
微服务监控 - Jaeger 简介
CNCF 主推的分布式链路追踪方案是 Jaeger,来自 Uber,Uber 有几千个微服务,调用关系错综复杂,Jaeger 和 M3DB 可谓 Uber 两大微服务监控利器,本讲我们就一起来看一下 Jaeger。本文转载自 MakeOptim

Jaeger 是受到 Dapper 和 OpenZipkin 启发的由 Uber Technologies 作为开源发布的分布式跟踪系统。Jaeger 用于监视和诊断基于微服务的分布式系统,包括:
- 分布式上下文传播
- 分布式传输监控
- 根本原因分析
- 服务依赖性分析
- 性能/延迟优化
注:简单理解的话, 可以认为 Jaeger 是兼容 OpenTracing 的一个实现。
Uber 发表了一篇博客文章 Evolving Distributed Tracing at Uber,文中解释了 Jaeger 在架构选择方面的历史和原因。Jaeger 的创建者 Yuri Shkuro 还出版了一本书 Mastering Distributed Tracing,该书深入介绍了 Jaeger 设计和操作的许多方面,以及一般的分布式跟踪。
特性
- 兼容 OpenTracing 的数据模型和工具库,包括 Go,Java,Node,Python, C++ 和 C#
- 对每个服务/端点概率使用一致的前期采样
- 多种存储后端支持:Cassandra,Elasticsearch,内存。
- 系统拓扑图
- 自适应采样(即将推出)
- 收集后数据处理管道(即将推出)
注:更多详细信息,请参见特性页面。
架构
Jaeger 的客户端遵守 OpenTracing 的数据模型。
为了更好地理解 Jaeger 的架构,先回顾以下几个术语。
Span
一个 Span 表示 Jaeger 的逻辑工作单元,Span 具有操作名称,操作的开始时间,和持续时间。Span 可以嵌套并排序以建立因果关系模型。

Trace
一个 Trace 是通过系统的数据/执行路径,Trace 可被认为是由一组 Span 定义的有向无环图(DAG)。
组件
Jaeger 可以使用 all-in-one 二进制(其中所有 Jaeger 后端组件都在单个进程中运行)进行部署,也可以作为可扩展的分布式系统进行部署,如下所述。有两个主要的部署选项:
- 收集器直接写入存储。
- 收集器写入 Kafka 作为中间缓冲。
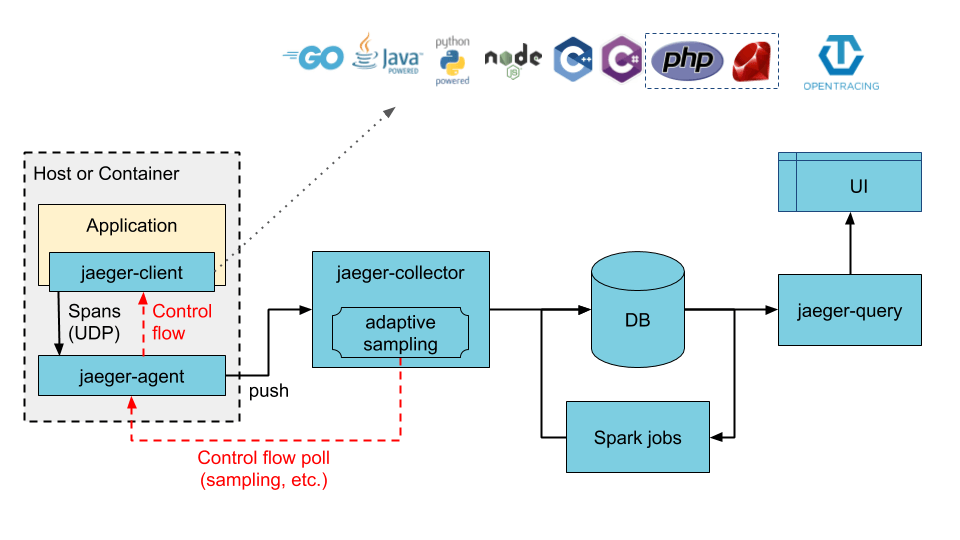
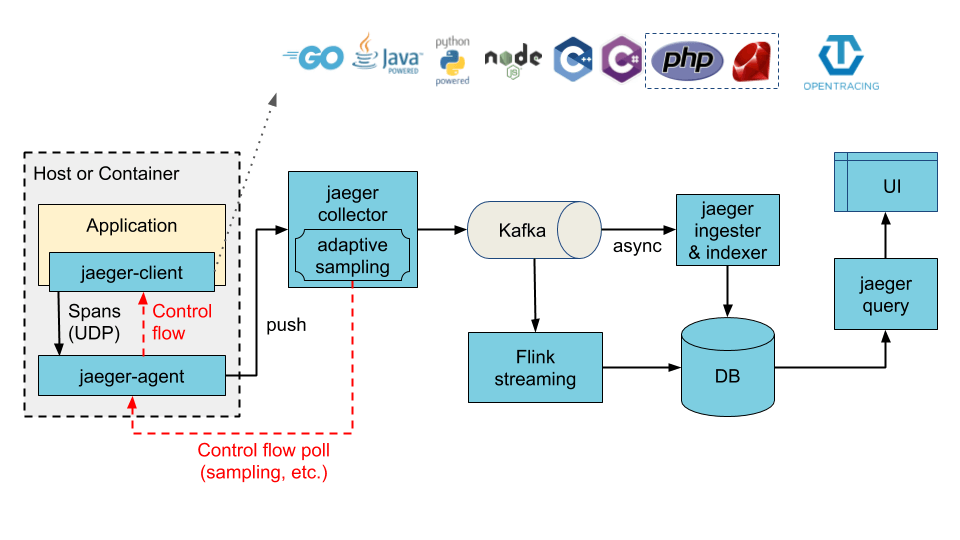
下面介绍 Jaeger 各个组件以及组件间的关系。
客户端库(client libraries)
Jaeger 客户端是 OpenTracing API 的特定于语言的实现。它们可用于手动或与已经与 OpenTracing 集成的各种现有开源框架(例如 Flask,Dropwizard,gRPC 等)一起为分布式跟踪应用程序进行检测。
检测服务在接收新请求时创建 Span,并将上下文信息(trace id,Span id 和 baggage)附加到传出请求。只有 id 和 baggage 随请求一起传播;所有其他概要分析数据(如操作名称,时间,tag 和 log)都不会传播。相反,它在后台异步地传输到 Jaeger 后端。
为了最大程度地减少开销,Jaeger 客户端采用了各种采样策略。对跟踪进行采样时,将捕获分析范围数据并将其传输到 Jaeger 后端。当不对跟踪进行采样时,根本不会收集任何性能分析数据,并且对 OpenTracing API 的调用会被短路,以产生最小的开销。默认情况下,Jaeger 客户端对 0.1% 的 traces 进行采样(每 1000 条中的 1 条),并且能够从 Jaeger 后端检索采样策略。有关更多信息,请参阅采样。
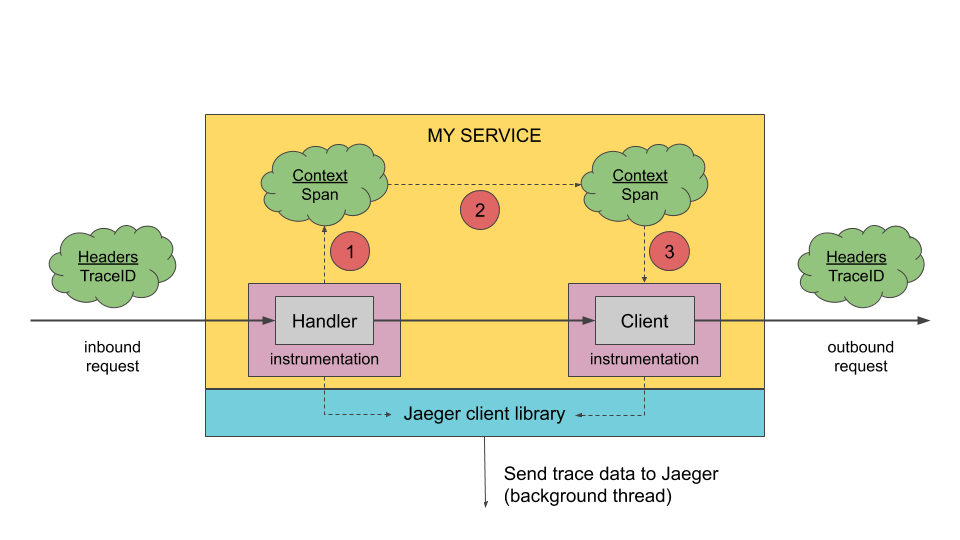
代理(Agent)
Jaeger 代理 是一个网络守护程序,它侦听通过 UDP 发送的 span,然后将其分批发送给收集器(Collector)。它旨在作为基础组件部署到所有主机。该代理为客户端抽象了收集器的路由和发现。
收集器(Collector)
Jaeger 收集器从 Jaeger 代理接收跟踪,并通过处理管道运行它们。当前,我们的管道会验证跟踪,为其建立索引,执行转换并最终存储它们。
Jaeger 的存储是一个可插拔组件,目前支持 Cassandra,Elasticsearch 和 Kafka。
查询(Query)
查询是一项从存储中检索跟踪并托管 UI 来显示跟踪的服务。
Ingester
Ingester 是一项从 Kafka topic 读取并写入另一个存储后端(Cassandra,Elasticsearch)的服务。
小结
本篇为大家介绍了 Jaeger 概念、特性以及架构,让大家对 Jaeger 的各个组件有初步的认识。下一篇,将为大家介绍如何部署和使用 Jaeger 进行分布式追踪。



