=>"fluent01", "ident"=>"systemd", "pid"=>"1", "message"=>"Started dnf makecache."}]
[1] linux.messages: [1666887629.000000000, {"time"=>"Oct 27 16:20:29", "host"=>"fluent01", "ident"=>"systemd", "pid"=>"1", "message"=>"Starting system activity accounting tool..."}]
[2] linux.messages: [1666887629.000000000, {"time"=>"Oct 27 16:20:29", "host"=>"fluent01", "ident"=>"systemd", "pid"=>"1", "message"=>"Started system activity accounting tool."}]
[3] linux.messages: [1666888829.000000000, {"time"=>"Oct 27 16:40:29", "host"=>"fluent01", "ident"=>"kubelet", "pid"=>"896", "message"=>"W1027 16:40:29.280967 896 watcher.go:95] Error while processing event ("/sys/fs/cgroup/cpu,cpuacct/system.slice/sysstat-collect.service": 0x40000100 == IN_CREATE|IN_ISDIR): inotify_add_watch /sys/fs/cgroup/cpu,cpuacct/system.slice/sysstat-collect.service: no such file or directory"}]
[4] linux.messages: [1666888829.000000000, {"time"=>"Oct 27 16:40:29", "host"=>"fluent01", "ident"=>"kubelet", "pid"=>"896", "message"=>"W1027 16:40:29.281027 896 watcher.go:95] Error while processing event ("/sys/fs/cgroup/blkio/system.slice/sysstat-collect.service": 0x40000100 == IN_CREATE|IN_ISDIR): inotify_add_watch /sys/fs/cgroup/blkio/system.slice/sysstat-collect.service: no such file or directory"}]
[5] linux.messages: [1666888829.000000000, {"time"=>"Oct 27 16:40:29", "host"=>"fluent01", "ident"=>"kubelet", "pid"=>"896", "message"=>"W1027 16:40:29.281048 896 watcher.go:95] Error while processing event ("/sys/fs/cgroup/memory/system.slice/sysstat-collect.service": 0x40000100 == IN_CREATE|IN_ISDIR): inotify_add_watch /sys/fs/cgroup/memory/system.slice/sysstat-collect.service: no such file or directory"}]
- 正如预期的那样,输出中已经有
time、host、ident、pid和message字段。 - 另外,Fluent Bit 写入的时间戳与原始消息中的时间戳相同。
配置检查清单
| 检查项 | 为什么重要 | 本文示例 |
|---|---|---|
| 正则命名捕获组 | 决定最终能得到哪些结构化字段 | time、host、ident、pid、message |
Parsers_File |
告诉 Fluent Bit 到哪里加载自定义解析器 | /fluentbit/conf/custom_parsers.conf |
Parser Name |
在 tail 输入插件里引用解析器 |
syslog-messages |
Time_Key |
指定原始日志里的时间字段 | time |
Time_Format |
指定时间字符串格式 | %b %d %H:%M:%S |
Time_Keep |
保留原始时间字段,便于后续排查 | On |
FAQ
Q1:为什么要用正则解析,而不是直接保留整行日志?
A:整行日志只能做全文检索;解析成字段后,可以按主机、进程、PID、消息正文、时间等维度过滤和分析,也更容易做告警和路由。
Q2:Time_Keep On 有什么价值?
A:它可以保留原始日志中的时间字段。这样在排查时间戳问题时,既能看 Fluent Bit 事件时间,也能看到日志原文里的时间信息。
Q3:正则解析失败时应该先检查什么?
A:先用 Rubular 或 Regex101 验证样例日志是否能匹配,再检查 custom_parsers.conf 是否被 Parsers_File 正确加载,最后确认 INPUT 中的 Parser 名称与 Parser 定义中的 Name 完全一致。
总结
在本博客中,我们学习了如何使用正则表达式在 Fluent Bit 中解析 Linux messages 日志。关键过程包括:用命名捕获组拆分字段,在 custom_parsers.conf 中定义 regex Parser,在 tail 输入插件中引用该 Parser,并通过 Time_Key、Time_Format、Time_Keep 保持事件时间与原始日志时间一致。
完成这个练习后,你已经掌握了 Fluent Bit 日志结构化的基本路径。下一步可以继续学习如何解析多行日志,例如 Java 堆栈、应用异常和容器日志。
原文:https://fluentd.ctc-america.com/blog/parsing-in-fluent-bit-using-regular-expression



