
Prometheus 的重要性和流行度已经无需多言。要把 Prometheus 用好,不能只会写几条 PromQL 或配置几个抓取目标,还要理解它把采集、存储、查询、告警判定和告警分发拆成了哪些组件,每个组件解决什么问题,又把哪些问题留给了周边生态。
核心摘要
- Prometheus 监控平台的主链路是:采集指标、写入时序库、查询分析、规则判定、告警分发。
- Prometheus Server 负责抓取、存储、查询和告警规则判定;Alertmanager 负责告警事件的去重、分组、路由和通知。
- Exporter 可以理解为适配器,用来把 MySQL、Redis 等系统的运行状态转成 Prometheus 可抓取的指标格式。
- Grafana 通常负责可视化分析,Pushgateway 主要服务于短生命周期任务的指标上报。
- Prometheus 单进程部署简单,但采集、存储、告警引擎天然有单点和容量边界,大规模场景通常需要 VictoriaMetrics、Thanos 或多套 Prometheus 等方案协同。
监控系统的核心逻辑
对于一套监控系统而言,核心逻辑就是采集数据并存储,然后做告警判定、数据展示分析。这个 专栏文章 详细讲解了数据流架构,整个流程图如下:
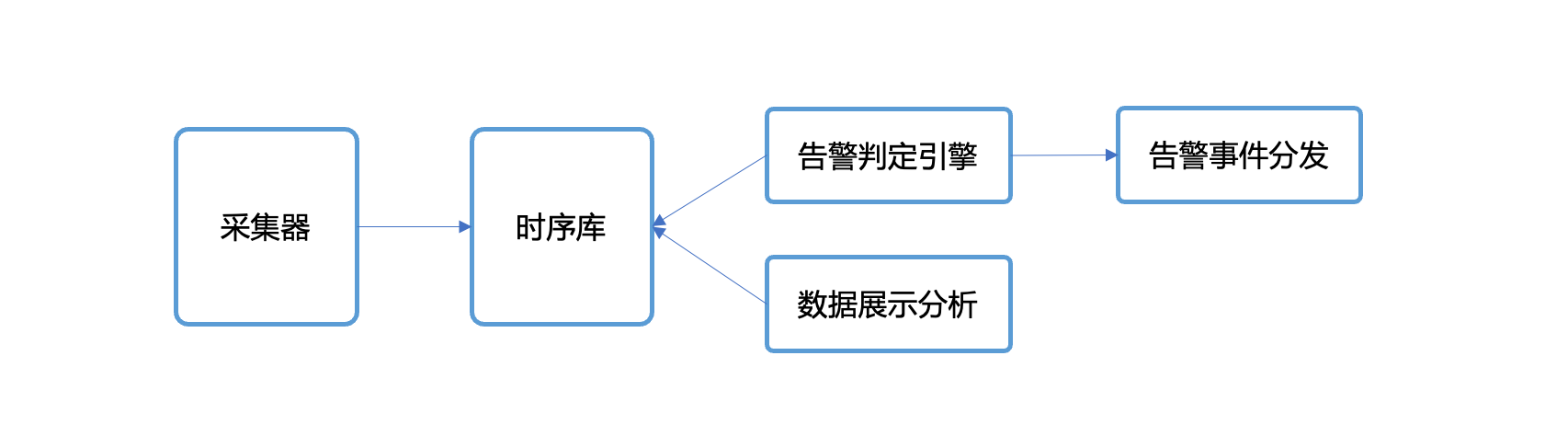
Prometheus 有多个组件,或者说多个进程,协同完成这条链路。先看两个最核心的代码仓库:
- https://github.com/prometheus/prometheus:这是 prometheus 进程的代码仓库,功能包括抓取远端监控指标、存储时序数据、暴露查询接口支持数据查询、支持告警规则配置并做告警判定
- https://github.com/prometheus/alertmanager:这是 alertmanager 进程的代码仓库,功能包括接收 prometheus 产生的告警事件,对事件做去重、分组、路由、通知等操作
我把监控系统的流程图给变换一下颜色:
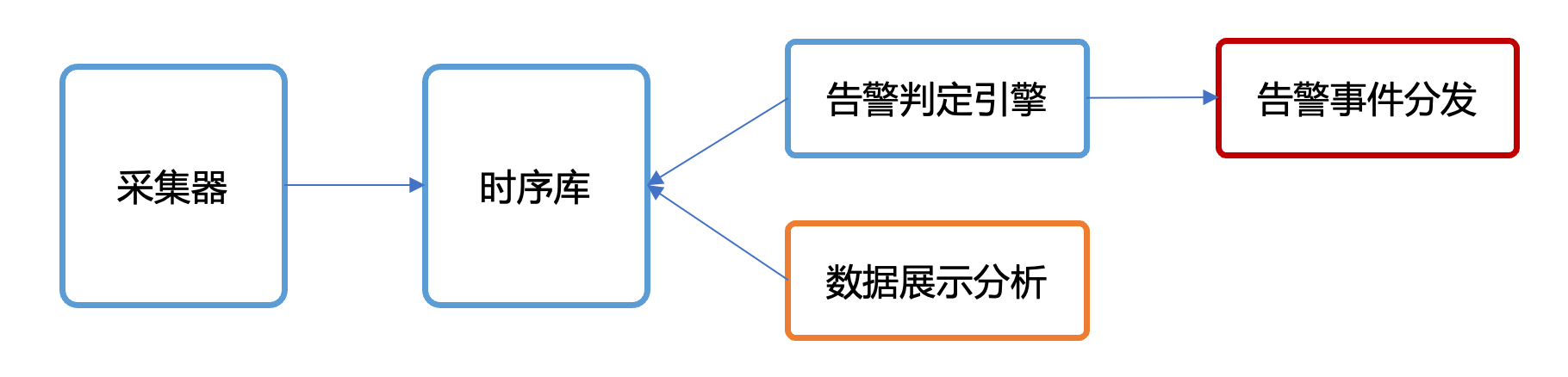
- prometheus 进程承接了图中蓝色功能,即:采集器、时序库、告警判定引擎
- alertmanager 进程负责告警事件分发,即图中红色部分
- 数据展示分析,橙色部分,Prometheus 做的比较少,Prometheus 确实有一个简单的 Web UI,不过比较简陋,一般使用更为强大的 Grafana 来做数据展示分析
大家可能还听过各类 Exporter,难道这些 Exporter 就没有一席之地了么?Exporter 也是很重要的,可以看做是一个适配器:它把监控目标的指标暴露出来,让 Prometheus 来抓取。或者把 Exporter 看做采集器的一部分也行,无伤大雅,理解整个数据流就可以,无需在词汇上纠结。
想象一下,假设你有一个 Application,一个 Go 程序或者 Java Spring Boot 程序,Application 把自身的运行状态指标通过 /metrics 接口暴露出来,Prometheus 直接抓取即可,这里不需要 Exporter。但是一些成熟的数据库、中间件,比如 MySQL、Redis,并不一定直接暴露 Prometheus 格式的指标,Prometheus 没法直接抓取,怎么办?
一种做法是把 Prometheus 的抓取器做得很重,让它既能抓 HTTP 协议的 /metrics 数据,也能抓 MySQL、Redis 等数据。但这样 Prometheus 代码会变得臃肿,不利于维护。Prometheus 选择了 Exporter 的设计:Exporter 去理解不同监控目标,把原始状态转换为 Prometheus 格式的指标;Prometheus 再统一抓取 Exporter 暴露出来的数据。这样 Prometheus Server 保持简洁,Exporter 可以独立维护,也更方便社区共建。
但是,Exporter 会有很多不同的进程,水平参差不齐,从部署的角度可能略麻烦,所以市面上也有一些开源项目,把众多 Exporter 整合在一起变成一个进程,比如 Grafana-agent、Cprobe,当然,还有大名鼎鼎的 OpenTelemetry 也是这个思路。
了解了上述知识,我们再来看 Prometheus 官网的架构图。
Prometheus 架构:各组件分别负责什么
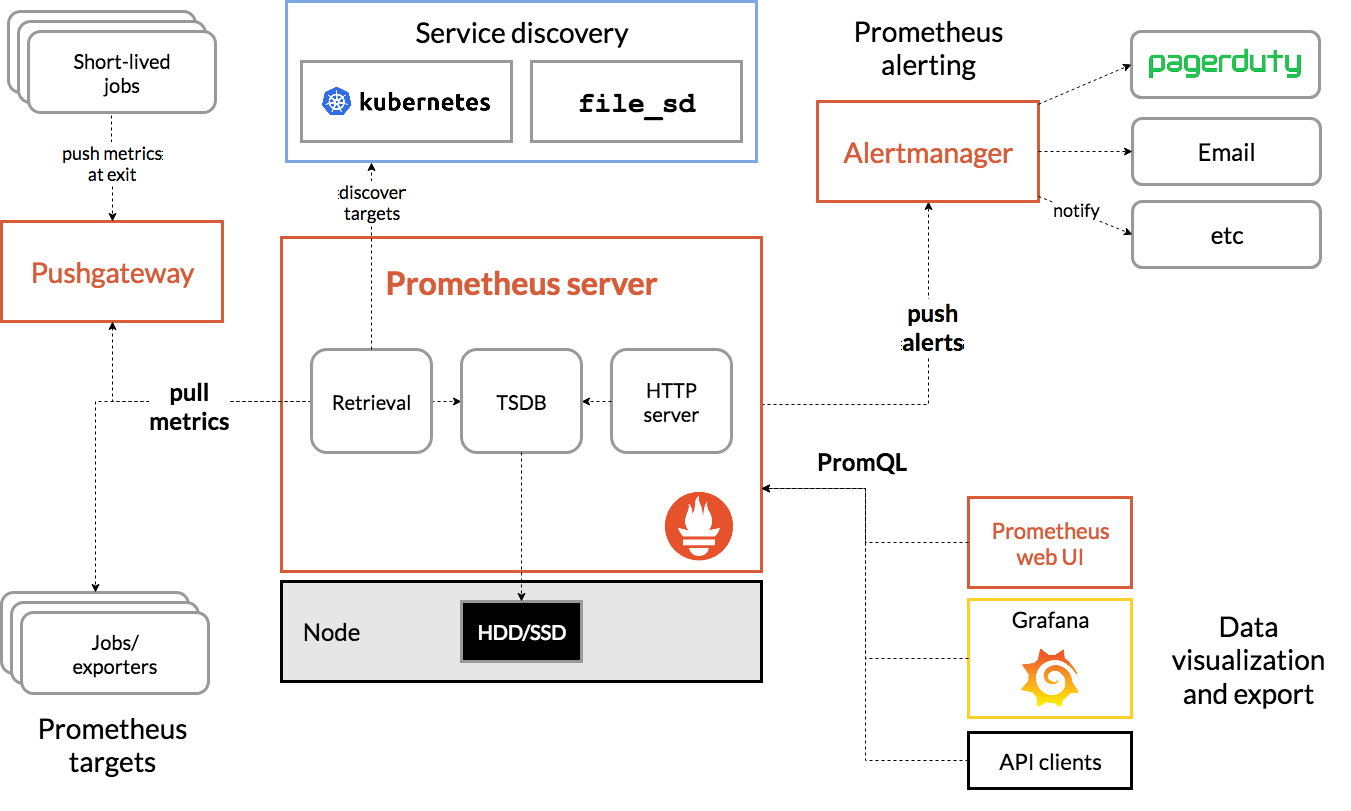
- Prometheus Server:是 prometheus 进程的一部分功能,负责数据抓取、存储、HTTP 接口查询
- Retrieval:数据抓取,从监控目标那里拉取监控指标,Prometheus 定义了一个标准协议,只要监控目标支持这个协议,Prometheus 就可以抓取
- TSDB:时序库,Prometheus 会把抓取到的监控指标存储在本地,单点的。如果想要高可用,可以使用 Thanos、VictoriaMetrics 等
- HTTP server:Prometheus 会暴露 HTTP 接口,供外部查询监控指标
- Service Discovery:服务发现,是 prometheus 进程的一部分功能,Prometheus 会定期去服务发现组件那里拉取监控目标的列表,省去了手动配置的繁琐,当然,前提是这些监控目标得注册到服务发现组件上
- Kubernetes SD:基于 Kubernetes 的服务发现机制,比如通过 apiserver 拉取 pod 列表、service 列表作为监控目标
- File SD:基于文件的服务发现机制,从配置文件中读取监控目标列表
- HTTP SD:基于 HTTP 的服务发现机制,从 HTTP 接口中读取监控目标列表
- Consul SD:基于 Consul 的服务发现机制,从 Consul 中读取监控目标列表
- 等等
- Pushgateway:是一个单独的进程,用于接收短生命周期的监控指标,比如批处理任务的监控指标,因为批处理任务通常不会暴露 HTTP 接口,Prometheus 就没法拉取了,所以批处理任务需要主动推送监控指标到 Pushgateway,Prometheus 再去拉取 Pushgateway 的监控指标
- Alertmanager:负责接收 prometheus 产生的告警事件,对事件做去重、分组、路由、通知等操作。如果想要更高阶的收敛、降噪、排班、认领、升级等功能,可以把 Alertmanager 和一些第三方工具结合使用,比如 PagerDuty、Flashduty、OpsGenie 等
- Prometheus web UI:prometheus 进程启动之后,会暴露一个简单的 Web UI,可以查看监控指标,但是功能比较简陋,一般使用 Grafana 来做数据展示分析
- Grafana:是一个独立的进程,不属于 Prometheus 项目的一部分,不过可以和 Prometheus 整合。用于数据展示分析,功能非常强大,支持多种数据源,比如 Prometheus、Elasticsearch、Loki 等,支持多种图表类型,比如折线图、柱状图、饼图、热力图等
Prometheus 架构的问题:简单部署背后的容量边界
主要问题是容量扩展。Prometheus 一个进程干了很多事情,部署非常简单,弊端就是单点没法扩展:告警引擎是单点、存储是单点、采集也是单点。如果体量很大,或者对稳定性要求比较高,就需要通过其他手段来解决。
比如 VictoriaMetrics 项目,就是完全兼容 Prometheus 生态的协议和接口,但是提供了分布式能力。存储使用 vmstorage 进程,查询使用 vmselect 进程,数据接收使用 vminsert,告警使用 vmalert,数据抓取使用 vmagent,组件确实多了,但是每个组件都可以部署多个实例组成集群,提升了整体的可用性和容量。VictoriaMetrics 项目的架构图如下:
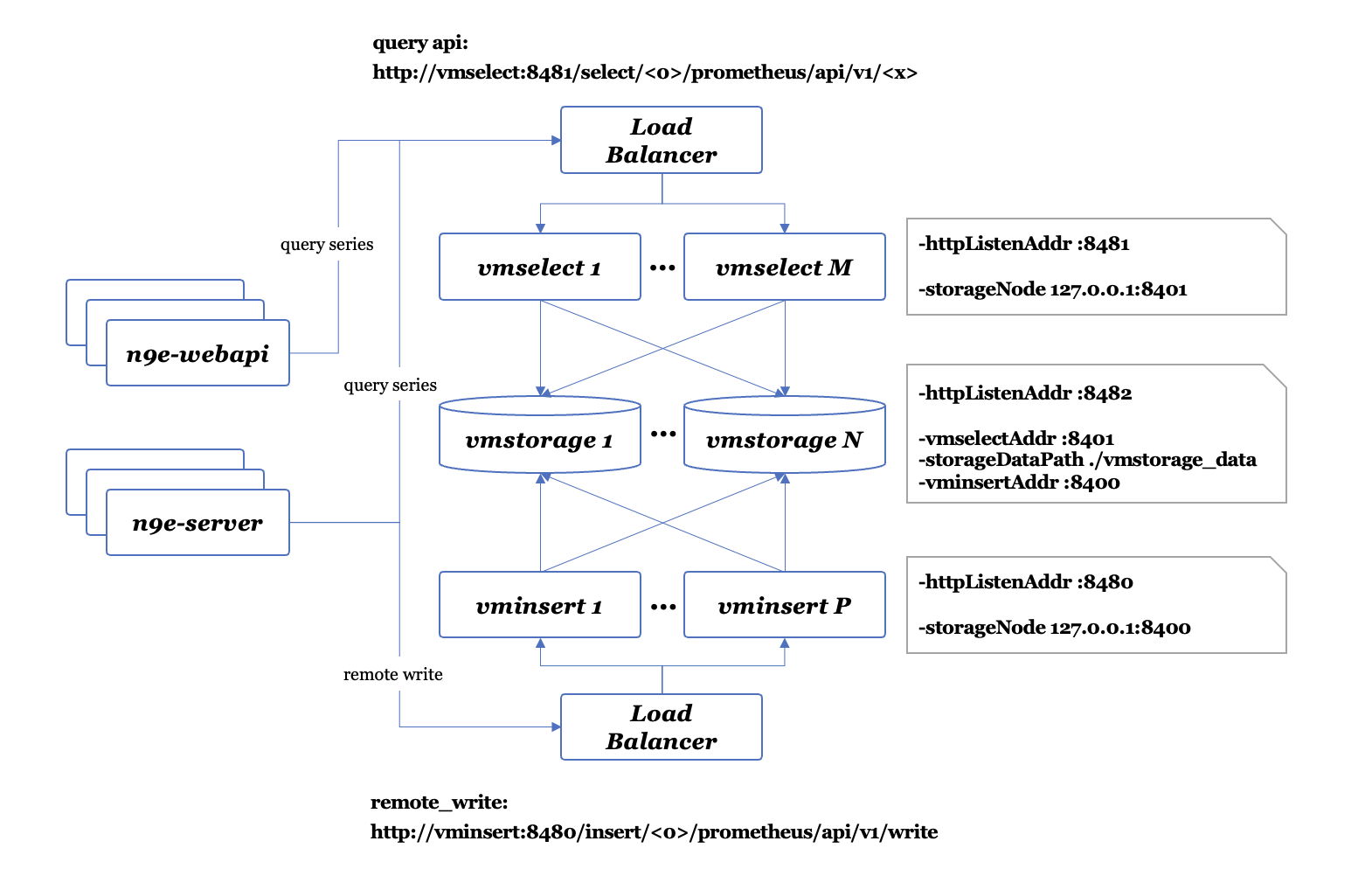
或者还有一个办法,就是直接部署多套 Prometheus,比如 DBA 自己用一个 Prometheus,Hadoop 团队自己用一个 Prometheus,这样可以解决容量问题,没法解决数据单点存储问题。如何解决单点问题?双写!比如 DBA 团队,部署两个 Prometheus,采集相同的数据,两个 Prometheus 数据相同,规则相同,告警也会产生两份,可以通过 Alertmanager 做告警去重,这样就解决了单点问题。
Prometheus 规则管理问题:从配置文件走向自服务
最后一个问题,简单聊聊 Prometheus 的规则管理问题。Prometheus 的规则是通过配置文件定义的,这个配置文件是一个 yaml 文件,里面定义了监控规则、告警规则等。如果一个公司有很多套 Prometheus,规则分散在多个 yaml 中不方便管理,希望能有一套易用的、权限隔离的 UI,把监控能力开放给全公司各个团队并让他们自服务,别啥事都来找监控团队,这个时候就需要一个规则管理系统,比如夜莺(Nightingale)。如果有这方面的痛点可以去了解一下,如果 Prometheus 自身的玩法就感觉够用了,那更好,不用再引入新的组件。
结论
Prometheus 监控平台不是一个单独的“看图工具”,而是一套围绕时序数据的数据流体系。Prometheus Server 负责抓取、存储、查询和规则判定,Alertmanager 负责告警事件分发,Exporter 负责适配不同监控对象,Grafana 负责可视化分析,Pushgateway 解决短生命周期任务的上报问题。
使用任何一个开源项目,都要了解其原理。知道数据从哪里来、存到哪里、在哪里判定、在哪里通知,才能理解最佳实践,出了问题也有排查思路。切莫只是解决一些表面问题,得过且过。
FAQ
Q1:Prometheus Server 和 Alertmanager 是什么关系?
A:Prometheus Server 做指标抓取、存储、查询和告警规则判定;Alertmanager 接收 Prometheus 产生的告警事件,并负责去重、分组、路由和通知。
Q2:Exporter 是采集器吗?
A:可以把 Exporter 理解为适配器,也可以理解为采集链路的一部分。它的核心价值是把不同系统的运行状态转换为 Prometheus 可抓取的指标格式。
Q3:Prometheus 自带 Web UI,为什么还常配 Grafana?
A:Prometheus 自带 Web UI 更适合基础查询和调试,功能相对简陋。实际做数据展示分析时,通常会使用 Grafana。
Q4:什么时候需要夜莺这类规则管理系统?
A:当公司有多套 Prometheus、规则分散在多个 yaml 文件里,或者希望通过权限隔离的 UI 把告警配置开放给各团队自服务时,就可以考虑规则管理系统。如果 Prometheus 原生配置已经够用,就不必额外引入组件。



