
Elasticsearch 数据源
夜莺( Nightingale )ES 数据源
日志采集&存储
ES 存储部署和日志采集上报,可以参考此文档
Elasticsearch 数据源配置
数据源名称-名称:Elasticsearch 数据源标识名称;
HTTP - URL :Elasticsearch 服务地址;示例:http://server-ip:9200
HTTP -超时(单位:ms ):连接服务超时时间;
授权-用户名 & 密码:Elasticsearch 授权用户名和密码;

Elasticsearch 通过your_path/bin/elasticsearch-users list|useradd创建和查询用户,可以通过GET /_security/user或者在 Kibana 的管理界面中查看和管理用户。
自定义HTTP标头- Header & Value :配置请求 Elasticsearch 接口的校验参数;
ES详情- 版本&最大并发分片请求数
如果集群中的分片数量非常高,未配置的最大并发分片请求数可能会导致高内存使用、CPU 负载增加、延迟增加等问题。那么这种情况下设置最大并发分片请求书就显得十分有必要了。通过 Elasticsearch 的查询命令curl -X GET http://server_ip:port/_cat/shards?v可以查询到设置的最大并发分片请求数
最小时间间隔(s) :按时间间隔自动分组的下限。建议设置为写入频率,例如,如果数据每分钟写入一次,则为1m。
写配置- 允许写入(商业版功能)
这个功能和 Prometheus 数据源中的 Remote Write 类似,开启后就可以将日志提取数据回写到 ES 节点中;
开启允许写入后,就可以正常写入数据了。
关联告警引擎集群:配置绑定指定告警引擎的数据源;
如何查询数据
1.日志查询-即时查询—>2.选择对应es数据源—>3.选择查询语法—>4.输入查询语句
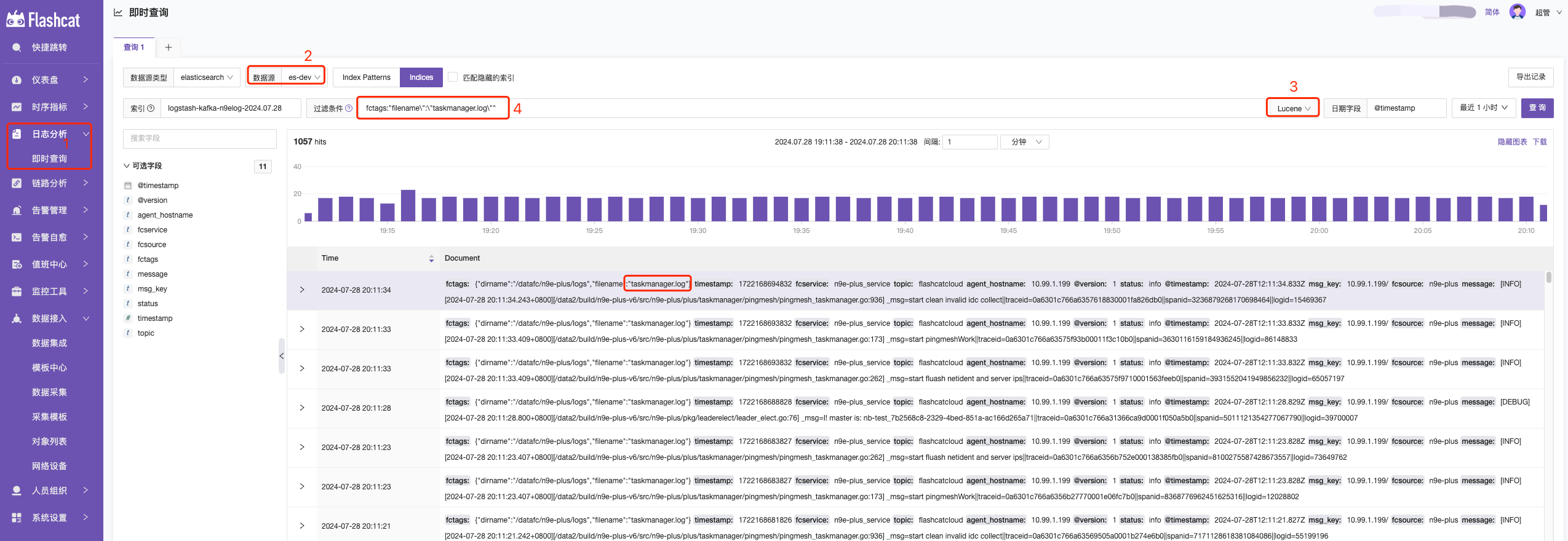
● KQL :一种用于过滤数据的简单基于文本的查询语言,KQL 仅过滤数据,并且不具有聚合、转换或排序数据的作用。KQL 官方语法介绍
● Lucene :查询语法的主要原因是使用高级 Lucene 功能,例如正则表达式或模糊术语匹配。但是,Lucene 语法无法搜索嵌套对象或脚本字段。Lucene 官方语法介绍
如何配置 ES 日志告警
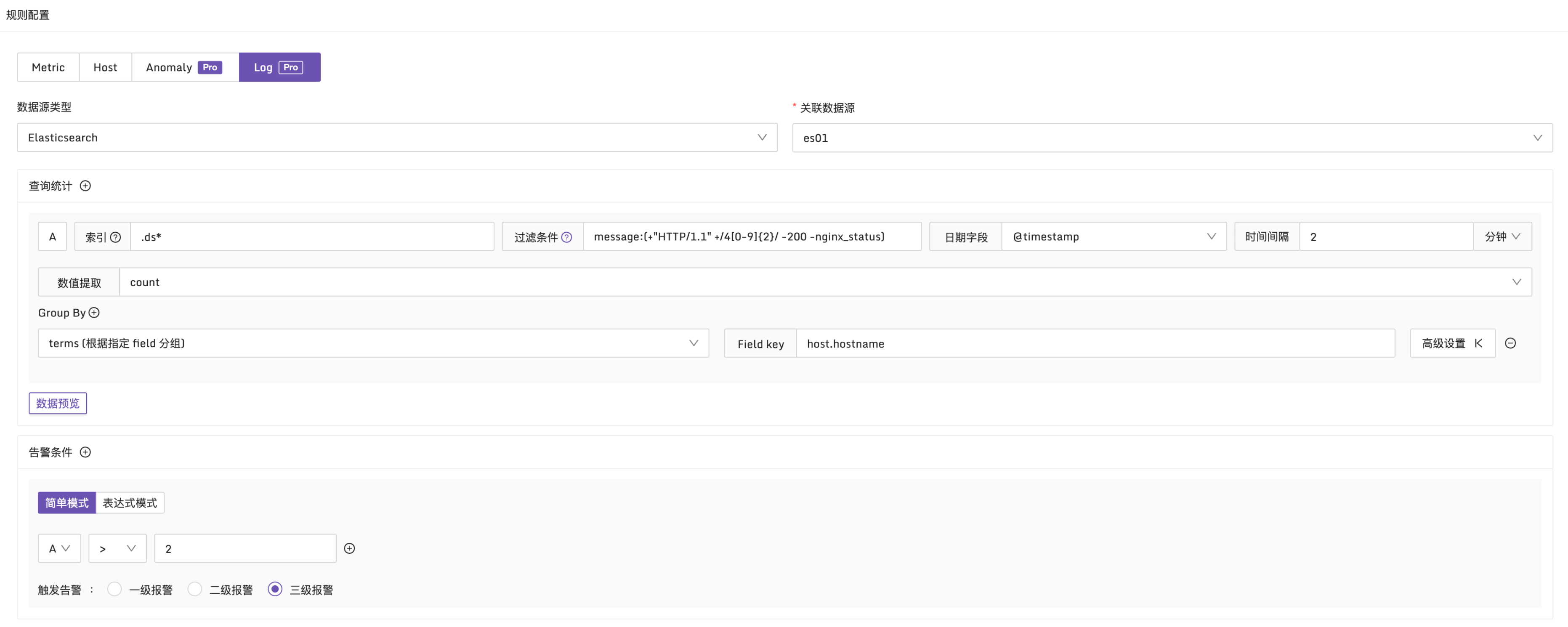
日志类型和常规的指标告警规则非常相似,其唯一的区别在于告警条件的设置。指标告警规则使用 PromQL 作为查询条件,而日志类型的告警规则则使用布尔表达式作为查询条件。这些告警条件(如 A、B 等)需要通过查询统计来获取。
在配置查询统计时,会发现它和 ES日志即时查询 类似,先选择索引和查询条件以及日期字段,还有两个额外的数据字段组:数值提取和 Group By。
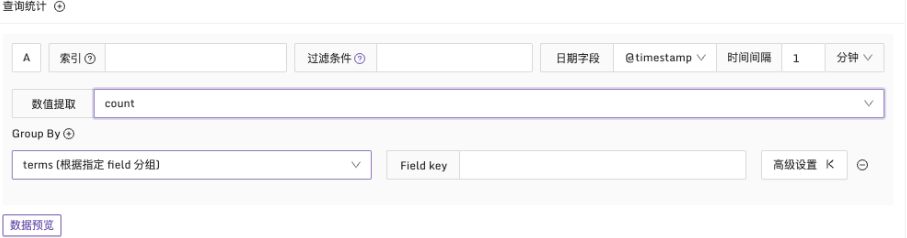
为了获得数值类型的结果,需要使用数值提取,选择适当的统计函数。除了常见的 count、sum、avg、min、max 等函数外,还支持一些百分位值函数,如 p90、p95、p99。
此外,通过配置 Group By,可以根据特定字段对结果进行分组。这将生成多个时间序列,并在满足告警条件的情况下产生多个异常点,从而生成多条告警事件。
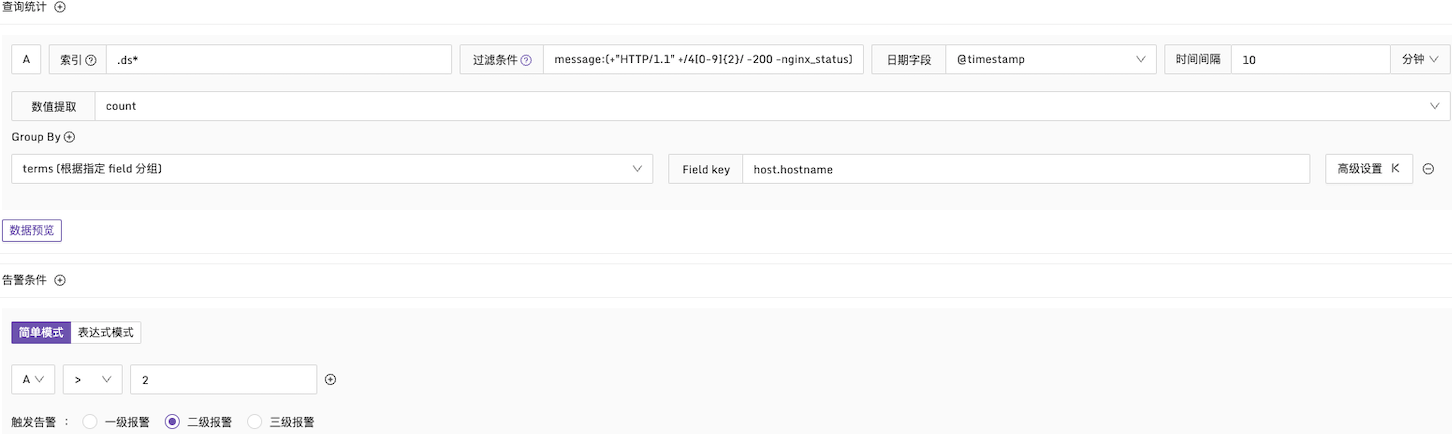
例子1:HTTP CODE 为4xx的告警条件
说明:在每10分钟的时间段内,检查日志中的 message 字段。如果4xx的日志数量超过2次,产生告警,并且按照 host.hostname 字段进行分组统计,配置方式如下
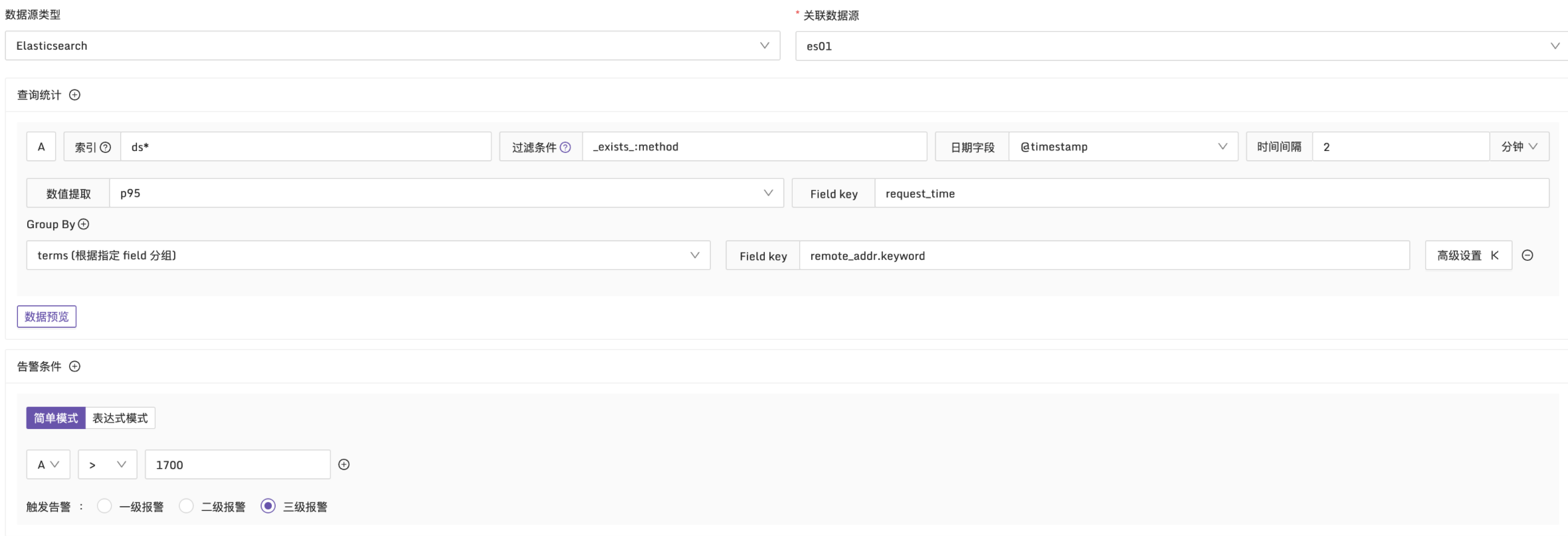
例子2:接口的请求耗时95分位值超过 1700ms 时触发告警
说明:在每2分钟的时间段内,使用p95函数统计日志中的 request_time 。按 remote_addr 维度进行分组,检查是否有超过1700ms 的请求耗时,配置方式如下
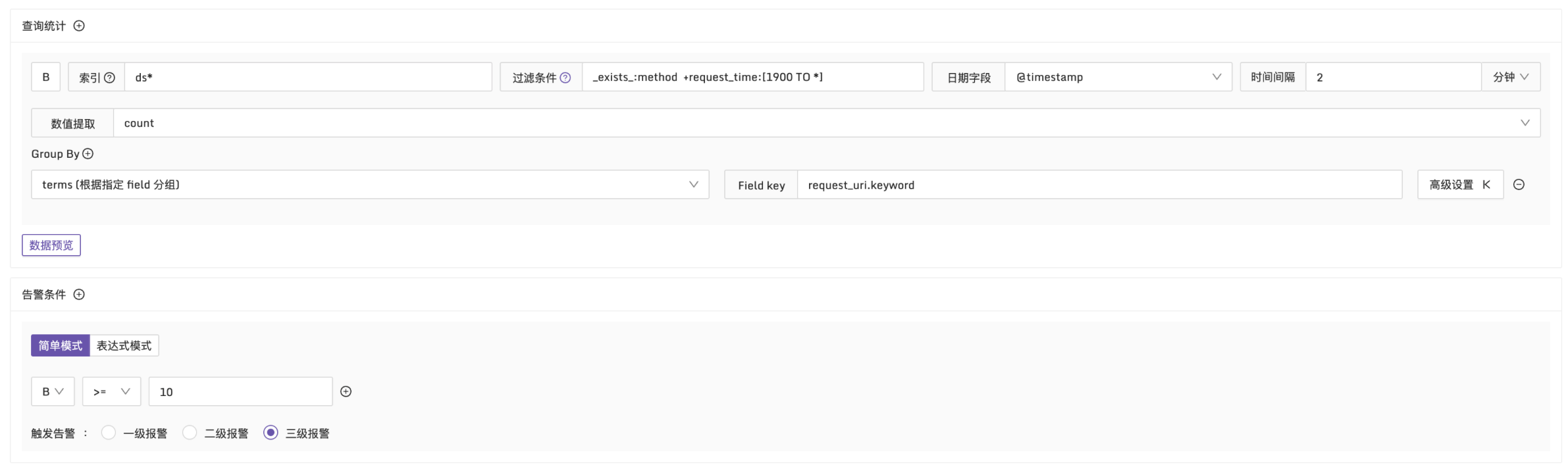
例子3:request_time 大于1900ms,匹配日志超过10条时触发告警
说明:在每2分钟的时间段内,筛选出 request_time 大于1900ms 的日志。按 request_uri 维度进行分组,检查日志数量是否超过10条,配置方式如下
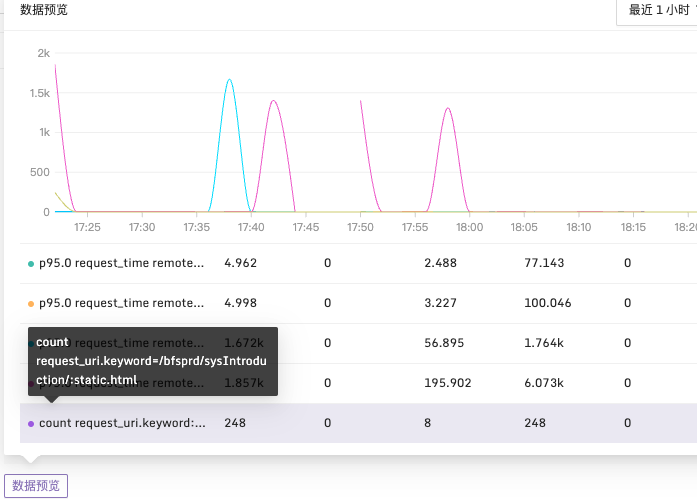
在配置完成所需的数据字段后,还可以通过数据预览按钮来预览查询结果。
常见问题
Q1:保存数据源后状态显示异常?
A:按顺序排查:
- 网络:n9e Server 主机上
curl http://<es>:9200/_cluster/health能否拿到 200; - 用户名密码:ES 8.x 默认开启 X-Pack security,必须填账号密码;
- HTTPS 证书:ES 8.x 默认自签证书,需要在表单里开"跳过 TLS 验证"或导入 ES 的根证书;
- 版本兼容:n9e 支持 ES 6.x / 7.x / 8.x,但部分 API 行为不同 — 看夜莺 server 日志。
Q2:能查到索引但查不到数据?
A:
- 时间字段映射:ES 数据源配置里要指定"时间字段名"(如
@timestamp),夜莺按这个字段过滤时间范围; - 索引模式:
logstash-*这种通配符正确,但要确保有匹配的实际索引; - 查询 DSL 错误:在 日志查询 里测试简单查询确认连通性。
Q3:跨多个集群 / 索引怎么处理?
A:每个 ES 集群配一份数据源。同集群下多个索引可以在查询时用通配符(如 log-prod-*)一次跨多个索引查。
Q4:OpenSearch 能用 ES 数据源类型接入吗?
A:可以 — OpenSearch fork 自 ES 7.10,API 兼容。n9e 也提供了独立的 OpenSearch 数据源类型,优先用 OpenSearch 类型(针对 OS 做了一些优化),用 ES 类型也能跑。


