
边缘机房部署夜莺,应对网络割裂的情况
介绍夜莺 v7 边缘机房部署方案,说明 n9e-edge 如何同步中心告警规则、分担本地时序库判定,并在网络割裂时保持告警可用。
在这个架构模式下,中心端部署 n9e + mysql + redis,边缘机房部署 n9e-edge,整体架构如下:
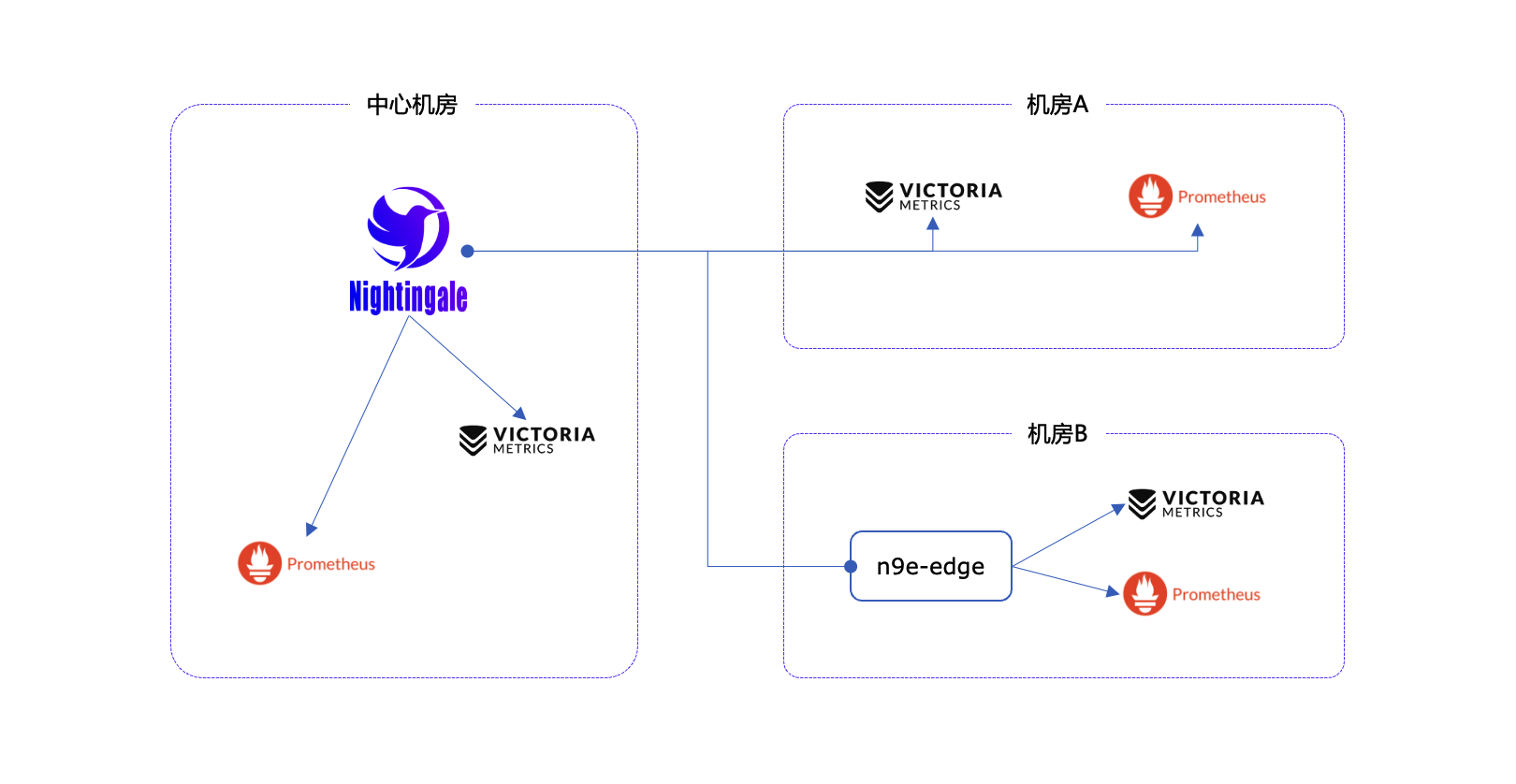
上例中,演示了 3 个机房的部署架构,其中机房 A 和中心机房之间网络链路很好,机房 B 和中心机房之间的网络链路不太好,各个机房都有时序库。所以,中心机房的夜莺告警引擎直接处理中心机房和机房 A 的时序库,机房 B 的时序库由机房 B 的告警引擎处理,也就是图中的 n9e-edge,n9e-edge 会从中心机房的夜莺同步告警规则,然后对本机房的时序库做告警判定。
这样一来,即便机房 B 和中心机房之间网络割裂,由于 n9e-edge 内存中早就同步到了告警规则,所以机房 B 的告警引擎还是可以正常处理机房 B 的两个时序库的告警判定工作。提升了监控系统整体高可用性。
n9e-edge 的配置文件默认放在了 etc/edge 目录下,启动 n9e-edge 的方法如下:
./n9e-edge -configs etc/edge
当然,生产环境需要使用 systemd 启动,上面我只是方便测试和说明问题。etc/edge/edge.toml 中的关键配置是 [CenterApi],如下:
[CenterApi]
Addrs = ["http://127.0.0.1:17000"]
BasicAuthUser = "user001"
BasicAuthPass = "ccc26da7b9aba533cbb263a36c07dcc5"
# unit: ms
Timeout = 9000
Addrs 字段配置了中心端 n9e 进程的连接地址。Timeout 是超时时间,单位是毫秒。BasicAuthUser 和 BasicAuthPass 是认证信息,如果中心端没有开启认证,这两个字段可以不填。认证信息对应中心端的 etc/config.toml 中的 [HTTP.APIForService] 配置。比如:
[HTTP.APIForService]
Enable = true
[HTTP.APIForService.BasicAuth]
user001 = "ccc26da7b9aba533cbb263a36c07dcc5"
🔴 注意:中心端的 HTTP.APIForService 下面的 Enable 需要设置为 true,否则 n9e-edge 没法和中心 n9e 通信。HTTP.APIForService.BasicAuth 是 BasicAuth 的用户名和密码,可以不配置,不配置的话 n9e-edge 和中心 n9e 之间通信就无需传入用户名和密码了,为了安全,一般都会配置。
老版本的 n9e-edge 只依赖中心 n9e,所以配置好了 [CenterApi] 就可以启动 n9e-edge 了。新版本的 n9e-edge 还依赖 redis,需要给每个 n9e-edge 集群部署专门的 redis 实例。注意,n9e-edge 要使用单独的 redis,不能和中心端的 redis 共用。
如果 n9e-edge 进程挂了怎么办?如果想提升可用性,可以在机房 B 部署多个 n9e-edge 进程,多个 n9e-edge 会互备,比如机房 B 总共有 100 条告警规则要处理,部署了两个 n9e-edge 实例,那么每个 n9e-edge 实例会处理 50 条规则,如果其中某个实例挂了,另一个实例会接管所有的 100 条规则,保证了告警引擎的高可用性。相当于机房 B 的多个 n9e-edge 实例组成了一个集群,这个 edge 集群需要一个共同的名字,配置在 etc/edge/edge.toml 中的 [Alert.Heartbeat] 部分,如下:
[Alert.Heartbeat]
# auto detect if blank
IP = ""
# unit ms
Interval = 1000
EngineName = "region-b"
EngineName 就是这个 edge 集群的名字,机房 B 的多个 n9e-edge 实例都要配置成这个名字。这样一来,中心端的 n9e 进程就会把机房 B 的告警规则分配给机房 B 的 n9e-edge 集群,n9e-edge 集群内部会自动分配告警规则,保证了告警引擎的高可用性。
页面上添加数据源的时候,会选择数据源要关联的告警引擎,这个告警引擎就是 n9e-edge 的名字(EngineName)。上面架构的实践方式:如果添加的是中心机房或机房 A 的数据源,就选择中心机房的告警引擎(即 default);如果添加的是机房 B 的数据源,就选择机房 B 的告警引擎(比如 region-b,和 edge 的配置文件中的 EngineName 保持一致)。
另外,新版本 n9e-edge 需要依赖 redis,可以查看你下载的那个版本的默认配置文件,如果默认配置文件 edge.toml 中有 redis 配置,就说明这个版本依赖 redis。如果 n9e-edge 部署了多个实例组成了集群(即多个 n9e-edge 的 EngineName 是相同的),一个集群使用一个单独的 redis 实例。
在边缘机房部署了 n9e-edge 之后,边缘机房的 categraf 就可以连边缘机房的 n9e-edge,不需要连中心机房的 n9e 了,包括 heartbeat、ibex、writer 等都指向边缘机房的 n9e-edge 即可。
还是懵懵懂懂没搞定?看一下这篇文章:《夜莺监控 - 边缘告警引擎架构详解》


