夜莺-Nightingale
夜莺V8
前言必读

安装
采集器
快速体验
监控实践
功能详解
说明文档
夜莺V7
项目介绍
功能概览
部署升级
数据接入
告警管理
数据查看
功能介绍
告警管理
通知管理
通知规则介绍
阿里云短信
Relabel 事件处理
Event Drop 事件处理
Event Update 事件处理
Callback 事件处理
Script 事件处理
Label Enrich 事件处理
AI Summary 事件处理
模板函数
仪表盘
数据源
时序指标
日志分析
告警自愈
基础设施
集成中心
人员组织
系统配置
数据库表结构
users
notify_tpl
board
users
target
target
user_group
user_group_member
task_tpl
task_tpl_host
task_record
sso_config
role
role_operation
recording_rule
notify_tpl
metric_view
datasource
configs
chart_share
busi_group
busi_group_member
builtin_cate
builtin_cate
builtin_cate
builtin_cate
board
board_payload
alerting_engines
alert_subscribe
alert_rule
alert_mute
alert_his_event
alert_cur_event
alert_aggr_view
API
FAQ
夜莺V6
项目介绍
架构介绍
快速开始
黄埔营
安装部署
升级
采集器
使用手册
API
数据库表结构
users
notify_tpl
board
users
target
target
user_group
user_group_member
task_tpl
task_tpl_host
task_record
sso_config
role
role_operation
recording_rule
notify_tpl
metric_view
datasource
configs
chart_share
busi_group
busi_group_member
builtin_cate
builtin_cate
builtin_cate
builtin_cate
board
board_payload
alerting_engines
alert_subscribe
alert_rule
alert_mute
alert_his_event
alert_cur_event
alert_aggr_view
FAQ
转发数据给多个时序库
机器列表数据异常
数据流图
监控数据时有时无
查询原始监控数据
快捷视图详解
告警自愈模块使用
仪表盘里只展示我的机器
仪表盘里图表数据缺失
设置自定义告警通知方式
target_up指标的问题
夜莺可以监控 x 么
夜莺告警常见问题排查思路
告警和恢复的判断逻辑
容量规划问题
connection refused
登录与认证
数据采集器Categraf
日志写到`/var/log/messages`
告警规则&告警模板如何引用变量
采集到的数据是字符串怎么处理
管理员密码忘记了
制作大盘如何添加图片
添加loki数据源报错
v6小版本升级有什么 sql 要执行吗
机器列表有展示,但采集数据查询不到
n9e 启动异常报错
n9e集群部署配置修改
推送 Promethus 报错 OOO
机器列表怎么忽略云资源
告警规则仅在本业务组生效失败
categraf 启动 oracle 插件报错
告警自愈不生效
n9e查询时序库EOF报错
手动编译项目报错
promQL 使用函数标签信息丢失
内存使用率+可用率不等于100
夜莺仪表盘有哪些内置变量
categraf配置文件支持热加载吗
导入 Grafana 仪表盘无效数据源
如何查看报错消息
采集器-Categraf
插件配置
插件综述
基础指标采集插件
Netstat 采集插件
Netstat_Filter 采集插件
Procstat 采集插件
HTTP_Response
MySQL 插件
Redis 插件
SNMP_Zabbix插件
SNMP 插件
IPMI 采集插件
DNS_Query 插件
DCGM 采集插件
NVIDIA_SMI 插件
cAdvisor 采集插件
Huatuo 托管插件
SSHD 采集插件
Systemd 采集插件
S.M.A.R.T.采集插件
PostgreSQL 插件
MongoDB 插件
Elasticsearch 采集插件
EXEC 采集插件
EMQX 采集插件
阿里云指标采集插件
Zabbix 指标转换插件
CloudWatch 指标采集插件
Google Cloud 指标采集插件
Mtail 日志采集插件
Prometheus 采集插件
开启采集配置控制台下发
贡献新插件
Flashcat 企业版
开源生态
Telegraf
Prometheus
版权声明
第1章:天降奇兵
第2章:探索PromQL
开篇
理解时间序列
Metrics类型
初识PromQL
PromQL操作符
PromQL聚合操作
PromQL内置函数
在HTTP API中使用PromQL
最佳实践:4个黄金指标和USE方法
小结
第3章:Prometheus告警处理
开篇
Prometheus告警简介
自定义Prometheus告警规则
部署Alertmanager
Alertmanager配置概述
基于标签的告警处理路由
使用Receiver接收告警信息
告警模板详解
屏蔽告警通知
使用Recoding Rules优化性能
小结
第4章:Exporter详解
第5章:数据与可视化
第6章:集群与高可用
第7章:Prometheus服务发现
第8章:监控Kubernetes
开篇
初识Kubernetes
在Kubernetes下部署Prometheus
Kubernetes下的服务发现
使用Prometheus监控Kubernetes集群
基于Prometheus的弹性伸缩
小结
第9章:Prometheus Operator
参考资料
PromQL 变量查询
使用场景
PromQL 变量设置主要应用于以下场景:
-
差异化监控配置
- 对不同重要程度的机器设置不同的告警阈值
- 针对特定设备组设置专门的监控规则
-
灵活的监控范围调整
- 快速切换监控目标设备
- 动态调整监控规则的覆盖范围
-
批量规则管理
- 使用同一个规则模板,通过变量适配不同环境
- 减少重复配置,提高规则维护效率
什么是变量?
在告警规则上下文中,变量是指那些可以在定义告警查询条件时被引用、但在实际触发告警时其值会被特定信息替换掉的占位符。使用变量可以让告警消息变得更加具体和个人化,同时也使得单个告警模板能够适应多种情况下的不同需求。
支持的类型
- 机器标识变量
在某些场景,如果只想对某些网络设备进行监控,这个时候,可以使用机器标识变量
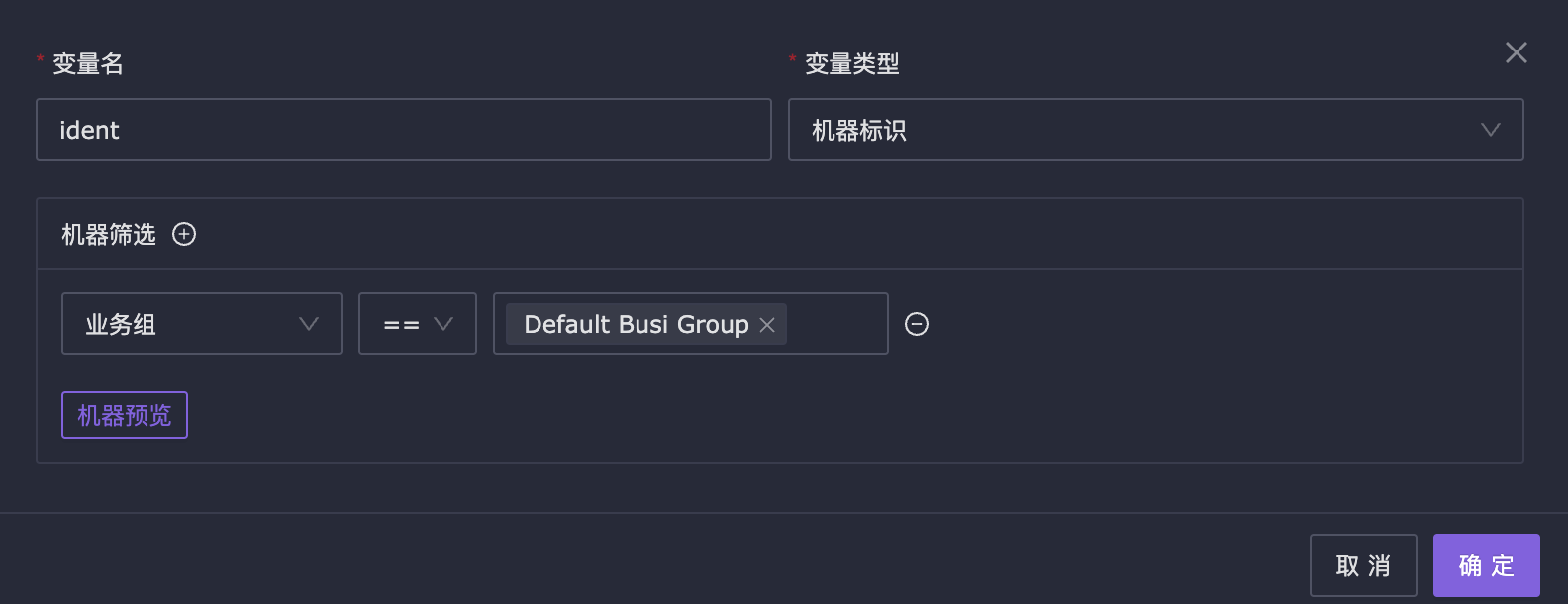
定义好变量名称之后,可以在 promql 查询条件中,使用 $ident 作为占位符,在查询之前,将变量替换为上面机器标识筛选到的机器
mem_available_percent{ident="$ident"}>80
- 网络设备变量
在某些场景,如果只想对某些网络设备进行监控,这个时候,可以使用网络设备变量

定义好变量名称之后,可以在 promql 查询条件中,使用 $ip 作为占位符,在查询之前,将变量替换为上面筛选到的网络设备
snmp_icmp_packet_loss{agent_host="$ip"}>0
- 阈值变量:
在某些场景,我们管理了一批机器,其中有几台机器比较特殊,告警阈值和其他机器不同,此时可以使用阈值变量,给特殊的机器配置不同的阈值,如下图所示
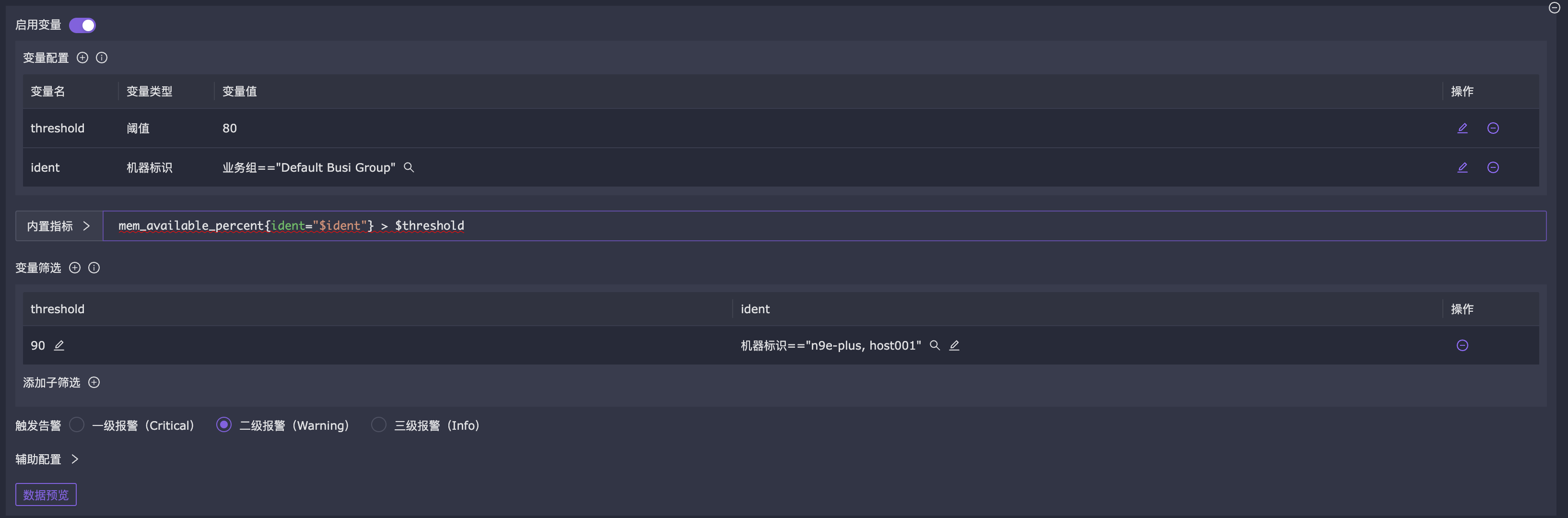
上面配置中,业务组为 Default Busi Group 的机器,阈值都是 80,如果在这个业务组的某两台机器,我们想设置特殊的阈值,可以在查询条件下面添加 变量筛选,机器标识选择这两台机器,阈值设置为 90,这个只有这两台机器的阈值是 90,其他机器是 80
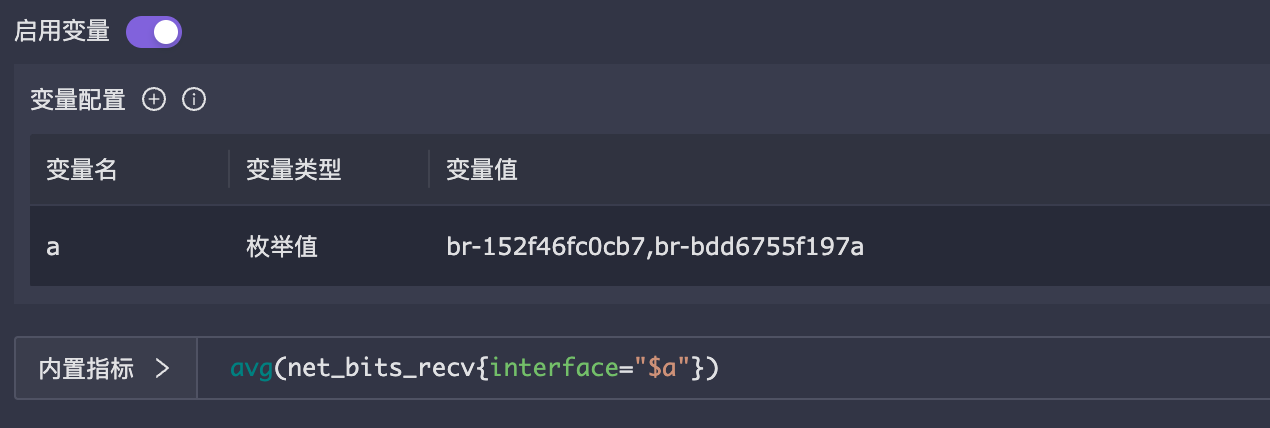
- 枚举值变量
有些场景,对于某个标签,只想对某几个值进行监控,可以使用枚举值